









Die Gestaltung eines robusten Datenbank-Schemas ist eine der wichtigsten Aufgaben in der Softwareentwicklung. Ein Entitäts-Beziehungs-Diagramm (ERD) dient als Bauplan für Ihre Datenarchitektur. Wenn die Grundlage fehlerhaft ist, wird die darauf aufbauende Anwendung mit Leistung, Datenintegrität und Skalierbarkeit kämpfen. Bevor Sie ein Datenbankmodell an Entwickler oder Bereitstellungsteams übergeben, ist ein strenger Überprüfungsprozess unerlässlich. Diese Anleitung beschreibt zehn wesentliche Schritte zur Validierung Ihres ERD, um sicherzustellen, dass Ihre Datenstruktur für die Produktion bereit ist.
Ein gut strukturiertes ERD minimiert Redundanz, setzt Einschränkungen durch und klärt die Beziehungen zwischen Datenentitäten. Das Überspringen von Validierungsschritten führt oft zu kostspieligen Umgestaltungen später im Entwicklungszyklus. Diese Prüfliste behandelt Namenskonventionen, Normalisierung, Einschränkungen und Dokumentationsstandards. Folgen Sie diesen Schritten, um sicherzustellen, dass Ihr Modell zuverlässig und wartbar ist.
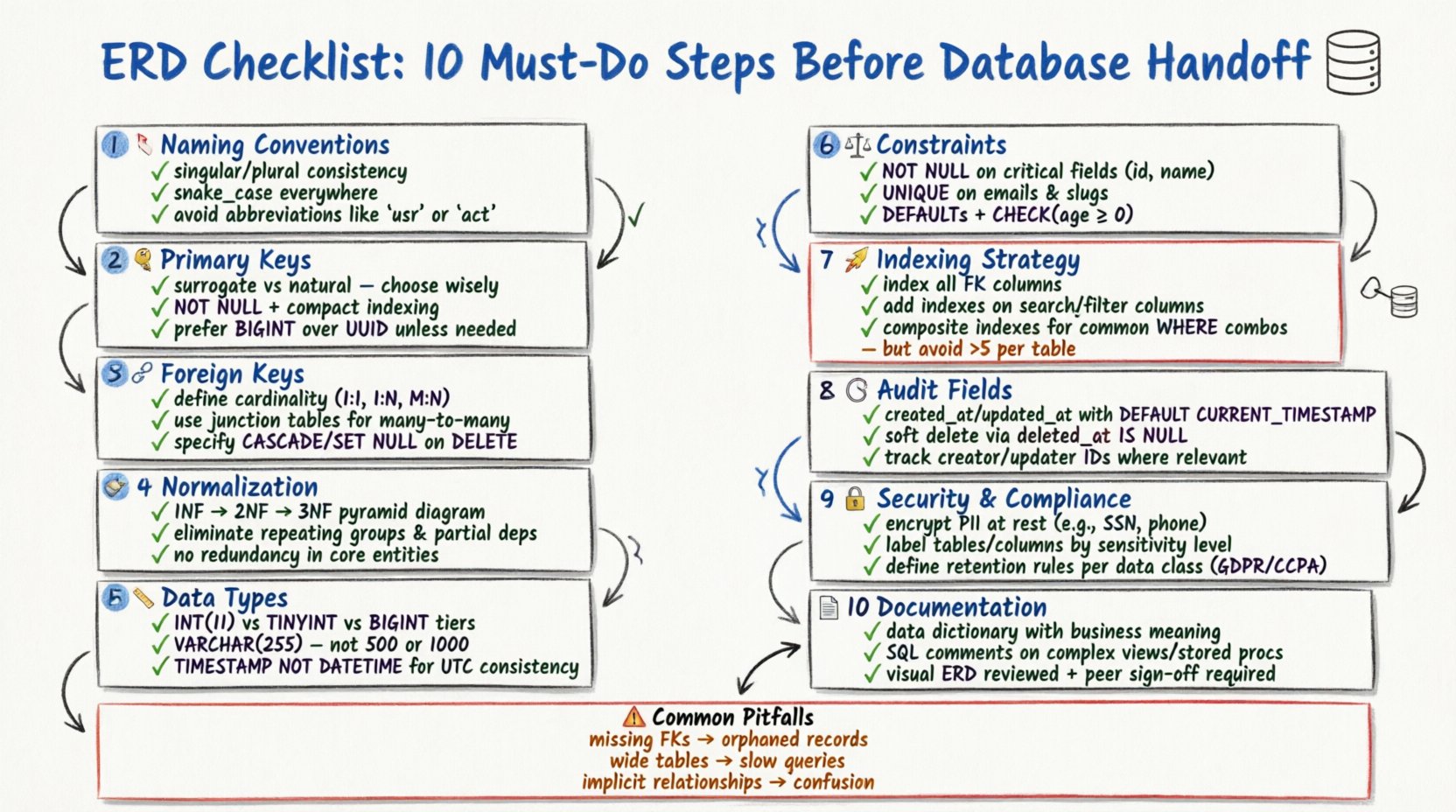
1. Überprüfen Sie die Namenskonventionen für Entitäten 🏷️
Konsistenz bei der Benennung ist die erste Verteidigungslinie gegen Verwirrung. Jede Tabelle (Entität) und jeder Spalte (Attribut) muss einer standardisierten Namenskonvention folgen. Inkonsistente Namen führen bei der Erstellung und Wartung von SQL-Abfragen zu Mehrdeutigkeiten.
- Verwenden Sie einheitlich Singular oder Plural:Wählen Sie einen Stil für Tabellennamen (z. B.
BenutzervsBenutzer) und wenden Sie ihn durchgehend im Schema an. Singular-Namen werden im Allgemeinen für das konzeptionelle Modell bevorzugt, während Plural-Namen oft für die physische Implementierung verwendet werden. - Vermeiden Sie reservierte Schlüsselwörter:Stellen Sie sicher, dass keine Entitäts- oder Spaltenname mit datenbank-spezifischen reservierten Wörtern kollidiert (z. B.
