











バックエンドエンジニアリングの複雑な世界において、データはアプリケーションを構築する基盤となる。そのデータを操作するコードを書くことが中心的な責任である一方で、データそのものの構造を理解することも同様に重要である。エンティティ関係図(ERD)は、この構造の設計図として機能する。情報がどのように格納され、リンクされ、取得されるかを伝える視覚的な言語である。バックエンド開発者にとって、ERDを流暢に読み解く能力は、単なる望ましいスキルではなく、堅牢でスケーラブルかつ保守可能なシステムを設計するための基本的な要件である。
多くの開発者は、スキーマのアーキテクチャを十分に理解せずに、いきなりクエリの記述に取り掛かる。これにより、パフォーマンスのボトルネックやデータ整合性の問題が発生し、後々に難しいリファクタリング作業を強いられることがよくある。ERDを正しく解釈する技術を習得することで、データがアプリケーション内でどのように流れ、ある領域の変更が全体のデータベースにどのような影響を及ぼすかを予見できるようになる。このガイドでは、ERDの読み方のメカニズムに焦点を当て、抽象的な理論ではなく実践的な応用に重点を置いている。
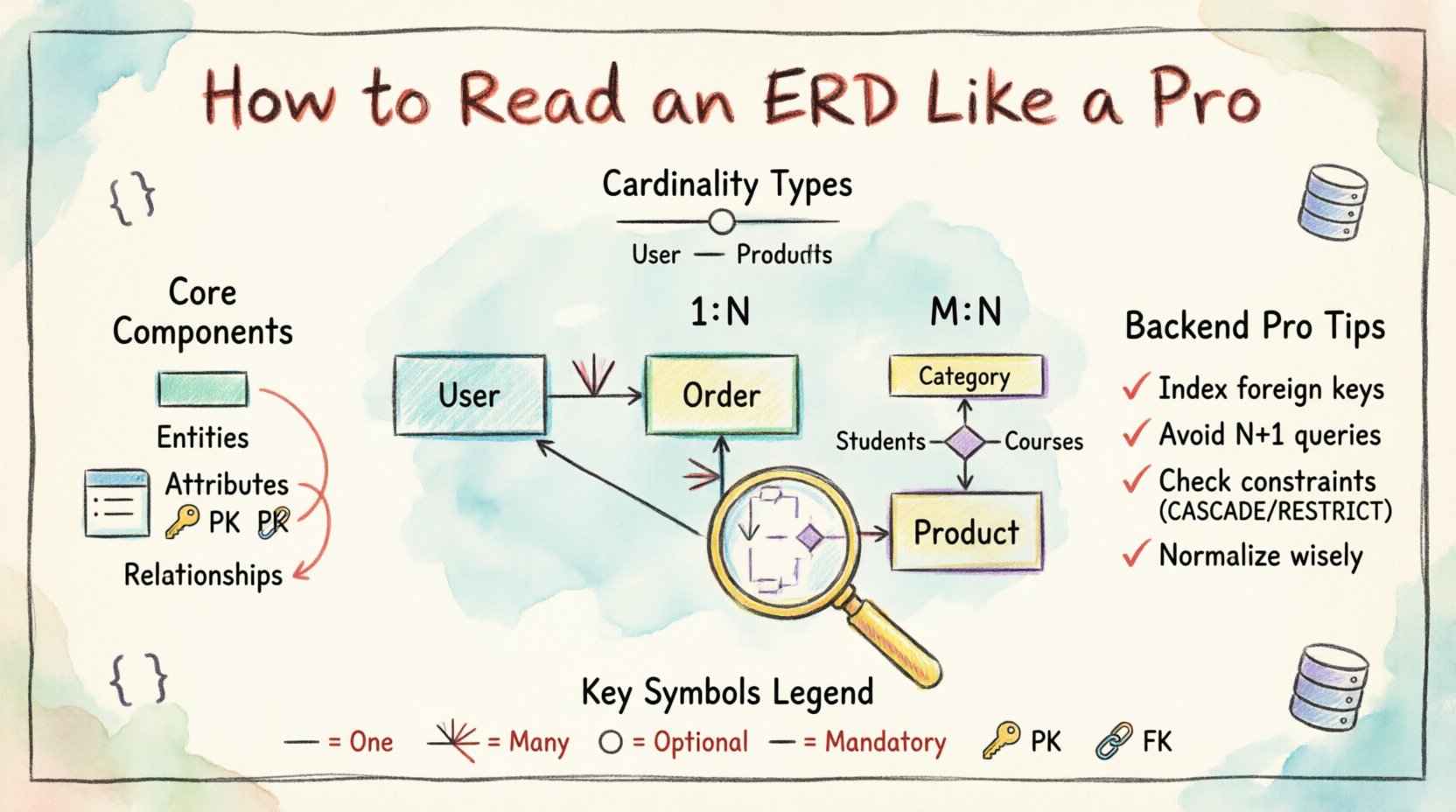
ERDのコアとなる要素を理解する 🧱
接続を理解する前に、図を構成する個々の記号を理解する必要がある。ERDは、データモデルの特定の側面をそれぞれ表す複数の異なる要素で構成されている。これらの要素を即座に認識できれば、線に迷うことなく複雑なスキーマを読み解くことができる。
1. エンティティ(テーブル)
ERDの最も目立つ特徴はエンティティである。リレーショナルデータベースの文脈では、エンティティはテーブルに直接対応する。これは、データが格納される対象となる明確なオブジェクトまたは概念を表す。名前が「顧客」または「注文」とラベル付けされた長方形を見たとき、それはテーブルを指している。
- 視覚的インジケーター:通常は名前を含む長方形またはボックス。
- 機能:関連するデータ属性をまとめる。
- バックエンドへの影響:すべてのエンティティは、通常、コードベース内のクラスまたはモデルに対応する。
エンティティを読む際は、内部のテキストに注意を払うべきだ。場合によっては、属性(列)を明示的にリストしている。また、別のドキュメントファイルに詳細が保存されている抽象的な表現の場合もある。いずれにせよ、エンティティ名はシステムの名詞を示している。
2. 属性(列)
属性はエンティティの性質を定義する。エンティティがテーブルである場合、属性はそのテーブル内の列に相当する。各レコードに必要な特定のデータポイントを説明する。
