











Die Datenbankgestaltung ist die Grundlage jeder robusten Softwareanwendung. Dennoch stolpern selbst erfahrene Ingenieure oft, wenn sie den Unterschied zwischen den visuellen Bauplänen und der physischen Implementierung erklären müssen. Die Verwirrung liegt typischerweise zwischen dem Entity-Relationship-Diagramm (ERD) und dem Datenbankschema. Obwohl diese Begriffe im alltäglichen Gespräch häufig synonym verwendet werden, repräsentieren sie unterschiedliche Ebenen des Datenarchitekturprozesses. Das Verständnis dieser Feinheiten ist nicht nur akademisch von Bedeutung; es bestimmt, wie Daten fließen, wie Einschränkungen durchgesetzt werden und wie sich das System im Laufe der Zeit entwickelt.
In diesem Leitfaden werden wir die theoretischen Konstrukte der Datenmodellierung im Vergleich zu den praktischen Gegebenheiten von Datenbankmanagementsystemen analysieren. Wir untersuchen, wie abstrakte Konzepte in konkrete Strukturen übergehen, welche Auswirkungen diese Transformation hat, und warum eine klare geistige Trennung zwischen beiden für die langfristige Wartbarkeit entscheidend ist. Unabhängig davon, ob Sie ein neues System entwerfen oder ein bestehendes umgestalten, sorgt Klarheit hier für die Vermeidung kostspieliger technischer Schulden.
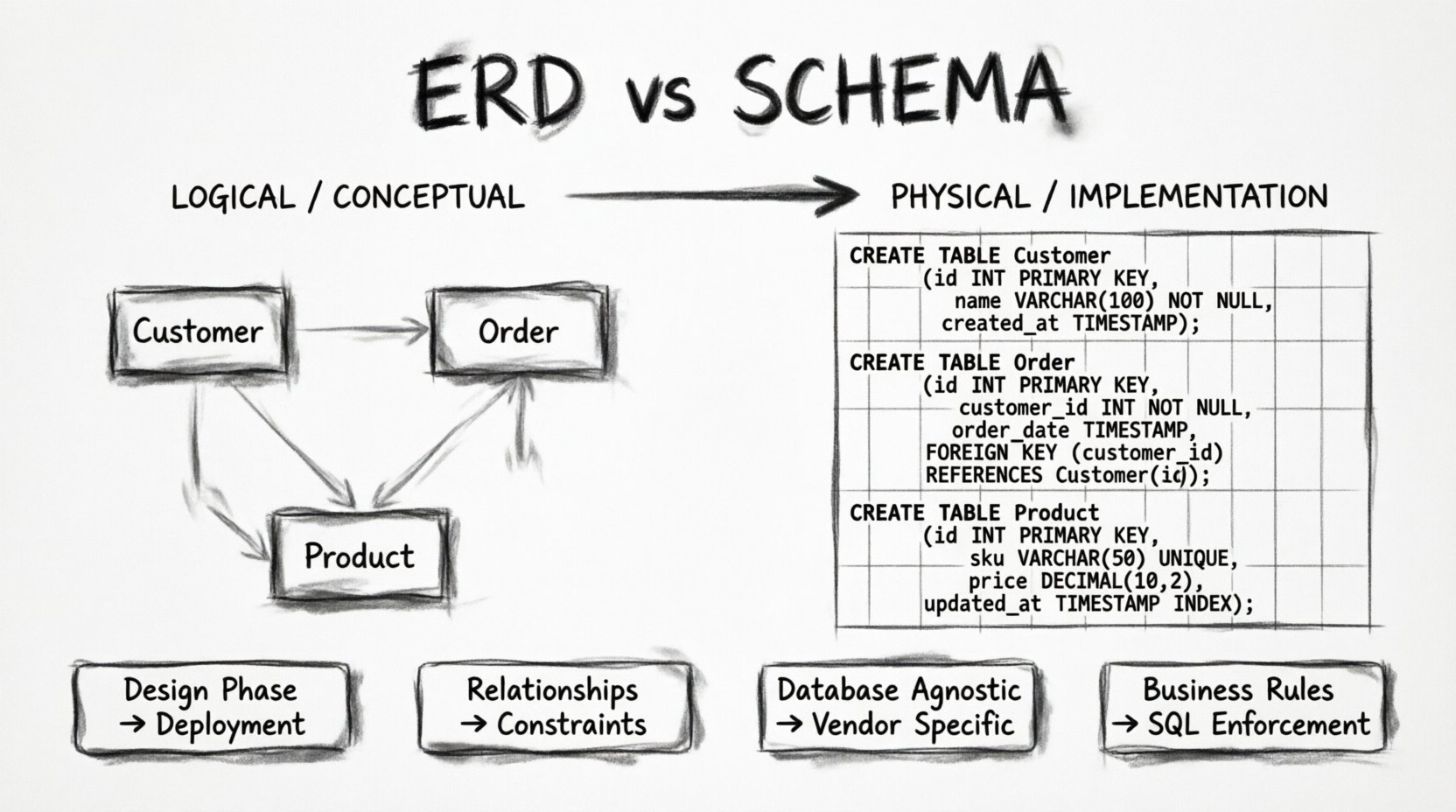
Was ist eigentlich ein ERD? 📐
Das Entity-Relationship-Diagramm ist eine konzeptionelle oder logische Darstellung von Daten. Es dient als Kommunikationsbrücke zwischen Geschäftsinteressenten, Analysten und Entwicklern. Sein primärer Zweck besteht darin, wie Datenbestandteile miteinander verbunden sind, visuell darzustellen, ohne sich in die Spezifika eines bestimmten Datenbank-Engines zu verlieren.
Im Kern konzentriert sich ein ERD auf drei grundlegende Komponenten:
- Entitäten: Diese stellen Gegenstände oder Konzepte der realen Welt dar. In einem Einzelhandelssystem könnte eine Entität seinKunden, Produkt, oderBestellung. Entitäten sind die Substantive Ihrer Datenwelt.
