











In der komplexen Welt der Backend-Entwicklung ist Daten die Grundlage, auf der Anwendungen aufgebaut werden. Während das Schreiben von Code zur Manipulation dieser Daten eine zentrale Verantwortung darstellt, ist das Verständnis der Struktur der Daten selbst ebenso entscheidend. Das Entity-Relationship-Diagramm (ERD) dient als Bauplan für diese Struktur. Es ist die visuelle Sprache, die vermittelt, wie Informationen gespeichert, verknüpft und abgerufen werden. Für einen Backend-Entwickler ist die Fähigkeit, ein ERD fließend zu lesen, keine bloße Zusatzfertigkeit, sondern eine grundlegende Voraussetzung für die Gestaltung robuster, skalierbarer und wartbarer Systeme.
Viele Entwickler springen direkt ins Schreiben von Abfragen, ohne die Architektur des Schemas vollständig verinnerlicht zu haben. Dies führt oft zu Leistungsengpässen, Datenintegritätsproblemen und schwierigen Refaktorisierungsaufgaben später im Prozess. Durch die Beherrschung der Kunst des Interpretierens eines ERD erlangen Sie die Weitsicht, um vorherzusehen, wie Daten durch Ihre Anwendung fließen, und wie Änderungen in einem Bereich sich über die gesamte Datenbank auswirken könnten. Dieser Leitfaden bietet einen tiefen Einblick in die Mechanik des Lesens von ERDs, wobei der Fokus auf der praktischen Anwendung liegt, nicht auf abstrakten Theorien.
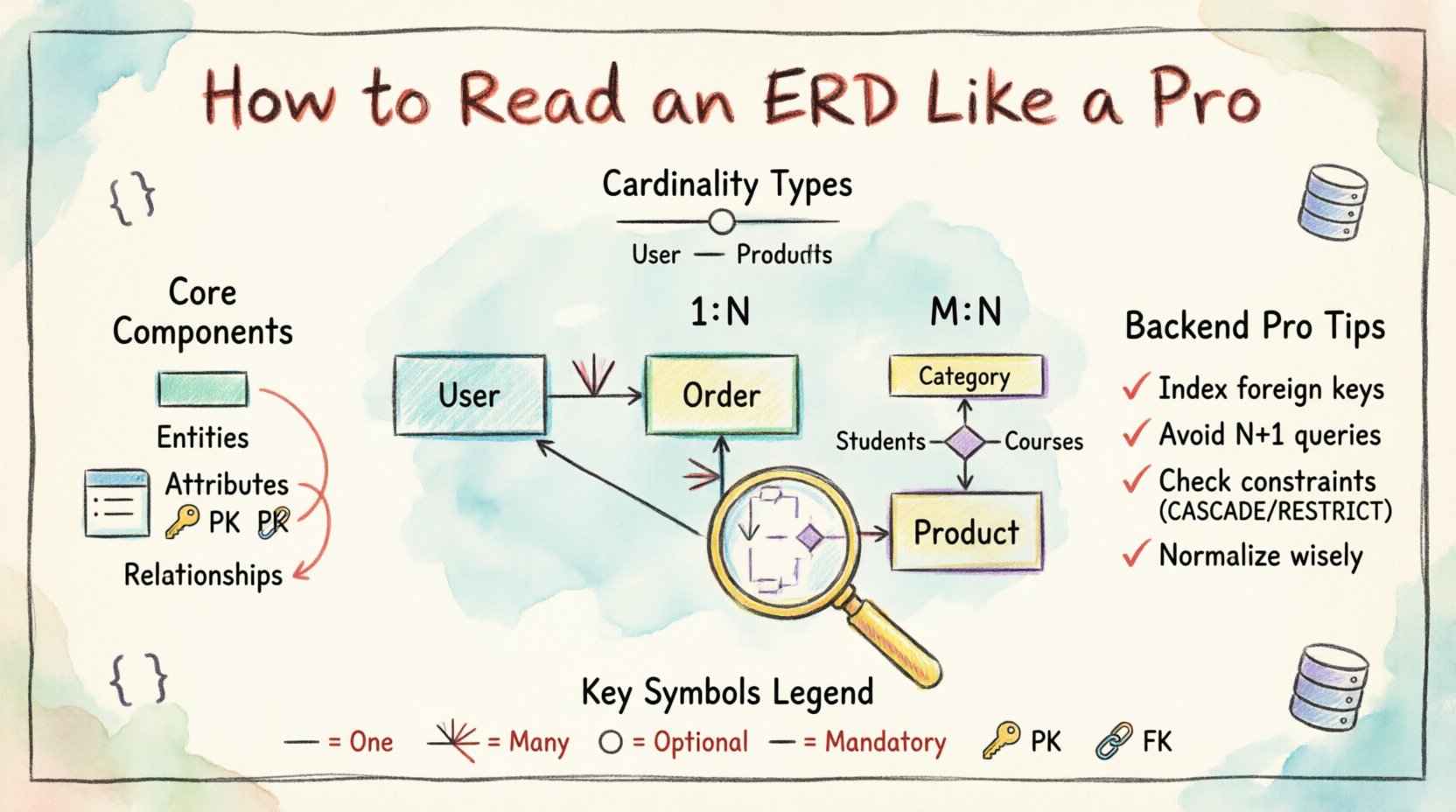
Das Verständnis der Kernkomponenten eines ERD 🧱
Bevor Sie die Verbindungen erkunden, müssen Sie die einzelnen Symbole verstehen, aus denen das Diagramm besteht. Ein ERD besteht aus mehreren unterschiedlichen Elementen, die jeweils einen bestimmten Aspekt des Datenmodells darstellen. Die sofortige Erkennung dieser Elemente ermöglicht es Ihnen, komplexe Schemata zu analysieren, ohne sich in den Linien zu verlieren.
