











Der Aufbau eines Systems, das Millionen von Nutzern bewältigen kann, erfordert mehr als nur leistungsstarke Hardware oder effizienten Code. Die Grundlage liegt in der Datenstruktur selbst. Ein Entity-Relationship-Diagramm (ERD) ist nicht bloß ein Dokumentationsprodukt; es ist der Bauplan für die Langzeitfähigkeit Ihrer Anwendung. Wenn Architekten für Wachstum gestalten, berücksichtigen sie die zukünftige Last, die Komplexität der Beziehungen und die Notwendigkeit von Datenintegrität. Ein gut konstruiertes Schema verhindert, dass technische Schulden anfallen, noch bevor der erste Commit erfolgt ist.
Diese Anleitung untersucht, wie man die Gestaltung von Entity-Relationship-Diagrammen speziell für skalierbare Umgebungen angeht. Wir behandeln die theoretischen Grundlagen, praktische Kompromisse und strukturelle Muster, die Hochdurchsatz-Systeme unterstützen, ohne die Konsistenz zu gefährden.
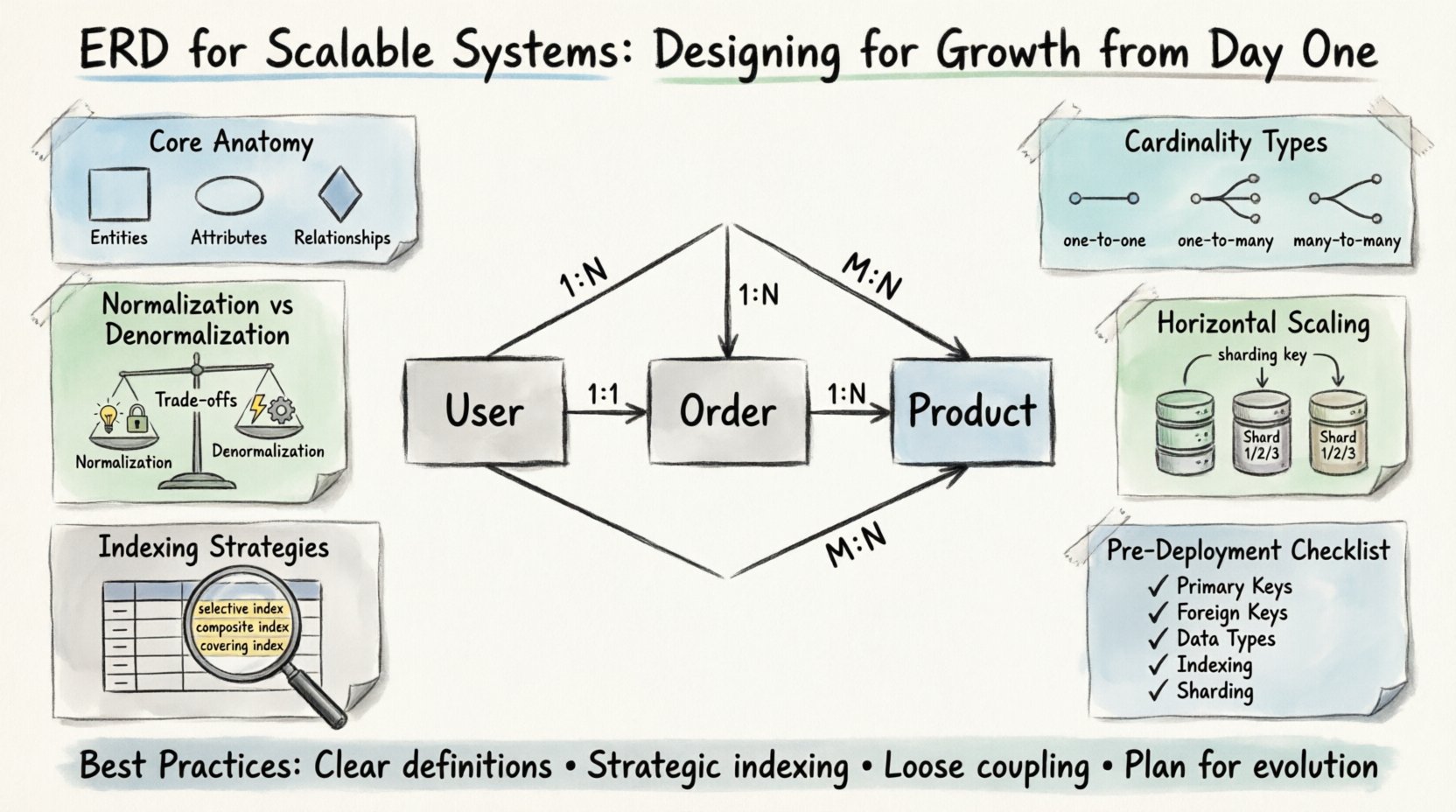
🧩 Die grundlegende Struktur eines skalierbaren ERD
Bevor man Skalierung berücksichtigt, muss man die grundlegenden Bausteine verstehen. Jedes Diagramm besteht aus Entitäten, Attributen und Beziehungen. In einem skalierbaren Kontext müssen diese Elemente präzise definiert werden, um spätere Engpässe zu vermeiden.
- Entitäten: Diese stellen die zentralen Objekte Ihres Geschäftsbereichs dar. Beispiele sind Benutzer, Bestellungen und Produkte. In Systemen mit hohem Wachstum sollten Entitäten so fein granuliert sein, dass sie unabhängig skaliert werden können, aber dennoch ausreichend kohärent, um logische Grenzen zu bewahren.
- Attribute: Diese sind die Eigenschaften, die die Entitäten beschreiben. Die Datentypen sind hier entscheidend. Die Wahl des richtigen Typs beeinflusst die Speichereffizienz und die Abfrageleistung. Beispielsweise ist die Verwendung eines speziellen Integer-Typs für IDs der Verwendung von Zeichenketten für Indexierungszwecke überlegen.
