











Projektowanie bazy danych to fundament każdej solidnej aplikacji oprogramowania. Mimo to nawet doświadczeni inżynierowie często mają trudności z wyjaśnieniem różnicy między wizualnymi projektami a fizyczną realizacją. Pomyłka najczęściej dotyczy diagramu encji i relacji (ERD) oraz schematu bazy danych. Choć te terminy są często używane wymiennie w rozmowach potocznych, reprezentują one różne warstwy procesu architektury danych. Zrozumienie subtelności między nimi nie jest tylko akademickie; decyduje o tym, jak przepływa dane, jak są stosowane ograniczenia oraz jak system ewoluuje z czasem.
W tym przewodniku przeanalizujemy konstrukcje teoretyczne modelowania danych w kontekście rzeczywistych warunków działania systemów zarządzania bazami danych. Przeanalizujemy, jak pojęcia abstrakcyjne przekształcają się w konkretne struktury, jakie są skutki takiego przekształcenia oraz dlaczego utrzymywanie jasnej rozłączności między nimi jest kluczowe dla długoterminowej utrzymywalności. Niezależnie od tego, czy projektujesz nowy system, czy przepisujesz istniejący, jasność w tym zakresie zapobiega kosztownemu zadłużeniu technicznemu.
Czym dokładnie jest ERD? 📐
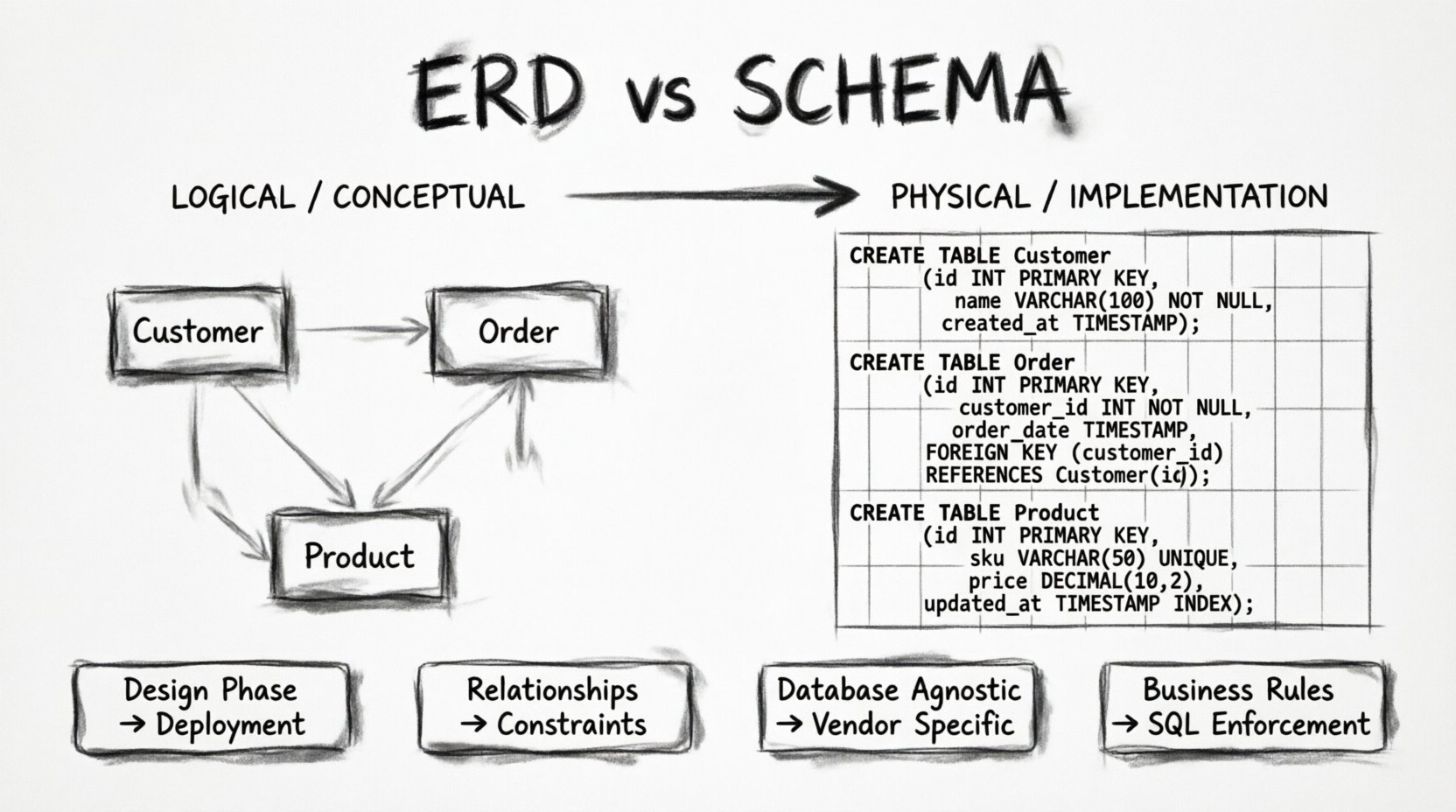
Diagram encji i relacji to reprezentacja koncepcyjna lub logiczna danych. Służy jako most komunikacyjny między stakeholderami biznesowymi, analitykami i programistami. Jego głównym celem jest wizualizacja sposobu, w jaki elementy danych są ze sobą powiązane, bez zagłębiania się w szczegóły konkretnej bazy danych.
