






Die Entwicklung von Software ist wie der Bau eines Hochhauses. Man kann mit einer stabilen Grundlage beginnen, aber wenn die Baupläne unklar sind, wackelt die Struktur letztendlich. In der Welt der Softwareentwicklung ist Daten die Grundlage. Ohne einen klaren Plan sammelt sich Daten zu einem verwirrenden Durcheinander, das die Leistung verlangsamt, Funktionen beschädigt und Entwickler frustriert. Genau hier setzt das Entity-Relationship-Diagramm (ERD) ein. Ein ERD ist nicht nur eine Zeichnung; es ist der architektonische Bauplan für Ihre Datenhaltung. Es zeigt auf, wie Daten miteinander verbunden sind, und stellt sicher, dass Ihre Datenbank auch bei der Skalierung Ihrer Anwendung stabil und zuverlässig bleibt.
Wenn Anwendungen wachsen, steigt die Komplexität der Datenbeziehungen exponentiell. Ein einfacher Start könnte eine einzelne Tabelle für Benutzer beinhalten, aber bald benötigen Sie Bestellungen, Produkte, Zahlungen und Protokolle. Ohne eine formelle Struktur werden diese Tabellen zu Inseln aus Informationen, die nicht korrekt miteinander kommunizieren. Dies führt zu Datenredundanz, Integritätsfehlern und langen Abfragezeiten. Indem Sie ein ERD frühzeitig nutzen und es während des gesamten Lebenszyklus pflegen, schaffen Sie eine einzigartige Quelle der Wahrheit, die jeden Aspekt der Datenverwaltung leitet.
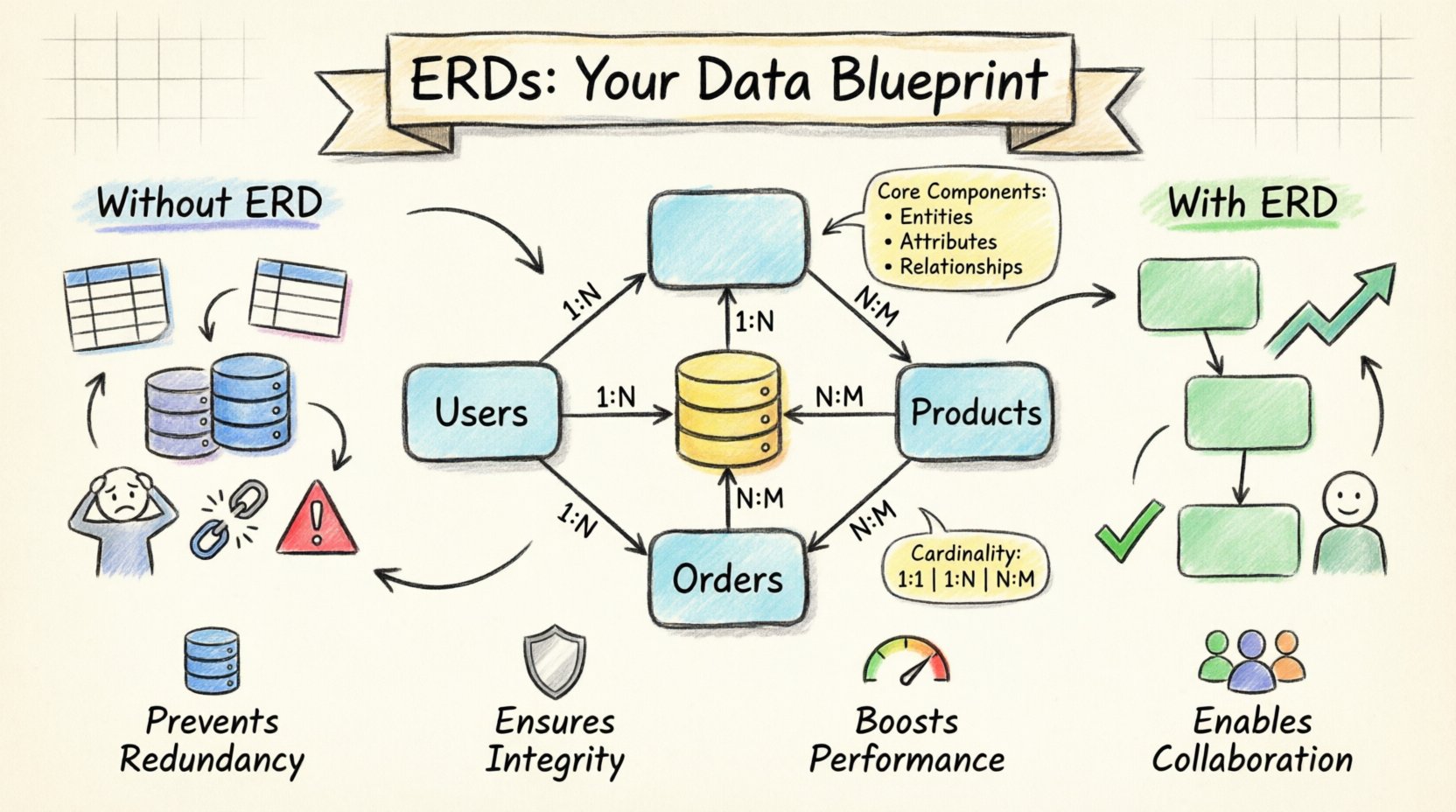
🧩 Das Verständnis der zentralen Bestandteile eines ERDs
Um zu verstehen, wie ein ERD Chaos verhindert, muss man verstehen, aus welchen Bestandteilen das Diagramm besteht. Es ist eine visuelle Darstellung der Datenbankstruktur, die abstrakte geschäftliche Anforderungen in konkrete technische Beschränkungen übersetzt. Jedes Diagramm besteht aus drei grundlegenden Elementen, die gemeinsam dafür sorgen, dass Ordnung herrscht.