Bestellung,Gruppe,Index). Die Verwendung reservierter Wörter erfordert oft das Escapen von Zeichen, was die Lesbarkeit des Codes verringert. - Verwenden Sie Unterstriche als Trennzeichen:Übernehmen Sie die snake_case-Namenskonvention für Spalten und Tabellen (z. B.
benutzer_profil) um die Lesbarkeit über verschiedene Datenbank-Engines hinweg zu gewährleisten. - Vermeiden Sie Abkürzungen:Vermeiden Sie Abkürzungen, es sei denn, sie sind allgemein verständlich.
kunde_idist besser alsknd. Klarheit sollte immer Vorrang vor Kürze haben.
2. Definieren Sie eine Strategie für Primärschlüssel 🔑
Jede Tabelle muss einen eindeutigen Bezeichner haben, um Datensätze zu unterscheiden. Die Wahl des Primärschlüssels beeinflusst die Leistung, das Indexing und die Datenbeziehungen.
- Schein-Schlüssel im Vergleich zu natürlichen Schlüsseln: Entscheiden Sie, ob Sie einen Scheinschlüssel (eine künstliche ID wie eine automatisch erhöhende Ganzzahl oder UUID) oder einen natürlichen Schlüssel (Daten, die bereits existieren, wie eine E-Mail-Adresse) verwenden möchten. Scheinschlüssel werden oft aufgrund ihrer Stabilität bevorzugt, da natürliche Schlüssel im Laufe der Zeit ändern können.
- Auswirkungen auf das Indexing:Primärschlüssel werden automatisch indiziert. Stellen Sie sicher, dass der gewählte Schlüsseltyp kompakt ist. Große Schlüssel (wie lange Zeichenketten) können Indizes vergrößern und die Join-Operationen verlangsamen.
- Eindeutigkeitsbeschränkungen: Markieren Sie die Primärschlüsselspalte explizit als
NICHT NULL. Ein Primärschlüssel darf unter keinen Umständen NULL-Werte enthalten. - Zusammengesetzte Schlüssel: Wenn eine Tabelle einen zusammengesetzten Primärschlüssel (mehrere Spalten) erfordert, stellen Sie sicher, dass jede Beziehung, die auf diese Tabelle verweist, mehrere Spalten verarbeiten kann. Dies kann die Fremdschlüsselbeschränkungen komplizierter machen.
