











Die Gestaltung von Datenmodellen in einer Microservices-Architektur erfordert eine grundlegende Veränderung des Denkens im Vergleich zu monolithischen Anwendungen. In einem traditionellen System deckt oft ein einzelnes Entity-Relationship-Diagramm (ERD) die gesamte Datenbank ab. In einer verteilten Umgebung zerfällt diese einheitliche Sicht in mehrere unabhängige Schemata. Die Herausforderung besteht darin, Kohärenz zu bewahren, ohne die Dienste miteinander zu koppeln. Dieser Leitfaden untersucht, wie Datenmodelle effektiv strukturiert werden können, um Skalierbarkeit und Robustheit zu gewährleisten und die häufigen Fallstricke der verteilten Datenverwaltung zu vermeiden.
Wenn Dienste Daten direkt teilen, übernehmen sie die Abhängigkeiten des jeweils anderen. Diese enge Kopplung führt zu zerbrechlichen Systemen, bei denen eine Änderung in einem Bereich einen anderen beschädigt. Das Ziel ist es, Grenzen zu schaffen, die es Teams ermöglichen, unabhängig zu deployen. Dazu ist eine sorgfältige Planung von Beziehungen, Konsistenzmodellen und Integrationsmustern erforderlich.
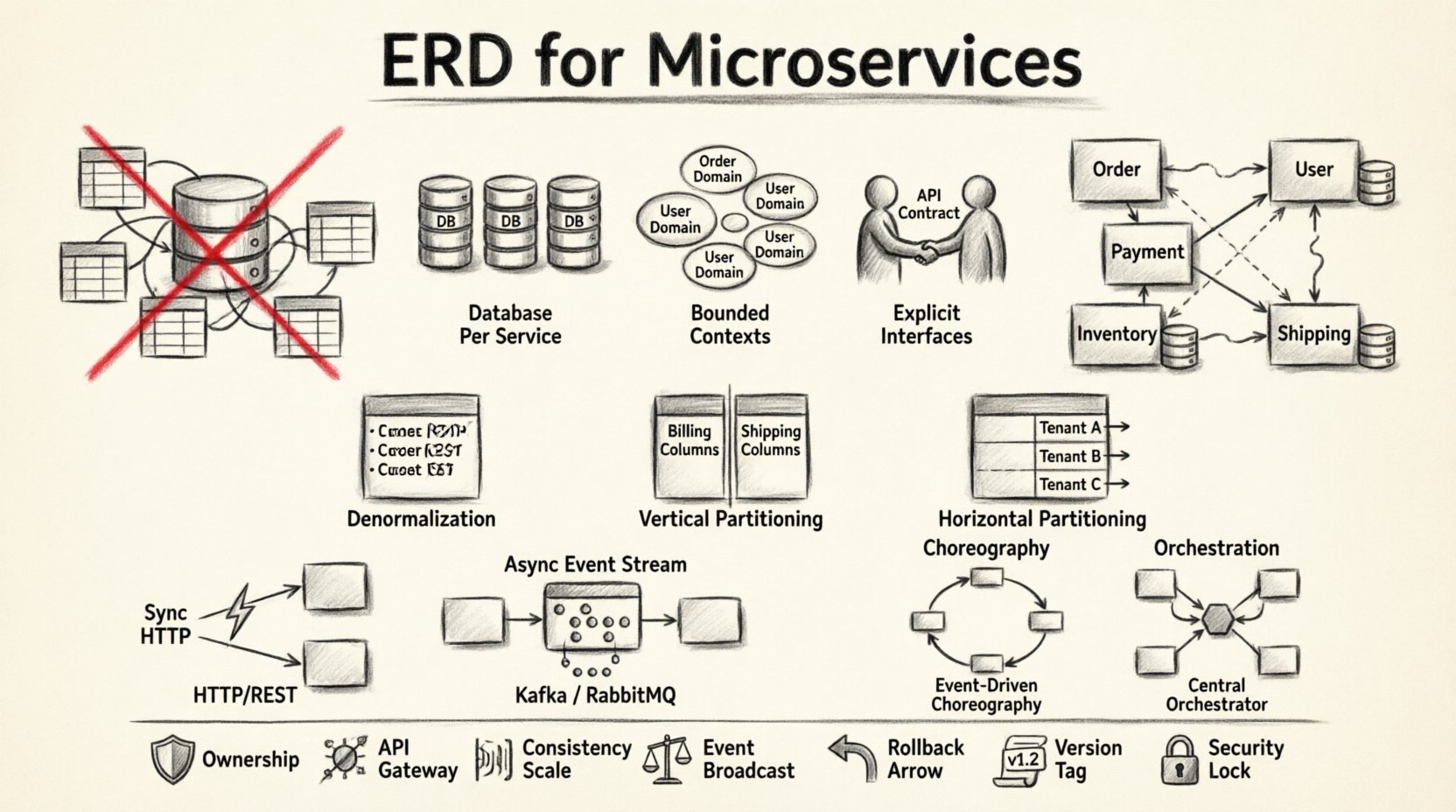
🧱 Warum traditionelle ERDs in verteilten Systemen versagen
Ein standardmäßiges ERD geht von einer zentralen Autorität aus. Es stellt Tabellen, Spalten und Fremdschlüssel innerhalb einer einzigen transaktionalen Grenze dar. Microservices lehnen diese Zentralisierung ab. Wenn man einen monolithischen ERD-Ansatz auf ein verteiltes System anwendet, besteht die Gefahr, ein verteiltes Monolith zu schaffen. Das geschieht, wenn Dienste auf gemeinsame Datenbanktabellen angewiesen sind, anstatt auf definierte APIs.