W centrum ERD skupia się na trzech podstawowych elementach:
- Encje: Odnoszą się do rzeczywistych obiektów lub pojęć. W systemie detalicznym encją może byćKlienta, Produkt, lubZamówienie. Encje to rzeczowniki Twojego świata danych.
- Atrybuty: To właściwości lub cechy opisujące encję. DlaKlienta, atrybuty mogą obejmowaćImię, Adres e-mail, lubData rejestracji. Atrybuty określają, jakie dane musimy przechowywać dotyczące encji.
- Związki: Określa sposób, w jaki encje się ze sobą oddziałują. Czy jeden klient może składać wiele zamówień? Czy jeden produkt może należeć do wielu kategorii? Związki to czasowniki łączące rzeczowniki.
Piękno ERD tkwi w jego abstrakcji. Nie interesuje go, czy dane w końcu znajdą się w PostgreSQL, MySQL czy magazynie dokumentów NoSQL. Zajmuje się integralnością informacji i logicznym przepływem. Styl notacji się różni, przy czym notacja Crow’s Foot jest powszechnym standardem do przedstawiania liczności (jeden do jednego, jeden do wielu, wiele do wielu). Ta język wizualny pozwala zespołom zweryfikować logikę modelu danych jeszcze przed napisaniem jednej linii kodu.
Podczas tworzenia ERD skupiamy się na normalizacji. Oznacza to organizację danych w celu zmniejszenia nadmiarowości i poprawy integralności danych. Analizujemy, jak rozbić duże tabele na mniejsze, powiązane ze sobą, aby upewnić się, że aktualizacja informacji w jednym miejscu aktualizuje ją wszędzie tam, gdzie to istotne. ERD to mapa terenu; pokazuje drogi i punkty orientacyjne, ale nie materiał wykończenia nawierzchni.
Definiowanie schematu bazy danych 🏗️
Jeśli ERD to mapa, to schemat to sam teren. Schemat bazy danych to struktura fizyczna bazy danych. Jest to konkretny zestaw definicji, które dokładnie informują system zarządzania bazami danych (DBMS), jak przechowywać dane. Podczas gdy ERD mówi w kategoriach pojęć, schemat mówi w kategoriach typów danych, ograniczeń i silników przechowywania.
Schemat definiuje następujące szczegóły techniczne:
- Tabele: Jednostka ERD staje się fizyczną tabelą. Schemat określa nazwę tabeli, która często musi spełniać rygorystyczne zasady nazewnictwa (np. snake_case).
- Typy danych: Atrybut takiej jakWiek staje się
INTlubSMALLINT. AtrybutEmail staje sięVARCHARz określonym limitem długości. AtrybutTimestamp staje sięTIMESTAMP Z STREFĄ CZASOWĄ. Te wybory wpływają na przestrzeń magazynowania i wydajność zapytań. - Ograniczenia: To jest miejsce, w którym realizowane jest logiczne zapewnienie ERD. Klucze główne (PK) zapewniają unikalność. Klucze obce (FK) zapewniają integralność referencyjną między tabelami.
NOT NULLOgraniczenia zapewniają, że pola wymagane są wypełnione. Ograniczenia unikalności zapobiegają powtarzającym się wpisom. - Indeksy: Choć często pomijane w ERD najwyższego poziomu, schemat określa, gdzie są tworzone indeksy. Indeksy przyspieszają operacje odczytu, ale spowalniają zapisy. Schemat określa fizyczną optymalizację bazy danych.