- 主キー:通常、下線を引くか、鍵のアイコンでマークされる。これにより、各行が一意に識別される。
- 外部キー:通常、別のエンティティに接続する線で示される。これにより関係が確立される。
- データ型:視覚的に常に表示されるわけではないが、経験豊富な読者は文脈に基づいてデータ型を推測する(例:「email_address」というフィールド名は文字列を意味し、created_at」というフィールド名はタイムスタンプを意味する)。
属性を理解することは、効率的なクエリを書くために不可欠です。属性にインデックスが設定されていない場合、その属性を検索するとフルテーブルスキャンが発生します。もし外部キーである場合、結合操作を決定します。
3. 関係性(線)
関係性は、エンティティが互いにどのように相互作用するかを定義します。これらの線は2つのエンティティを結び、基数(何個か)を説明します。これはバックエンドロジックのためのERDを読む上で最も重要な部分であり、データがテーブル間でどのようにリンクされるかを決定するからです。
- 方向性:線の端には、方向性を示すために矢印や記号がよく付いています。
- 基数:関係性が1対1、1対多、または多対多であるかどうかを指定します。
- 選択的:実線と破線で示されることがあり、関係性が必須かオプションかを示します。
基数と関係性の解読 🔗
基数はERDの核です。データベースの関係性における制約や論理を決定します。基数を誤解すると、データの重複や孤立レコードが生じる可能性があります。あなたが遭遇するであろう3つの主要な関係性の種類を確認しましょう。
1. 1対1(1:1)
Table Aの1つのレコードがTable Bの正確に1つのレコードに関連し、その逆も成り立つ場合にこの関係性が存在します。
- 使用例:セキュリティやパフォーマンスのため、大きなテーブルを分割する。例えば、Userプロフィールは、User_Settingsテーブルから分離されることがある。
- 実装方法:1つのテーブルの外部キーが、もう1つのテーブルの主キーを参照し、しばしば一意制約が付加される。
- バックエンドへの影響:完全なデータを取得するには結合が通常必要ですが、論理は明確です。
2. 1対多(1:N)
これはリレーショナルデータベースで最も一般的な関係性です。Table Aの1つのレコードは、Table Bの複数のレコードに関連することができるが、Table Bの各レコードはTable Aの1つのレコードにのみ関連します。
- 使用例: 1つのCategory に複数のProducts.
