











Die Gestaltung einer robusten Datenstruktur ist die Grundlage jedes zuverlässigen Software-Systems. Ein Entitäts-Beziehungs-Diagramm (ERD) dient als Bauplan dafür, wie Daten gespeichert, verknüpft und abgerufen werden. Wenn dieser Bauplan fehlerhaft ist, wirken sich die Konsequenzen über die gesamte Anwendung aus und beeinträchtigen Leistung, Datenintegrität und Entwicklungsrate. Viele Teams stürzen sich ohne Überprüfung ihrer Schema-Designs direkt in die Implementierung, was zu strukturellen Schulden führt, die später teuer zu beheben sind.
Diese Anleitung untersucht sieben kritische Fehler, die bei der Datenbankmodellierung auftreten. Jeder Punkt beschreibt die spezifischen technischen Auswirkungen und liefert handlungsorientierte Empfehlungen, um diese Fehler zu vermeiden. Durch das Verständnis der Mechanismen der Normalisierung, Einschränkungen und Beziehungsmapping können Sie Systeme aufbauen, die skalieren, ohne die Stabilität zu gefährden.
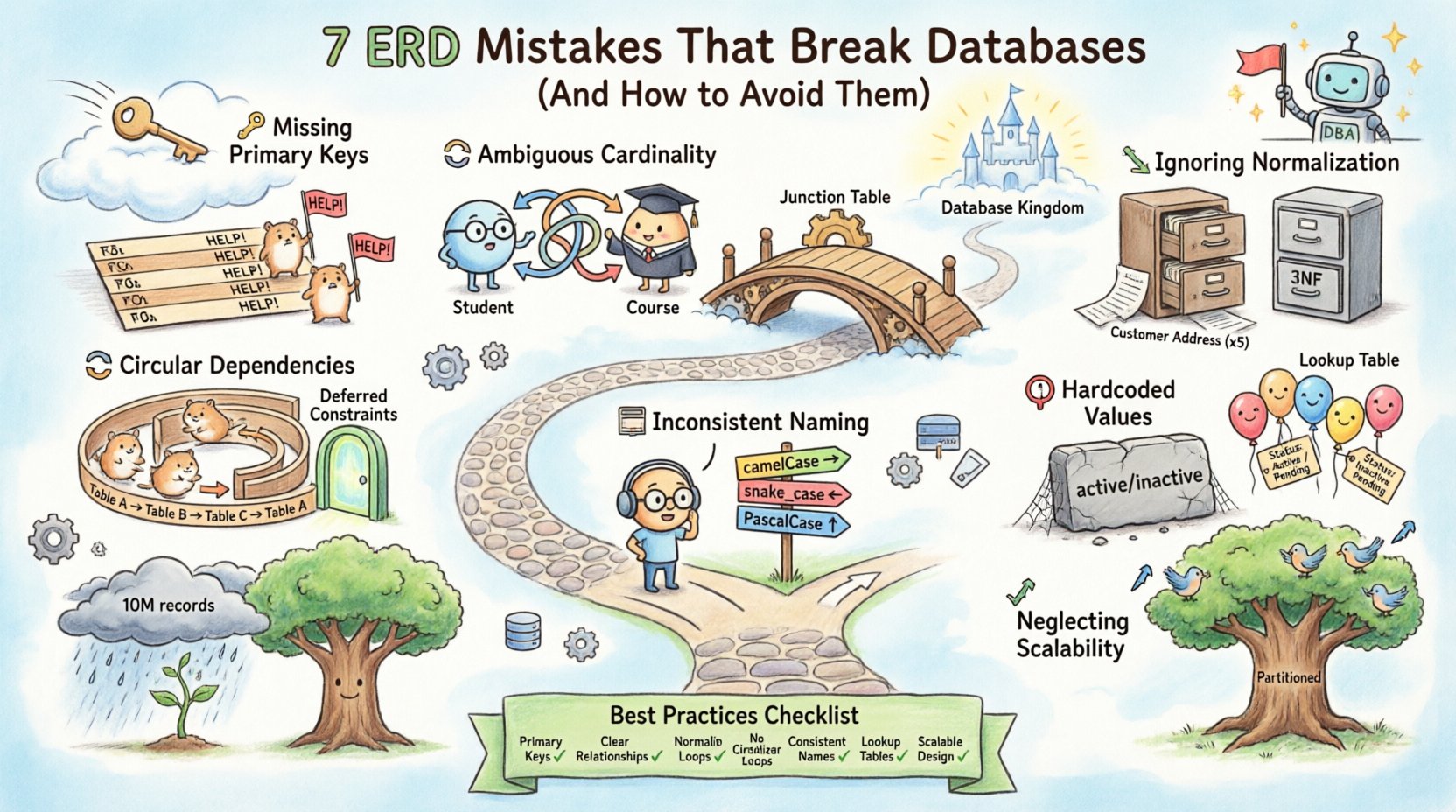
1. Fehlende oder schwache Primärschlüssel 🔑
Ein Primärschlüssel ist der eindeutige Bezeichner für eine Datensatz in einer Tabelle. Er ist der Anker, der sicherstellt, dass jede Zeile eindeutig und abrufbar ist. Die Weglassung eines Primärschlüssels oder eine schlechte Gestaltung desselben ist einer der grundlegenden Fehler in der Datenbankarchitektur.
