











Datenerfassungsmodellierung wird oft als statische Aufgabe angesehen, bei der Beziehungen und Entitäten definiert werden. Ein Entity-Relationship-Diagramm (ERD) ist jedoch nicht nur eine Bauplan für die Speicherung; es ist ein direkter Bestimmungsfaktor dafür, wie effizient eine Datenbankengine Informationen abruft und verarbeitet. Jede Linie, die gezeichnet wird, jede definierte Beziehung und jede gewählte Datentypen wirkt sich auf den Ausführungsplan Ihrer Abfragen aus. Das Verständnis der Mechanismen hinter der Schema-Design ermöglicht Systeme, die sich unter Last reibungslos skalieren lassen.
Diese Anleitung untersucht die technische Beziehung zwischen ERD-Strukturen und der Abfrageleistung. Wir werden über die grundlegenden Definitionen hinausgehen, um zu untersuchen, wie bestimmte Modellierungsentscheidungen die I/O-Operationen, die CPU-Nutzung und die Sperrmechanismen in einer relationalen Umgebung beeinflussen.
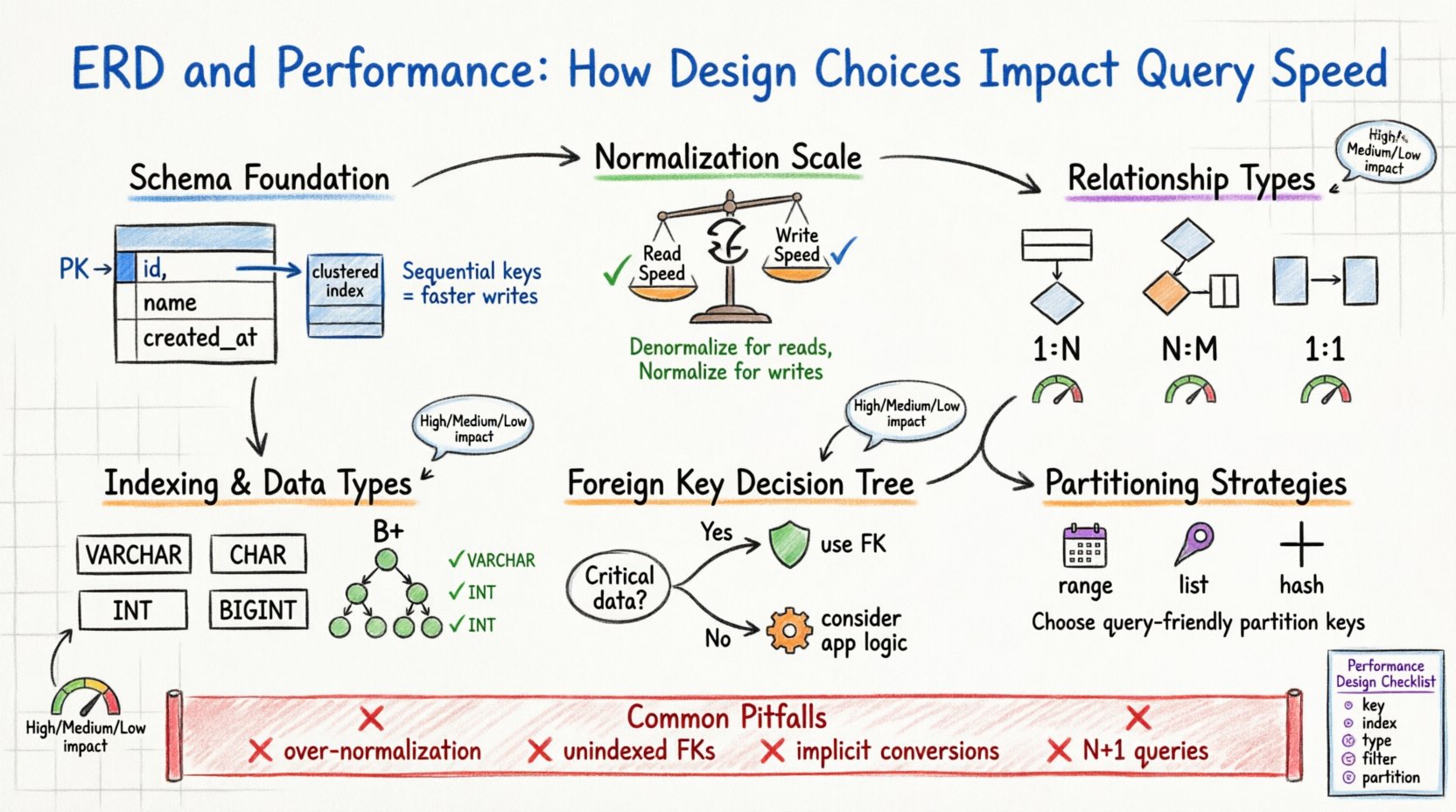
1. Die Grundlage: Schema-Struktur und physische Speicherung 🏗️
Die logische Gestaltung, die Sie in Ihrem ERD erstellen, wird letztendlich in physische Dateien auf einer Festplatte übersetzt. Die Datenbankengine muss diese logischen Entitäten auf Seiten, Blöcke und Zeilen abbilden. Wenn das Schema optimiert ist, minimiert die Engine die Anzahl der Festplattenlesevorgänge, die zur Erfüllung einer Anfrage erforderlich sind. Wenn dies nicht der Fall ist, kann die Engine gezwungen werden, vollständige Tabellenscans durchzuführen, was kostspielige Operationen sind.