- Attribute: Dies sind die Eigenschaften oder Merkmale, die eine Entität beschreiben. Für einenKunden könnten Attribute wieVorname, E-Mail-Adresse, oderRegistrierungsdatum. Attribute definieren, welche Daten wir über die Entität speichern müssen.
- Beziehungen: Dies definiert, wie Entitäten miteinander interagieren. Stellt ein Kunde viele Bestellungen auf? Gehört ein Produkt mehreren Kategorien an? Beziehungen sind die Verben, die die Substantive verbinden.
Die Schönheit eines ERD liegt in seiner Abstraktion. Es spielt keine Rolle, ob die Daten letztendlich in PostgreSQL, MySQL oder einem NoSQL-Dokumentenspeicher gespeichert werden. Es geht um die Integrität der Informationen und den logischen Ablauf. Die Notationsstile variieren, wobei die Crow’s-Foot-Notation ein gängiger Standard zur Darstellung der Kardinalität (eins-zu-eins, eins-zu-viele, viele-zu-viele) ist. Diese visuelle Sprache ermöglicht es Teams, die Logik des Datenmodells zu überprüfen, bevor eine einzige Codezeile geschrieben wird.
Beim Erstellen eines ERD liegt der Fokus auf der Normalisierung. Dabei geht es darum, Daten zu organisieren, um Redundanz zu reduzieren und die Datenintegrität zu verbessern. Wir betrachten, wie große Tabellen in kleinere, verwandte Tabellen aufgeteilt werden können, um sicherzustellen, dass die Aktualisierung einer Information an einer Stelle überall dort, wo es wichtig ist, aktualisiert wird. Der ERD ist die Karte des Territoriums; er zeigt die Straßen und die Sehenswürdigkeiten, aber nicht das spezifische Pflastermaterial.
Definition des Datenbankschemas 🏗️
Wenn der ERD die Karte ist, ist das Schema das Territorium selbst. Das Datenbankschema ist die physische Struktur der Datenbank. Es ist die konkrete Sammlung von Definitionen, die dem Datenbankmanagementsystem (DBMS) genau sagt, wie Daten gespeichert werden sollen. Während der ERD in Konzepten spricht, spricht das Schema in Datentypen, Einschränkungen und Speicher-Engines.
