











Bei der Backend-Entwicklung fühlt es sich oft an, als würde man ein Haus ohne Bauplan bauen. Man beginnt, Ziegel zu legen, Fenster hinzuzufügen und Wände zu errichten, basierend auf Intuition. Manchmal funktioniert es. Oft jedoch nicht. Wochen später steht man vor der Situation, Wände abzureißen, um eine Tür zu integrieren, die man vergessen hat zu planen. Das ist die Realität des Programmierens ohne eine solideEntitäts-Beziehungs-Diagramm (ERD). Das ERD ist der stille Architekt Ihrer Dateninfrastruktur, der hinter den Kulissen wirkt, um kostspielige strukturelle Fehler zu verhindern. Wenn Sie Zeit darauf verwenden, Ihr Datenmodell zu entwerfen, bevor Sie eine einzige Codezeile schreiben, gewinnen Sie Klarheit, reduzieren technischen Schulden und vereinfachen die Zusammenarbeit zwischen Teams.
Diese Anleitung untersucht die greifbaren Auswirkungen von ERDs auf Backend-Workflows. Wir werden die Mechanik der Datenmodellierung, die versteckten Kosten des Weglassens der Planung und die strategischen Vorteile eines gut dokumentierten Schemas analysieren. Durch das Verständnis dieser Prinzipien können Sie von reaktiver Programmierung zu proaktiver Architektur wechseln.
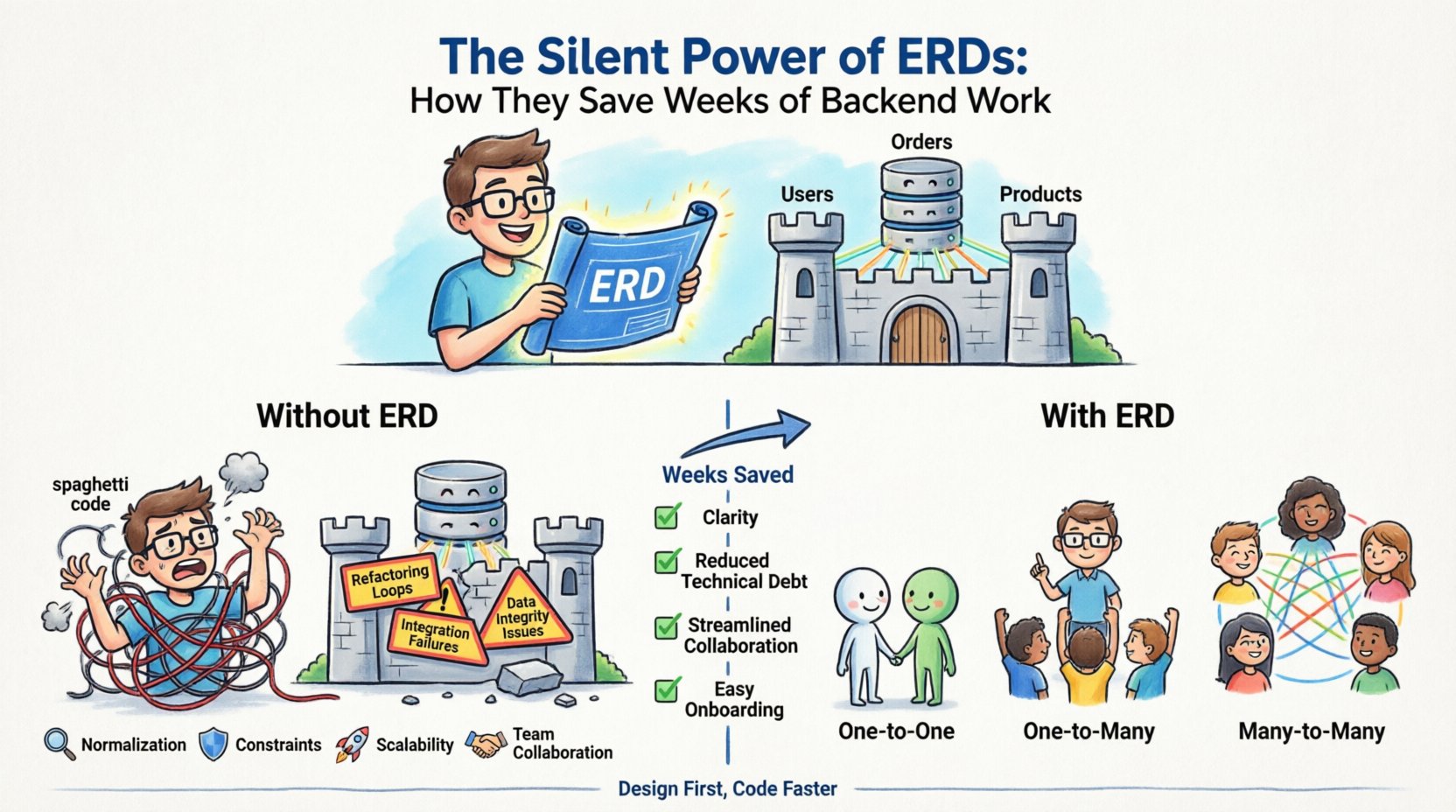
Was ist eigentlich ein ERD? 📐
Ein Entitäts-Beziehungs-Diagramm ist eine visuelle Darstellung der logischen Struktur einer Datenbank. Es zeigt auf, wie verschiedene Datenbestandteile miteinander verbunden sind. Stellen Sie sich das als Karte für das Gedächtnis Ihrer Anwendung vor. Ohne diese Karte navigieren Entwickler blind und riskieren Kollisionen zwischen Datenpunkten, die getrennt bleiben sollten.
Im Kern besteht ein ERD aus drei Hauptkomponenten:
- Entitäten: Diese stellen die Objekte oder Konzepte dar, die Sie verfolgen. In einer Datenbank entsprechen sie Tabellen. Beispiele sindBenutzer, Bestellungen, oderProdukte.
- Attribute: Diese sind die spezifischen Eigenschaften einer Entität. Sie werden zu Spalten in Ihren Tabellen. Für eineBenutzerEntität könnten Attribute wieE-Mail, Passwort-Hash, understellt_am.
- Beziehungen: Diese definieren, wie Entitäten miteinander interagieren. Sie bestimmen die Kardinalität und Verbindung zwischen Tabellen, wie zum Beispiel eineBenutzerdie vieleBestellungen.
Während das Konzept einfach erscheint, entsteht die Komplexität bei der Verwaltung von Skalierung. Ein einfacher Blog benötigt möglicherweise nur wenige Tabellen. Ein Unternehmenssystem erfordert Dutzende, wenn nicht Hunderte, miteinander verbundener Entitäten. Das ERD fungiert als einziges Quellensystem für all diese Interaktionen.
Die versteckten Kosten des Weglassens der Planung 💸
Viele Entwicklerteams eilen zum Coden, um Deadlines einzuhalten. Sie gehen davon aus, dass sie die Datenbank später refaktorisieren können. Dies ist eine gefährliche Annahme. Die Änderung eines Datenbankschemas ist erheblich teurer als die Änderung von Anwendungslogik. Sobald Daten geschrieben wurden, erfordert die Änderung der Struktur Migrationsskripte, mögliche Ausfallzeiten und sorgfältige Behandlung bestehender Datensätze.
Berücksichtigen Sie die folgenden Szenarien, in denen das Fehlen eines ERDs zu Reibung führt:
- Refactoring-Schleifen: Sie bauen eine Funktion, erkennen, dass die Datenstruktur diese nicht unterstützt, und müssen die Abfragen neu schreiben. Dieser Zyklus wiederholt sich und verbraucht Wochen des Sprint-Zeitraums.
