











Der Aufbau einer robusten Datenbank beginnt lange bevor die erste Tabelle erstellt wird. Es beginnt mit der Verständnis der geschäftlichen Probleme und der Übersetzung menschlicher Sprache in strukturierte Datenlogik. Diese Reise, bekannt alsDatenerfassung, schließt die Lücke zwischen dem, was Stakeholder benötigen, und der Art und Weise, wie das System sie speichert. Ein gut konstruiertes Entitäts-Beziehungs-Diagramm (ERD) dient als Bauplan für diese Infrastruktur. Ohne einen klaren Übersetzungsprozess laufen Projekte das Risiko von Datenredundanz, Integritätsproblemen und kostspieligen Umstrukturierungen später ein.
Diese Anleitung beschreibt die praktischen Schritte, um von rohen Anforderungen zu einem finalen ERD zu gelangen. Wir werden uns auf die Logik, die Beziehungen und das kritische Denken konzentrieren, das erforderlich ist, um sicherzustellen, dass Ihr Datenmodell der Zeit standhält.
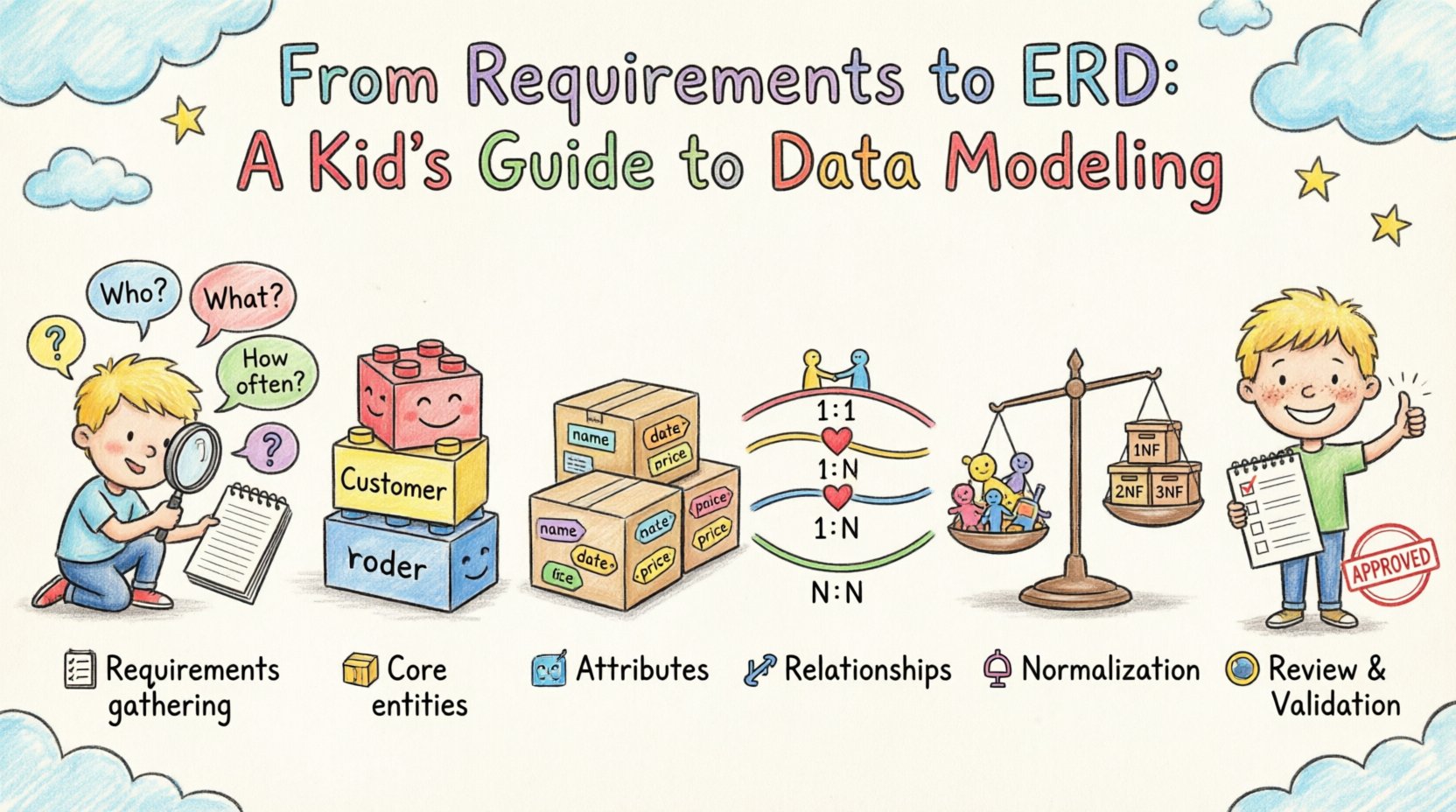
1. Verstehen der Eingabe: Sammeln und Analysieren der Anforderungen 📋
Die Grundlage jeder Datenbankgestaltung liegt in den Anforderungen. Diese sind oft vage, widersprüchlich oder unvollständig, wenn sie ursprünglich präsentiert werden. Das Ziel ist es, daswas und daswarum zuerst zu ermitteln, bevor man sich um daswie.
