








Projektowanie solidnego schematu bazy danych to jedno z najważniejszych zadań w rozwoju oprogramowania. Diagram relacji encji (ERD) pełni rolę projektu architektury danych. Jeśli fundament jest wadliwy, aplikacja oparta na nim będzie miała problemy z wydajnością, integralnością danych i skalowalnością. Zanim przekażesz model bazy danych programistom lub zespołom wdrażającym, konieczna jest szczegółowa analiza. Ten przewodnik przedstawia dziesięć kluczowych kroków weryfikacji ERD, zapewniając, że struktura danych jest gotowa do wdrożenia w środowisku produkcyjnym.
Dobrze zaprojektowany ERD minimalizuje nadmiarowość, zastosowuje ograniczenia i jasno definiuje relacje między jednostkami danych. Pomijanie kroków weryfikacji często prowadzi do kosztownej refaktoryzacji na późniejszych etapach cyklu rozwoju oprogramowania. Ta lista kontrolna obejmuje zasady nazewnictwa, normalizację, ograniczenia oraz standardy dokumentacji. Postępuj zgodnie z tymi krokami, aby zapewnić, że Twój model jest wiarygodny i łatwy w utrzymaniu.
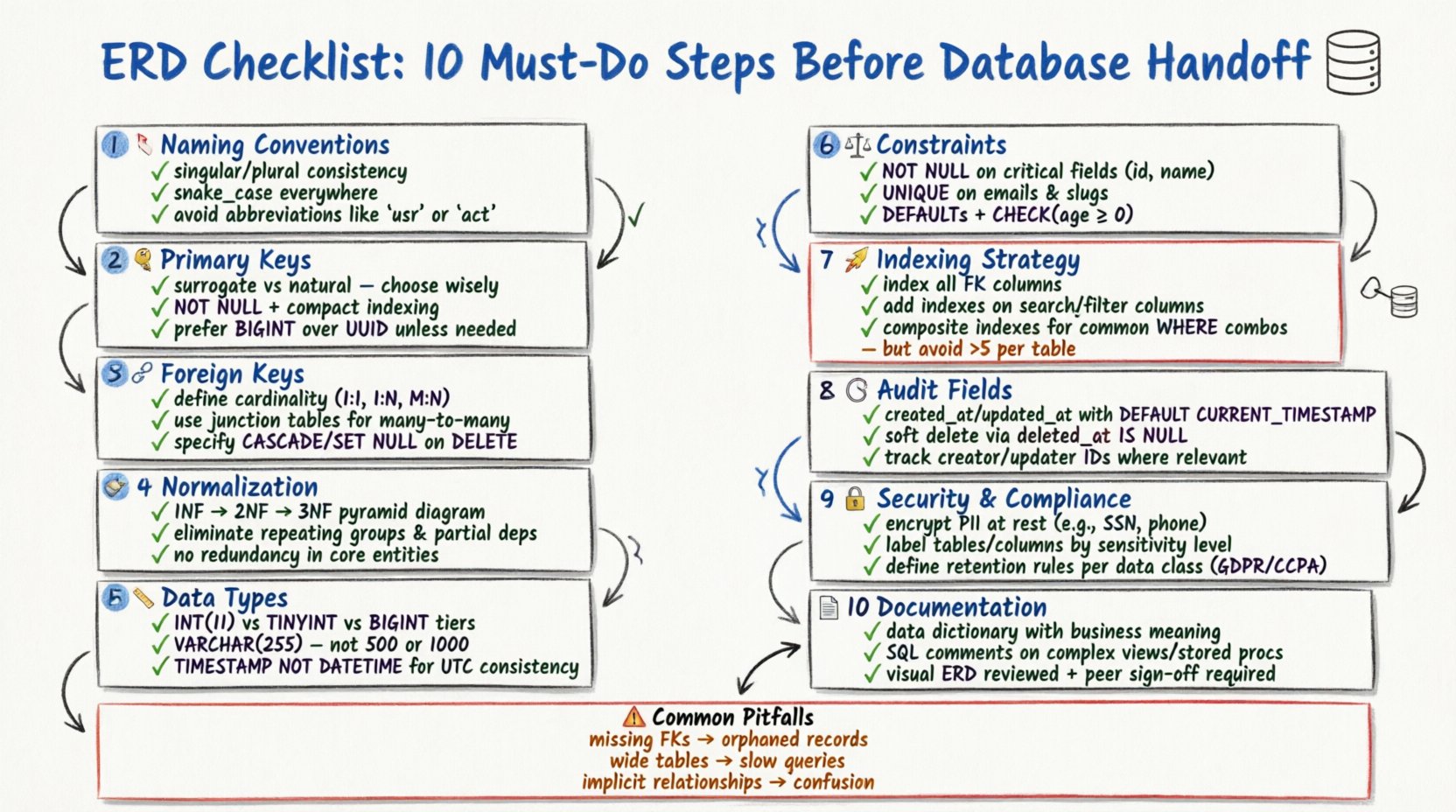
1. Sprawdź zasady nazewnictwa encji 🏷️
Spójność w nazewnictwie to pierwsza linia obrony przed zamieszaniem. Każda tabela (encja) i kolumna (atrybut) muszą przestrzegać znormalizowanego schematu nazewnictwa. Niespójne nazwy prowadzą do niejasności podczas pisania zapytań SQL i ich utrzymania.