- 実装: 外部キーは「多数」側のテーブル(Products)にあり、「単数」側(Category)を参照しています。
- バックエンドへの影響: カテゴリを取得する際には、しばしば製品のリストを読み込みます。製品を取得する際には、単一のカテゴリを読み込みます。
3. 多対多(M:N)
この関係は、Table A のレコードが Table B の複数のレコードとリンク可能であり、Table B のレコードも Table A の複数のレコードとリンク可能である場合に発生します。
- 使用例: 学生が複数の授業に登録し、授業が複数の学生を持つ。
- 実装: これは単一の外部キーでは直接表現できません。関係を二つの1対多関係に分解するために、結合テーブル(またはブリッジテーブル)が必要です。
- バックエンドへの影響: クエリはしばしば3つのテーブルを含みます。関連付けを管理するために、コード内で結合テーブルを明示的に扱う必要があります。
表:関係の基数の要約
| 関係の種類 | 例のシナリオ | 実装戦略 | クエリの複雑さ |
|---|---|---|---|
| 1対1(1:1) | ユーザーとプロフィール | 一意の外部キー | 低(単一結合) |
| 1対多(1:N) | 著者と本 | 多数側への外部キー | 中(リスト結合) |
| 多対多(M:N) | 学生と授業 | 結合テーブル | 高(3テーブル結合) |
表記スタイルと記号 📐
概念は一貫しているものの、図の視覚的表記は誰が設計したかによって異なる場合があります。一般的なスタイルに精通しておくことで、微細な詳細を見逃すことを防げます。
クロウズフット表記
これは現代のデータベース設計ツールで広く使われています。関係線の端に特定の記号を使用して、基数を示します。
- 単線: 「1」を表します。
- クロウズフット(3本の枝): 「複数」を表します。
- 円: 「オプション」(ゼロ)を表します。
- 垂直バー: 「必須」(1)を表します。
たとえば、片側に垂直バー、もう片側にクロウズフットがある線は、『1対多』の関係を示し、『1』側が必須であることを意味します。
チェン表記
アプリケーション開発ではあまり使われないが、学術的または高レベルのアーキテクチャ的文脈ではよく見られる。関係を線ではなく、菱形で表す。
- エンティティ:長方形。
- 関係:菱形。
- 属性:楕円。
チェン表記を読む際は、菱形の形状に注目してください。基数ラベル(1、N、M)は、菱形とエンティティを結ぶ線の上に配置されます。
キーと制約:ルールの世界 🔑
ERDはつながりだけを扱うものではありません。ルールの世界です。制約はデータの整合性を保証します。バックエンド開発者として、データベースが強制する制約と、アプリケーションロジックで処理しなければならない制約を把握しておく必要があります。
主キー(PK)
すべてのテーブルには主キーが必要です。この値が各行を一意に識別します。ERDを読む際は、下線が引かれた属性を探してください。
- 代替キー:ビジネス上の意味を持たない自動増分整数(例:ID)
- 自然キー:本来から一意であるビジネス識別子(例:メールアドレス、SKU)
なぜ重要なのか:外部キーは主キーを参照します。主キーの戦略(例:UUID vs. 整数)を変更する場合、すべての依存する外部キーを更新し、アプリケーションのキャッシュレイヤーを再構成する必要があるかもしれません。
外部キー(FK)
外部キーとは、あるテーブル内のフィールド(または複数のフィールド)で、別のテーブルの主キーを参照するものです。参照整合性を保証します。
- ON DELETE CASCADE: 親レコードが削除されると、子レコードも自動的に削除されます。
- ON DELETE RESTRICT: 子レコードが存在する場合、親の削除を禁止します。
- ON DELETE SET NULL: 親が削除された場合、外部キー列をNULLに設定します。
削除エンドポイントを記述する際には、これらの動作を理解することが不可欠です。関係グラフが複雑な場合、カスケード削除は予期しない副作用を引き起こす可能性があります。
正規化とデータ構造 🧹
ERDを分析する際には、正規化のレベルも評価するべきです。正規化はデータの重複を減らし、整合性を向上させます。ただし、パフォーマンスのためには必ずしも厳密な要件とは限りません。
第一正規形(1NF)
すべての列は原子値を含む必要があります。1つのセルにリストや配列を含めることはできません。列名が「tags」に「tag1, tag2, tag3」のような値が含まれている場合、スキーマは1NFに違反しています。」に「tag1, tag2, tag3」のような値が含まれている場合、スキーマは1NFに違反しています。
第二正規形(2NF)
1NFに準拠している必要があり、すべての非キー属性は主キーに完全に依存しなければなりません。これは、複合キーの一部にのみ依存する属性を別テーブルに移動する場合が多いです。
第三正規形(3NF)
2NFに準拠している必要があり、推移的依存関係が存在してはなりません。もしAがBを決定し、BがC、その後Aは…を決定するC。3NFでは、Cは、同じテーブル内に存在してはならないB.