Berücksichtigen Sie den Primärschlüssel. Er dient als eindeutiger Bezeichner für eine Zeile. In vielen Speicher-Engines definiert der Primärschlüssel die physische Reihenfolge der Daten auf der Festplatte (geclusterter Index). Die Wahl eines sequenziellen und kurzen Primärschlüssels stellt sicher, dass die Daten kontinuierlich gespeichert werden. Dies reduziert die Fragmentierung und ermöglicht schnellere Bereichsscans. Im Gegenteil kann ein zufälliger, langer Primärschlüssel bei Einfügungen zu Seitensplits führen, was die Schreibleistung verschlechtert und die Speicheraufwände erhöht.
Wichtige Überlegungen zu Primärschlüsseln
- Reihenfolge:Auto-incrementierende Ganzzahlen werden typischerweise für schreibintensive Workloads bevorzugt.
- Größe:Kleinere Schlüssel reduzieren die Größe sekundärer Indizes, da sie in diesen Indizes als Zeiger gespeichert werden.
- Stabilität:Primärschlüssel sollten sich nicht ändern. Die Aktualisierung eines Primärschlüssels erfordert oft die Aktualisierung aller zugehörigen Fremdschlüssel.
2. Normalisierung im Vergleich zu Leistungsabwägungen ⚖️
Die Normalisierung ist der Prozess der Organisation von Daten, um Redundanz zu reduzieren und die Integrität zu verbessern. Obwohl sie traditionell mit Datenqualität assoziiert wird, hat sie tiefgreifende Auswirkungen auf die Leistung. Ein stark normalisiertes Schema (z. B. dritte Normalform) erfordert oft mehr Joins, um Daten wiederherzustellen, während ein de-normalisiertes Schema Joins reduziert, dafür aber Speicherplatz und Aktualisierungskomplexität erhöht.
Die Entscheidung, zu normalisieren oder zu de-normalisieren, ist ein Ausgleich zwischen Lese- und Schreibgeschwindigkeit. In einer umfangreichen Leseumgebung kann die De-normalisierung die Abfragezeit erheblich reduzieren, indem komplexe Joins vermieden werden. In einer umfangreichen Schreibumgebung reduziert die Normalisierung die Anzahl der Zeilen, die über mehrere Tabellen hinweg aktualisiert werden müssen.