Ein Schema definiert die folgenden technischen Details:
- Tabellen: Die ERD-Entität wird zu einer physischen Tabelle. Das Schema legt den Tabellennamen fest, der oft strengen Namenskonventionen folgen muss (z. B. snake_case).
- Daten-Typen: Ein Attribut wie Alter wird zu einem
INToderSMALLINT. Ein E-Mail wird zu einemVARCHARmit einer bestimmten Längenbegrenzung. Ein Timestamp wirdTIMESTAMP MIT ZEITZONE. Diese Entscheidungen beeinflussen Speicherplatz und Abfrageleistung. - Beschränkungen: Hier wird die Logik des ERD durchgesetzt. Primärschlüssel (PK) sorgen für Eindeutigkeit. Fremdschlüssel (FK) gewährleisten die referenzielle Integrität zwischen Tabellen.
NICHT NULLBeschränkungen stellen sicher, dass Pflichtfelder ausgefüllt werden. Eindeutige Beschränkungen verhindern doppelte Einträge. - Indizes: Obwohl Indizes oft in hochstufigen ERDs weggelassen werden, bestimmt das Schema, wo Indizes erstellt werden. Indizes beschleunigen Lesevorgänge, verlangsamen aber Schreibvorgänge. Das Schema legt die physische Optimierung der Datenbank fest.
Das Schema ist auch für Sicherheit und Zugriffssteuerung verantwortlich. Es definiert, wer auf bestimmte Tabellen lesen oder schreiben darf. Es verwaltet Transaktionen und stellt sicher, dass Datenänderungen atomar sind. Wenn ein Entwickler eine Anweisung wie CREATE TABLEschreibt, definieren sie das Schema. Dies ist die Implementierungsebene, mit der der Anwendungscode direkt interagiert.
Wichtige Unterschiede im Überblick 📊
Um die Unterschiede klarzustellen, hilft es, die Unterschiede nebeneinander zu betrachten. Das ERD ist abstrakt und designorientiert, während das Schema konkret und implementierungsorientiert ist.
| Funktion | ERD (Entitäts-Beziehungs-Diagramm) | Datenbank-Schema |
|---|---|---|
| Art | Logisches / Konzeptuelles Modell | Physisches Modell |
| Schwerpunkt | Beziehungen und Datenfluss | Speicherung und Durchsetzung |
| Notation | Felder, Linien, Krähenfuß-Symbole | SQL-Anweisungen, DDL-Skripte |
| Abhängigkeit | Datenbankunabhängig | Datenbank-spezifisch (Hersteller) |
| Einschränkungen | Implizit (Geschäftsregeln) | Explizit (PK, FK, Prüfung) |
| Phase | Entwurfsphase | Entwicklungs-/Bereitstellungsphase |
Diese Tabelle zeigt, dass sie zwar miteinander verknüpft sind, aber in verschiedenen Phasen des Software-Lebenszyklus arbeiten. Die Verwechslung beider führt oft dazu, dass Entwickler physische Einschränkungen versuchen, auf ein logisches Modell aufzuprägen, bevor es vollständig validiert wurde.
Der Übersetzungsprozess: Von der Darstellung zum Code 🔄
Die Reise von der ERD zum Schema ist nicht immer eine direkte 1:1-Zuordnung. In dieser Übersetzungsphase stoßen viele Projekte auf Widerstände. Das logische Modell geht von idealen Bedingungen aus, während das physische Modell mit Leistung, veralteten Systemen und spezifischen Engine-Fähigkeiten umgehen muss.
Normalisierung gegenüber Leistung
Eine ERD ist typischerweise auf die Dritte Normalform (3NF) normalisiert. Dies minimiert die Daten-Duplikation. Bei der Übersetzung in ein Schema für eine Anwendung mit hohem Datenverkehr denormalisieren Entwickler jedoch oft. Das bedeutet, dass Daten absichtlich dupliziert werden, um die Anzahl der benötigten Joins bei einer Abfrage zu reduzieren. Zum Beispiel kann das Speichern des Kundenname direkt in der Tabelle BestellungTabelle, auch wenn dies strenge Normalisierungsregeln verletzt, kann die Abfragegeschwindigkeit für Berichte erheblich verbessern. Die ERD könnte eine Beziehung zeigen, aber das Schema könnte die Daten redundant speichern, um die Geschwindigkeit zu erhöhen.