Die folgenden Probleme treten typischerweise auf, wenn diese Prinzipien ignoriert werden:
- Deployment-Kopplung:Änderungen an einer gemeinsam genutzten Tabelle erfordern gleichzeitige Deployments über mehrere Dienste hinweg.
- Transaktionsgrenzen:ACID-Transaktionen erstrecken sich über mehrere Dienste und erhöhen Latenz und Fehlerpunkte.
- Schema-Sperrung:Datenbank-Sperrungen in einem Dienst können Anfragen in einem anderen Dienst blockieren.
- Sichtbarkeitsprobleme:Kein einzelnes Team besitzt den globalen Datenzustand, was zu Dateninseln führt.
Anstatt eines einzigen Diagramms benötigen Sie eine Sammlung service-spezifischer Schemata, die über gut definierte Schnittstellen kommunizieren. Dieser Ansatz setzt Autonomie gegenüber sofortiger Konsistenz.
🧬 Kernprinzipien der verteilten Datenmodellierung
Um Ordnung zu bewahren, müssen Sie bestimmten architektonischen Prinzipien folgen. Diese Leitlinien unterstützen Teams bei Entscheidungen bezüglich Datenbesitz und Zugriffsmuster.
1. Datenbank pro Dienst
Jeder Microservice sollte seine eigene Datenbank besitzen. Dadurch wird sichergestellt, dass das interne Schema eines Dienstes für andere nicht sichtbar ist. Wenn Dienst A Daten aus Dienst B benötigt, muss er diese über eine API anfordern, nicht direkt auf die Datenbank zugreifen. Diese Isolation schützt die Integrität jedes Domänenbereichs.
- Dienste verwalten ihre eigene Schema-Evolution.
- Teams können die beste Datenbanktechnologie für ihre spezifischen Anforderungen wählen (Polyglot-Persistence).
- Ein Fehler in einer Datenbank führt nicht zum Absturz der gesamten Anwendung.
2. Begrenzte Kontexte
Daten müssen mit den Geschäftsfähigkeiten übereinstimmen. In der domain-driven Design-Methodik definiert ein begrenzter Kontext die semantische Grenze eines Modells. Zwei Dienste könnten den Begriff „Kunde“ verwenden, doch die Daten innerhalb dieser Kontexte unterscheiden sich. Ein Dienst könnte Kontaktdaten speichern, während der andere Finanzgeschichte speichert. Die Zusammenführung dieser in ein einziges ERD erzeugt Verwirrung und technischen Schulden.
3. Explizite Schnittstellen
Da Dienste die Daten des jeweils anderen nicht direkt sehen können, wird die API zur Datenvertragsvereinbarung. Das Schema der API-Antwort definiert die Wirklichkeit der Daten für den Verbraucher. Dadurch wird die interne Speicherimplementierung von der externen Nutzung entkoppelt.
📐 Schema-Entwurfsmuster für Unabhängigkeit
Die Gestaltung von Schemata für Microservices erfordert spezifische Muster, um Beziehungen zu handhaben, die traditionell durch Fremdschlüssel geregelt werden. Sie können sich nicht auf datenbankseitige Einschränkungen verlassen, um Beziehungen über Dienste hinweg durchzusetzen.
Denormalisierung
In einem Monolith reduziert Normalisierung Redundanz. Bei Microservices wird oft die Denormalisierung bevorzugt. Das Speichern von doppelten Daten verringert die Notwendigkeit von Fernaufrufen. Zum Beispiel könnte ein Bestellungs-Dienst den Kundennamen und die Adresse innerhalb des Bestell-Datensatzes speichern. Dadurch wird ein synchroner Aufruf an den Benutzer-Dienst bei jeder Anzeige einer Bestellung vermieden.
- Vorteil: Schnellere Leseleistung und weniger Netzwerk-Hops.
- Risiko: Dateninkonsistenz, wenn die Quelldaten geändert werden. Sie müssen Aktualisierungen über Ereignisse verarbeiten.
