









Projetar um esquema de banco de dados robusto é uma das tarefas mais críticas no desenvolvimento de software. Um Diagrama de Relacionamento de Entidades (ERD) serve como o projeto arquitetônico para sua arquitetura de dados. Se a base estiver comprometida, o aplicativo construído sobre ela terá dificuldades com desempenho, integridade de dados e escalabilidade. Antes de entregar um modelo de banco de dados para equipes de desenvolvimento ou implantação, um processo rigoroso de revisão é essencial. Este guia apresenta dez etapas essenciais para validar seu ERD, garantindo que sua estrutura de dados esteja pronta para produção.
Um ERD bem estruturado minimiza redundâncias, impõe restrições e esclarece as relações entre entidades de dados. Pular etapas de validação frequentemente leva a refatorações custosas mais tarde no ciclo de vida do desenvolvimento. Esta lista de verificação abrange convenções de nomeação, normalização, restrições e padrões de documentação. Siga estas etapas para garantir que seu modelo seja confiável e passível de manutenção.
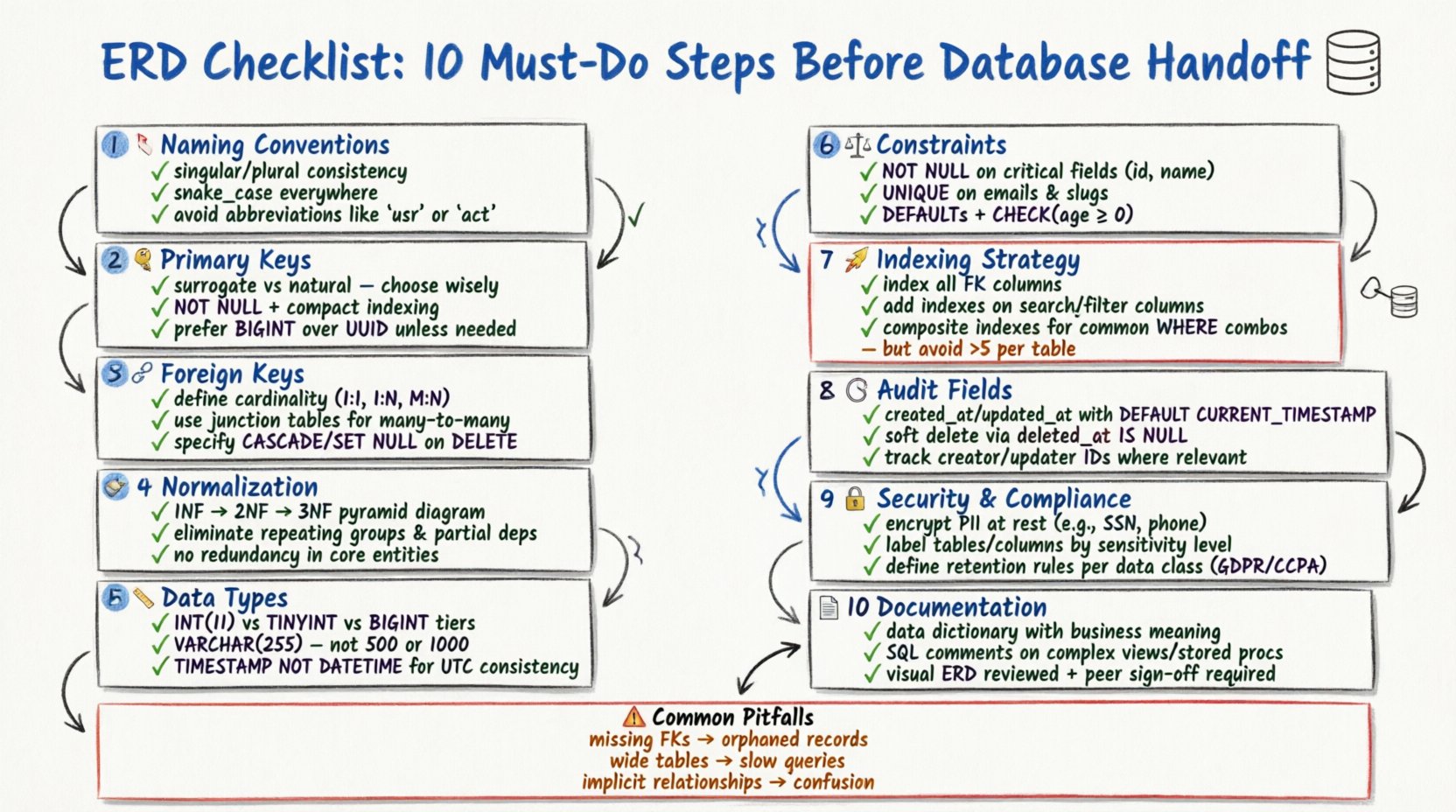
1. Verifique as Convenções de Nomeação de Entidades 🏷️
A consistência na nomeação é a primeira linha de defesa contra confusão. Cada tabela (entidade) e coluna (atributo) deve seguir uma convenção de nomeação padronizada. Nomes inconsistentes levam a ambiguidades durante a escrita de consultas SQL e manutenção.