- Integrationsfehler: Wenn Frontend- und Backend-Teams ohne gemeinsame Schema-Definition arbeiten, brechen APIs oft ab. Das Backend sendet eine Struktur; das Frontend erwartet eine andere.
- Integritätsprobleme bei Daten: Ohne definierte Einschränkungen gelangen ungültige Daten in das System. Sie enden damit, verwaiste Datensätze aufzuräumen oder inkonsistente Zustände manuell zu beheben.
- Verzögerungen bei der Einarbeitung: Neue Entwickler kämpfen damit, das System zu verstehen. Sie verbringen Tage damit, Code zu lesen, anstatt Funktionen zu entwickeln, weil der Datenfluss nicht dokumentiert ist.
Bis Sie das Problem bemerken, hat sich die Kosten bereits vervielfacht. Die „Lösung“ erfordert nun nicht nur Codeänderungen, sondern auch Datenmigration, Tests und Überprüfung der Bereitstellung.
Beziehungen wie ein Profi abbilden 🔗
Das Verständnis, wie Daten miteinander verbunden sind, ist das Herzstück der ERD-Planung. Beziehungen bestimmen, wie Abfragen formuliert werden und wie die Leistung optimiert wird. Es gibt drei Hauptarten von Beziehungen, die Sie klar definieren müssen.
Die folgende Tabelle zeigt die Unterschiede zwischen diesen Beziehungstypen:
| Beziehungstyp | Definition | Beispiel-Szenario | Implementierungshinweis |
|---|---|---|---|
| Ein-zu-Eins (1:1) | Ein einzelner Datensatz in Tabelle A steht genau mit einem Datensatz in Tabelle B in Beziehung. | Ein Benutzerprofil, das mit einer Benutzereinstellungstabelle verknüpft ist. | Oft wird dies durch Platzieren des Primärschlüssels von B in A realisiert. |
| Ein-zu-Viele (1:N) | Ein einzelner Datensatz in Tabelle A steht mit mehreren Datensätzen in Tabelle B in Beziehung. | Eine Kategorie, die mehrere Produkte enthält. | Standardmäßige Platzierung des Fremdschlüssels in der Tabelle der „vielen“ Seite. |
| Viele-zu-Viele (M:N) | Mehrere Datensätze in Tabelle A beziehen sich auf mehrere Datensätze in Tabelle B. | Studenten, die in mehreren Kursen eingeschrieben sind. | Erfordert eine Verbindungstabelle, um die Verbindung aufzulösen. |
Das Ignorieren dieser Unterschiede führt zu ineffizienten Abfragen. Beispielsweise verstößt das Speichern einer Liste von Produkt-IDs in einer einzigen Spalte für eine Kategorie gegen die Normalisierungsprinzipien. Es zwingt Sie dazu, Zeichenketten zu parsen, anstatt Joins zu verwenden, was die Leistung verlangsamt, je größer die Daten werden.
Normalisierung: Daten sauber halten 🧹
Die Normalisierung ist der Prozess der Datenorganisation zur Reduzierung von Redundanz und Verbesserung der Integrität. Obwohl moderne Systeme manchmal von der strengen Normalisierung abweichen, um die Leistung zu verbessern, bleibt das Verständnis der Prinzipien unverzichtbar.
Die gängigen Formen der Normalisierung umfassen:
- Erste Normalform (1NF): Stellt Atomarität sicher. Jede Spalte enthält nur einen Wert. Keine Listen oder Arrays in einer einzelnen Zelle.
- Zweite Normalform (2NF): Baut auf 1NF auf. Erfordert, dass alle nicht-schlüsselbasierten Attribute vollständig vom Primärschlüssel abhängen. Keine partiellen Abhängigkeiten.
- Dritte Normalform (3NF): Baut auf 2NF auf. Erfordert, dass nicht-schlüsselbasierte Attribute sich nur auf den Primärschlüssel beziehen, nicht auf andere nicht-schlüsselbasierte Attribute.