Vertikale Partitionierung
Große Tabellen in kleinere, fokussierte Mengen aufteilen. Wenn eine Tabelle sowohl Rechnungsdaten als auch Versandadressen enthält, sollten diese Aspekte getrennt werden. Rechnungsdaten könnten einem Zahlungsservice zugeordnet sein, während Versandadressen einem Logistikservice zuzuordnen sind. Dadurch wird die Änderungsfläche verkleinert und die Sicherheit verbessert, indem der Zugriff eingeschränkt wird.
Horizontale Partitionierung
Daten basierend auf der Mandanten-ID oder geografischer Region aufteilen. Dies ist nützlich, um bestimmte Dienste zu skalieren, ohne andere zu beeinflussen. Es ermöglicht die Replikation von Diensten für hoch frequentierte Regionen, während andere leicht gehalten werden.
| Muster | Beste Anwendungssituation | Wichtiger Aspekt |
|---|---|---|
| Entnormalisierung | Leseintensive Workloads | Erfordert Synchronisationslogik |
| Vertikale Partitionierung | Unterschiedliche Domänen | Klare API-Grenzen |
| Horizontale Partitionierung | Hohe Skalierung / Mehrmandantenfähigkeit | Komplexität der Routing-Logik |
🔄 Behandlung von Beziehungen und Konsistenz
Der schwierigste Teil der Datenmodellierung in Microservices ist die Aufrechterhaltung der Konsistenz ohne verteilte Transaktionen. Sie müssen sich zwischen starker Konsistenz und eventualer Konsistenz entscheiden.
Synchrones Kommunikation
Dienste können sich direkt über HTTP oder gRPC aufrufen. Dies bietet starke Konsistenz für sofortige Operationen. Es führt jedoch zu Latenz und schafft eine Abhängigkeitskette. Wenn Dienst A Dienst B aufruft und Dienst B ist nicht erreichbar, scheitert Dienst A.
Asynchrones Kommunikation
Dienste kommunizieren über Nachrichtenwarteschlangen oder Ereignisströme. Dadurch werden die Zeitpunkte der Operationen entkoppelt. Dienst A veröffentlicht ein Ereignis, das Dienst B später verarbeitet. Dies unterstützt die eventualen Konsistenz.
- Vorteile: Resilienz, Skalierbarkeit und lose Kopplung.
- Nachteile:Die Daten sind vorübergehend inkonsistent. Debugging erfordert das Verfolgen über mehrere Logs hinweg.
🗓️ Das Saga-Muster für Datenintegrität
Eine Saga ist eine Folge lokaler Transaktionen. Jede Transaktion aktualisiert die lokale Datenbank und veröffentlicht ein Ereignis, um den nächsten Schritt auszulösen. Wenn ein Schritt fehlschlägt, führt die Saga kompensierende Transaktionen aus, um vorherige Änderungen rückgängig zu machen.
Choreografie vs. Orchestrierung
Sagas können auf zwei Arten implementiert werden:
- Choreografie:Dienste hören auf Ereignisse und entscheiden, was als Nächstes geschehen soll. Es gibt keinen zentralen Controller. Dies ist flexibel, aber schwerer zu visualisieren.
- Orchestrierung:Ein zentraler Koordinator sagt den Diensten, was sie tun sollen. Dies bietet bessere Sichtbarkeit und Kontrolle über den Ablauf, führt aber zu einem einzigen Ausfallpunkt.
Beim Modellieren von ERDs für Sagen müssen Sie Zustandsänderungen berücksichtigen. Jeder Dienst, der an einer Saga beteiligt ist, muss seinen Zustand speichern, um Rückgängigmachungen zu behandeln. Das bedeutet, dass Ihr Schema transaktionale Zustände unterstützen muss, nicht nur endgültige Daten.
📝 Verwaltung der Schema-Evolution
Die Evolution von Schemata ist unvermeidlich. Felder ändern sich, Typen verschieben sich und Beschränkungen werden gelockert. In einem verteilten System können Sie ein Datenbankschema nicht ändern, solange andere Dienste davon abhängen. Sie müssen für Versionierung planen.
Rückwärtskompatibilität
Stellen Sie immer die Rückwärtskompatibilität sicher. Wenn Sie ein neues Feld hinzufügen, entfernen Sie das alte nicht sofort. Erlauben Sie den Verbrauchern eine schrittweise Migration. Wenn Sie einen Feldnamen ändern müssen, legen Sie während einer Übergangsphase einen Alias für den alten Namen an.
Versionsstrategien
- URI-Versionierung:Fügen Sie Versionsnummern in den API-Pfad ein.
- Header-Versionierung:Verwenden Sie benutzerdefinierte Header, um die erwartete Schema-Version anzugeben.
- Inhaltsabstimmung:Verwenden Sie Standard-HTTP-Header, um bestimmte Medientypen anzufordern.