- Entitäten: Diese stellen Gegenstände oder Konzepte der realen Welt dar, die Sie verfolgen. In einer Datenbank wird eine Entität typischerweise zu einer Tabelle. Häufige Beispiele sindBenutzer, Bestellungen, undProdukte.
- Attribute: Dies sind die spezifischen Details, die eine Entität beschreiben. Für eineBenutzerEntität könnten Attribute beinhaltenBenutzername, E-Mail, understellt_am. Attribute werden zu Spalten innerhalb der Tabelle.
- Beziehungen: Dies ist der entscheidende Punkt, um Chaos zu verhindern. Beziehungen definieren, wie Entitäten miteinander interagieren. Ein Benutzer stellt eine Bestellung auf. Eine Bestellung enthält Produkte. Diese Verbindungen werden durch Linien dargestellt, die die Entitäten verbinden, oft mit einer Angabe der Kardinalität (z. B. ein-zu-viele).
Wenn diese Komponenten klar definiert werden, bevor eine einzige Codezeile geschrieben wird, vermeidet das Entwicklungsteam Ratespiele. Jeder weiß genau, welche Daten benötigt werden und wie sie mit anderen Daten verknüpft sind. Diese Klarheit reduziert Fehlerphase während der Implementierung erheblich.
🌪️ Die Mechanik des Datenchaos
Was passiert eigentlich, wenn man die ERD-Phase überspringt? Es ist leicht zu denken: „Ich kann einfach Tabellen hinzufügen, wenn ich sie brauche.“ Kurzfristig fühlt sich das effizient an. Langfristig erzeugt es jedoch eine Schuldenlast, die sich mit der Zeit vergrößert. Hier ist eine Aufschlüsselung der spezifischen Probleme, die ohne ein strukturiertes Datenmodell auftreten.
1. Redundanz und Duplikation
Ohne ein klares Schema kopieren Entwickler oft Daten, um Funktionen schnell zu realisieren. Sie könnten den Namen eines Kunden sowohl in der Tabelle Bestellungen als auch in der Tabelle Kunden speichern. Wenn sich der Name des Kunden ändert, müssen Sie ihn an zwei Stellen aktualisieren. Wenn Sie eine Stelle übersehen, wird Ihre Datenbasis inkonsistent. Ein ERD setzt die Normalisierung durch, sodass Daten an nur einer logischen Stelle gespeichert werden.
