









Concevoir un schéma de base de données robuste est l’une des tâches les plus importantes dans le développement logiciel. Un diagramme d’entité-relation (ERD) sert de plan directeur pour votre architecture des données. Si la fondation est défectueuse, l’application construite dessus éprouvera des difficultés en matière de performance, d’intégrité des données et de scalabilité. Avant de remettre un modèle de base de données aux développeurs ou aux équipes de déploiement, un processus d’examen rigoureux est essentiel. Ce guide décrit dix étapes fondamentales pour valider votre ERD, garantissant que votre structure de données est prête pour la production.
Un ERD bien structuré minimise la redondance, impose des contraintes et clarifie les relations entre les entités de données. Sauter des étapes de validation entraîne souvent des refacturations coûteuses plus tard dans le cycle de développement. Cette liste de contrôle couvre les conventions de nommage, la normalisation, les contraintes et les normes de documentation. Suivez ces étapes pour garantir que votre modèle est fiable et maintenable.
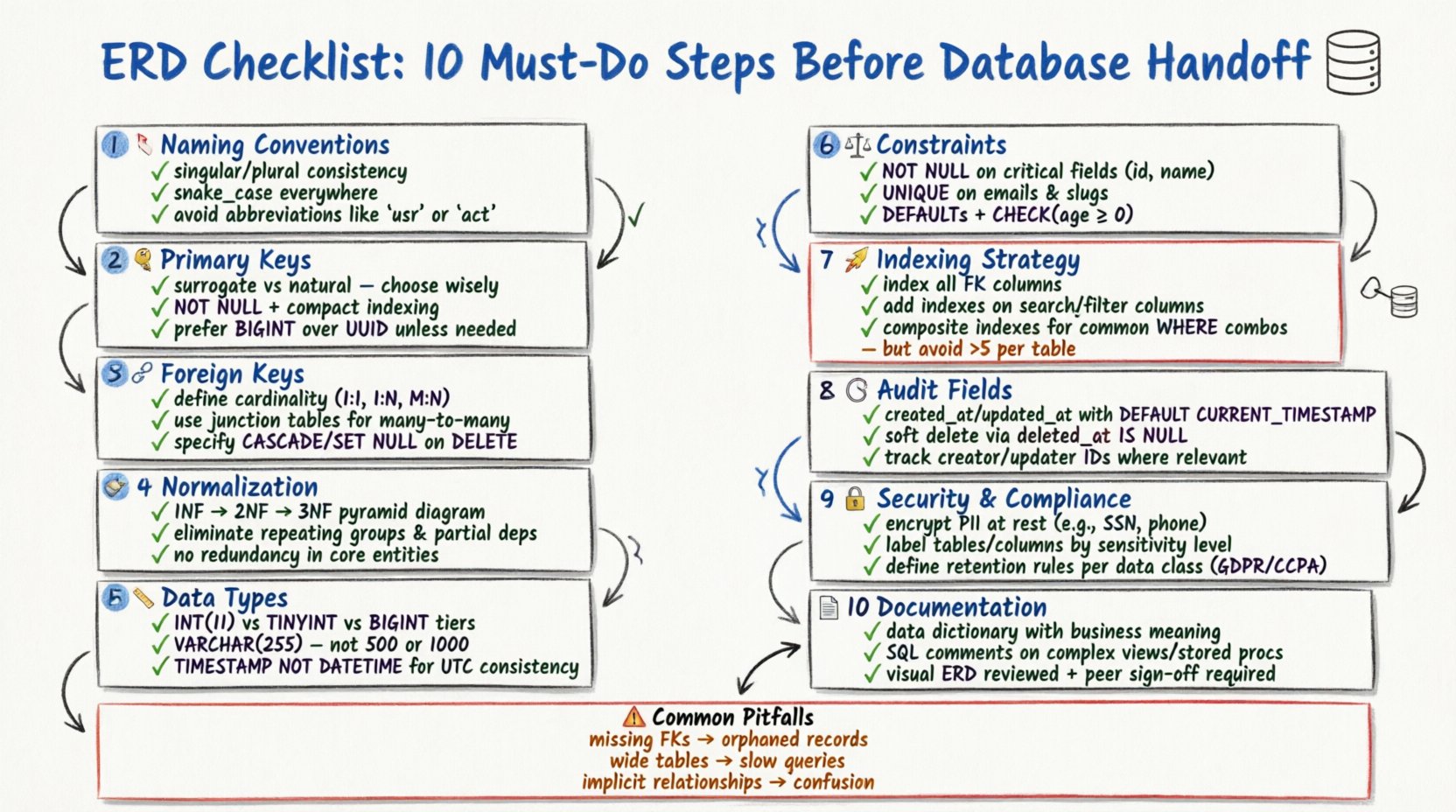
1. Vérifiez les conventions de nommage des entités 🏷️
La cohérence dans le nommage est la première ligne de défense contre la confusion. Chaque table (entité) et chaque colonne (attribut) doit suivre une convention de nommage standardisée. Des noms incohérents entraînent une ambiguïté lors de l’écriture des requêtes SQL et de la maintenance.