Die technische Konsequenz
- Datenduplikation: Ohne eine eindeutige Einschränkung kann die Datenbank Duplikate nicht verhindern. Dies führt zu inkonsistenten Berichten und Problemen mit der Datenintegrität.
- Join-Leistung: Fremdschlüssel-Beziehungen setzen auf Primärschlüssel für eine effiziente Indizierung. Ein fehlender oder nicht indizierter Primärschlüssel zwingt zu vollständigen Tabellen-Scans bei Joins und verlangsamt die Abfrageausführung erheblich.
- Komplexität bei Aktualisierungen: Wenn Sie einen Datensatz aktualisieren müssen, muss das System auf nicht eindeutige Spalten zurückgreifen, um die Zeile zu finden. Wenn mehrere Zeilen den Suchkriterien entsprechen, könnte die Aktualisierung unbeabsichtigte Daten betreffen.
Best Practices zur Vermeidung dieses Problems
- Definieren Sie immer einen Primärschlüssel für jede Tabelle, auch wenn dies redundant erscheint.
- Verwenden Sie vorzugsweise künstliche Schlüssel (auto-inkrementierende Ganzzahlen oder UUIDs) anstelle natürlicher Schlüssel (wie E-Mail-Adressen oder Telefonnummern), um Änderungen im Geschäftslogikbereich zu vermeiden, die das Schema beeinflussen könnten.
- Stellen Sie sicher, dass die Spalte für den Primärschlüssel nicht NULL-Werte zulässt.
- Verwenden Sie zusammengesetzte Schlüssel nur dann, wenn eine einzelne Spalte eine Zeile nicht eindeutig identifizieren kann, beispielsweise bei Tabellen für viele-zu-viele-Beziehungen.
2. Mehrdeutige Beziehungskardinalität 🔄
Die Kardinalität definiert die numerische Beziehung zwischen Datensätzen in zwei Tabellen. Zu den gängigen Arten gehören ein-zu-eins, ein-zu-viele und viele-zu-viele. Die falsche Darstellung dieser Beziehungen im Diagramm führt zu strukturellen Abweichungen in der physischen Datenbank.
Häufige Fehlerquellen
- Annahme von ein-zu-viele:Designer neigen oft dazu, eine ein-zu-viele-Beziehung anzunehmen, wenn tatsächlich eine viele-zu-viele-Beziehung besteht. Zum Beispiel kann ein Student an vielen Kursen teilnehmen, und ein Kurs kann viele Studenten haben. Die Modellierung als ein-zu-viele erfordert die Duplizierung von Studentendaten über mehrere Kurszeilen hinweg.
- Unbeschriftete Linien:ERD-Linien sollten die Kardinalität anzeigen (z. B. in Form der Krähenfuß-Notation). Das Weglassen von Beschriftungen lässt Entwickler raten, wie die Daten miteinander verknüpft sind.
- Ignorieren der NULL-Zulässigkeit: Eine ein-zu-eins-Beziehung könnte NULL-Werte in der Fremdschlüsselspalte zulassen, wenn die Beziehung optional ist. Das Nichtmodellieren dieser Einschränkung ermöglicht verwaiste Datensätze.