Warum ist das wichtig? Betrachten Sie eine BestellungTabelle. Wenn Sie die Kundennamein jeder Bestellzeile speichern, entsteht Redundanz. Wenn sich der Kunde seinen Namen ändert, müssen Sie Tausende von Zeilen aktualisieren. Wenn Sie eine übersehen, wird Ihre Datenintegrität beeinträchtigt. Indem Sie den Kundennamein eine KundenTabelle verschieben und über die ID verknüpfen, stellen Sie sicher, dass es eine einzige Quelle der Wahrheit gibt.
Allerdings ist die Normalisierung keine Allheilmittel. Übermäßige Normalisierung kann zu komplexen Joins führen, die die Leistung beeinträchtigen. Das Ziel ist Ausgewogenheit. Sie müssen die Abwägungen zwischen Speichereffizienz und Abfragegeschwindigkeit verstehen.
Häufige Fehler bei der Schema-Design 🚧
Selbst erfahrene Entwickler begehen Fehler beim Entwurf von ERDs. Die Erkennung dieser häufigen Fallen kann Ihnen später erhebliche Kopfschmerzen ersparen.
- Zirkuläre Abhängigkeiten: Entität A benötigt Entität B, und Entität B benötigt Entität A. Dies führt zu einer Blockade bei der Initialisierung und macht das Schreiben von Migrations-Skripten schwierig.
- Fehlende Einschränkungen:Das Auslassen der Definition von Fremdschlüsseln, eindeutigen Einschränkungen oder Prüfbedingungen ermöglicht es ungültigen Daten, durch die Lücken zu schlüpfen. Die Datenbank sollte Regeln durchsetzen, nicht der Anwendungscode.
- Hartkodierte Werte:Die Speicherung von Statuscodes wie „active“ oder „inactive“ als Ganzzahlen ohne eine Abfrage-Tabelle macht das System anfällig. Wenn Sie „suspended“ hinzufügen müssen, müssen Sie die Logik überall ändern.
- Ignorieren von Weichen Löschungen:Das permanente Löschen von Daten entfernt die Historie. Die Gestaltung für weiche Löschungen (Markieren eines Datensatzes als gelöscht anstatt ihn zu entfernen) bewahrt Audit-Protokolle.
- Überdimensionierung:Die Gestaltung für einen Anwendungsfall, der noch nicht existiert. Bauen Sie für die aktuellen Anforderungen, aber stellen Sie sicher, dass das Schema flexibel genug ist, um angemessenes Wachstum zu bewältigen.
Jeder dieser Fallstricke fügt der Codebasis zusätzliche Komplexität hinzu. Ein ERD hilft Ihnen, diese Probleme zu visualisieren, bevor sie in der Produktion verankert sind.
Von der Darstellung zur Umsetzung 🚀
Sobald der ERD finalisiert ist, ist der nächste Schritt die Übersetzung in Code. Dieser Prozess, der oft als Schema-Migration bezeichnet wird, erfordert Disziplin.
Befolgen Sie diese Schritte, um einen reibungslosen Übergang zu gewährleisten:
- Versionskontrolle:Behandeln Sie Ihr Datenbankschema wie Anwendungscode. Jede Änderung sollte eine Migrationsdatei sein, die in Ihrem Repository gespeichert wird.
- Abwärtskompatibilität: Wenn Sie eine Spalte hinzufügen, machen Sie sie zunächst nullable. Füllen Sie die vorhandenen Daten auf, und setzen Sie die Einschränkung in einer nachfolgenden Migration durch. Dadurch wird Ausfallzeit vermieden.
- Testen von Migrationen: Führen Sie Migrations-Skripte in einer Staging-Umgebung aus, die der Produktion entspricht. Überprüfen Sie auf Leistungsverschlechterungen.
- Rückgängigmachungspläne: Stellen Sie immer eine Möglichkeit bereit, eine Migration rückgängig zu machen, falls sie fehlschlägt. Datenverlust ist inakzeptabel.