3. Fremdschlüssel-Beziehungen abbilden 🔗
Beziehungen definieren, wie Entitäten miteinander interagieren. Eine falsche Zuordnung von Beziehungen führt zu Datenverwaischung und Verletzungen der Referenzintegrität.
- Kardinalität: Definieren Sie klar, ob eine Beziehung Eins-zu-Eins, Eins-zu-Viele oder Viele-zu-Viele ist. Eins-zu-Viele ist das häufigste Muster in relationalen Datenbanken.
- Lösung von Viele-zu-Viele-Beziehungen: Eine Viele-zu-Viele-Beziehung erfordert eine Verbindungstabelle (Link-Tabelle). Stellen Sie sicher, dass diese Tabelle die Fremdschlüssel beider übergeordneter Entitäten enthält und gegebenenfalls eigene Attribute besitzt.
- Referenzielle Aktionen: Geben Sie an, wie die Datenbank Updates oder Löschungen behandeln soll. Häufige Optionen sind
CASCADE(löschen der Kinddatensätze),SET NULL, oderRESTRICT(Löschung verhindern). Wählen Sie basierend auf den Anforderungen der Geschäftslogik. - Selbstreferenzierung: Wenn eine Tabelle sich selbst referenziert (z. B. eine Mitarbeiter-Tabelle mit einer Spalte für den Vorgesetzten), markieren Sie diese Beziehung klar, um Verwirrung während der Schema-Überprüfung zu vermeiden.
4. Daten-Normalisierungsregeln anwenden 🧹
Die Normalisierung reduziert Datenredundanz und verbessert die Integrität. Obwohl moderne Systeme manchmal zur Leistungssteigerung auf Normalisierung verzichten, ist das Verständnis der Normalformen entscheidend.
| Normalform | Anforderung | Vorteil |
|---|---|---|
| 1NF (Erste Normalform) | Atomare Werte, keine wiederholenden Gruppen | Stellt sicher, dass jede Zelle einen einzelnen Wert enthält |
| 2NF (Zweite Normalform) | Keine partiellen Abhängigkeiten | Stellt sicher, dass nicht-schlüsselbasierte Spalten vom gesamten Schlüssel abhängen |
| 3NF (Dritte Normalform) | Keine transitiven Abhängigkeiten | Stellt sicher, dass nicht-schlüsselbasierte Spalten nur vom Schlüssel abhängen |
- Vermeiden Sie Redundanz: Wenn ein Informationsteil in mehreren Tabellen gespeichert ist, sollte er an einer Stelle gespeichert werden, um Aktualisierungsanomalien zu vermeiden.
- Gleichgewicht mit Leistung: Strenges Normalisieren kann zu komplexen Joins führen. Dokumentieren Sie alle bewussten Entscheidungen zur De-Normalisierung, die zur Optimierung von Abfragen getroffen wurden.
- Prüfen Sie Datenabhängigkeiten: Stellen Sie sicher, dass Spalten logisch vom Primärschlüssel abhängen und nicht von anderen nicht-schlüsselbasierten Spalten.
5. Wählen Sie geeignete Datentypen 📏
Die Auswahl des falschen Datentyps verschwendet Speicherplatz und kann zu Berechnungsfehlern führen.
- Ganzzahlpunktzahl: Verwenden Sie
TINYINTfür kleine Zahlen (0-255) undBIGINTfür große Bezeichner. Verwenden Sie nichtINTfür alles, wennSMALLINTausreicht. - Zeichenfolgenlängen: Verwenden Sie keine generischen
TEXToderVARCHAR(MAX)es sei denn, es ist unbedingt notwendig. Definieren Sie spezifische Längen (z. B.VARCHAR(50)für einen Bundeslandcode) um Datenbeschränkungen durchzusetzen und die Effizienz der Indizierung zu verbessern. - Datum und Uhrzeit: Verwenden Sie
TIMESTAMPoderDATETIMEje nach Zeitzoneanforderungen. Stellen Sie sicher, dass das Format konsistent ist (ISO 8601 ist ein Standard). Vermeiden Sie das Speichern von Daten als Zeichenketten. - Boolesche Werte: Verwenden Sie einen nativen booleschen Typ, falls verfügbar. Andernfalls verwenden Sie
TINYINT(1)oderCHAR(1). Vermeiden Sie das Speichern boolescher Werte als Zeichenketten („ja“/„nein“).