2. Verletzungen der Referenziellen Integrität
Dies tritt auf, wenn eine Verbindung zwischen Datenpunkten unterbrochen ist. Zum Beispiel existiert eine Bestellung in der Datenbank, aber der Benutzer, der sie aufgegeben hat, wurde gelöscht. Ohne eine Fremdschlüsselbeschränkung, die im ERD definiert ist, erlaubt die Datenbank diesen verwaisten Datensatz, weiterhin vorhanden zu bleiben. Dies führt zu defekten Berichten und verwirrenden UI-Zuständen, bei denen Daten auf nichts verweisen.
3. Leistungsverschlechterung bei Abfragen
Je größer das Datenvolumen wird, desto wichtiger ist die Art und Weise, wie Sie darauf zugreifen. Ein schlecht strukturiertes Schema fehlt an Indizes oder logischen Gruppierungen. Joins werden kostspielig und verlangsamen die gesamte Anwendung. Ein ERD hilft Ihnen, visuell darzustellen, wo Indizes platziert werden sollten, basierend darauf, wie oft die Daten zugegriffen werden.
4. Kooperationskonflikte
Wenn die Datenstruktur nicht dokumentiert ist, verbringen Entwickler Stunden damit, herauszufinden, was ein Spaltenname bedeutet oder warum eine bestimmte Tabelle existiert. Dies verlangsamt die Einarbeitung und die Entwicklung neuer Funktionen. Ein Diagramm dient als visueller Vertrag zwischen dem Produktteam und dem Engineering-Team.
📐 Strategische Umsetzung: Aufbau der Grundlage
Die Erstellung eines ERDs ist kein einmaliger Vorgang. Es ist ein strategischer Prozess, der sich mit dem Unternehmen entwickelt. Ziel ist es, Flexibilität mit Struktur zu balancieren. Hier ist, wie Sie die Erstellung einer robusten Datenbankstruktur angehen können.
- Beginnen Sie mit den Geschäftsanforderungen:Bevor Sie über Tabellen nachdenken, denken Sie über das Geschäft nach. Was sind die zentralen Objekte? Wer sind die Akteure? Welche Transaktionen finden statt? Dadurch wird sichergestellt, dass das technische Modell mit der realen Nutzung übereinstimmt.
- Definieren Sie Primärschlüssel:Jede Tabelle benötigt einen eindeutigen Bezeichner. Dies ist der Anker für alle Beziehungen. Entscheiden Sie, ob Sie natürliche Schlüssel (wie eine E-Mail-Adresse) oder künstliche Schlüssel (wie eine automatisch hochzählende ID) verwenden. Künstliche Schlüssel werden im Allgemeinen aufgrund ihrer Stabilität bevorzugt.
- Bestimmen Sie die Kardinalität:Bestimmen Sie die Art der Beziehungen. Ist es Eins-zu-Eins? Eins-zu-Viele? Oder Viele-zu-Viele? Dies bestimmt, wie Sie die Fremdschlüssel und Verbindungstabellen gestalten.
- Wenden Sie Normalisierung an:Streben Sie bei geeigneten Gelegenheiten die Dritte Normalform (3NF) an. Dadurch wird Redundanz minimiert. Stellen Sie sicher, dass nicht-schlüsselbasierte Attribute sich ausschließlich auf den Primärschlüssel beziehen.
Berücksichtigen Sie die folgenden gängigen Beziehungstypen und ihre Darstellung in einem Diagramm.
| Beziehungstyp | Beschreibung | Implementierungsstrategie |
|---|---|---|
| Eins-zu-Eins (1:1) | Ein Datensatz in Tabelle A steht genau mit einem Datensatz in Tabelle B in Beziehung. | Platzieren Sie einen Fremdschlüssel in einer der beiden Tabellen. |
| Eins-zu-Viele (1:N) | Ein Datensatz in Tabelle A steht mit mehreren Datensätzen in Tabelle B in Beziehung. | Platzieren Sie einen Fremdschlüssel in Tabelle B, der auf Tabelle A verweist. |
| Viele-zu-Viele (N:M) | Mehrere Datensätze in Tabelle A stehen mit mehreren Datensätzen in Tabelle B in Beziehung. | Erstellen Sie eine Verbindungstabelle (Brücke), die Fremdschlüssel aus beiden Tabellen enthält. |
🚀 Skalierung mit dem ERD
Anwendungen bleiben nicht statisch. Sie wachsen. Funktionen werden hinzugefügt, die Benutzerbasis erweitert sich und das Datenvolumen nimmt zu. Ein statisches Diagramm könnte veraltet werden, aber ein lebendiges ERD passt sich an. Wie hilft ein ERD während der Skalierungsphase?