- Beziehungen: Diese definieren, wie Entitäten miteinander interagieren. Die Kardinalität ist der wichtigste Aspekt, der früh definiert werden muss. Eine falsche Interpretation einer ein-zu-viele-Beziehung als viele-zu-viele kann unnötige Joins und gravierende Leistungsverluste verursachen.
📐 Verständnis von Kardinalität und Einschränkungen
Die Kardinalität bestimmt die Anzahl der Instanzen einer Entität, die mit Instanzen einer anderen Entität in Beziehung stehen können oder müssen. In skalierbaren Systemen bestimmt die Wahl der Kardinalität oft, wie die Daten partitioniert werden.
- Ein-zu-eins (1:1): Selten zur Leistungsverbesserung eingesetzt. Deutet oft darauf hin, eine große Entität zu teilen, um die Blockierungsanzahl zu reduzieren. Nur verwenden, wenn die Datenzugriffsmuster strikt unterschiedlich sind.
- Ein-zu-viele (1:N): Die häufigste Beziehung. Ein Benutzer hat viele Bestellungen. Diese Struktur ermöglicht eine effiziente Indizierung auf der Fremdschlüsselseite und erlaubt eine schnelle Abrufung verwandter Datensätze.
- Viele-zu-viele (M:N): Erfordert eine Verbindungstabelle. Obwohl flexibel, können diese zu Leistungsengpässen werden, wenn die Datenmenge wächst. Berücksichtigen Sie bei hoher Lesehäufigkeit eine Denormalisierung oder materialisierte Ansichten.
Bei der Definition von Einschränkungen ist die Belastung der Durchsetzung zu berücksichtigen. In verteilten Systemen kann die strikte Durchsetzung von Fremdschlüsselbeschränkungen über Shard-Grenzen hinweg Latenz verursachen. In solchen Fällen kann eine Validierung auf Anwendungsebene notwendig sein, um die Systemdurchsatzleistung zu erhalten, während die Datenintegrität gewahrt bleibt.