Identifizierung von Geschäftsprozessen
Beginnen Sie damit, die Arbeitsabläufe zu kartieren. Fordern Sie die Stakeholder auf, ihre täglichen Abläufe zu beschreiben. Hören Sie auf Aktionen, die die Speicherung von Informationen beinhalten. Zum Beispiel könnte ein Logistikmanager sagen:„Wir müssen verfolgen können, wo sich jeder Paket zu jedem beliebigen Zeitpunkt befindet.“ Dieser Satz enthält mehrere Datenpunkte: das Paket, dessen Standort und das Zeitfenster.
- Interviews mit Stakeholdern: Planen Sie Sitzungen mit Endbenutzern, nicht nur mit Managern. Sie offenbaren oft Sonderfälle, die hochrangige Zusammenfassungen übersehen.
- Regeln dokumentieren: Dokumentieren Sie geschäftliche Regeln explizit. „Ein Kunde kann nicht mehr als eine aktive Abonnement haben.“ Dies ist eine Einschränkung, keine einfache Funktion. Dokumentieren Sie geschäftliche Regeln explizit. „Ein Kunde kann nicht mehr als eine aktive Abonnement haben.“ Dies ist eine Einschränkung, keine einfache Funktion. Dokumentieren Sie geschäftliche Regeln explizit. „Ein Kunde kann nicht mehr als eine aktive Abonnement haben.“ Dies ist eine Einschränkung, keine einfache Funktion.
- Bestehende Systeme überprüfen: Wenn von einem alten System migriert wird, analysieren Sie die veralteten Daten. Welche Felder werden tatsächlich genutzt? Welche sind veraltet?
Qualitative vs. quantitative Anforderungen
Nicht alle Anforderungen sind gleich. Sie müssen zwischen Art der Daten und Menge der Daten unterscheiden.
- Qualitativ: Definiert die Bedeutung und Art. Ist ein Datum ein Geburtsdatum oder ein Transaktionsdatum? Ist ein Name ein einzelner String oder in Vor- und Nachnamen aufgeteilt?
- Quantitativ: Definiert Grenzen. Wie viele Datensätze pro Tag? Was ist die Aufbewahrungsfrist?
Verwirrung hier führt zu einer schlechten Schema-Design. Zum Beispiel ermöglicht die Behandlung einer Telefonnummer als Zeichenkette das Einbeziehen von Formatierungszeichen, aber die Behandlung als Ganzzahl könnte notwendige Präfixe entfernen. Entscheidungen müssen früh dokumentiert werden.
2. Identifizierung der zentralen Entitäten 🏗️
Sobald die Anforderungen klar sind, ist der nächste Schritt, die Entitäten. Eine Entität stellt ein Gegenstand oder Konzept der realen Welt dar, über das Daten gespeichert werden müssen. In einem ERD werden diese typischerweise als Rechtecke dargestellt.
Techniken zur Entdeckung
Um Entitäten zu finden, durchsuchen Sie die Anforderungen nach Substantiven. Jedoch ist nicht jedes Substantiv eine Entität. Sie müssen Substantive filtern, die Speicherung erfordern und eine eindeutige Identität besitzen.
- Direkte Substantive: Kunde, Produkt, Rechnung. Dies sind offensichtliche Kandidaten.
- Implizite Substantive: Manchmal sind Entitäten in Verben versteckt.„Weisen Sie ein Projekt einem Team zu.“ Hier sind Projekt und Team Entitäten. Zuweisung könnte eine Beziehung oder eine separate Entität sein, wenn sie über eigene Attribute verfügt (wie ein Zuweisungsdatum).
- Ausgeschlossene Substantive: Wörter wie System, Benutzer (im allgemeinen Sinne), oder Daten sind oft zu abstrakt. Seien Sie spezifisch. Ist es ein Registrierter Benutzer oder ein Gast?