Der richtige Ansatz
- Stellen Sie viele-zu-viele-Beziehungen explizit mithilfe einer Verbindungstabelle (assoziative Tabelle) dar, die Fremdschlüssel aus beiden beteiligten Tabellen enthält.
- Dokumentieren Sie die Kardinalität deutlich auf den Linien des Diagramms.
- Wenden Sie Datenbank-Einschränkungen (wie UNIQUE-Einschränkungen auf Fremdschlüsseln) an, um die Logik des Diagramms durchzusetzen.
| Beziehungsart | Implementierungsstrategie | Häufiger Fehler |
|---|---|---|
| Ein-zu-Eins | Fremdschlüssel in einer Tabelle mit UNIQUE-Beschränkung | Unnötiges Hinzufügen eines Fremdschlüssels zu beiden Tabellen |
| Ein-zu-Viele | Fremdschlüssel in der „Viele“-Tabelle | Speichern von Elterndaten in der Kindtabelle (Denormalisierung) |
| Viele-zu-Viele | Zwischentabelle (Junction Table) | Speichern mehrerer IDs in einer einzelnen durch Kommas getrennten Spalte |
3. Ignorieren der Normalisierungsstandards 📉
Normalisierung ist der Prozess der Datenorganisation zur Reduzierung von Redundanz und Verbesserung der Integrität. Während einige moderne Systeme die Denormalisierung zur Verbesserung der Leseleistung nutzen, führt das vollständige Auslassen der Normalisierung während der Entwurfsphase zu erheblichen Wartungsaufwendungen.
Die Risiken einer schlechten Normalisierung
- Aktualisierungsanomalien: Wenn eine Kundenadresse in fünf verschiedenen Auftragstabellen gespeichert ist, erfordert die Aktualisierung ihrer Adresse fünf getrennte Aktualisierungen. Wenn eine Aktualisierung fehlschlägt, wird die Datenkonsistenz verletzt.
- Einfügeanomalien: Sie könnten nicht in der Lage sein, eine neue Produktkategorie hinzuzufügen, ohne auch einen Produkt-Eintrag hinzuzufügen, was die Erstellung von Dummy-Daten erzwingt.
- Löschanomalien: Das Löschen eines Datensatzes könnte versehentlich kritische Daten zu anderen Entitäten entfernen.
Implementierungsrichtlinien
- Ziel sollte die dritte Normalform (3NF) als Baseline sein. Dadurch wird sichergestellt, dass Spalten nur vom Primärschlüssel abhängen.
- Identifizieren Sie transitive Abhängigkeiten, bei denen eine nicht-schlüsselbehaftete Spalte von einer anderen nicht-schlüsselbehafteten Spalte abhängt.
- Trennen Sie unterschiedliche Entitäten. Wenn eine Tabelle Informationen zu „Aufträgen“ und „Kunden“ enthält, sollten sie getrennt werden.
- Denormalisieren Sie erst nach der Profilierung der Abfrageleistung. Optimieren Sie nicht vorab für Geschwindigkeit auf Kosten der Integrität.
4. Erstellen von zirkulären Abhängigkeiten 🔁
Zirkuläre Abhängigkeiten treten auf, wenn Tabellen sich in einer Schleife gegenseitig referenzieren, was die Initialisierung verhindert oder unendliche Rekursionen in Abfragen verursacht. Während rekursive Beziehungen (wie ein Organigramm, bei dem ein Mitarbeiter einen Vorgesetzten hat) gültig sind, können unkontrollierte zirkuläre Fremdschlüssel die Datenbank beschädigen.
Warum dies Systeme beschädigt
- Initialisierungsfehler: Bei der Bereitstellung kann die Datenbankengine die Erstellung von Fremdschlüsselbeschränkungen ablehnen, wenn eine zirkuläre Referenz besteht (z. B. Tabelle A verweist auf B, und B verweist auf A), es sei denn, sie wird mit verzögerten Beschränkungen behandelt.
- Abfrage-Stack-Überläufe:Rekursive Abfragen, die diese Schleifen ohne eine Stopbedingung durchlaufen, können den gesamten verfügbaren Speicher verbrauchen.
- Verletzungen der Referenziellen Integrität:Das Löschen einer übergeordneten Tabelle kann fehlschlagen, wenn die untergeordneten Tabellen nicht geleert wurden, aber das Leeren der untergeordneten Tabellen kann aufgrund anderer Abhängigkeiten fehlschlagen.