実践における非正規化
正規化は理論上の理想であるが、バックエンド開発ではパフォーマンス向上のため、非正規化を必要とする場合が多い。スピードを重視したERDでは、重複データが見られることがある。
- 読み込み vs. 書き込み:正規化されたスキーマは書き込みに適している。非正規化されたスキーマは読み込みに適している。
- キャッシュ:場合によっては、高トラフィックのエンドポイントでのJOIN操作を減らすために、データを重複させることがある。
ERDに冗長なデータが見られたら、その理由を問い直すべきだ。これは設計上の欠陥なのか、それとも意図的な最適化戦略なのか。
バックエンド最適化のための読み方 🚀
ERDを読むことは、データの保存方法を理解することだけではない。パフォーマンスを予測することでもある。適切に読み解かれたスキーマがあれば、インデックスを効果的に活用できるクエリを書くことができる。
インデックス化の機会を特定する
検索フィルターや並べ替え操作で頻繁に使用される属性を探せ。これらの属性はインデックス化すべきである。
- 検索カラム:WHERE句で使用される属性。
- 結合カラム:外部キーはほとんど常にインデックス化され、JOINの高速化に役立つ。
- 並べ替えカラム:ORDER BY句で使用される属性。
N+1クエリの回避
ERDは関係構造を明らかにする。1対多の関係がある場合、親を取得してからループで子を個別に取得すると、N+1クエリ問題が発生する。
- 解決策:ERDで定義された関係パスに基づいて、エイジングロードまたは明示的なJOINを使用する。
- 警告: 複雑な多対多の関係は、結合テーブルが両方の外部キー列にインデックスが張られていない場合、簡単にパフォーマンス上の問題を引き起こす可能性があります。
スキーマ設計における一般的な落とし穴 ⚠️
経験豊富なアーキテクトですらミスを犯します。ERDを読む際は、後で問題を引き起こす可能性のある悪い設計の兆候を探してください。
1. 円環依存
エンティティAがエンティティBに依存し、エンティティBがエンティティAに依存する場合、円環依存が生じます。これはトランザクションのコミット中にデッドロックを引き起こすか、複雑な初期化ロジックを必要とする可能性があります。
2. バランスの取れていない基数
時折、多対多の関係が、両方向に一対多として誤ってモデル化され、データの重複や情報の喪失を引き起こします。
3. メタデータの欠落
タイムスタンプ(created_at、updated_at)が欠けたERDは、監査やデバッグを困難にします。バックエンドシステムでは、ソフトデリートやバージョン管理のためにこのデータをしばしば必要とします。
4. 過剰正規化
テーブルが多すぎると、単純なクエリでも過剰な結合を必要とし、アプリケーションの速度を低下させることがあります。同じライフサイクルを持つテーブルは論理的に統合できる可能性があるかを確認してください。
実践的応用:図からコードへ 💻
ERDを理解したら、次にその内容をアプリケーションロジックに変換する段階です。このプロセスでは、視覚的なモデルをコードベースにマッピングします。
1. モデルマッピング
各エンティティはコード内のクラスまたはモデルになります。属性はプロパティになります。関係は関連付けやメソッドになります。
- 1対1: 単一のオブジェクトプロパティ。
- 1対多: コレクションまたはリストプロパティ。
- 多対多: ブリッジを介して関連モデルのコレクション。
2. API設計
ERDがAPIの構造を決定します。正規化されたスキーマは、ネストされたJSON応答や関連リソースのための別々のエンドポイントをもたらすことがよくあります。たとえば、/orders エンドポイントには、/order-items というネスト構造を含むことがあります。