1. Entitäten (Tabellen)
Das auffälligste Merkmal eines ERD ist die Entität. Im Kontext einer relationalen Datenbank entspricht eine Entität direkt einer Tabelle. Sie stellt ein eindeutiges Objekt oder Konzept dar, über das Daten gespeichert werden. Wenn Sie ein Rechteck mit einem Namen wie Kunde oder Bestellung, sehen Sie eine Tabelle vor sich.
- Visueller Hinweis:Typischerweise ein Rechteck oder ein Feld mit dem Namen.
- Funktion:Gruppiert verwandte Datenattribute zusammen.
- Backend-Bedeutung:Jede Entität entspricht in der Regel einer Klasse oder einem Modell in Ihrem Codebase.
Beim Lesen einer Entität achten Sie auf den Text innerhalb. Manchmal werden die Attribute (Spalten) explizit aufgelistet. In anderen Fällen handelt es sich um eine abstrakte Darstellung, bei der die Details in einer separaten Dokumentationsdatei gespeichert sind. In jedem Fall verrät Ihnen der Name der Entität das Substantiv Ihres Systems.
2. Attribute (Spalten)
Attribute definieren die Eigenschaften einer Entität. Wenn eine Entität eine Tabelle ist, dann sind die Attribute die Spalten innerhalb dieser Tabelle. Sie beschreiben die spezifischen Datenpunkte, die für jedes Datensatz benötigt werden.
- Primärschlüssel:Oft unterstrichen oder mit einem Schlüsselsymbol markiert. Dies identifiziert jede Zeile eindeutig.
- Fremdschlüssel:Oft durch eine Linie gekennzeichnet, die mit einer anderen Entität verbunden ist. Dies begründet die Beziehung.
- Daten-Typen:Obwohl sie nicht immer visuell dargestellt werden, schließt ein erfahrener Leser die Daten-Typen anhand des Kontexts ab (z. B. ein Feld namens email_adresseimpliziert einen String, erstellt_amimpliziert ein Zeitstempel).