Analyse der Auswirkungen der Normalisierung
| Aspekt | Stark normalisiert | De-normalisiert |
|---|---|---|
| Leseleistung | Niedriger (erfordert Joins) | Höher (Zugriff auf eine einzige Tabelle) |
| Schreibleistung | Höher (geringe Redundanz) | Niedriger (Aktualisierung mehrerer Kopien) |
| Datenintegrität | Hoch (einziges Quell-Element) | Niedriger (Risiko von Inkonsistenzen) |
| Speicherausnutzung | Niedriger | Höher |
3. Fremdschlüssel und Integritäts-Overhead 🔗
Fremdschlüssel gewährleisten die Referenzintegrität. Sie stellen sicher, dass ein Wert in einer Tabelle mit einem Wert in einer anderen Tabelle übereinstimmt. Während dies verwaiste Datensätze verhindert, führt dies zu Laufzeit-Overhead. Beim Einfügen, Aktualisieren oder Löschen einer Zeile muss die Datenbank die Fremdschlüssel-Beschränkung überprüfen.
Diese Überprüfung ist nicht kostenlos. Die Engine muss die referenzierte Zeile finden und deren Existenz überprüfen. Wenn die referenzierte Tabelle groß ist und keinen Index auf der Fremdschlüsselspalte besitzt, wird die Überprüfung zu einer vollständigen Tabellen-Durchsuchung. Außerdem muss beim Löschen eines übergeordneten Datensatzes die Engine alle untergeordneten Datensätze überprüfen, um sicherzustellen, dass keine Verweise verbleiben, was möglicherweise viele Zeilen sperren kann.
Wann Fremdschlüssel verwendet werden sollten
- Kritische Datenintegrität: Wenn die Datenkorrektheit entscheidend ist (z. B. Finanztransaktionen), sollten Fremdschlüssel verwendet werden.
- Anwendungslogik: Wenn die Anwendungslogik komplex ist, vereinfacht die Übertragung der Integritätsprüfung auf die Datenbank den Code.
- Kleine Datensätze: Der Overhead ist bei kleinen Tabellen vernachlässigbar.
Wann Fremdschlüssel vermieden werden sollten
- Hoher Schreibdurchsatz: Das Entfernen von Beschränkungen kann den Sperrkonflikt reduzieren.
- Großflächige Analytik: In Data-Warehousing überwiegt die Leistung oft die strikte Integrität.
- Architektonische Schichten: In Microservices ist die Aufrechterhaltung von Fremdschlüsseln über Dienstgrenzen hinweg oft unpraktisch.
4. Indizierungsstrategien und Spaltentypen 📑
Ein ERD definiert die Datentypen für jede Spalte. Die Wahl zwischen VARCHAR und CHAR oder zwischen INT und BIGINT beeinflusst, wie Daten gespeichert und indiziert werden. Kleinere Datentypen verbrauchen weniger Speicherplatz und Festplattenspeicher, sodass mehr Daten in den Pufferpool (RAM) passen.
Wenn eine Abfrage auf einer Spalte filtert, verlässt sich die Datenbankengine auf Indizes, um Zeilen schnell zu finden. Wenn die Schema-Design nicht mit den Abfrage-Mustern übereinstimmt, werden Indizes nutzlos. Zum Beispiel ist die Erstellung eines Indexes auf einer Spalte, die selten in WHERE-Klauseln verwendet wird, eine Verschwendung von Ressourcen.
Optimierung von Spaltentypen
- Festlänge vs. variabler Länge: Verwenden Sie CHAR für Daten mit fester Länge (z. B. Ländercodes), um Fragmentierung zu reduzieren. Verwenden Sie VARCHAR für Daten mit variabler Länge.
- Integer-Bereiche: Verwenden Sie BIGINT nicht, wenn INT ausreicht. Kleinere Ganzzahlen passen pro Seite mehr Zeilen.
- Boolesche Darstellung: Verwenden Sie TINYINT(1) oder BOOLEAN-Typen anstelle von ‘Ja’/ ‘Nein’-Zeichenketten.
5. Implikationen der Beziehungskardinalität 📊
Die Kardinalität von Beziehungen (Eins-zu-Eins, Eins-zu-Viele, Viele-zu-Viele) bestimmt, wie Daten verknüpft werden. Jede Beziehungstyp hat unterschiedliche Leistungsmerkmale.