Datentypspezifika
Ein ERD sagt einfach, dass ein Feld ein Datum. Das Schema muss entscheiden zwischen DATUM, DATUMZEIT, oder TIMESTAMP. Es muss sich für Zeichensätze (UTF8, ASCII) und Kollationsregeln entscheiden. Diese Entscheidungen beeinflussen, wie die Anwendung die Internationalisierung und Sortierung behandelt. Ein generisches ERD kann diese Feinheiten nicht erfassen.
Behandlung von Many-to-Many-Beziehungen
In einem ERD wird eine Many-to-Many-Beziehung als Linie mit doppelten Krähenfüßen dargestellt. In der physischen Schema kann dies nicht direkt existieren. Es muss in zwei One-to-Many-Beziehungen über eine Verbindungstabelle (oder Brückentabelle) aufgelöst werden. Das Schema muss den Primärschlüssel dieser Verbindungstabelle definieren, der entweder ein zusammengesetzter Schlüssel oder ein künstlicher Schlüssel (UUID) sein kann. Diese strukturelle Änderung ist in der hochstufigen Darstellung nicht sichtbar, ist aber entscheidend für die Datenbankstruktur.
Warum der Unterschied für Entwickler wichtig ist 🛠️
Das Verständnis der Lücke zwischen diesen beiden Konzepten geht nicht nur um Theorie; es beeinflusst die tägliche Arbeit. Wenn ein Fehler in der Datenintegrität auftritt, ist es der erste Schritt zur Lösung, zu wissen, ob das Problem in der logischen Gestaltung oder in der physischen Implementierung liegt.
Debuggen der Datenintegrität
Wenn Sie eine Situation erleben, bei der Daten unerwartet dupliziert werden, müssen Sie fragen: Ist das ERD fehlerhaft, oder fehlt eine Schema-Beschränkung? Ein fehlender Fremdschlüssel im Schema ermöglicht verwaiste Datensätze, die das ERD-Logik als unmöglich ansah. Umgekehrt könnte, wenn das ERD zu starr ist und keine weichen Löschungen berücksichtigt, das Schema harte Löschungen erzwingen, die die Geschäftslogik stören. Die Trennung der Anliegen ermöglicht es Ihnen, die Quelle des Fehlers genau zu identifizieren.
Versionskontrolle und Zusammenarbeit
Beim Verwalten einer Datenbank ist Versionskontrolle unverzichtbar. Allerdings entwickeln sich ERDs und Schemas unterschiedlich. Das ERD ändert sich, wenn sich die Geschäftsanforderungen ändern. Das Schema ändert sich, wenn die Datenbank optimiert werden muss oder wenn Migrationen angewendet werden. Ihre Synchronisation zu halten, ist eine Herausforderung. Wenn sich das Schema ändert, ohne dass das ERD aktualisiert wird, wird die Dokumentation veraltet. Wenn sich das ERD ändert, ohne dass ein Migrations-Skript vorhanden ist, bleibt die Datenbank mit dem Entwurf unvereinbar.
Einarbeitung neuer Teammitglieder
Neue Entwickler haben oft Schwierigkeiten, die Datenbankstruktur zu verstehen. Wenn man ihnen ein ERD zeigt, erhalten sie den Kontext, wie das System konzeptionell funktioniert. Wenn man ihnen das Schema zeigt, erhalten sie den Kontext, wie das System technisch funktioniert. Eine effektive Einarbeitung erfordert beides. Das ERD beantwortet „Was bedeutet das?“ und das Schema beantwortet „Wie kann ich darauf zugreifen?“.
Häufige Fehler bei der Datenmodellierung 🚧
Trotz der klaren Definitionen geraten viele Teams in Fallen, wenn sie ERD und Schema als identisch betrachten.