Das Verständnis von Attributen ist entscheidend für die Erstellung effizienter Abfragen. Wenn ein Attribut nicht indiziert ist, führt die Suche nach ihm zu einer vollständigen Tabellen-Durchsuchung. Wenn es sich um einen Fremdschlüssel handelt, bestimmt er die Join-Operationen.
3. Beziehungen (Linien)
Beziehungen definieren, wie Entitäten miteinander interagieren. Diese Linien verbinden zwei Entitäten und beschreiben die Kardinalität (wie viele). Dies ist der wichtigste Teil beim Lesen eines ERD für die Backend-Logik, da festgelegt wird, wie Daten über mehrere Tabellen hinweg verknüpft sind.
- Richtung:Linien haben oft Pfeile oder Symbole am Ende, um die Richtung zu zeigen.
- Kardinalität:Gibt an, ob die Beziehung ein-zu-eins, ein-zu-viele oder viele-zu-viele ist.
- Optionalität:Manchmal wird sie durch durchgezogene vs. gestrichelte Linien angezeigt, um anzuzeigen, ob eine Beziehung obligatorisch oder optional ist.
Entschlüsselung von Kardinalität und Beziehungen 🔗
Die Kardinalität ist das Herzstück des ERD. Sie bestimmt die Einschränkungen und Logik Ihrer Datenbankbeziehungen. Eine falsche Interpretation der Kardinalität kann zu Daten-Duplikaten oder verwaisten Datensätzen führen. Lassen Sie uns die drei Hauptarten von Beziehungen analysieren, die Sie treffen werden.
1. Eins-zu-Eins (1:1)
Diese Beziehung besteht dann, wenn ein einzelner Datensatz in Tabelle A genau einem Datensatz in Tabelle B zugeordnet ist und umgekehrt.
- Anwendungsfall:Aufteilung großer Tabellen aus Sicherheits- oder Leistungsgründen. Zum Beispiel könnte ein BenutzerProfil von einem Benutzer_EinstellungenTabellen getrennt werden.
- Implementierung:Der Fremdschlüssel in einer Tabelle verweist auf den Primärschlüssel in der anderen, oft mit einer eindeutigen Einschränkung.
- Auswirkung auf das Backend:Joins sind meist erforderlich, um die vollständigen Daten abzurufen, aber die Logik ist einfach.
2. Eins-zu-Viele (1:N)
Dies ist die häufigste Beziehung in relationalen Datenbanken. Ein Datensatz in Tabelle A kann mit mehreren Datensätzen in Tabelle B verknüpft sein, aber jeder Datensatz in Tabelle B ist nur mit einem Datensatz in Tabelle A verknüpft.
- Anwendungsfall: Eine Kategorie mit mehreren Produkten.
- Implementierung: Der Fremdschlüssel befindet sich in der „Viele“-Seiten-Tabelle (Produkte) und verweist auf die „Eins“-Seiten-Tabelle (Kategorie).
- Backend-Auswirkung: Beim Abrufen einer Kategorie laden Sie oft eine Liste von Produkten. Beim Abrufen eines Produkts laden Sie eine einzelne Kategorie.
3. Many-to-Many (M:N)
Diese Beziehung tritt auf, wenn Datensätze in Tabelle A mit mehreren Datensätzen in Tabelle B verknüpft werden können und Datensätze in Tabelle B mit mehreren Datensätzen in Tabelle A verknüpft werden können.
- Anwendungsfall: Studierende, die sich in mehreren Klassen einschreiben, und Klassen, die mehrere Studierende haben.
- Implementierung: Dies kann nicht direkt durch einen einzelnen Fremdschlüssel dargestellt werden. Es erfordert eine Verbindungstabelle (oder Brückentabelle), um die Beziehung in zwei ein-zu-viele-Beziehungen aufzulösen.