Schemat odpowiada również za bezpieczeństwo i kontrolę dostępu. Określa, kto może odczytywać lub zapisywać do określonych tabel. Obsługuje transakcje, zapewniając, że zmiany danych są atomowe. Gdy programista pisze instrukcjęCREATE TABLE, definiuje on schemat. Jest to warstwa implementacji, z którą kod aplikacji bezpośrednio się komunikuje.
Kluczowe różnice na pierwszy rzut oka 📊
Aby wyjaśnić różnicę, pomocne jest spojrzenie na różnice obok siebie. ERD jest abstrakcyjny i skierowany na projektowanie, podczas gdy schemat jest konkretny i skierowany na implementację.
| Funkcja | ERD (Diagram relacji encji) | Schemat bazy danych |
|---|---|---|
| Charakter | Model logiczny / koncepcyjny | Model fizyczny |
| Skupienie | Związki i przepływ danych | Przechowywanie i wymuszanie |
| Notacja | Pola, linie, symbole kłykci | Instrukcje SQL, skrypty DDL |
| Zależność | Niezależny od bazy danych | Specyficzny dla bazy danych (dostawca) |
| Ograniczenia | Zespolone (zasady biznesowe) | Jawne (PK, FK, Check) |
| Etapa | Faza projektowania | Faza rozwoju / wdrażania |
Ten tabelka pokazuje, że mimo że są powiązane, działają na różnych etapach cyklu życia oprogramowania. Pomylenie ich często prowadzi do sytuacji, gdy programiści próbują narzucić ograniczenia fizyczne modelowi logicznemu, zanim został on w pełni zwalidowany.
Proces tłumaczenia: od diagramu do kodu 🔄
Droga od ERD do schematu nie zawsze jest prostym odwzorowaniem 1:1. Warstwa tłumaczenia to miejsce, w którym wiele projektów napotyka trudności. Model logiczny zakłada idealne warunki, ale model fizyczny musi radzić sobie z wydajnością, systemami dziedzicznymi oraz specyficznymi możliwościami silnika.
Normalizacja vs. Wydajność
ERD jest zazwyczaj normalizowany do trzeciej formy normalnej (3NF). To minimalizuje powielanie danych. Jednak podczas tłumaczenia na schemat aplikacji o wysokim obciążeniu programiści często dokonują denormalizacji. Oznacza to celowe powielanie danych w celu zmniejszenia liczby połączeń wymaganych podczas zapytania. Na przykład przechowywanie Imię i nazwisko klienta bezpośrednio w tabeli Zamówienie tabela, nawet jeśli narusza ścisłe zasady normalizacji, może znacznie przyspieszyć zapytania raportujące. ERD może pokazywać relację, ale schemat może przechowywać dane redundantnie w celu przyspieszenia.
Szczegóły typów danych
ERD po prostu mówi, że pole to Data. Schemat musi zdecydować między DATA, DATETIME, lub CZAS ZNAKU. Musi zdecydować się na zestawy znaków (UTF8, ASCII) i zasady porównania. Te decyzje wpływają na sposób, w jaki aplikacja obsługuje międzynarodowość i sortowanie. Ogólny ERD nie może oddać tych subtelności.
Obsługa relacji wiele do wielu
W ERD relacja wiele do wielu jest rysowana jako linia z podwójnymi piórami kruka. W schemacie fizycznym nie może istnieć bezpośrednio. Musi zostać rozwiązana jako dwie relacje jeden do wielu za pomocą tabeli pośredniej (lub mostowej). Schemat musi zdefiniować klucz główny tej tabeli pośredniej, który może być kluczem złożonym lub kluczem zastępczym (UUID). Ta zmiana strukturalna jest niewidoczna na diagramie najwyższego poziomu, ale jest krytyczna dla struktury bazy danych.
Dlaczego różnica ma znaczenie dla programistów 🛠️
Zrozumienie różnicy między tymi dwoma pojęciami nie dotyczy tylko teorii; ma wpływ na codzienną pracę. Gdy pojawia się błąd integralności danych, wiedza, czy problem tkwi w projekcie logicznym, czy w implementacji fizycznej, jest pierwszym krokiem do jego rozwiązania.
Debugowanie integralności danych
Jeśli napotkasz sytuację, w której dane są nieoczekiwanie duplikowane, musisz zadać pytanie: Czy ERD jest błędny, czy brakuje ograniczenia w schemacie? Brakujące klucze obce w schemacie pozwalają na istnienie zaniedbanych rekordów, które logika ERD uznawała za niemożliwe. Z kolei jeśli ERD jest zbyt sztywny i nie uwzględnia usuwania miękkiego, schemat może wymuszać usuwanie twarde, które narusza logikę biznesową. Oddzielenie tych aspektów pozwala dokładnie zlokalizować źródło błędu.