- Überspringen des ERD:Direkt mit dem Schreiben von SQL-Schemascripts zu beginnen führt oft zu strukturellem Verschuldung. Ohne ein visuelles Modell werden Beziehungen oft vergessen oder inkonsistent implementiert.
- Ignorieren von Beschränkungen:Sich ausschließlich auf den Anwendungscode zur Durchsetzung von Regeln (wie eindeutige E-Mails) zu verlassen, anstatt auf Datenbankbeschränkungen (UNIQUE-Indizes), ist riskant. Das Schema sollte die letzte Verteidigungslinie für die Datenintegrität sein.
- Überingenieurwesen: Erstellen eines ERDs, der zu detailliert ist und alle möglichen Attribute enthält, bevor die Anforderungen klar sind. Dies führt zu einer Schema, das später schwer zu migrieren ist.
- Tool-Abstand: Verwenden eines Design-Tools, das keine Codegenerierung unterstützt, oder Verwenden eines Datenbank-Tools, das keine Reverse-Engineering-Funktionen bietet. Dies erzeugt eine manuelle Lücke, in der Änderungen an einer Stelle vorgenommen werden, aber nicht an der anderen.
- Annahme der Äquivalenz: Glauben, dass ein perfektes ERD eine perfekte Datenbank garantiert. Das Schema ist eingeschränkt durch Hardware-Beschränkungen, Abfrage-Muster und Konkurrenzprobleme, die das ERD nicht vorhersehen kann.
Aufrechterhaltung der Synchronisation über die Zeit 🔄
Je mehr sich eine Anwendung entwickelt, desto mehr entwickelt sich auch die Datenbank. Funktionen werden hinzugefügt und alte Funktionen werden abgeschaltet. Die Aufrechterhaltung der Verbindung zwischen dem ERD und dem Schema wird mit der Zeit schwieriger. Dies wird oft alsSchema-Drift.
Um dies zu bekämpfen, sollten Teams einen strikten Arbeitsablauf anwenden:
- Design zuerst: Aktualisieren Sie immer das ERD, bevor Sie Migrations-Skripte schreiben.
- Generierung automatisieren: Verwenden Sie Werkzeuge, die SQL-DDL aus dem ERD generieren können. Dadurch wird sichergestellt, dass das Schema mit dem Design übereinstimmt.
- Reverse Engineering: Führen Sie regelmäßig Reverse-Engineering-Werkzeuge auf der laufenden Datenbank aus, um das ERD zu aktualisieren. Dadurch werden Änderungen erfasst, die durch direkte SQL-Abfragen vorgenommen wurden, die den Gestaltungsprozess umgehen.
- Dokumentation: Stellen Sie sicher, dass das ERD im selben Repository wie die Schema-Migrations-Skripte gespeichert ist. Dadurch entsteht eine einzige Quelle der Wahrheit.
Diese Disziplin verhindert, dass die Datenbank zu einer Black Box wird. Wenn ERD und Schema synchronisiert sind, bleibt das System transparent und verwaltbar.
Einfluss auf die Abfrageleistung und Optimierung ⚡
Das Schema bestimmt die Leistung stärker als das ERD. Während das ERD Beziehungen zeigt, bestimmt das Schema, wie der Datenbank-Engine auf die Daten zugreift. Ein ERD könnte eine logische Verknüpfung zwischenBenutzer und Beiträge. Das Schema bestimmt, ob ein Index auf derBenutzer_ID in derBeiträgeTabelle existiert.
Ohne eine angemessene Indizierung im Schema kann eine einfache Abfrage eine vollständige Tabellen-Suche auslösen. Dies ist eine physische Beschränkung. Das ERD kann Ihnen den Ausführungsplan nicht zeigen. Entwickler müssen das Schema betrachten, um zu verstehen, warum eine Abfrage langsam ist. Sie müssen die Indizes, die Partitionierungsstrategie und die Datentypen analysieren.
Darüber hinaus handhabt das Schema Sperrmechanismen. Wenn mehrere Benutzer dasselbe Datensatz aktualisieren, bestimmen das Isolationsniveau und die Sperrstrategie des Schemas, ob sie sich gegenseitig blockieren. Das ERD sagt nichts zur Konkurrenzfähigkeit aus. Dies ist ein entscheidender Unterschied für Systeme mit hoher Last.