Die Dokumentation muss mit dem Code synchron gehalten werden. Automatisierte Tests sollten sicherstellen, dass der API-Vertrag mit dem Schema übereinstimmt. Dadurch werden brechende Änderungen verhindert, die in die Produktion gelangen könnten.
🛡️ Häufige Fallen, die vermieden werden sollten
Selbst mit einem soliden Plan stolpern Teams oft über bestimmte Probleme. Die Aufmerksamkeit für diese Fallen hilft bei der Gestaltung eines robusten Systems.
1. Die Falle des geteilten Datenbanksystems
Teilen Sie keine Tabellen zwischen Diensten. Dadurch entsteht eine versteckte Kopplung. Wenn der Zahlungsdienst die Tabelle des Auftragsdienstes liest, erfährt er zu viel über die interne Struktur. Dies führt zu enger Kopplung und Bereitstellungskonflikten.
2. Übernormalisierung
Die Versuche, Daten über Dienste hinweg zu normalisieren, führen zu übermäßigen Joins und Netzwerkaufrufen. Akzeptieren Sie eine gewisse Redundanz. Es ist besser, doppelte Daten zu haben, als ein langsames, stark gekoppeltes System zu haben.
3. Ignorieren der Idempotenz
Netzwerkaufrufe können fehlschlagen. Nachrichten werden dupliziert. Ihr Schema und Ihre API-Logik müssen doppelte Anfragen verarbeiten können, ohne Fehler zu verursachen. Gestalten Sie Ihre Endpunkte idempotent, damit das erneute Senden einer Anfrage keine doppelten Datensätze erzeugt.
4. Mangel an Beobachtbarkeit
Wenn Daten verteilt sind, können Sie nicht eine einzige Datenbank abfragen, um eine Transaktion zurückzuverfolgen. Sie benötigen verteilte Tracing- und zentralisierte Protokollierung. Ihr Schema sollte Korrelations-IDs enthalten, um Anfragen über Dienstgrenzen hinweg zu verfolgen.
📋 Governance-Checkliste
Bevor Sie einen neuen Dienst bereitstellen, überprüfen Sie die folgende Checkliste, um sicherzustellen, dass Ihr Datenmodell solide ist.
- Verantwortung: Ist ein einziger Dienst für diese Daten verantwortlich?
- Schnittstelle: Werden die Daten nur über eine API verfügbar gemacht?
- Konsistenz: Ist das Konsistenzmodell dokumentiert (Stark vs. Eventuell)?
- Ereignisse: Werden Zustandsänderungen als Ereignisse für andere Dienste veröffentlicht?
- Kompensation: Gibt es eine Rückgängigmachungsmechanismus für fehlgeschlagene Transaktionen?
- Versionsverwaltung: Wird das Schema versioniert, um zukünftige Änderungen zu bewältigen?
- Sicherheit: Wird vertrauliche Daten ruhend und im Transport verschlüsselt?
🔍 Visualisierung der Architektur
Obwohl Sie kein einziges ERD für das gesamte System zeichnen können, können Sie eine grobe Karte erstellen. Diese Karte zeigt Dienste und ihre Datenbereiche, nicht spezifische Spalten.
- Zeichnen Sie für jeden Dienst ein Feld.
- Beschriften Sie den Datenbereich innerhalb des Feldes (z. B. „Benutzerprofil-Daten“).
- Zeichnen Sie Pfeile für API-Aufrufe, die den Datenfluss anzeigen.
- Zeigen Sie Ereignisströme getrennt von Anfrage-/Antwort-Flüssen an.
Diese visuelle Hilfestellung hilft den Stakeholdern, den Informationsfluss zu verstehen, ohne sich in technischen Schema-Details zu verlieren. Sie dient als Kommunikationswerkzeug für Architekten und Business-Analysten.
🚀 Fazit
Das Entwerfen von ERDs für Microservices geht nicht darum, Linien zwischen Tabellen zu zeichnen. Es geht darum, Grenzen zwischen Geschäftsleistungen zu definieren. Indem Sie die Datenbank pro Dienst annehmen, die eventuelle Konsistenz akzeptieren und APIs streng verwalten, können Sie skalierbare Systeme aufbauen. Die Chaos der verteilten Daten ist mit Disziplin und klaren Verträgen beherrschbar. Konzentrieren Sie sich auf Autonomie, minimieren Sie die Kopplung und stellen Sie sicher, dass jeder Dienst seine Daten vollständig besitzt.
Denken Sie daran, dass Datenmodellierung ein iterativer Prozess ist. Sobald Dienste wachsen, muss sich Ihr Schema weiterentwickeln. Überprüfen Sie Ihre Architektur regelmäßig anhand dieser Prinzipien, um ein gesundes, widerstandsfähiges System zu erhalten.