- Używaj zgodnie nazw liczby pojedynczej lub mnogiej: Wybierz jedną stylizację dla nazw tabel (np.
UżytkownikvsUżytkownicy) i stosuj ją we wszystkich częściach schematu. Nazwy liczby pojedynczej są zazwyczaj preferowane w modelowaniu koncepcyjnym, podczas gdy nazwy liczby mnogiej często stosuje się w implementacji fizycznej. - Unikaj słów kluczowych zarezerwowanych: Upewnij się, że żadna nazwa encji ani kolumny nie koliduje z zarezerwowanymi słowami specyficznymi dla bazy danych (np.
Zamówienie,Grupa,Indeks). Używanie słów kluczowych zarezerwowanych często wymaga ucieczki znaków, co zmniejsza czytelność kodu. - Używaj podkreślników jako separatorów: Używaj konwencji snake_case dla kolumn i tabel (np.
profil_użytkownika) aby zachować czytelność na różnych silnikach baz danych. - Wyklucz skróty: Unikaj skrótów, chyba że są powszechnie rozumiane.
id_klientajest lepsze niżidk. Jasność powinna zawsze mieć priorytet przed krótkością.
2. Zdefiniuj strategię klucza głównego 🔑
Każda tabela musi mieć unikalny identyfikator do rozróżniania rekordów. Wybór klucza głównego wpływa na wydajność, indeksowanie i relacje danych.
- Klucze zastępcze vs. naturalne: Zdecyduj, czy użyć klucza zastępczego (sztucznego identyfikatora, takiego jak automatycznie zwiększający się numer całkowity lub UUID) czy klucza naturalnego (danych, które już istnieją, takich jak adres e-mail). Klucze zastępcze są często preferowane ze względu na stabilność, ponieważ klucze naturalne mogą się zmieniać z czasem.
- Skutki indeksowania: Klucze główne są automatycznie indeksowane. Upewnij się, że wybrany typ klucza jest kompaktowy. Duże klucze (takie jak długie ciągi znaków) mogą powiększać indeksy i spowalniać operacje łączenia.
- Ograniczenia unikalności: Jawnie oznacz kolumnę klucza głównego jako
NOT NULL. Klucz główny nie może zawierać wartości NULL w żadnym przypadku. - Klucze złożone: Jeśli tabela wymaga klucza głównego złożonego (wielu kolumn), upewnij się, że każda relacja odnosząca się do tej tabeli może obsługiwać wiele kolumn. Może to skomplikować ograniczenia kluczy obcych.
3. Zmapuj relacje kluczy obcych 🔗
Relacje definiują sposób działania między jednostkami. Niepoprawne mapowanie relacji prowadzi do porzucenia danych i problemów z integralnością referencyjną.
- Moc zbioru: Jawnie określ, czy relacja jest jedno do jednego, jedno do wielu, czy wiele do wielu. Relacja jedno do wielu jest najczęściej występującym wzorcem w bazach danych relacyjnych.
- Rozwiązanie relacji wiele do wielu: Relacja wiele do wielu wymaga tabeli pośredniej (tabeli łączącej). Upewnij się, że ta tabela zawiera klucze obce z obu jednostek nadrzędnych oraz, jeśli potrzeba, własne atrybuty.
- Działania referencyjne: Określ, jak baza danych ma obsługiwać aktualizacje lub usunięcia. Powszechne opcje to
CASCADE(usunięcie rekordów potomnych),SET NULL, lubRESTRICT(zabronienie usunięcia). Wybierz na podstawie wymagań logiki biznesowej. - Odwołanie do samego siebie: Jeśli tabela odwołuje się do samej siebie (np. tabela pracowników z kolumną menedżera), jasno oznacz tę relację, aby uniknąć nieporozumień podczas przeglądu schematu.