Definieren der Entitätsidentität
Jede Entität muss eine Möglichkeit haben, eine Instanz von einer anderen zu unterscheiden. Dies ist die Primärschlüssel. In der konzeptuellen Phase müssen Sie nicht entscheiden, ob dieser Schlüssel eine automatisch erhöhende Nummer oder eine UUID ist, aber Sie müssen anerkennen, dass eine Identität erforderlich ist.
- Natürliche Schlüssel: Liefern die realweltbezogenen Attribute eine eindeutige Identifikation? (z. B. eine Sozialversicherungsnummer oder eine Fahrzeugidentifikationsnummer).
- Ersatzschlüssel: Wenn kein natürlicher Schlüssel existiert oder wenn der Schlüssel häufig wechselt, ist eine systemgenerierte eindeutige ID erforderlich.
Betrachten Sie die Entität Mitarbeiter. Ist die Mitarbeiter-ID der Schlüssel, oder ist die Kombination aus Name und Abteilung eindeutig? Normalerweise ist eine eindeutige ID sicherer, um Probleme bei Namensänderungen oder doppelten Namen zu vermeiden.
3. Definieren von Attributen und Datentypen 🏷️
Attribute sind die Eigenschaften, die eine Entität beschreiben. Sie füllen die Details aus. Wenn eine Entität eine Kiste ist, sind Attribute die Etiketten auf der Kiste.
Kategorisieren von Attributen
Attribute sollten logisch gruppiert werden. Einige sind erforderlich, einige optional und einige abgeleitet.
- Erforderliche Attribute:Daten, die für die Gültigkeit der Entität existieren müssen. (z. B. Bestelldatum für eine Bestellung).
- Optionale Attribute:Daten, die vorhanden sein können oder nicht. (z. B. Zweite E-Mail-Adresse für einen Benutzer).
- Abgeleitete Attribute: Daten, die aus anderen Attributen berechnet werden. (z. B. Alter abgeleitet aus Geburtsdatum). Normalerweise werden diese nicht physisch gespeichert, um Aktualisierungsanomalien zu vermeiden, sind aber für das Modell wichtig.
Auswahl von Datentypen
Während das ERD konzeptionell ist, hilft die Überlegung über Speichertypen, zukünftige Fehler zu vermeiden. Falsche Typen verursachen Leistungsprobleme und Datenverlust.
| Attributbegriff | Empfohlener Typ | Begründung |
|---|---|---|
| Namens- und Adressangaben | VARCHAR / Text | Variabel lange Zeichenfolgen, keine numerischen Zeichen. |
| Zählungen, Preise | Ganzzahl / Dezimal | Mathematische Operationen, Genauigkeitsanforderungen. |
| Datums- und Zeitangaben | Datum / DateTime | Ermöglicht Sortierung, Filterung und Dauerberechnungen. |
| Ja/Nein-Flags | Boolesch | Klare Logik für Wahr/Falsch-Zustände. |
| Große Dokumente | BLOB / Dateiverweis | Speichert binäre Daten oder Verweise auf externe Speicher. |
Normalisierung von Attributen
Bevor Sie Linien zwischen Entitäten ziehen, stellen Sie sicher, dass Attribute atomar sind. Ein Attribut sollte nur einen Wert enthalten. Vermeiden Sie es, mehrere Telefonnummern in einem Feld wie Telefon_1, Telefon_2, Telefon_3. Stattdessen erstellen Sie eine separate Entität für Kontaktinformationen verbunden mit dem Kunde.
- Warum atomar? Es vereinfacht Abfragen. Die Suche nach einer bestimmten Telefonnummer ist unmöglich, wenn sie verkettet sind.
- Flexibilität: Wenn ein Kunde eine zweite Telefonnummer erhält, ermöglicht eine separate Entität eine unbegrenzte Erweiterung ohne Änderung des Schemas.
4. Abbildung von Beziehungen und Kardinalität 🔗
Entitäten existieren selten isoliert. Sie interagieren. Die Linien, die Entitäten in einem ERD verbinden, stellenBeziehungen. Die korrekte Definition dieser ist der wichtigste Teil des Modellierungsprozesses.
Arten von Beziehungen
Beziehungen beschreiben, wie Instanzen einer Entität zu Instanzen einer anderen Entität stehen.
- Ein-zu-eins (1:1): Eine Instanz der Entität A ist genau einer Instanz der Entität B zugeordnet. Beispiel: Mitarbeiter zu Mitarbeiterausweis.