- Identifizieren von Engpässen: Wenn Sie das Diagramm überprüfen, könnten Sie feststellen, dass eine bestimmte Tabelle zum Schwerpunkt wird. Dies deutet auf die Notwendigkeit von Partitionierung oder Sharding hin. Die visuelle Anordnung hilft Ihnen, dort zu erkennen, wo die Last konzentriert ist.
- Planung von Migrationen: Wenn Sie eine Änderung am Schema vornehmen müssen (z. B. Aufteilung einer Tabelle), zeigt Ihnen das ERD alle abhängigen Beziehungen. Sie können die Migration planen, um sicherzustellen, dass während des Übergangs keine Fremdschlüsselbeschränkungen verletzt werden.
- Architektonische Entscheidungen: Manchmal verschieben sich die Datenanforderungen von relational zu nicht-relational. Ein ERD hilft Ihnen, die zentralen Beziehungen zu verstehen, die erhalten bleiben müssen, auch wenn sich die zugrundeliegende Technologie ändert.
Zum Beispiel, wenn Sie sich entscheiden, eine Caching-Schicht einzuführen, müssen Sie wissen, welche Daten stark gelesen werden. Das ERD hebt die Entitäten hervor, die für die Anwendung zentral sind, und leitet Sie an, was gecacht und was im primären Speicher belassen werden sollte.
🛠️ Wartung und Evolution
Das Erstellen des Diagramms ist nur die halbe Miete. Der echte Wert liegt darin, es aktuell zu halten. Ein Diagramm, das nicht mit der tatsächlichen Datenbank übereinstimmt, ist schlimmer als gar kein Diagramm, da es falsche Sicherheit erzeugt. Hier sind Best Practices für die Wartung.
- Versionskontrolle: Behandeln Sie das ERD wie Code. Speichern Sie es in Ihrem Repository. Commiten Sie Änderungen, wenn Schemaänderungen vorgenommen werden. Dadurch entsteht eine Nachverfolgung der Entwicklung des Datenmodells im Laufe der Zeit.
- Überprüfungszyklen: Integrieren Sie die Überprüfung des Schemas in Ihre Sprint-Planung. Überprüfen Sie die Datenbankmigration vor der Bereitstellung anhand des Diagramms. So werden Abweichungen erkannt, bevor sie in die Produktion gelangen.
- Dokumentationsstandards: Verwenden Sie konsistente Namenskonventionen. Vermeiden Sie verschlüsselte Abkürzungen. Wenn ein Tabellenname ist
tbl_usr, ändern Sie ihn inusers. Konsistenz reduziert die kognitive Belastung für jeden, der das Diagramm liest. - Generierung automatisieren: Wo immer möglich, generieren Sie das Diagramm aus dem bestehenden Schema. Dadurch wird sichergestellt, dass die visuelle Darstellung immer mit der physischen Realität übereinstimmt. Verwenden Sie Werkzeuge, die die Datenbankstruktur rückwärts analysieren können.
🚫 Häufige Fallen, die vermieden werden sollten
Sogar erfahrene Teams geraten bei der Datenmodellierung in Fallen. Die Kenntnis dieser häufigen Fehler hilft Ihnen, zukünftiges Chaos zu vermeiden.
- Über-Normalisierung: Während Normalisierung gut ist, kann die Aufteilung von Daten in zu viele Tabellen Abfragen unglaublich komplex und langsam machen. Finden Sie ein Gleichgewicht zwischen Struktur und Abfrageleistung.