Eins-zu-Viele (1:N)
Dies ist die häufigste Beziehung. Eine übergeordnete Tabelle enthält einen Datensatz, und die untergeordnete Tabelle enthält viele. Die Leistung hängt stark vom Index in der Fremdschlüsselspalte der untergeordneten Tabelle ab. Ohne diesen Index erfordert die Suche nach allen Kindern eines Elterns die vollständige Durchsuchung der gesamten untergeordneten Tabelle.
Viele-zu-Viele (N:M)
Dies erfordert eine Verbindungstabelle (assoziatives Entität). Dies fügt eine zusätzliche Schicht der Indirektheit hinzu. Abfragen, die N:M-Beziehungen betreffen, erfordern typischerweise drei Joins: Tabelle A, Verbindungstabelle, Tabelle B. Diese Komplexität erhöht die CPU-Auslastung und den Speicherverbrauch.
Eins-zu-Eins (1:1)
Häufig verwendet, um eine große Tabelle in logische Gruppen aufzuteilen. Dies kann die Leistung verbessern, wenn nur eine Teilmenge von Spalten häufig abgefragt wird. Allerdings fügt es die Kosten eines Joins hinzu, um den vollständigen Datensatz abzurufen.
6. Überlegungen zur Partitionierung und Sharding 🗃️
Wenn die Daten wachsen, kann eine einzelne Tabelle zu groß werden, um sie effizient zu verwalten. Die Partitionierung ermöglicht es, eine große Tabelle basierend auf einem Schlüssel (z. B. Datum) in kleinere, überschaubarere Teile zu unterteilen. Das ERD-Design muss dies vorab berücksichtigen.
Wenn Sie ein Schema für ein System entwerfen, das später sharded wird (auf mehrere Server verteilt), muss der Partitionsschlüssel sorgfältig gewählt werden. Der Schlüssel sollte häufig in Abfragen verwendet werden, damit die Engine Anfragen an den richtigen Shard weiterleiten kann. Die Wahl eines Schlüssels, der nicht in Abfragen verwendet wird, zwingt das System, Daten aus allen Shards zu aggregieren, was langsam ist.
Partitionierungsstrategien
- Bereichs-Partitionierung: Aufteilung nach Datums- oder ID-Bereichen. Gut geeignet für Zeitreihendaten.
- Liste-Partitionierung: Aufteilung nach spezifischen Werten (z. B. Regionscodes).
- Hash-Partitionierung: Verteilt die Daten gleichmäßig, um Hotspots zu vermeiden.
7. Häufige Fehler bei der Gestaltung 🚫
Selbst erfahrene Architekten können durch Gestaltungsentscheidungen Leistungsengpässe verursachen. Die Erkennung dieser Muster früh verhindert kostspielige Umgestaltungen später.
- Über-Normalisierung: Die Aufteilung der Daten in zu viele kleine Tabellen erhöht die Joinkomplexität und verringert die Cacheeffizienz.
- Ignorieren der Selektivität: Die Indizierung von Spalten mit geringer Selektivität (z. B. Geschlecht oder Status-Flags) führt oft zu schlechter Leistung, da der Optimierer den Index möglicherweise ignorieren und die Tabelle dennoch vollständig scannen könnte.
- Implizite Konvertierungen: Die Gestaltung einer Spalte als Zeichenkette, wenn numerische Werte erwartet werden, zwingt die Engine, Typen während Abfragen zu konvertieren, wodurch die Nutzung von Indizes verhindert wird.
- N+1-Abfrage-Muster: Die Gestaltung von Beziehungen, die das Abrufen von Daten in Schleifen anstelle von gruppierten Joins fördern, kann den Server überlasten.
8. Zukunftsorientierung und Entwicklung 🛡️
Datenbanken entwickeln sich weiter. Anforderungen ändern sich, und neue Funktionen werden hinzugefügt. Ein Schema, das heute leistungsfähig ist, kann morgen zu einem Engpass werden, wenn es keine Flexibilität besitzt. Das ERD sollte Wachstum ermöglichen, ohne eine vollständige Neuschreibung zu erfordern.