- Backend-Auswirkung: Abfragen beinhalten oft drei Tabellen. Sie müssen die Verbindungstabelle explizit in Ihrem Code behandeln, um Verknüpfungen zu verwalten.
Tabelle: Zusammenfassung der Beziehungskardinalität
| Beziehungstyp | Beispiel-Szenario | Implementierungsstrategie | Abfragekomplexität |
|---|---|---|---|
| Eins-zu-Eins (1:1) | Benutzer & Profil | Eindeutiger Fremdschlüssel | Niedrig (Einzelner Join) |
| Eins-zu-Viele (1:N) | Autor & Bücher | Fremdschlüssel auf der Viele-Seite | Mittel (Liste Join) |
| Viele-zu-Viele (M:N) | Studierende & Kurse | Verbindungstabelle | Hoch (Drei-Tabellen-Join) |
Notationsstile und Symbole 📐
Während die Konzepte konsistent bleiben, kann die visuelle Notation je nach Designer des Diagramms variieren. Die Kenntnis der gängigen Stile stellt sicher, dass Sie feine Details nicht übersehen.
Crow’s-Foot-Notation
Diese Notation wird in modernen Datenbank-Design-Tools weit verbreitet verwendet. Sie verwendet spezifische Symbole am Ende der Beziehungslinie, um die Kardinalität anzugeben.
- Einfache Linie: Stellt „Eins“ dar.
- Crow’s-Foot (Drei Äste): Stellt „Viele“ dar.
- Kreis: Stellt „Optional“ (Null) dar.
- Senkrechte Linie: Stellt „Mandatory“ (Eins) dar.
Zum Beispiel zeigt eine Linie mit einer senkrechten Linie auf einer Seite und einem Crow’s-Foot auf der anderen eine Eins-zu-Viele-Beziehung an, bei der die Seite mit „Eins“ verpflichtend ist.
Chen-Notation
Weniger verbreitet in der Anwendungsentwicklung, aber häufig in akademischen oder hochrangigen architektonischen Kontexten. Sie verwendet Diamanten, um Beziehungen darzustellen, anstatt Linien.
- Entitäten:Rechtecke.
- Beziehungen:Diamanten.
- Attribute:Ovale.
Beim Lesen der Chen-Notation konzentrieren Sie sich auf die Diamantenform. Die Kardinalitätsbezeichnungen (1, N, M) werden auf die Linien gesetzt, die den Diamanten mit den Entitäten verbinden.
Schlüssel und Einschränkungen: Die Regeln des Spiels 🔑
Ein ERD ist nicht nur über Verbindungen, sondern auch über Regeln. Einschränkungen gewährleisten die Datenintegrität. Als Backend-Entwickler müssen Sie wissen, welche Einschränkungen von der Datenbank erzwungen werden und welche in der Anwendungslogik behandelt werden müssen.
Primärschlüssel (PK)
Jede Tabelle sollte einen Primärschlüssel haben. Dieser Wert identifiziert jede Zeile eindeutig. Beim Lesen des ERD suchen Sie nach dem unterstrichenen Attribut.
- Surrogatschlüssel:Auto-inkrementierende Ganzzahlen (z. B. ID), die keine geschäftliche Bedeutung haben.
- Natürliche Schlüssel:Geschäftliche Identifikatoren (z. B. E-Mail, SKU), die von Natur aus eindeutig sind.
Warum es wichtig ist: Fremdschlüssel verweisen auf Primärschlüssel. Wenn Sie die Strategie für den Primärschlüssel ändern (z. B. UUID gegenüber Integer), müssen Sie alle abhängigen Fremdschlüssel aktualisieren und möglicherweise die Caching-Ebenen Ihrer Anwendung neu strukturieren.
Fremdschlüssel (FK)
Ein Fremdschlüssel ist ein Feld (oder eine Feldgruppe) in einer Tabelle, das auf den Primärschlüssel in einer anderen Tabelle verweist. Er gewährleistet die Referenzintegrität.