6. Setzen Sie Einschränkungen und Standardwerte durch ⚖️
Einschränkungen schützen die Datenqualität auf Datenbankebene. Die alleinige Abhängigkeit von Validierungen auf Anwendungsebene ist riskant.
- Nicht null: Markieren Sie kritische Spalten als
NICHT NULL. Dies verhindert, dass fehlende Daten Berichte oder Logik beschädigen. - Eindeutige Einschränkungen: Wenden Sie eindeutige Einschränkungen auf Spalten wie E-Mail-Adressen oder Benutzernamen an, um doppelte Einträge zu verhindern.
- Standardwerte: Legen Sie sinnvolle Standardwerte für Statusspalten fest (z. B.
status = 'aktiv') oder Zeitstempel, um manuelle Eingabefehler zu vermeiden. - Prüfbeschränkungen: Verwenden Sie Prüfbeschränkungen, um Geschäftsregeln zu überprüfen (z. B.
Alter > 18oderPreis > 0). Dadurch wird sichergestellt, dass die Daten unabhängig von der Quelle logischen Regeln folgen.
7. Planen Sie die Indizierungsstrategie 🚀
Indizes beschleunigen die Datenabrufung, verlangsamen aber Schreibvorgänge. Ein ausgewogener Ansatz ist erforderlich.
- Fremdschlüssel-Indizes: Indizieren Sie immer Fremdschlüsselspalten. Dies ist entscheidend für die Leistung von Join-Vorgängen zwischen Tabellen.
- Suchspalten: Identifizieren Sie Spalten, die häufig in
WHERE,ORDER BY, oderGROUP BYKlauseln verwendet werden. Fügen Sie Indizes für diese Spalten hinzu. - Komposite Indizes: Wenn Abfragen auf mehreren Spalten filtern, erstellen Sie einen kompositen Index. Die Reihenfolge der Spalten im Index ist wichtig und sollte den Abfragemustern entsprechen.
- Vermeiden Sie übermäßiges Indizieren: Zu viele Indizes erhöhen den Speicherplatzbedarf und verlangsamen
INSERT,UPDATE, undDELETEVorgänge. Überprüfen Sie die Notwendigkeit jedes Indexes.
8. Include Audit-Felder 🕒
Die Rückverfolgbarkeit ist für die Fehlerbehebung und die Einhaltung von Vorschriften von entscheidender Bedeutung. Jede Tabelle, die Geschäftslogik verarbeitet, sollte Änderungen verfolgen.
- Erstellt am: Fügen Sie eine
created_atSpalte hinzu, um den Zeitpunkt der ersten Einfügung eines Datensatzes zu erfassen. - Zuletzt aktualisiert am: Fügen Sie eine
updated_atSpalte hinzu, um die letzte Änderungszeit zu erfassen. - Weiche Löschungen: Anstatt eine dauerhafte Löschung vorzunehmen, erwägen Sie, eine
deleted_atSpalte hinzuzufügen. Dadurch kann die Daten bei Bedarf wiederhergestellt werden, und die Referenzintegrität wird gewahrt. - Wer hat geändert: Für kritische Audit-Protokolle sollten Sie eine
created_byundupdated_bySpalte hinzufügen, um die Benutzer-ID zu speichern, die für die Aktion verantwortlich ist.
9. Sicherheit und Compliance berücksichtigen 🔒
Datensicherheit muss in das Schema integriert sein, nicht als nachträgliche Maßnahme hinzugefügt werden.
- Umgang mit personenbezogenen Daten (PII):Identifizieren Sie personenbezogene Informationen (PII), wie Sozialversicherungsnummern, Kreditkartennummern oder Gesundheitsdaten. Diese sollten verschlüsselt oder tokenisiert werden.