4. Zastosuj zasady normalizacji danych 🧹
Normalizacja zmniejsza nadmiarowość danych i poprawia integralność. Choć nowoczesne systemy czasem zniekształcają dane dla wydajności, zrozumienie form jest kluczowe.
| Postać normalna | Wymóg | Zalety |
|---|---|---|
| 1NF (Pierwsza postać normalna) | Wartości atomowe, brak powtarzających się grup | Zapewnia, że każda komórka zawiera jedną wartość |
| 2NF (Druga postać normalna) | Brak częściowych zależności | Zapewnia, że kolumny niekluczowe zależą od całego klucza |
| 3NF (Trzecia postać normalna) | Brak zależności przechodnich | Zapewnia, że kolumny niekluczowe zależą wyłącznie od klucza |
- Unikaj nadmiarowości: Jeśli część informacji jest przechowywana w wielu tabelach, powinna być przechowywana w jednym miejscu, aby uniknąć anomalii aktualizacji.
- Zrównowaguj z wydajnością: Ścisła normalizacja może prowadzić do skomplikowanych połączeń. Dokumentuj wszelkie celowe decyzje o denormalizacji podjęte w celu optymalizacji zapytań.
- Sprawdź zależności danych: Upewnij się, że kolumny są logicznie zależne od klucza głównego, a nie od innych kolumn niekluczowych.
5. Wybierz odpowiednie typy danych 📏
Wybór nieprawidłowego typu danych marnuje przestrzeń pamięci i może prowadzić do błędów obliczeniowych.
- Precyzja liczb całkowitych: Użyj
TINYINTdo małych liczb (0-255) orazBIGINTdo dużych identyfikatorów. Nie używajINTdo wszystkiego, jeśliSMALLINTwystarczy. - Długość ciągów: Unikaj używania ogólnych
TEXTlubVARCHAR(MAX)chyba że to konieczne. Określ konkretne długości (np.VARCHAR(50)dla kodu stanu) w celu ograniczenia danych i poprawy wydajności indeksowania. - Data i czas: Użyj
TIMESTAMPlubDATETIMEw zależności od wymagań strefy czasowej. Upewnij się, że format jest spójny (ISO 8601 to standard). Unikaj przechowywania dat jako ciągów znaków. - Wartości logiczne: Użyj wbudowanego typu logicznego, jeśli jest dostępny. Jeśli nie, użyj
TINYINT(1)lubCHAR(1). Unikaj przechowywania wartości logicznych jako ciągów znaków („tak”/„nie”).
6. Wymuszaj ograniczenia i domyślne wartości ⚖️
Ograniczenia chronią jakość danych na poziomie bazy danych. Opieranie się wyłącznie na weryfikacji na poziomie aplikacji jest ryzykowne.
- Nie null: Oznacz kluczowe kolumny jako
NOT NULL. Zapobiega temu, by brakujące dane zepsuły raporty lub logikę. - Ograniczenia unikalności: Zastosuj ograniczenia unikalności do kolumn takich jak adresy e-mail lub nazwy użytkowników, aby zapobiec powtórzonym wpisom.
- Wartości domyślne: Ustaw rozsądne wartości domyślne dla kolumn statusu (np.
status = 'aktywny') lub znaczniki czasu, aby uniknąć błędów wprowadzanych ręcznie. - Ograniczenia sprawdzające:Użyj ograniczeń sprawdzających do weryfikacji reguł biznesowych (np.
wiek > 18lubcena > 0). Zapewnia to, że dane spełniają reguły logiczne niezależnie od źródła.
7. Zaprojektuj strategię indeksowania 🚀
Indeksy przyspieszają pobieranie danych, ale spowalniają operacje zapisu. Konieczna jest zrównoważona strategia.
- Indeksy kluczy obcych: Zawsze indeksuj kolumny kluczy obcych. Jest to kluczowe dla wydajności operacji łączenia tabel.
- Kolumny wyszukiwania: Zidentyfikuj kolumny często używane w
WHERE,ORDER BY, lubGROUP BYklauzulach. Dodaj indeksy do tych kolumn. - Indeksy złożone: Jeśli zapytania filtrowane są według wielu kolumn, utwórz indeks złożony. Kolejność kolumn w indeksie ma znaczenie i powinna odpowiadać wzorcom zapytań.
- Unikaj nadmiernego indeksowania: Zbyt wiele indeksów zwiększa zużycie dysku i spowalnia operacje
INSERT,UPDATE, orazDELETEoperacji. Przejrzyj potrzebę każdego indeksu.
8. Uwzględnij pola audytu 🕒
Śledzenie zmian jest kluczowe dla debugowania i zgodności. Każda tabela obsługująca logikę biznesową powinna śledzić zmiany.