- BEI LÖSCHEN AUSFÜHREN (CASCADE): Wenn der übergeordnete Datensatz gelöscht wird, werden die untergeordneten Datensätze automatisch gelöscht.
- BEI LÖSCHEN EINSCHRÄNKEN (RESTRICT): Verhindert das Löschen des übergeordneten Datensatzes, wenn untergeordnete Datensätze existieren.
- BEI LÖSCHEN AUF NULL SETZEN (SET NULL): Setzt die Fremdschlüsselspalte auf NULL, wenn der übergeordnete Datensatz gelöscht wird.
Das Verständnis dieser Verhaltensweisen ist entscheidend beim Schreiben von Löschendpunkten. Ein Kaskadenlöschen kann unbeabsichtigte Nebenwirkungen haben, wenn das Beziehungsschema komplex ist.
Normalisierung und Datenstruktur 🧹
Beim Analysieren eines ERD sollten Sie auch das Maß der Normalisierung bewerten. Die Normalisierung reduziert Datenredundanz und verbessert die Integrität. Sie ist jedoch nicht immer eine strenge Voraussetzung für die Leistung.
Erste Normalform (1NF)
Alle Spalten müssen atomare Werte enthalten. Keine Listen oder Arrays in einer einzelnen Zelle. Wenn Sie eine Spalte namensTags mit dem Inhalt„tag1, tag2, tag3“, verstößt das Schema gegen die 1NF.
Zweite Normalform (2NF)
Muss in 1NF sein und alle nichtschlüsselbasierten Attribute müssen vollständig vom Primärschlüssel abhängen. Dies erfordert oft das Verschieben von Attributen, die nur teilweise auf einem zusammengesetzten Schlüssel basieren, in eine separate Tabelle.
Dritte Normalform (3NF)
Muss in 2NF sein und keine transitiven Abhängigkeiten aufweisen. WennAbestimmtB, undBbestimmtC, dann A bestimmt C. In 3NF, C sollte nicht in derselben Tabelle wie B.
Denormalisierung in der Praxis
Während Normalisierung das theoretische Ideal darstellt, erfordert die Backend-Entwicklung oft eine Denormalisierung zur Leistungssteigerung. Sie könnten doppelte Daten in einem ERD sehen, der für Geschwindigkeit ausgelegt ist.
- Lesen gegenüber Schreiben: Normalisierte Schemata sind besser für Schreibvorgänge; denormalisierte Schemata sind besser für Lesevorgänge.
- Caching: Manchmal wird Daten doppelt gespeichert, um JOIN-Operationen bei hoch frequentierten Endpunkten zu reduzieren.
Wenn Sie redundant Daten in einem ERD sehen, fragen Sie sich, warum. Ist es ein Gestaltungsfehler oder eine bewusste Optimierungsstrategie?
Lesen zur Backend-Optimierung 🚀
Ein ERD zu lesen geht nicht nur darum, die Datenspeicherung zu verstehen; es geht darum, die Leistung vorherzusehen. Ein gut analysiertes Schema ermöglicht es Ihnen, Abfragen zu schreiben, die Indizes effektiv nutzen.
Identifizieren von Indexierungsmöglichkeiten
Suchen Sie nach Attributen, die häufig in Suchfiltern oder Sortieroperationen verwendet werden. Diese sollten indiziert werden.
- Suchspalten: Attribute, die in WHERE-Klauseln verwendet werden.
- Verknüpfungsspalten: Fremdschlüssel sollten fast immer indiziert werden, um JOINs zu beschleunigen.
- Sortierspalten: Attribute, die in ORDER BY-Klauseln verwendet werden.
Vermeiden von N+1-Abfragen
Der ERD zeigt die Beziehungsstruktur auf. Wenn Sie eine Eins-zu-Viele-Beziehung haben, führt das Abrufen des Eltern-Elements und anschließendes Schleifen zum Einzeln-Abrufen der Kind-Elemente zu einem N+1-Abfrageproblem.