Kontrola wersji i współpraca
Podczas zarządzania bazą danych kontrola wersji jest niezbędna. Jednak ERD i schematy rozwijają się różnie. ERD zmienia się, gdy zmieniają się wymagania biznesowe. Schemat zmienia się, gdy baza danych wymaga optymalizacji lub gdy stosuje się migracje. Zachowanie ich zsynchronizowania to wyzwanie. Jeśli schemat zmienia się bez aktualizacji ERD, dokumentacja staje się przestarzała. Jeśli ERD zmienia się bez skryptu migracji, baza danych pozostaje niezgodna z projektem.
Wprowadzanie nowych członków zespołu
Nowi programiści często mają trudności z zrozumieniem struktury bazy danych. Pokazując im ERD, dostarczasz kontekst, jak system działa koncepcyjnie. Pokazując im schemat, dostarczasz kontekst, jak system działa technicznie. Skuteczne wdrażanie wymaga obu. ERD odpowiada na pytanie „Co to oznacza?” a schemat odpowiada na pytanie „Jak do niego uzyskać dostęp?”.
Typowe pułapki w modelowaniu danych 🚧
Mimo jasnych definicji, wiele zespołów wpada w pułapki, traktując ERD i schemat jako tożsame.
- Pomijanie ERD:Skakanie bezpośrednio do pisania skryptów SQL schematu często prowadzi do długu strukturalnego. Bez modelu wizualnego relacje często są zapomniane lub implementowane niezgodnie.
- Ignorowanie ograniczeń:Opieranie się wyłącznie na kodzie aplikacji w celu wymuszania reguł (np. unikalnych adresów e-mail) zamiast ograniczeń bazy danych (indeksów UNIQUE) jest ryzykowne. Schemat powinien być ostatnią linii obrony integralności danych.
- Przeprojektowanie: Tworzenie ERD z nadmierną szczegółowością, z każdym możliwym atrybutem, zanim wymagania będą jasne. Powoduje to schemat, który jest trudny do migracji w przyszłości.
- Rozłączenie narzędzi: Używanie narzędzia projektowego, które nie obsługuje generowania kodu, albo używanie narzędzia bazodanowego, które nie obsługuje inżynierii wstecznej. Powoduje to ręczny rozłączenie, gdzie zmiany są wprowadzane w jednym miejscu, ale nie w drugim.
- Zakładanie równoważności: Uważanie, że doskonały ERD gwarantuje doskonałą bazę danych. Schemat podlega ograniczeniom sprzętowym, wzorców zapytań i problemom współbieżności, których ERD nie może przewidzieć.
Utrzymywanie synchronizacji w czasie 🔄
W miarę wzrostu aplikacji baza danych się rozwija. Dodawane są nowe funkcje, a stare są wycofywane. Utrzymywanie związku między ERD a schematem staje się coraz trudniejsze z upływem czasu. Zjawisko to często nazywa sięrozłączenie schematu.
Aby temu zapobiec, zespoły powinny przyjąć rygorystyczny przepływ pracy:
- Projektowanie najpierw: Zawsze aktualizuj ERD przed napisaniem skryptów migracji.
- Automatyzacja generowania: Używaj narzędzi, które mogą generować SQL DDL z ERD. Zapewnia to, że schemat odpowiada projektowi.
- Inżynieria wsteczna: Okresowo uruchamiaj narzędzia inżynierii wstecznej na działającej bazie danych, aby zaktualizować ERD. Pozwala to wykryć zmiany wprowadzone przez bezpośrednie zapytania SQL, które pomijają proces projektowania.
- Dokumentacja: Upewnij się, że ERD jest przechowywany w tym samym repozytorium co skrypty migracji schematu. Tworzy to jedno źródło prawdy.
Ta dyscyplina zapobiega przekształceniu bazy danych w czarną skrzynkę. Gdy ERD i schemat są zsynchronizowane, system pozostaje przejrzysty i zarządzalny.
Wpływ na wydajność zapytań i optymalizację ⚡
Schemat decyduje o wydajności bardziej niż ERD. Choć ERD pokazuje relacje, schemat określa sposób dostępu silnika bazy danych do danych. ERD może pokazywać logiczne połączenie międzyUżytkownikami i Posts. Schemat decyduje, czy indeks istnieje na poluUser_ID w tabeliPosts tabela.