Automatisierungstools können bei der Generierung von SQL aus ERDs unterstützen, aber eine manuelle Überprüfung ist entscheidend. Automatisierte Generatoren überspringen oft Nuancen der Geschäftslogik, die ein menschlicher Architekt erkennen würde.
Zusammenarbeit und Kommunikation 🤝
Ein ERD ist nicht nur für Datenbankadministratoren gedacht. Er dient als Kommunikationswerkzeug für das gesamte Team. Produktmanager, Frontend-Entwickler und QA-Engineer profitieren alle von einem Verständnis der Datenstruktur.
Wenn Stakeholder den ERD überprüfen, können sie potenzielle Probleme frühzeitig erkennen:
- Möglichkeit der Funktionalität: Kann die Datenbank die angeforderte Funktion unterstützen? Wenn nicht, welche Änderungen sind erforderlich?
- Leistungsanforderungen: Erlaubt das Design eine effiziente Abfrage im großen Maßstab?
- Sicherheitsanforderungen: Sind sensible Felder identifiziert und geschützt? Ist Zugriffssteuerung auf Datenebene möglich?
Dieses gemeinsame Verständnis verringert die Spannungen während der Sprintplanung. Anstatt zu raten, wie die Daten fließen, diskutiert das Team darauf basierend auf einem visuellen Modell. Streitigkeiten werden anhand des Diagramms, nicht nach Meinung, gelöst.
Skalierbarkeitsüberlegungen 📈
Je größer Ihre Anwendung wird, desto mehr muss sich auch Ihr Datenmodell weiterentwickeln. Ein ERD hilft Ihnen, diese Veränderungen vorherzusehen. Er ermöglicht es Ihnen, visuell darzustellen, wie das Hinzufügen einer neuen Entität bestehende Beziehungen beeinflusst.
Wichtige Skalierbarkeitsfaktoren, die bei der Gestaltung berücksichtigt werden müssen:
- Indizierungsstrategie:Identifizieren Sie, welche Spalten häufig abgefragt werden. Planen Sie Indizes für diese Felder, um die Abrufgeschwindigkeit zu erhöhen.
- Partitionierung:Wird eine bestimmte Tabelle zu groß? Planen Sie gegebenenfalls eine horizontale Partitionierung.
- Lesen/Schreiben-Trennung:Unterstützt das Design separate Lese- und Schreib-Replicas? Stellen Sie sicher, dass Fremdschlüssel die Replikation nicht komplizieren.
- Caching-Ebenen:Wie interagiert das Datenmodell mit Cache-Systemen? Unveränderliche Daten sind einfacher zu cachen als häufig veränderte Daten.
Die frühzeitige Berücksichtigung der Skalierung verhindert später die Notwendigkeit einer vollständigen Neuschreibung. Es ist einfacher, eine neue Tabelle hinzuzufügen, als Daten von einem Server auf einen anderen zu verschieben.
Abschließende Gedanken zur Datenarchitektur 🧠
Die Anstrengung, die bei der Erstellung eines detaillierten ERDs investiert wird, zahlt sich während des gesamten Projektlebenszyklus aus. Es verwandelt die Datenmodellierung von einer reaktiven Aufgabe in ein strategisches Gut. Durch die Visualisierung von Beziehungen, die Durchsetzung von Einschränkungen und die Planung des Wachstums bauen Sie Systeme auf, die robust und wartbar sind.
Behandeln Sie die Datenbank nicht als nachträgliche Überlegung. Sie ist die Grundlage Ihrer Anwendung. Investieren Sie in die Entwurfsphase, und Sie werden langfristig Wochen an Backend-Arbeit sparen. Die stille Stärke des ERDs liegt in seiner Fähigkeit, Probleme zu verhindern, bevor sie überhaupt auftreten.
Beginnen Sie heute mit der Kartierung Ihrer Daten. Die Klarheit, die Sie dadurch gewinnen, macht den Unterschied zwischen einem chaotischen Codebase und einem strukturierten System aus.