Überlegen Sie, Spalten hinzuzufügen, die in Zukunft wahrscheinlich für die Filterung verwendet werden. Obwohl dies die Zeilengröße leicht erhöht, spart dies die Kosten einer späteren Änderung der Tabellenstruktur, die bei großen Datensätzen eine teure Operation sein kann. Berücksichtigen Sie auch die Auswirkungen des Hinzufügens neuer Indizes. Jeder Index verbraucht Schreibressourcen. Gestalten Sie das Schema so, dass die Anzahl notwendiger Indizes minimiert wird.
Design-Checkliste für Leistungsfähigkeit
- Sind Primärschlüssel kurz und sequenziell?
- Sind Fremdschlüssel indiziert?
- Sind Datentypen der kleinstmögliche gültige Typ?
- Sind häufige Filter durch Indizes abgedeckt?
- Ist das Normalisierungslevel für die Arbeitslast angemessen?
- Haben Sie eine Partitionierung für große Tabellen in Betracht gezogen?
- Gibt es Spalten, die komplexes JSON oder Text speichern, das strukturiert werden könnte?
9. Die Rolle des Ausführungsplans 📋
Letztendlich entscheidet der Datenbank-Engine, wie eine Abfrage basierend auf dem Schema und den Statistiken ausgeführt wird. Das ERD beeinflusst die Statistiken, die die Engine sammelt. Zum Beispiel wird eine Spalte mit einer unterschiedlichen Werteverteilung anders behandelt als eine mit verzerrten Daten. Das Verständnis, wie der Ausführungsplan funktioniert, hilft Ihnen, zu verstehen, warum eine Abfrage langsam ist.
Wenn eine Abfrage eine vollständige Tabellen-Suche durchführt, deutet dies oft auf einen fehlenden Index oder eine Architektur hin, die keine effiziente Filterung unterstützt. Wenn viele verschachtelte Schleifen ausgeführt werden, deutet dies auf komplexe Joins hin, die vereinfacht werden könnten. Durch die Ausrichtung des ERD an den erwarteten Zugriffsmustern leiten Sie die Engine zu optimalen Ausführungsplänen.
10. Ausbalancieren von Integrität und Geschwindigkeit ⚖️
Es gibt kein perfektes Schema. Jede Gestaltungswahl beinhaltet einen Kompromiss. Das Ziel ist nicht, Leistungsprobleme zu eliminieren, sondern sie strategisch zu managen. In einigen Fällen ist es eine gültige Entscheidung, ein geringes Risiko von Dateninkonsistenzen (durch Anwendungslevel-Prüfungen statt Datenbankbeschränkungen) hinzunehmen, um eine extrem hohe Schreibdurchsatzleistung zu erreichen.
Überprüfen Sie regelmäßig Ihr ERD anhand der tatsächlichen Abfrageprotokolle. Identifizieren Sie die langsamsten Abfragen und verfolgen Sie sie zurück zum Schema. Diese Rückkopplungsschleife stellt sicher, dass Ihre Gestaltung im Einklang mit den Anforderungen Ihrer Anwendung entwickelt wird.
Zusammenfassung der Einflussbereiche 📝
| Gestaltungselement | Leistungsbeeinflussung | Empfehlung |
|---|---|---|
| Typ des Primärschlüssels | Hoch (Speicherplatz & Indizierung) | Verwenden Sie Integer oder UUIDs konsistent. |
| Fremdschlüssel | Mittel (Schreibaufwand) | Indizieren Sie FK-Spalten; entfernen Sie sie, wenn die Integrität an anderer Stelle behandelt wird. |
| Normalisierung | Hoch (Komplexität der Joins) | Denormalisieren Sie tabellen mit hohem Leseaufwand. |
| Datentypen | Mittel (Speicherverbrauch) | Verwenden Sie den spezifischsten verfügbaren Typ. |
| Kardinalität | Hoch (Join-Kosten) | Optimieren Sie Verbindungstabellen für N:M-Beziehungen. |
Indem Sie das Entitäts-Beziehungs-Diagramm als Leistungsartefakt behandeln, anstatt es nur als logische Karte zu sehen, können Sie Systeme erstellen, die robust, skalierbar und effizient sind. Die Entscheidungen, die Sie jetzt treffen, werden das Verhalten Ihrer Anwendung für Jahre bestimmen.