Bez odpowiedniego indeksowania w schemacie prosty zapytanie może wywołać pełne skanowanie tabeli. Jest to ograniczenie fizyczne. Diagram ER nie może pokazać planu wykonania. Deweloperzy muszą spojrzeć na schemat, aby zrozumieć, dlaczego zapytanie jest wolne. Muszą przeanalizować indeksy, strategię partycjonowania oraz typy danych.
Dodatkowo schemat obsługuje mechanizmy blokowania. Jeśli wiele użytkowników aktualizuje ten sam rekord, poziom izolacji i strategia blokowania w schemacie decydują, czy blokują się wzajemnie. Diagram ER nie mówi nic o współbieżności. To istotna różnica dla systemów o wysokim obciążeniu.
Mostowanie luki za pomocą najlepszych praktyk 🏆
Aby zapewnić, że oba modele skutecznie spełniają swoje zadania, rozważ przyjęcie tych standardów:
- Używaj standardowych konwencji nazewnictwa: Upewnij się, że nazwy tabel w schemacie odpowiadają nazwom encji w diagramie ER. Spójność zmniejsza obciążenie poznawcze.
- Dokumentuj ograniczenia jawnie: W diagramie ER oznacz relacje zgodnie z ich licznością. W schemacie oznacz kolumny ich ograniczeniami. Uczynij zasady widocznymi w obu miejscach.
- Regularnie przeglądarki: Zaprojektuj kwartalne przeglądy diagramu ER w stosunku do schematu produkcyjnego. Szukaj odchyleń i anomalii.
- Oddzielaj odpowiedzialności: Traktuj diagram ER jako artefakt biznesowy, a schemat jako artefakt techniczny. Nie mieszkaj logiki biznesowej z definicjami schematu fizycznego.
- Planuj migrację: Gdy diagram ER ulega zmianie, schemat musi zostać zmieniony za pomocą skryptu migracji. Nigdy nie zmieniaj schematu bezpośrednio w środowisku produkcyjnym bez wersjonowanego skryptu.
Człowiek w modelowaniu danych 👥
Na końcu te modele są tworzone dla ludzi, a nie tylko dla maszyn. Diagram ER służy do komunikacji. Pozwala menedżerowi produktu zrozumieć strukturę danych bez znajomości SQL. Schemat jest dla maszyny. Pozwala aplikacji efektywnie pobierać dane.
Gdy deweloperzy rozumieją tę różnicę między człowiekiem a maszyną, mogą projektować lepsze systemy. Wiedzą, kiedy uprościć diagram ER dla stakeholderów, a kiedy szczegółowo opisać schemat dla silnika bazy danych. Ta dwuwartościowość to esencja architektury bazy danych.
Szanując granicę między diagramem logicznym a implementacją fizyczną, zespoły unikają typowych pułapek spowodowanych uszkodzeniem danych i zawieszeniami wydajności. Diagram ER zapewnia wizję; schemat zapewnia rzeczywistość. Oba są niezbędne dla skutecznego systemu.
Ostateczne rozważania nad architekturą danych 🧠
Różnica między diagramem encji i relacji a schematem bazy danych to podstawowy fundament inżynierii oprogramowania. Reprezentuje przejście od myśli do działania, od pomysłu do realizacji. Podczas gdy diagram ER zapisuje relacje i logikę napędzające biznes, schemat zapisuje ograniczenia i struktury napędzające aplikację.
Opanowanie relacji między tymi dwoma modelami nie polega na zapamiętywaniu definicji. Polega na zrozumieniu cyklu życia danych. Polega na wiedzy, że zmiana w diagramie wymaga zmiany w kodzie, a zmiana w kodzie musi odzwierciedlać się z powrotem w diagramie. Ten cykl zapewnia, że system pozostaje spójny, wiarygodny i skalowalny.
W miarę postępowania w swojej drodze rozwojowej, utrzymuj te dwa modele odseparowane. Używaj diagramu ER do planowania i komunikacji. Używaj schematu do budowania i wymuszania. Gdy je wyrównasz, budujesz systemy, które wytrzymają próbę czasu i zmian.
Pamiętaj, że celem nie jest tylko przechowywanie danych, ale przechowywanie ich w sposób, który ma sens. Ten sens pochodzi z logicznej przejrzystości diagramu ER i strukturalnej ścisłości schematu. Razem tworzą fundament Twojej architektury danych.