⚖️ Normalisierung im Vergleich zu Leistungs-Kompromissen
Die Normalisierung reduziert Redundanz und verbessert die Datenintegrität. Allerdings erfordern Hochleistungssysteme oft eine Abweichung von strengen Normalisierungsregeln. Das Verständnis der Ebenen hilft bei fundierten Entscheidungen.
- Erste Normalform (1NF):Atomare Werte. Stellt sicher, dass jedes Feld nur einen einzigen Wert enthält. Dies ist für die relationale Integrität unverzichtbar.
- Zweite Normalform (2NF): Keine partiellen Abhängigkeiten. Alle Nicht-Schlüssel-Attribute müssen auf den gesamten Primärschlüssel abhängen. Nützlich zur Reduzierung von Aktualisierungsanomalien.
- Dritte Normalform (3NF): Keine transitive Abhängigkeit. Nicht-Schlüssel-Attribute dürfen nicht von anderen Nicht-Schlüssel-Attributen abhängen. Dies ist der Standardzielwert für die meisten transaktionalen Systeme.
Während 3NF ideal für Konsistenz ist, erfordert sie oft komplexe Joins. In lesedominanten Systemen kann das Verknüpfen mehrerer Tabellen die Datenbankengine belasten. Die Denormalisierung beinhaltet die Duplizierung von Daten, um die Notwendigkeit von Joins zu reduzieren. Dies erhöht die Schreibkomplexität, beschleunigt aber die Lesevorgänge erheblich.
📊 Vergleich zwischen Normalisierung und Denormalisierung
| Funktion | Normalisiert (3NF) | Dennormalisiert |
|---|---|---|
| Datenintegrität | Hoch (einziges Quellsystem) | Niedriger (erfordert Synchronisationslogik) |
| Schreibleistung | Schneller (weniger Daten geschrieben) | Langsamer (redundante Schreibvorgänge) |
| Lesegeschwindigkeit | Langsamer (erfordert Joins) | Schneller (direkter Zugriff) |
| Speicherplatznutzung | Effizient | Höher (Redundanz) |
| Anwendungsfall | Transaktionsbasierte Systeme (OLTP) | Berichterstattung & Analytik (OLAP) |
🚀 Gestaltung für horizontales Skalieren
Wenn das Datenvolumen wächst, wird ein einzelner Datenbankknoten zu einer Engstelle. Horizontales Skalieren beinhaltet das Hinzufügen weiterer Knoten zur Lastverteilung. Ihr ERD muss diese Architektur von Anfang an unterstützen.
- Sharding-Schlüssel:Identifizieren Sie eine Spalte, die es ermöglicht, die Daten gleichmäßig über die Shards zu verteilen. Diese Spalte sollte in jeder Abfrage enthalten sein, die auf die Daten zugreift. Wenn eine Abfrage alle Shards scannen muss, wird die Leistung leiden.
- Fremdschlüssel über Shards hinweg:Das Verknüpfen von Tabellen, die sich auf verschiedenen Shards befinden, ist rechnerisch kostspielig. Minimieren Sie Beziehungen über Shards hinweg bereits in der Entwurfsphase. Falls eine Beziehung notwendig ist, überlegen Sie, die Referenzdaten zu cachen.
- Globale IDs:Verwenden Sie eindeutige Bezeichner, die nicht auf automatisch erhöhte Zähler zurückgreifen, da diese zu Konkurrenz führen können. UUIDs oder verteilte ID-Generatoren werden bevorzugt.
Beim Modellieren für Sharding sollten Sie die Datenverteilung berücksichtigen. Hotspots entstehen, wenn ein Shard erheblich mehr Traffic erhält als andere. Analysieren Sie Zugriffsmuster, um sicherzustellen, dass der Sharding-Schlüssel mit den häufigsten Abfragefiltern übereinstimmt.