- Lösung: Verwenden Sie vorläufiges Laden oder explizite JOINs basierend auf dem in der ERD definierten Beziehungsverlauf.
- Warnung:Komplexe Many-to-Many-Beziehungen können leicht zu Leistungsproblemen führen, wenn die Verbindungstabelle nicht auf beiden Fremdschlüsselspalten indiziert ist.
Häufige Fehler bei der Schema-Design ⚠️
Selbst erfahrene Architekten machen Fehler. Wenn Sie ein ERD lesen, achten Sie auf Anzeichen eines schlechten Designs, die später zu Problemen führen könnten.
1. Zirkuläre Abhängigkeiten
Wenn Entity A von Entity B abhängt und Entity B von Entity A abhängt, erzeugen Sie eine zirkuläre Abhängigkeit. Dies kann zu Deadlocks während der Transaktionscommit-Vorgänge oder komplexer Initialisierungslogik führen.
2. Ungleichgewichtige Kardinalität
Manchmal wird eine Many-to-Many-Beziehung falsch als One-to-Many in beide Richtungen modelliert, was zu Daten-Duplikation oder Informationsverlust führen kann.
3. Fehlende Metadaten
Ein ERD, das keine Zeitstempel (created_at, updated_at) enthält, macht Auditing und Debugging schwierig. Backend-Systeme benötigen diese Daten oft für weiche Löschungen oder Versionierung.
4. Über-Normalisierung
Zu viele Tabellen können dazu führen, dass einfache Abfragen übermäßige Joins erfordern und die Anwendung verlangsamen. Suchen Sie nach Tabellen, die logisch zusammengefasst werden könnten, wenn sie dasselbe Lebenszyklus haben.
Praktische Anwendung: Von der Darstellung zum Code 💻
Sobald Sie das ERD verstanden haben, ist der nächste Schritt die Übersetzung in Anwendungslogik. Dieser Prozess beinhaltet die Abbildung des visuellen Modells auf Ihre Codebasis.
1. Modell-Zuordnung
Jede Entität wird zu einer Klasse oder einem Modell in Ihrem Code. Attribute werden zu Eigenschaften. Beziehungen werden zu Assoziationen oder Methoden.
- Eins-zu-Eins:Eigenschaft für ein einzelnes Objekt.
- Eins-zu-Viele:Eigenschaft für eine Sammlung oder Liste.
- Viele-zu-Viele:Sammlung verwandter Modelle über eine Brücke.
2. API-Design
Das ERD bestimmt Ihre API-Struktur. Ein normalisiertes Schema führt oft zu verschachtelten JSON-Antworten oder getrennten Endpunkten für verwandte Ressourcen. Zum Beispiel könnte ein /bestellungenEndpunkt eine /bestellpositionenverschachtelte Struktur enthalten.
3. Validierungslogik
Einschränkungen im ERD (wie NOT NULL) sollten in der Anwendungslogik nachgebildet werden. Wenn die Datenbank einen NULL-Wert zulässt, Ihre Geschäftslogik aber einen Wert erfordert, muss die Anwendung diese Regel vor dem Senden der Daten an die Datenbank durchsetzen.
Aufrechterhaltung der Schema-Integrität im Laufe der Zeit 🔧
Ein ERD ist nicht statisch. Je nach Entwicklung der Anwendung ändert sich das Schema. Ihre Fähigkeit, den ERD zu lesen, hilft Ihnen, Migrationen effektiv zu verwalten.
1. Umgang mit Migrationen
Wenn Sie eine neue Tabelle oder Beziehung hinzufügen, aktualisieren Sie den ERD sofort. Dadurch stellen Sie sicher, dass Ihr Team einen aktuellen Überblick über das System hat. Migrationen sollten versioniert und an der aktuellen Schemastruktur getestet werden.
2. Refactoring
Beim Refactoring geht es oft darum, Tabellen zu teilen oder zusammenzuführen. Das Verständnis der Beziehungslinien hilft Ihnen zu erkennen, welche Daten verschoben werden müssen und welche Fremdschlüssel aktualisiert werden müssen.