3. 検証ロジック
ERD内の制約(NOT NULLなど)は、アプリケーションレベルの検証にも反映されるべきです。データベースがNULL値を許可しているが、ビジネスロジックで値が必要な場合、アプリケーションはデータをデータベースに送信する前にそのルールを強制しなければなりません。
時間の経過に伴うスキーマの整合性の維持 🔧
ERDは静的ではありません。アプリケーションが進化するにつれて、スキーマも変化します。ERDを読み解く力があることで、移行を効果的に管理できます。
1. 移行の処理
新しいテーブルや関係性を追加する際は、ERDを直ちに更新してください。これにより、チームがシステムの最新状態を把握できるようになります。移行はバージョン管理され、現在のスキーマ構造に対してテストされるべきです。
2. リファクタリング
リファクタリングでは、テーブルを分割したり統合したりすることがよくあります。関係性の線を理解することで、どのデータを移動する必要があるか、どの外部キーを更新する必要があるかを判断できます。
3. ドキュメント化
ERDは動的な文書です。図がデータベースと一致しなければ、無意味です。定期的な監査により、視覚的な表現が物理的な現実と一致していることを確認できます。
高度な概念:再帰的関係 🔁
時折、エンティティが自分自身と関係を持つことがあります。これを再帰的関係と呼びます。
- 例: ある 従業員エンティティで、1人の従業員が他の従業員のマネージャーとなるもの。
- 実装:同じテーブル内の外部キーが、同じテーブルの主キーを指す。
- バックエンドロジック:すべての部下や完全な階層を検索するには、再帰クエリまたは走査アルゴリズムが必要です。
ERDでこのパターンを認識することは、組織図やスレッド付きコメントのような機能を構築する上で不可欠です。
主なポイントの要約 📝
ERDを習得することは、観察と実践を繰り返す継続的なプロセスです。すべての線をたどり、各記号の意味を理解するには忍耐が必要です。コンポーネント、関係性、制約に注目することで、開発を導く心のモデルを構築できます。
- 記号を理解する:エンティティ、属性、関係性を区別する。
- 基数を理解する:1:1、1:N、M:Nの違いを把握する。
- 制約を確認する:キーとnull許容ルールを探る。
- パフォーマンスを考慮する:ERDを活用してインデックス作成とクエリ最適化を計画する。
- 常に最新の状態に保つ: 図面が現在のデータベース状態を正確に反映していることを確認してください。
バックエンド開発者の道を歩み続ける中で、ERDをあなたの羅針盤としてください。データアーキテクチャに関する情報に基づいた意思決定に必要な文脈を提供し、あなたが構築するシステムが機能的であるだけでなく、耐障害性と効率性も確保されます。
スキーマリテラシーについてのまとめ 🎓
ERDを効果的に読み解く力は、コーダーとエンジニアを分けるものです。コードが動くことだけに注目するのではなく、データが負荷下でどのように振る舞うか、どのように永続化されるか、他の情報とどのように関係しているかを理解するようになります。このスキルはデバッグ時間の短縮、データチームとの連携の向上、そしてより良いシステム設計につながります。
プロジェクト内の図面をじっくりと学ぶ時間を取ってください。特定の関係性が選ばれた理由について質問してください。非効率さが見られたら設計に疑問を呈してください。こうすることで、より健全なデータエコシステムとより安定したアプリケーションの構築に貢献できます。
思い出してください。データベースは真実の源です。ERDをその真実への地図として扱いましょう。練習を重ねれば、これらの図面を読むことが自然なことになり、複雑なデータの地図を自信と正確さを持って進むことができるようになります。