- Ein-zu-viele (1:N): Eine Instanz der Entität A steht in Beziehung zu vielen Instanzen der Entität B, aber die B steht nur zu einer A in Beziehung. Beispiel: Autor zu Buch.
- Viele-zu-viele (M:N): Viele Instanzen von A stehen in Beziehung zu vielen Instanzen von B. Beispiel: Student zu Klasse. Hinweis: Bei der physischen Implementierung erfordert dies oft eine Zwischeneinheit (Verknüpfungstabelle).
Kardinalität und Modalität
Die Kardinalität definiert die Anzahl (Eins, Mehr). Die Modalität definiert die Anforderung (Muss, Optional). Die Visualisierung dieser Aspekte ist für die Datenintegrität essenziell.
- Null oder Eins: Die Beziehung ist optional, und nur eine ist zulässig.
- Genau eine: Die Beziehung ist obligatorisch, und nur eine ist zulässig.
- Null oder Mehr: Die Beziehung ist optional, und mehrere sind zulässig.
- Eine oder mehrere: Die Beziehung ist obligatorisch, und mehrere sind zulässig.
Berücksichtigen Sie die Bestellung und Kunde Beziehung. Ein Kunde muss mindestens eine Bestellung aufgeben (Pflicht). Eine Bestellung muss genau einem Kunden gehören (Pflicht). Dies definiert die Fremdschlüsselbeschränkungen in der Datenbank.
5. Sicherstellen der Datenintegrität und Normalisierung ⚖️
Sobald das Diagramm gezeichnet ist, muss es auf logische Konsistenz überprüft werden. In dieser Phase werden Normalisierungsregeln angewendet, um Redundanz zu beseitigen und Stabilität zu gewährleisten.
Erste Normalform (1NF)
Stellen Sie sicher, dass jede Spalte atomare Werte enthält und keine sich wiederholenden Gruppen vorhanden sind. Jede Zeile muss eindeutig sein.
- Überprüfen: Gibt es Listen in Zellen? Gibt es für ein einzelnes Feld mehrere Werte?
- Beheben: Teilen Sie Listen in separate Zeilen oder separate Tabellen auf.
Zweite Normalform (2NF)
Stellen Sie sicher, dass alle Attribute vollständig vom Primärschlüssel abhängen. Wenn Sie einen zusammengesetzten Schlüssel haben, sollte kein Attribut nur von einem Teil dieses Schlüssels abhängen.
- Beispiel: In einer Tabelle, die Studenten-ID, Kurs-ID, und Studentenname, die Studentenname hängt nur von der Studenten-ID, nicht von der Kombination. Verschiebe Studentenname in eine Student Tabelle.
Dritte Normalform (3NF)
Stellen Sie sicher, dass keine transitiven Abhängigkeiten bestehen. Nicht-Schlüsselattribute sollten nicht von anderen Nicht-Schlüsselattributen abhängen.
- Beispiel: Wenn Stadt hängt ab von Postleitzahl, und Postleitzahl befindet sich in der Kunde Tabelle, sollten Sie Postleitzahl und Stadt in eine Ort Tabelle. Dies verhindert, dass Aktualisierungen von Stadtnamen in Tausenden von Kundendaten unkonsequent werden.
6. Überprüfung und Validierung 🧐
Das Modell ist nicht abgeschlossen, bis es anhand der ursprünglichen Anforderungen validiert wurde. Dies ist ein Sinnfestigkeitscheck, um sicherzustellen, dass nichts übersehen oder falsch interpretiert wurde.
Durchlauf-Szenarien
Durchlaufen Sie spezifische Anwendungsfälle, um zu prüfen, ob das Modell sie unterstützt. Stellen Sie Fragen wie:
- „Können wir eine Bestellung ohne Kunden erstellen?“ Wenn das Modell dies zulässt, die Geschäftsregeln es jedoch verbieten, ist die Beziehungskardinalität falsch.
- „Können wir ein Produkt löschen, das derzeit in einer Bestellung enthalten ist?“ Wenn die Antwort nein lautet, benötigen Sie Referenzintegritätsbeschränkungen (kaskadierende Löschungen).
- „Was passiert, wenn ein Kunde seinen Namen ändert?“ Wenn der Name auch in der Bestellungstabelle gespeichert ist, besteht ein Risiko für Dateninkonsistenzen. Er sollte nur in der Kundentabelle gespeichert werden.
Zustimmung der Stakeholder
Stellen Sie das ERD den Geschäftsanwendern vor. Sie mögen die technischen Begriffe nicht verstehen, aber sie verstehen die Logik. Fragen Sie sie, ob die Entitäten und Beziehungen ihrem mentalen Geschäftsmodell entsprechen.