- Utilisez de manière cohérente le singulier ou le pluriel : Choisissez un style pour les noms de tables (par exemple,
UtilisateurouUtilisateurs) et appliquez-le de manière cohérente dans tout le schéma. Les noms au singulier sont généralement préférés pour la modélisation conceptuelle, tandis que les noms au pluriel sont souvent utilisés pour l’implémentation physique. - Évitez les mots réservés : Assurez-vous qu’aucun nom d’entité ou de colonne ne contredit les mots réservés propres à la base de données (par exemple,
Commande,Groupe,Index). L’utilisation de mots réservés nécessite souvent l’échappement des caractères, ce qui réduit la lisibilité du code. - Utilisez des traits de soulignement comme séparateurs : Adoptez la convention snake_case pour les colonnes et les tables (par exemple,
profil_utilisateur) afin de maintenir la lisibilité sur différents moteurs de base de données. - Excluez les abréviations : Évitez les abréviations sauf si elles sont universellement comprises.
id_clientest préférable àcid. La clarté doit toujours primer sur la concision.
2. Définissez la stratégie de clé primaire 🔑
Chaque table doit avoir un identifiant unique pour distinguer les enregistrements. Le choix de la clé primaire a une incidence sur les performances, l’indexation et les relations entre les données.
- Clés de substitution vs. clés naturelles :Décidez si vous devez utiliser une clé de substitution (un identifiant artificiel comme un entier auto-incrémenté ou un UUID) ou une clé naturelle (des données déjà existantes, comme une adresse e-mail). Les clés de substitution sont souvent préférées pour leur stabilité, car les clés naturelles peuvent évoluer au fil du temps.
- Implications de l’indexation :Les clés primaires sont automatiquement indexées. Assurez-vous que le type de clé choisi est compact. Les grandes clés (comme les chaînes longues) peuvent gonfler les index et ralentir les opérations de jointure.
- Contraintes d’unicité :Marquez explicitement la colonne clé primaire comme
NON NULL. Une clé primaire ne peut jamais contenir de valeurs nulles, sous quelque circonstance que ce soit. - Clés composées :Si une table nécessite une clé primaire composée (plusieurs colonnes), assurez-vous que chaque relation faisant référence à cette table peut gérer plusieurs colonnes. Cela peut compliquer les contraintes de clé étrangère.
3. Cartographiez les relations de clés étrangères 🔗
Les relations définissent comment les entités interagissent. Une cartographie incorrecte des relations entraîne des données orphelines et des problèmes d’intégrité référentielle.
- Cardinalité :Définissez clairement si une relation est un-à-un, un-à-plusieurs ou plusieurs-à-plusieurs. Le modèle un-à-plusieurs est le plus courant dans les bases de données relationnelles.
- Résolution des relations plusieurs-à-plusieurs :Une relation plusieurs-à-plusieurs nécessite une table de jonction (table de lien). Assurez-vous que cette table inclut les clés étrangères provenant des deux entités parentes, et, si nécessaire, ses propres attributs.
- Actions référentielles :Précisez comment la base de données doit gérer les mises à jour ou les suppressions. Les options courantes incluent
CASCADE(supprimer les enregistrements enfants),SET NULL, ouRESTRICT(empêcher la suppression). Choisissez en fonction des exigences logiques métier. - Référence à soi-même :Si une table fait référence à elle-même (par exemple, une table employé avec une colonne responsable), identifiez clairement cette relation pour éviter toute confusion lors de la revue du schéma.