Brückenbildung mit Best Practices 🏆
Um sicherzustellen, dass beide Modelle ihre Aufgabe effektiv erfüllen, sollten Sie diese Standards übernehmen:
- Verwenden Sie standardisierte Namenskonventionen:Stellen Sie sicher, dass die Tabellennamen im Schema den Entitätsnamen im ERD entsprechen. Konsistenz verringert die kognitive Belastung.
- Beschränkungen explizit dokumentieren:Im ERD markieren Sie Beziehungen mit Kardinalität. Im Schema markieren Sie Spalten mit ihren Beschränkungen. Stellen Sie sicher, dass die Regeln an beiden Stellen sichtbar sind.
- Regelmäßig überprüfen:Planen Sie vierteljährliche Überprüfungen des ERD im Vergleich zum Produktivschema. Suchen Sie nach Abweichungen und Anomalien.
- Anliegen trennen:Behandeln Sie das ERD als geschäftliches Artefakt und das Schema als technisches Artefakt. Mischen Sie keine Geschäftslogik in die physischen Schema-Definitionen.
- Planung für Migration: Wenn sich das ERD ändert, muss das Schema über ein Migrations-Skript geändert werden. Ändern Sie das Schema niemals direkt in der Produktion, ohne ein versioniertes Skript.
Das menschliche Element der Datenmodellierung 👥
Letztendlich werden diese Modelle für Menschen geschaffen, nicht nur für Maschinen. Das ERD dient der Kommunikation. Es ermöglicht einem Produktmanager, die Datenstruktur zu verstehen, ohne SQL zu kennen. Das Schema ist für die Maschine. Es ermöglicht der Anwendung, Daten effizient abzurufen.
Wenn Entwickler diese Unterscheidung zwischen Mensch und Maschine verstehen, können sie bessere Systeme gestalten. Sie wissen, wann sie das ERD für Stakeholder vereinfachen und wann sie das Schema für die Datenbank-Engine detaillieren müssen. Diese Dualität ist das Wesen der Datenbankarchitektur.
Durch die Achtung der Grenze zwischen dem logischen Diagramm und der physischen Implementierung vermeiden Teams die häufigen Fallen der Datenkorruption und Leistungsengpässe. Das ERD liefert die Vision; das Schema liefert die Realität. Beide sind für ein erfolgreiches System erforderlich.
Abschließende Gedanken zur Datenarchitektur 🧠
Der Unterschied zwischen einem Entitäts-Beziehungs-Diagramm und einem Datenbankschema ist ein grundlegender Säule der Softwaretechnik. Er repräsentiert die Übergangsphase von Gedanken zu Handlung, von Idee zur Umsetzung. Während das ERD die Beziehungen und Logik erfasst, die das Geschäft antreiben, erfasst das Schema die Beschränkungen und Strukturen, die die Anwendung antreiben.
Die Beherrschung der Beziehung zwischen diesen beiden Modellen geht nicht darum, Definitionen auswendig zu lernen. Es geht darum, den Lebenszyklus der Daten zu verstehen. Es geht darum zu wissen, dass eine Änderung im Diagramm eine Änderung im Code erfordert, und dass eine Änderung im Code wiederum in das Diagramm zurückfließen muss. Dieser Zyklus stellt sicher, dass das System kohärent, zuverlässig und skalierbar bleibt.
Bleiben Sie bei Ihrer Entwicklung auf dem Weg diese beiden Modelle klar voneinander getrennt. Verwenden Sie das ERD zur Planung und Kommunikation. Verwenden Sie das Schema zum Aufbau und zur Durchsetzung. Wenn Sie sie ausrichten, bauen Sie Systeme, die der Zeit und Veränderungen standhalten.
Denken Sie daran, dass das Ziel nicht nur darin besteht, Daten zu speichern, sondern sie so zu speichern, dass es Sinn ergibt. Dieser Sinn kommt aus der logischen Klarheit des ERD und der strukturellen Strenge des Schemas. Zusammen bilden sie die Grundlage Ihrer Datenarchitektur.