- Visuelle Bestätigung:Verwenden Sie das Diagramm, um ihnen zu zeigen, wo ihre Daten gespeichert sind.
- Lückenanalyse:Fragen Sie, ob kritische Datenpunkte in der Attributliste fehlen.
- Zukunftssicherung:Besprechen Sie mögliche Änderungen. Unterstützt das Modell die Erweiterung in eine neue Region, falls der Geschäftsbetrieb dies plant?
Häufige Herausforderungen bei der Übersetzung 🛑
Selbst erfahrene Modelleure stoßen bei der Übersetzung von Anforderungen auf Hindernisse. Die Kenntnis dieser Fallen hilft, sie zu vermeiden.
- Übermodellierung: Versuchen, jedes mögliche zukünftige Bedürfnis vorherzusehen, führt zu einem komplexen, starren Schema. Gestalten Sie für die aktuellen Anforderungen, lassen Sie aber Raum für Erweiterungen (z. B. Verwendung einer JSON-Spalte für flexible Metadaten, falls angemessen).
- Untermodellierung:Das Ignorieren von Beschränkungen führt zu unübersichtlichen Daten. Wenn ein Feld erforderlich ist, machen Sie es im Modell nicht optional.
- Verwechseln von Entitäten mit Beziehungen: Manchmal hat eine Beziehung so viele Attribute, dass sie selbst zu einer Entität wird. (z. B. Einschreibung zwischen Student und Kurs könnte ein Note und Datum). Behandle es als Entität, wenn es eine eigene Historie oder Attribute benötigt.
- Berücksichtigung der Groß-/Kleinschreibung ignorieren: In einigen Systemen, „New York“ und „new york“ sind unterschiedlich. Entscheide frühzeitig über Standardisierungsregeln.
- Annahme der Hardware-Leistung: Optimiere nicht auf Kosten der Integrität für Geschwindigkeit. Eine langsame Abfrage ist besser als falsche Daten.
Best Practices für nachhaltige Modelle ✅
Um eine gesunde Datenbank über Jahre hinweg zu erhalten, folge diesen Richtlinien während der Entwurfsphase.
- Konsistente Namenskonventionen: Verwende Singular-Nomen für Entitäten (z. B. Kunde nicht Kunden). Verwende Kleinbuchstaben mit Unterstrichen für Spalten (z. B. kunden_id). Dadurch wird Mehrdeutigkeit reduziert.
- Dokumentation: Kommentiere dein Diagramm. Erkläre, warum eine Beziehung besteht, nicht nur, dassdass Es existiert. Dies hilft zukünftigen Entwicklern, die Geschäftslogik zu verstehen.
- Versionskontrolle: Behandle dein ERD wie Code. Speichere Versionen, wenn sich die Anforderungen ändern. Dadurch kannst du rückgängig machen, falls sich eine Entwurfsentscheidung als unbrauchbar erweist.
- Standardisierung: Verwende bei Gelegenheit standardmäßige Datentypen. Vermeide benutzerdefinierte Typen, es sei denn, sie sind unbedingt notwendig.
- Sicherheitsaspekte: Identifiziere vertrauliche Daten (PII, Finanzinformationen) früh. Stelle sicher, dass das Modell die Verschlüsselung oder Maskierung auf Spaltenebene erlaubt.
Abschließende Gedanken zum Übersetzungsprozess 🎯
Der Übergang von Anforderungen zu einem ERD ist kein linearer Weg. Es ist ein iterativer Prozess. Du wirst neue Entitäten erkennen, während du Beziehungen definierst. Du wirst Attribute verfeinern, während du normalisierst. Das Ziel ist nicht Perfektion im ersten Entwurf, sondern eine solide Grundlage, die weiter verbessert werden kann.
Ein starkes Datenmodell reduziert technische Schulden. Es verhindert die Notwendigkeit, Systeme neu zu bauen, weil die Datenstruktur neue Funktionen nicht unterstützen konnte. Indem du dich auf die Logik des Geschäfts konzentrierst und strenge Übersetzungsverfahren anwendest, schaffst du ein System, das zuverlässig, skalierbar und wartbar ist.
Gib dir Zeit bei der Analyse. Die Stunden, die du in die Verfeinerung des Diagramms investierst, sparen Wochen an Debugging und Refactoring während der Entwicklung. Behandle das ERD als Vertrag zwischen dem Geschäft und der Technologie.