- Ignorieren von Weichlöschungen: In modernen Anwendungen werden Daten selten hart gelöscht. Sie benötigen ein
deleted_atFlag. Stellen Sie sicher, dass Ihr ERD diese logische Löschstrategie von Anfang an berücksichtigt. - Versteckte Beziehungen: Verstecke Beziehungen nicht innerhalb der Anwendungslogik. Wenn Tabelle A mit Tabelle B verknüpft ist, stelle dies im Datenbankschema explizit dar. Sich auf die Anwendung zu verlassen, um Beziehungen durchzusetzen, ist brüchig.
- Denormalisierung ohne Zweck: Manchmal duplizierst du bewusst Daten zur Geschwindigkeit. Dies muss jedoch eine bewusste Entscheidung sein, keine Folge schlechter Planung. Dokumentiere, warum du die Normalisierung aufhebst.
🤝 Der menschliche Faktor der Datenmodellierung
Daten sind nicht nur Zahlen; sie repräsentieren Menschen, Produkte und Aktionen. Ein ERD schließt die Lücke zwischen technischen Beschränkungen und Geschäftslogik. Wenn ein Produktmanager eine neue Funktion vorschlägt, ermöglicht das ERD ihnen, sofort die Datenfolgen zu erkennen. Es verhindert das „Feature-Creep“, das oft Datenbanken beschädigt.
Stelle dir eine Situation vor, in der ein Unternehmen Nutzerpräferenzen verfolgen möchte. Ohne ein ERD könnte ein Entwickler für jede Präferenz eine neue Spalte erstellen. Dies führt zu einer breiten, lückenhaften Tabelle, die schwer abfragbar ist. Mit einem ERD erkennen sie ein Muster: Schlüssel und Werte. Sie erstellen eine PräferenzenTabelle. Diese Struktur ist flexibel und skalierbar.
Darüber hinaus fördert das ERD eine bessere Kommunikation zwischen Abteilungen. Wenn die Rechtsabteilung nach der Datenhaltung fragt, zeigt das Datenmodell genau, wo sich diese Daten befinden. Diese Transparenz ist entscheidend für Compliance- und Sicherheitsprüfungen.
🔍 Tiefgang: Integritätsbeschränkungen
Eine der mächtigsten Funktionen einer relationalen Datenbank ist die Fähigkeit, Regeln auf Datenbankebene durchzusetzen. Diese werden als Beschränkungen bezeichnet. Ein ERD ist der visuelle Vorläufer dieser Beschränkungen. Er definiert, wo sie hingehören.
- NICHT NULL: Stellt sicher, dass ein Feld einen Wert haben muss. Wichtig für zentrale Identifikatoren wie Benutzer-IDs oder E-Mail-Adressen.
- EINDEUTIG: Stellt sicher, dass in einer Spalte keine doppelten Werte existieren. Wichtig, um doppelte E-Mail-Adressen oder Benutzernamen zu verhindern.
- ÜBERPRÜFEN: Erlaubt benutzerdefinierte Logik, beispielsweise sicherzustellen, dass ein Preis immer größer als null ist.
- Standardwert: Stellt einen Rückfallwert bereit, falls kein Wert angegeben wird. Nützlich für Zeitstempel oder Status-Flags.
Durch die Definition dieser Regeln im Diagramm stellst du sicher, dass die Datenbank selbst die Daten schützt, anstatt sich auf den Anwendungscode zur Eingabeverifizierung zu verlassen. Dies ist eine grundlegende Schutzschicht gegen Datenkorruption.
🔄 Der Lebenszyklus einer Schemaänderung
Änderungen sind unvermeidlich. Du wirst Spalten hinzufügen, Tabellen umbenennen oder Entitäten aufteilen müssen. Das ERD leitet diesen Prozess sicher.
- Visualisiere die Änderung: Aktualisiere das Diagramm, um den zukünftigen Zustand darzustellen.
- Analysiere die Auswirkungen: Verfolge die Linien. Welche Tabellen werden betroffen sein? Welche Abfragen werden fehlschlagen?
- Plane die Migration: Schreibe Skripte, die die Übergabe reibungslos gestalten. Füge zuerst die neue Spalte hinzu, fülle sie, schalte dann die Anwendung auf ihre Nutzung um und entferne schließlich die alte Spalte.
- Aktualisiere das Diagramm:Sobald die Migration abgeschlossen ist, aktualisieren Sie das ERD, um die neue Realität widerzuspiegeln.