Wie wird behoben
- Verwenden Sie Verzögerte Beschränkungen wenn Ihre Datenbank sie unterstützt, wodurch die Datenbank die Beziehungen nach dem Laden aller Daten überprüfen kann.
- Stellen Sie für selbstreferenzierende Tabellen (wie Kategorien) sicher, dass der Fremdschlüssel nullbar ist, um Stammknoten zu ermöglichen.
- Gestalten Sie das Schema so, dass eine logische Hierarchie möglich ist, ohne auf jeder Ebene eine physische Fremdschlüsselschleife zu erzwingen.
- Implementieren Sie weiche Löschungen, um Löschkaskaden sicher zu verwalten.
5. Inkonsistente Namenskonventionen 📝
Namensbezeichnungen sind die Schnittstelle zwischen Menschen und Maschinen. Inkonsistente Namensgebung in Tabellen- und Spaltennamen macht das Schema schwer verständlich, wartbar und abfragbar. Dies stammt oft aus dem Fehlen einer gemeinsam genutzten Stilrichtlinie.
Spezifische Probleme
- Gemischte Groß- und Kleinschreibung: Vermischung von
camelCase,snake_case, undPascalCaseverwirrt Entwickler, die die Daten abfragen. - Reservierte Schlüsselwörter: Verwenden von Namen wie
order,group, oderuserohne Escape kann zu Syntaxfehlern in SQL-Abfragen führen. - Akkronym: Verwenden von
usr_idgegenüberbenutzer_idgegenüberuidin verschiedenen Tabellen verringert die Klarheit. - Länge gegenüber Kürze: Einige Spalten sind übermäßig lang, während andere verschlüsselte Abkürzungen sind.
Standard festlegen
- Übernehmen Sie eine konsistente Groß-/Kleinschreibung (z. B.
snake_casefür SQL-Tabellen wird weit verbreitet empfohlen). - Verwenden Sie beschreibende Namen, die den geschäftlichen Sinn widerspiegeln, nicht interne Implementierungsdetails.
- Vermeiden Sie reservierte Schlüsselwörter vollständig. Falls unvermeidbar, setzen Sie sie in Anführungszeichen oder Klammern, die spezifisch für die Datenbank-Engine sind.
- Standardisieren Sie Singular gegenüber Plural bei Tabellennamen. Wählen Sie eine Variante und halten Sie sich daran (z. B.
benutzergegenüberbenutzer). - Präfixieren Sie Fremdschlüsselspalten mit dem Namen der referenzierten Tabelle (z. B.
benutzer_id) um Beziehungen offensichtlich zu machen.
6. Wertehardcodierung im Schema 🛑
Designer integrieren manchmal bestimmte Geschäftswerte direkt in die Datenbankstruktur, beispielsweise durch die Verwendung einer Spalte zur Speicherung bestimmter Statuscodes wie aktiv oder inaktiv anstelle eines generischen Statusfeldes oder der Festcodierung von Währungstypen.
Die Auswirkungen auf die Flexibilität
- Schema-Änderungen: Wenn ein neuer Status benötigt wird, müssen Sie möglicherweise die Tabellenstruktur ändern oder eine neue Spalte hinzufügen, was eine Bereitstellungsunterbrechung auslöst.
- Datenvalidierung: Der Anwendungscode validiert diese Werte oft, aber das Datenbankschema sollte gültige Bereiche oder Mengen durch Einschränkungen durchsetzen.
- Lokalisierungsprobleme:Festcodieren von Textwerten wie
USDoderEnglischmacht eine globale Erweiterung schwierig.
Refactoring zur Skalierbarkeit
- Verwenden SieSuchtabellen für jede Wertemenge, die sich ändern oder vergrößern könnte (z. B. Status, Währung, Land).
- Implementieren SiePrüfbeschränkungen um sicherzustellen, dass nur gültige Werte eingegeben werden, halten Sie die Definition dieser Werte jedoch in der Anwendung oder in einer separaten Konfigurationstabelle.
- Verwenden Sie Aufzählungen nur, wenn das Datenbanksystem sie robust unterstützt und die Menge wirklich festgelegt ist.
- Trennen Sie Konfigurationsdaten von Transaktionsdaten.