- Utworzono w: Dodaj kolumnę
created_ataby zapisać czas pierwszego wstawienia rekordu. - Zaktualizowano w: Dodaj kolumnę
updated_ataby zapisać czas ostatniej modyfikacji. - Miękkie usuwanie: Zamiast twardego usuwania, rozważ dodanie kolumny
deleted_ataby umożliwić przywrócenie danych w razie potrzeby i zachować integralność referencyjną. - Kto zmienił: W przypadku krytycznych śladów audytowych, dodaj kolumnę
created_byorazupdated_byaby zapisać identyfikator użytkownika odpowiedzialnego za działanie.
9. Zajmij się bezpieczeństwem i zgodnością 🔒
Bezpieczeństwo danych musi być zintegrowane ze schematem, a nie dodawane jako połączenie.
- Obsługa danych osobowych (PII): Zidentyfikuj informacje osobowe (PII), takie jak numery ubezpieczenia społecznego, numery kart kredytowych lub rekordy medyczne. Powinny one być szyfrowane lub tokenizowane.
- Klasyfikacja danych: Oznacz wrażliwe kolumny w dokumentacji schematu, aby deweloperzy wiedzieli, które pola wymagają dodatkowych środków bezpieczeństwa.
- Kontrola dostępu: Choć konkretne uprawnienia są często ustawiane na poziomie aplikacji lub użytkownika bazy danych, schemat powinien odzwierciedlać wrażliwość danych (np. osobne tabele dla danych publicznych w porównaniu do prywatnych).
- Polityki przechowywania: Upewnij się, że schemat obsługuje wymagania dotyczące przechowywania danych. Niektóre jurysdykcje wymagają usunięcia danych po określonym czasie.
10. Dokumentuj i weryfikuj schemat 📄
Schemat bez dokumentacji to obciążenie. Dokumentacja zapewnia utrzymywalność w przyszłości.
- Słownik danych:Utrzymuj dokument opisujący każdą tabelę, kolumnę i relację. Włącz definicje biznesowe dla każdego pola.
- Komentarze:Używaj komentarzy SQL w skryptach DDL (język definicji danych), aby wyjaśnić złożoną logikę lub konkretne zasady biznesowe.
- Wizualna kontrola:Wygeneruj ERD wizualnie, aby sprawdzić cykliczne odniesienia, porzucone tabele lub brakujące relacje.
- Recenzja przez kolegów:Niech inny architekt lub starszy programista przeanalizuje model. Świeże spojrzenie często wykrywa błędy logiczne, które zostały pominięte podczas początkowego projektowania.
Typowe błędy modelowania i ich rozwiązania 🛠️
Przeglądanie listy kontrolnej nie wystarczy. Musisz również być świadomy typowych pułapek.
| Błąd | Skutek | Rozwiązanie |
|---|---|---|
| Brakujące klucze obce | Porzucone rekordy, niezgodność danych | Dodaj jawne ograniczenia kluczy obcych |
| Szerokie tabele | Trudne do odczytania, powolne zapytania | Podziel na powiązane tabele (normalizacja) |
| Niejawne relacje | Zmieszanie podczas rozwoju | Narysuj jawne linie w ERD, dodaj kolumny FK |
| Problemy z dopuszczalnością wartości NULL | Błędy logiki w aplikacji | Ustaw NOT NULL tam, gdzie dane są wymagane |
| Zakodowane ID | Trudności migracji | Używaj kluczy obcych zamiast stało zdefiniowanych identyfikatorów |
Ostateczne rozważania dotyczące projektowania schematu 🎯
Tworzenie modelu bazy danych to równowaga między ściśle utrzymywaną integralnością a praktyczną wydajnością. Stosowanie tego listy kontrolnej zapewnia, że struktura danych obsługuje potrzeby biznesowe bez kompromitowania jakości. Poświęć czas na przejrzenie każdego kroku przed zatwierdzeniem schematu w systemie kontroli wersji. Kilka godzin poświęconych weryfikacji ERD może zaoszczędzić tygodnie debugowania i przekształcania kodu w przyszłości.
Pamiętaj, że model bazy danych to dokument dynamiczny. W miarę zmian wymagań biznesowych schemat musi się rozwijać. Regularne audyty w oparciu o tę listę kontrolną utrzymają Twoją architekturę danych zdrową i zgodną z Twoimi celami. Zawsze priorytetem powinna być przejrzystość, spójność i integralność w każdej decyzji, którą podejmujesz.
Przestrzegając tych dziesięciu kroków, tworzysz solidną podstawę dla swojej aplikacji. Twój zespół doceni przejrzystość, a środowisko produkcyjne skorzysta z mniejszej liczby błędów i lepszej wydajności. Zrób listę kontrolną standardową częścią swojego procesu rozwoju.