3. Dokumentation
Ein ERD ist ein lebendiges Dokument. Wenn das Diagramm nicht mit der Datenbank übereinstimmt, ist es nutzlos. Regelmäßige Audits stellen sicher, dass die visuelle Darstellung der physischen Realität entspricht.
Fortgeschrittene Konzepte: Rekursive Beziehungen 🔁
Manchmal bezieht sich eine Entität auf sich selbst. Dies wird als rekursive Beziehung bezeichnet.
- Beispiel: Ein MitarbeiterEntität, bei der ein Mitarbeiter andere leitet.
- Implementierung:Ein Fremdschlüssel in derselben Tabelle verweist auf den Primärschlüssel derselben Tabelle.
- Backend-Logik:Erfordert rekursive Abfragen oder Durchlaufalgorithmen, um alle Unterstellten oder die vollständige Hierarchie zu finden.
Das Erkennen dieses Musters im ERD ist entscheidend für die Entwicklung von Funktionen wie Organigrammen oder kommentierten Threads.
Zusammenfassung der wichtigsten Erkenntnisse 📝
Die Beherrschung des ERD ist ein kontinuierlicher Prozess der Beobachtung und Übung. Es erfordert Geduld, jede Linie nachzuverfolgen und die Auswirkungen jedes Symbols zu verstehen. Indem Sie sich auf die Komponenten, Beziehungen und Einschränkungen konzentrieren, bauen Sie ein mentales Modell auf, das Ihre Entwicklung leitet.
- Kennen Sie Ihre Symbole:Unterscheiden Sie zwischen Entitäten, Attributen und Beziehungen.
- Verstehen Sie die Kardinalität:Kennen Sie den Unterschied zwischen 1:1, 1:N und M:N.
- Prüfen Sie Einschränkungen:Suchen Sie nach Schlüsseln und Nullwertregeln.
- Berücksichtigen Sie die Leistung:Verwenden Sie den ERD zur Planung von Indizierung und Abfrageoptimierung.
- Halten Sie es aktuell: Stellen Sie sicher, dass das Diagramm den aktuellen Zustand der Datenbank widerspiegelt.
Wenn Sie Ihre Reise als Backend-Entwickler fortsetzen, lassen Sie das ERD Ihre Richtschnur sein. Es liefert den Kontext, der erforderlich ist, um fundierte Entscheidungen über die Datenarchitektur zu treffen und sicherzustellen, dass die Systeme, die Sie entwickeln, nicht nur funktional, sondern auch widerstandsfähig und effizient sind.
Abschließende Gedanken zur Schema-Verständlichkeit 🎓
Die Fähigkeit, ein ERD effektiv zu lesen, unterscheidet einen Programmierer von einem Ingenieur. Sie verlagert den Fokus von der bloßen Funktion des Codes hin zur Verständnis der Datenverhaltens unter Last, der Persistenz und der Beziehungen zu anderen Informationen. Diese Fähigkeit verringert die Debug-Zeit, verbessert die Zusammenarbeit mit Datenteams und führt zu einer besseren Systemgestaltung.
Nehmen Sie sich die Zeit, die Diagramme in Ihren Projekten zu studieren. Fragen Sie nach den Gründen, warum bestimmte Beziehungen gewählt wurden. Fordern Sie die Gestaltung heraus, wenn Sie Unzulänglichkeiten erkennen. Auf diese Weise tragen Sie zu einem gesünderen Datenökosystem und einer stabileren Anwendung bei.
Denken Sie daran, dass die Datenbank die Quelle der Wahrheit ist. Behandeln Sie das ERD wie eine Karte zu dieser Wahrheit. Mit Übung wird das Lesen dieser Diagramme zur zweiten Natur, sodass Sie komplexe Datenlandschaften mit Vertrauen und Präzision navigieren können.