📑 Indexstrategien für große Datensätze
Indizes sind für die Abfrageleistung unverzichtbar, bringen aber auch Kosten mit sich. Jeder Index verbraucht Speicherplatz und verlangsamt Schreibvorgänge. Ein strategischer Ansatz beim Indexieren ist entscheidend.
- Selektive Indizes: Erstellen Sie Indizes für Spalten, die Daten erheblich filtern. Eine Spalte mit geringer Kardinalität (z. B. Geschlecht) ist oft ein schlechter Kandidat für einen Primärindex.
- Komposite Indizes: Kombinieren Sie mehrere Spalten in einer Reihenfolge, die Abfragemuster entspricht. Die Regel des linken Vorsatzes gilt, was bedeutet, dass die erste Spalte im Index mit der Abfrage übereinstimmen muss, damit der Index effektiv genutzt werden kann.
- Deckende Indizes: Fügen Sie alle Spalten, die von einer Abfrage benötigt werden, direkt in den Index ein. Dadurch kann die Datenbank die Abfrage erfüllen, ohne auf die Tabellendaten zuzugreifen, was als „deckende“ Operation bezeichnet wird.
- Teilindizes: Indizieren Sie nur eine Teilmenge der Tabellenzeilen. Dies ist nützlich für weiche Löschungen oder spezifische Statusflags und reduziert die Größe der Indexstruktur.
Überprüfen Sie Abfrageausführungspläne regelmäßig. Ein Index, der auf Papier gut aussieht, könnte vom Abfrageoptimierer ignoriert werden, wenn die Statistiken veraltet sind. Regelmäßige Wartung stellt sicher, dass die Datenbankengine optimale Entscheidungen trifft.
🔄 Evolution und Schema-Migrationen
Systeme sind nicht statisch. Die Anforderungen ändern sich, und das Datenmodell muss sich weiterentwickeln. Der Übergang von Version A zu Version B ohne Ausfallzeit ist eine entscheidende Fähigkeit.
- Additive Änderungen: Das Hinzufügen einer Spalte oder Tabelle ist im Allgemeinen sicher. Es bricht keine bestehenden Abfragen. Dies ist die bevorzugte Methode zur Einführung neuer Funktionen.
- Umbenennungsoperationen: Das Umbenennen einer Spalte ist riskant. Es erfordert die Aktualisierung des Anwendungscodes. Planen Sie einen Ablaufzeitraum, in dem sowohl der alte als auch der neue Name unterstützt werden.
- Hinzufügen von Einschränkungen: Das Hinzufügen einer Einschränkung (z. B. NOT NULL) zu bestehenden Daten kann fehlschlagen, wenn Daten vorhanden sind. Validieren Sie die Daten zuerst, und fügen Sie die Einschränkung in einem separaten Schritt hinzu.
- Rückwärtskompatibilität: Stellen Sie sicher, dass neue Schemaversionen bestehende Clients nicht brechen. Verwenden Sie Funktionsflags, um neue Logik nur dann zu aktivieren, wenn das Schema bereit ist.
🚫 Häufige Fallen, die vermieden werden sollten
Selbst erfahrene Designer stoßen auf Probleme. Die Erkennung dieser Muster frühzeitig kann erhebliche Ingenieurzeit sparen.
- Starke Kopplung: Erstellen von Beziehungen, die eine strenge Synchronisation zwischen unzusammenhängenden Entitäten erzwingen. Halten Sie Module lose gekoppelt, um eine unabhängige Bereitstellung zu ermöglichen.
- Überdimensionierung: Gestaltung für Szenarien, die niemals eintreten werden. Konzentrieren Sie sich auf die 80 % der Anwendungsfälle, die 90 % des Datenverkehrs verursachen. Einfachheit erleichtert die Wartbarkeit.