7. Vernachlässigung zukünftiger Skalierbarkeit 📈
Viele ERDs werden für die aktuelle Datensatzgröße entworfen, ohne Wachstum zu berücksichtigen. Ein Schema, das für 1.000 Datensätze funktioniert, kann bei 10 Millionen Datensätzen aufgrund von Sperr-, Indizierungs- oder Partitionierungsproblemen vollkommen versagen.
Skalierbarkeitsfallen
- Große Textfelder:Das Speichern großer Blobs oder langer Textzeichenfolgen in der Haupttabelle kann den Index aufblähen und das Lesen verlangsamen.
- Fehlende Partitionierungsschlüssel: Wenn das Schema nicht berücksichtigt, wie die Daten partitioniert oder gesplittet werden (z. B. nach Datum oder Region), wird die zukünftige horizontale Skalierung zu einem großen Refactoring.
- Fehlende Indizes:Das Nichtvorhersehen der Spalten, die zukünftig für Filtern oder Sortieren verwendet werden, führt zu Leistungsbottlenecks.
- Schreibintensive Muster: Ein für Lesevorgänge optimiertes Design kann bei hohen Schreibvolumina an Leistung verlieren, da Sperrmechanismen bei Fremdschlüsseln auftreten.
Design für Wachstum
- Überprüfen Sie die Lese-/Schreibverhältnis Ihrer Anwendung. Wenn es schreibintensiv ist, minimieren Sie Fremdschlüsselbeschränkungen, die Sperrungen verursachen.
- Entwerfen Sie Partitionierungsschlüssel in Ihr Hauptschema ein. Stellen Sie sicher, dass jede Tabelle eine Spalte hat, die zur logischen Aufteilung der Daten verwendet werden kann.
- Trennen Sie umfangreiche Textdaten in eine separate Tabelle (1:1-Beziehung), um den Hauptindex schlank zu halten.
- Planen Sie für Weiche Löschungen anstelle von harten Löschungen, um die Datenhistorie zu bewahren, ohne die aktuelle Abfrageleistung zu beeinträchtigen.
Zusammenfassung der Best Practices 📋
Um sicherzustellen, dass Ihre Datenbank stabil und wartbar bleibt, überprüfen Sie Ihr Entitäts-Beziehungs-Diagramm vor der Bereitstellung anhand der folgenden Prüfliste.
- Schlüssel: Jede Tabelle verfügt über einen Primärschlüssel. Fremdschlüssel sind indiziert.
- Beziehungen: Die Kardinalität ist eindeutig definiert. Many-to-many-Beziehungen verwenden Zwischentabellen.
- Normalisierung: Datenredundanz wird gemäß den 3NF-Standards minimiert.
- Abhängigkeiten: Keine zirkulären Fremdschlüssel-Schleifen ohne verzögerte Einschränkungen.
- Benennung: Konsistente Groß-/Kleinschreibung und beschreibende Namen werden durchgehend verwendet.
- Werte: Keine fest codierten Geschäftsregeln in der Schemastruktur.
- Skalierung: Das Schema berücksichtigt Partitionierungs- und Indizierungsstrategien für zukünftige Last.
Abschließende Gedanken zur Datenmodellierung 🧠
Ein Datenbankaufbau geht nicht nur darum, zu schreiben CREATE TABLEAnweisungen. Es geht darum, die Realität Ihrer Geschäftsprozesse in eine logische Struktur zu modellieren, die eine Maschine effizient verarbeiten kann. Die Kosten für die Behebung eines Schema-Fehlers steigen exponentiell, je später er im Entwicklungszyklus entdeckt wird.
Durch die Vermeidung dieser sieben häufigen Fallen verringern Sie technische Schulden und schaffen eine Grundlage, die komplexe Abfragen und Transaktionen mit hoher Volumenbelastung unterstützt. Priorisieren Sie Klarheit, Integrität und Flexibilität in Ihren Diagrammen. Ein gut gestaltetes ERD ist für den Endbenutzer unsichtbar, aber entscheidend für die Langzeitstabilität des Systems.
Nehmen Sie sich die Zeit, Ihr Schema mit frischem Blick oder durch ein Peer-Review-Verfahren zu überprüfen. Fragen Sie nach dem Grund für eine Beziehung und wie sie sich unter Last verhalten wird. Diese Sorgfalt zahlt sich in der Systemzuverlässigkeit und der Entwicklerproduktivität später aus.