Dieser Prozess verhindert den sogenannten „Schema-Drift“, der entsteht, wenn Code und Datenbank im Laufe der Zeit auseinanderdriften. Die Abstimmung des Diagramms ist der Schlüssel für langfristige Stabilität.
📈 Messen des Einflusses
Wie erkennen Sie, ob Ihre ERD-Strategie funktioniert? Suchen Sie nach diesen Gesundheitsindikatoren innerhalb Ihrer Anwendung.
- Weniger Datenfehler:Berichte zeigen weniger Inkonsistenzen oder verwaiste Datensätze.
- Schnellerer Onboarding:Neue Entwickler können die Datenstruktur schnell verstehen.
- Optimierte Abfragen:Leistungsmetriken zeigen stabile oder verbesserte Abfragezeiten, während die Datenmenge wächst.
- Klare Kommunikation:Weniger Besprechungen sind notwendig, um zu erklären, wie Daten zwischen Systemen fließen.
Diese Metriken zeigen, dass die vorherige Investition in die Modellierung sich über die Lebensdauer der Anwendung auszahlt. Der Fokus verschiebt sich von der Behebung von Problemen hin zur Verhinderung von ihnen.
🛠️ Werkzeuge und Techniken zur Dokumentation
Obwohl Sie darauf verzichten sollten, sich auf spezifische Anbieterwerkzeuge zu verlassen, ist die Dokumentation eine universelle Praxis. Egal, ob Sie Stift und Papier, digitale Whiteboards oder spezialisierte Modellierungssoftware verwenden – das Prinzip bleibt dasselbe. Ziel ist Klarheit.
Stellen Sie sicher, dass Ihre Diagramme enthalten:
- Tabellennamen in Fettdruck.
- Primärschlüssel deutlich gekennzeichnet.
- Fremdschlüssel mit ihrem Beziehungstyp gekennzeichnet.
- Beschreibungen für komplexe Tabellen.
Einige Teams verwenden ein „Lesen-Only“-Diagramm für Frontend-Entwickler und ein „Schreiboptimiertes“ Diagramm für das Backend-Team. Diese Trennung der Verantwortlichkeiten hält die Komplexität überschaubar. Stellen Sie immer sicher, dass die endgültige Quelle der Wahrheit die Datenbank-Schemadefinition selbst ist, halten Sie das ERD aber als Referenz für das Verständnis.
🔗 Integration mit DevOps
In modernen Arbeitsabläufen wird die Datenbank als Code behandelt. Das ERD passt in diese Pipeline. Wenn ein Entwickler eine Änderung am Schema committet, sollte die CI/CD-Pipeline diese gegen das erwartete Diagramm validieren. Wenn das tatsächliche Schema von der Gestaltung abweicht, kann der Build fehlschlagen. Diese automatisierte Durchsetzung stellt sicher, dass der Bauplan immer eingehalten wird.
Diese Integration verhindert das versehentliche Löschen von Tabellen oder die Erstellung unstrukturierter Felder. Sie setzt Disziplin auf der Ebene der Automatisierung durch und stellt sicher, dass Chaos bereits vor der Produktion blockiert wird.
🧠 Letzte Überlegungen zur Datenarchitektur
Datenchaos ist kein Rätsel; es ist eine vorhersehbare Folge unstrukturierter Wachstumsprozesse. Indem Sie Zeit in Entity-Relationship-Diagramme investieren, bauen Sie ein System auf, das dem Druck des Skalierens standhält. Es geht darum, Ordnung aus Komplexität zu schaffen. Es stellt sicher, dass jedes Datenstück einen Ort und einen Zweck hat.
Die Disziplin, die zur Pflege eines ERD erforderlich ist, zahlt sich in Zuverlässigkeit aus. Ihre Anwendung wird zu einer stabilen Plattform statt zu einem zerbrechlichen Prototypen. Während Sie weiter bauen, denken Sie daran, dass das Diagramm ein lebendiges Dokument ist. Es wächst mit Ihnen, leitet Ihre Entscheidungen und schützt Ihre Investition. Der Weg zu einer robusten Anwendung ist mit klaren, gut definierten Datenbeziehungen gepflastert.