- Datenklassifizierung:Markieren Sie sensible Spalten in der Schema-Dokumentation, damit Entwickler wissen, welche Felder zusätzliche Sicherheitsmaßnahmen erfordern.
- Zugriffssteuerung:Obwohl spezifische Berechtigungen oft auf Anwendungs- oder Datenbankbenutzerebene festgelegt werden, sollte das Schema die Datensensibilität widerspiegeln (z. B. getrennte Tabellen für öffentliche und private Daten).
- Aufbewahrungsrichtlinien:Stellen Sie sicher, dass das Schema die Anforderungen an die Datenaufbewahrung unterstützt. Einige Rechtsgebiete verlangen die Löschung von Daten nach einer bestimmten Frist.
10. Dokumentieren und Validieren des Schemas 📄
Ein Schema ohne Dokumentation ist eine Gefahr. Die Dokumentation stellt die zukünftige Wartbarkeit sicher.
- Datensatzverzeichnis:Führen Sie ein Dokument, das jede Tabelle, jedes Feld und jede Beziehung beschreibt. Fügen Sie für jedes Feld geschäftliche Definitionen hinzu.
- Kommentare:Verwenden Sie SQL-Kommentare innerhalb der DDL-(Data Definition Language)-Skripte, um komplexes Logik oder spezifische Geschäftsregeln zu erklären.
- Visuelle Überprüfung:Generieren Sie die ERD visuell, um auf zirkuläre Referenzen, verwaiste Tabellen oder fehlende Beziehungen zu prüfen.
- Peer-Review:Lassen Sie ein weiterer Architekt oder Senior-Entwickler das Modell überprüfen. Ein frischer Blick erfasst oft logische Fehler, die bei der ursprünglichen Gestaltung übersehen wurden.
Häufige Modellierungsfehler und Lösungen 🛠️
Die Überprüfung der Checkliste reicht nicht aus. Sie müssen sich auch der häufigen Fallen bewusst sein.
| Fehler | Folge | Lösung |
|---|---|---|
| Fehlende Fremdschlüssel | Verwaiste Datensätze, Dateninkonsistenz | Fügen Sie explizite Fremdschlüsselbeschränkungen hinzu |
| Breite Tabellen | Schwer lesbar, langsame Abfragen | Aufteilen in verwandte Tabellen (Normalisierung) |
| Implizite Beziehungen | Verwirrung während der Entwicklung | Zeichnen Sie explizite Linien in der ERD, fügen Sie FK-Spalten hinzu |
| Null-Wert-Probleme | Logische Fehler in der Anwendung | Setzen Sie NICHT NULL wo Daten erforderlich sind |
| Hartkodierte IDs | Schwierigkeiten bei der Migration | Verwenden Sie Fremdschlüssel anstelle von fest codierten IDs |
Abschließende Gedanken zur Schema-Design 🎯
Die Erstellung eines Datenbankmodells ist ein Ausgleich zwischen strenger Integrität und praktischer Leistungsfähigkeit. Die Einhaltung dieser Prüfliste stellt sicher, dass Ihre Datenstruktur die geschäftlichen Anforderungen erfüllt, ohne die Qualität zu beeinträchtigen. Nehmen Sie sich die Zeit, jeden Schritt zu überprüfen, bevor Sie das Schema in die Versionskontrolle übertragen. Ein paar Stunden, die für die Validierung des ERD aufgewendet werden, können später Wochen an Debugging und Umgestaltung ersparen.
Denken Sie daran, dass ein Datenbankmodell ein lebendiges Dokument ist. Sobald sich die geschäftlichen Anforderungen ändern, muss das Schema sich weiterentwickeln. Regelmäßige Überprüfungen anhand dieser Prüfliste halten Ihre Datenarchitektur gesund und richten sie an Ihren Zielen aus. Priorisieren Sie in jeder Entscheidung Klarheit, Konsistenz und Integrität.
Durch die Einhaltung dieser zehn Schritte legen Sie eine solide Grundlage für Ihre Anwendung. Ihr Team wird die Klarheit schätzen, und Ihre Produktionsumgebung profitiert von weniger Fehlern und besserer Leistung. Machen Sie die Prüfliste zu einem festen Bestandteil Ihres Entwicklungsprozesses.