4. Appliquez les règles de normalisation des données 🧹
La normalisation réduit la redondance des données et améliore l’intégrité. Bien que les systèmes modernes dénormalisent parfois pour des raisons de performance, comprendre les formes est crucial.
| Forme normale | Exigence | Avantage |
|---|---|---|
| 1NF (Première forme normale) | Valeurs atomiques, pas de groupes répétés | Assure que chaque cellule contient une seule valeur |
| 2NF (Deuxième forme normale) | Pas de dépendances partielles | Assure que les colonnes non clés dépendent de toute la clé |
| 3NF (Troisième forme normale) | Pas de dépendances transitives | Assure que les colonnes non clés dépendent uniquement de la clé |
- Éviter la redondance : Si une information est stockée dans plusieurs tables, elle doit être stockée à un seul endroit pour éviter les anomalies de mise à jour.
- Équilibrer avec les performances : Une normalisation stricte peut entraîner des jointures complexes. Documentez toute décision de dénormalisation intentionnelle prise dans le but d’optimiser les requêtes.
- Vérifier les dépendances des données : Assurez-vous que les colonnes dépendent logiquement de la clé primaire et non d’autres colonnes non clés.
5. Sélectionner les types de données appropriés 📏
Choisir le mauvais type de données gaspille de l’espace de stockage et peut entraîner des erreurs de calcul.
- Précision des entiers : Utilisez
TINYINTpour de petits nombres (0-255) etBIGINTpour les identifiants importants. N’utilisez pasINTpour tout, siSMALLINTsuffit. - Longueurs des chaînes : Évitez d’utiliser des types génériques
TEXTouVARCHAR(MAX)sauf si nécessaire. Définissez des longueurs spécifiques (par exemple,VARCHAR(50)pour un code d’état) afin de contraindre les limites des données et améliorer l’efficacité de l’indexation. - Date et heure : Utilisez
TIMESTAMPouDATETIMEselon les exigences de fuseau horaire. Assurez-vous que le format est cohérent (ISO 8601 est une norme). Évitez de stocker les dates sous forme de chaînes. - Valeurs booléennes : Utilisez un type booléen natif si disponible. Sinon, utilisez
TINYINT(1)ouCHAR(1). Évitez de stocker les booléens sous forme de chaînes (« oui »/« non »).
6. Appliquez des contraintes et des valeurs par défaut ⚖️
Les contraintes protègent la qualité des données au niveau de la base de données. Se fier uniquement à la validation au niveau de l’application est risqué.
- Non nul : Marquez les colonnes critiques comme
NON NUL. Cela empêche les données manquantes de corrompre les rapports ou la logique. - Contraintes uniques : Appliquez des contraintes uniques aux colonnes telles que les adresses e-mail ou les noms d’utilisateur pour éviter les entrées en double.
- Valeurs par défaut : Définissez des valeurs par défaut sensées pour les colonnes d’état (par exemple,
status = 'actif') ou des horodatages pour éviter les erreurs de saisie manuelle. - Contraintes de vérification : Utilisez les contraintes de vérification pour valider les règles métier (par exemple,
âge > 18ouprix > 0). Cela garantit que les données respectent des règles logiques, quelle que soit leur source.
7. Élaborez une stratégie d’indexation 🚀
Les index accélèrent la récupération des données, mais ralentissent les opérations d’écriture. Une approche équilibrée est nécessaire.
- Index des clés étrangères : Indexez toujours les colonnes de clés étrangères. Cela est crucial pour les performances des opérations de jointure entre les tables.
- Colonnes de recherche : Identifiez les colonnes fréquemment utilisées dans
WHERE,ORDER BY, ouGROUP BYclauses. Ajoutez des index à ces colonnes. - Index composés : Si les requêtes filtrent sur plusieurs colonnes, créez un index composé. L’ordre des colonnes dans l’index est important et doit correspondre aux modèles de requête.
- Évitez l’indexation excessive : Trop d’index augmentent l’utilisation du disque et ralentissent les opérations
INSERT,UPDATE, etDELETEopérations. Revoyez la nécessité de chaque index.
8. Incluez des champs de traçabilité 🕒
La traçabilité est essentielle pour le débogage et la conformité. Chaque table traitant la logique métier doit suivre les modifications.