- Ignorieren von Weichlöschungen: Hartlöschungen entfernen Daten dauerhaft. Für Audits oder Wiederherstellungen verwenden Sie stattdessen eine Statusflag (z. B. is_deleted) anstelle der physischen Löschung.
- N+1-Abfrageprobleme: Das Fehlen einer Vorhersage darüber, wie Daten abgerufen werden. Planen Sie im Dateneingangsschicht eine vorzeitige Lade- oder Stapelabfrage, um zu viele Datenbankrundreisen zu vermeiden.
✅ Prüfliste für die Designphase vor der Bereitstellung
Bevor Sie das Schema endgültig festlegen, durchlaufen Sie diese Überprüfungsliste, um die Bereitschaft für Skalierung sicherzustellen.
- ☐ Primärschlüssel:Sind alle Tabellen mit einem eindeutigen, indizierten Primärschlüssel ausgestattet?
- ☐ Fremdschlüssel:Sind die Beziehungen korrekt definiert? Ist die Kardinalität korrekt?
- ☐ Daten-Typen:Werden numerische Typen für IDs und Beträge verwendet? Sind Datums-Typen standardisiert?
- ☐ Nullable-Werte:Sind erforderliche Felder als NOT NULL markiert?
- ☐ Indizierung:Sind Spalten, die häufig abgefragt werden, indiziert?
- ☐ Sharding:Gibt es einen geeigneten Sharding-Schlüssel, falls horizontales Skalieren erwartet wird?
- ☐ Beschränkungen:Sind Beschränkungen für die Geschäftslogik notwendig, oder können sie in der Anwendungsschicht behandelt werden?
- ☐ Dokumentation:Ist das ERD aktualisiert, um die endgültige Implementierung widerzuspiegeln?
🛡️ Datenintegrität in verteilten Umgebungen
In einer verteilten Umgebung ist es schwieriger, die ACID-Eigenschaften (Atomarität, Konsistenz, Isolation, Dauerhaftigkeit) über Knoten hinweg zu gewährleisten. Das Verständnis der Auswirkungen auf Ihr ERD ist entscheidend.
- Eventuelle Konsistenz:Akzeptieren Sie, dass die Daten zwischen Replikaten temporär inkonsistent sein können. Gestalten Sie Ihre Anwendung so, dass sie diesen Zustand reibungslos handhaben kann.
- Idempotenz:Stellen Sie sicher, dass Operationen ohne Nebenwirkungen wiederholt werden können. Dies ist entscheidend bei Netzwerkfehlern, bei denen ein Schreibvorgang erfolgreich sein könnte, aber die Bestätigung verloren geht.
- Konfliktlösung: Definieren Sie, wie gleichzeitige Aktualisierungen desselben Datensatzes behandelt werden sollen. Zeitstempel oder Vektorticks können helfen, die neueste Version zu bestimmen.
Durch die Einbeziehung dieser Überlegungen in Ihr Entity-Relationship-Diagramm schaffen Sie ein System, das nicht nur heute funktional ist, sondern auch robust genug für morgen. Die Kosten für die Änderung eines Schemas in der Produktion sind exponentiell höher als die richtige Gestaltung von Anfang an.
🔍 Zusammenfassung der Best Practices
Zusammenfassend basiert ein erfolgreicher Ausbau auf einer disziplinierten Herangehensweise an die Datenmodellierung. Konzentrieren Sie sich auf klare Definitionen, angemessene Normalisierung und strategisches Indexieren. Vermeiden Sie Abkürzungen, die die Datenintegrität gefährden. Überprüfen Sie Ihre Diagramme regelmäßig, während sich das System weiterentwickelt. Ein statisches ERD ist eine Belastung; ein lebendiges Modell ist ein Vermögen.
Investieren Sie die Zeit in die Entwurfsphase. Es wird sich in geringeren Wartungskosten und höherer Systemzuverlässigkeit auszahlen. Ihre Benutzer werden das Diagramm nie sehen, aber sie werden die Leistung des Systems spüren, das es unterstützt.