- Créé le : Ajouter une
created_atcolonne pour enregistrer le moment où un enregistrement a été inséré pour la première fois. - Mis à jour le : Ajouter une
updated_atcolonne pour enregistrer l’heure de la dernière modification. - Suppression douce : Au lieu de la suppression définitive, envisagez d’ajouter une
deleted_atcolonne. Cela permet de restaurer les données si nécessaire et préserve l’intégrité référentielle. - Qui a modifié : Pour les journaux d’audit critiques, incluez une
created_byetupdated_bycolonne pour stocker l’identifiant de l’utilisateur responsable de l’action.
9. Gérer la sécurité et la conformité 🔒
La sécurité des données doit être intégrée au schéma dès le départ, et non ajoutée en dernier recours.
- Gestion des données personnelles (PII) : Identifiez les informations personnelles identifiables (PII), telles que les numéros de sécurité sociale, les numéros de carte de crédit ou les dossiers médicaux. Ces données doivent être chiffrées ou tokenisées.
- Classification des données : Étiquetez les colonnes sensibles dans la documentation du schéma afin que les développeurs sachent quelles champs nécessitent des mesures de sécurité supplémentaires.
- Contrôle d’accès : Bien que des permissions spécifiques soient souvent définies au niveau de l’application ou de l’utilisateur de la base de données, le schéma doit refléter la sensibilité des données (par exemple, des tables distinctes pour les données publiques et privées).
- Politiques de rétention : Assurez-vous que le schéma prend en charge les exigences de rétention des données. Certaines juridictions exigent la suppression des données après une période donnée.
10. Documenter et valider le schéma 📄
Un schéma sans documentation est une charge. La documentation garantit la maintenabilité future.
- Dictionnaire des données :Maintenez un document décrivant chaque table, chaque colonne et chaque relation. Incluez les définitions métiers pour chaque champ.
- Commentaires :Utilisez des commentaires SQL dans les scripts DDL (Langage de définition des données) pour expliquer la logique complexe ou des règles métier spécifiques.
- Revue visuelle :Générez l’ERD visuellement pour vérifier les références circulaires, les tables orphelines ou les relations manquantes.
- Revue par les pairs :Faites revue le modèle par un autre architecte ou développeur senior. Un regard neuf détecte souvent des erreurs logiques passées inaperçues lors de la conception initiale.
Erreurs courantes de modélisation et corrections 🛠️
Passer en revue la liste de contrôle n’est pas suffisant. Vous devez également être conscient des pièges courants.
| Erreur | Conséquence | Correction |
|---|---|---|
| Clés étrangères manquantes | Enregistrements orphelins, incohérence des données | Ajoutez des contraintes de clés étrangères explicites |
| Tables trop larges | Difficile à lire, requêtes lentes | Divisez en tables liées (Normalisation) |
| Relations implicites | Confusion pendant le développement | Tracez des lignes explicites dans l’ERD, ajoutez les colonnes de clés étrangères |
| Problèmes de nullabilité | Erreurs logiques dans l’application | Définissez NOT NULLlà où les données sont requises |
| Identifiants codés en dur | Difficultés de migration | Utilisez des clés étrangères au lieu des identifiants codés en dur |
Réflexions finales sur la conception du schéma 🎯
Construire un modèle de base de données est un équilibre entre une intégrité stricte et une performance pratique. Suivre cette liste de vérification garantit que votre structure de données répond aux besoins métiers sans compromettre la qualité. Prenez le temps de passer en revue chaque étape avant de valider le schéma dans le contrôle de version. Quelques heures passées à valider le MCD peuvent éviter des semaines de débogage et de refonte ultérieurement.
Souvenez-vous qu’un modèle de base de données est un document vivant. Au fur et à mesure que les exigences métiers évoluent, le schéma doit évoluer lui aussi. Des audits réguliers selon cette liste de vérification maintiendront votre architecture des données en bonne santé et alignée sur vos objectifs. Priorisez la clarté, la cohérence et l’intégrité dans chaque décision que vous prenez.
En suivant ces dix étapes, vous établissez une base solide pour votre application. Votre équipe appréciera la clarté, et votre environnement de production bénéficiera d’une réduction des erreurs et d’une meilleure performance. Intégrez cette liste de vérification comme une étape standard de votre processus de développement.