- Use singular ou plural de forma consistente: Escolha um estilo para os nomes das tabelas (por exemplo,
UsuáriovsUsuários) e aplique-o em todo o esquema. Nomes no singular são geralmente preferidos para modelagem conceitual, enquanto nomes no plural são frequentemente usados na implementação física. - Evite palavras reservadas: Certifique-se de que nenhum nome de entidade ou coluna conflite com palavras reservadas específicas do banco de dados (por exemplo,
Pedido,Grupo,Índice). O uso de palavras reservadas frequentemente exige o uso de caracteres de escape, o que reduz a legibilidade do código. - Use sublinhados como separadores: Adote a convenção snake_case para colunas e tabelas (por exemplo,
perfil_usuario) para manter a legibilidade em diferentes motores de banco de dados. - Exclua abreviações: Evite abreviações, a menos que sejam amplamente compreendidas.
id_clienteé melhor quecid. A clareza deve sempre prevalecer sobre a brevidade.
2. Defina a Estratégia de Chave Primária 🔑
Toda tabela deve ter um identificador exclusivo para distinguir registros. A escolha da chave primária afeta o desempenho, indexação e relacionamentos de dados.
- Chaves fictícias vs. Chaves naturais: Decida se deve usar uma chave fictícia (um ID artificial, como um inteiro autoincrementado ou UUID) ou uma chave natural (dados que já existem, como um endereço de e-mail). As chaves fictícias são frequentemente preferidas por estabilidade, pois chaves naturais podem mudar ao longo do tempo.
- Implicações de indexação:As chaves primárias são automaticamente indexadas. Certifique-se de que o tipo de chave escolhido seja compacto. Chaves grandes (como strings longas) podem aumentar o tamanho dos índices e tornar mais lenta a operação de junção.
- Restrições de unicidade: Marque explicitamente a coluna da chave primária como
NÃO NULO. Uma chave primária não pode conter valores nulos em nenhuma circunstância. - Chaves compostas: Se uma tabela exigir uma chave primária composta (várias colunas), certifique-se de que todas as relações que referenciam essa tabela possam lidar com múltiplas colunas. Isso pode complicar as restrições de chave estrangeira.
3. Mapeie as relações de chave estrangeira 🔗
As relações definem como as entidades interagem. O mapeamento incorreto de relações leva à perda de dados e problemas de integridade referencial.
- Cardinalidade: Defina claramente se uma relação é de Um para Um, Um para Muitos ou Muitos para Muitos. A relação Um para Muitos é o padrão mais comum em bancos de dados relacionais.
- Resolução de Muitos para Muitos: Uma relação Muitos para Muitos exige uma tabela de junção (tabela de ligação). Certifique-se de que essa tabela inclua as chaves estrangeiras de ambas as entidades pais e, se necessário, seus próprios atributos.
- Ações referenciais: Especifique como o banco de dados deve lidar com atualizações ou exclusões. Opções comuns incluem
CASCADE(excluir registros filhos),DEFINIR NULO, ouRESTRIÇÃO(impedir exclusão). Escolha com base nos requisitos de lógica de negócios. - Referência própria: Se uma tabela se refere a si mesma (por exemplo, uma tabela de funcionários com uma coluna de gerente), identifique claramente essa relação para evitar confusão durante a revisão do esquema.
4. Aplicar regras de normalização de dados 🧹
A normalização reduz a redundância de dados e melhora a integridade. Embora sistemas modernos às vezes desnormalizem para desempenho, entender as formas é crucial.
| Forma Normal | Requisito | Benefício |
|---|---|---|
| 1FN (Primeira Forma Normal) | Valores atômicos, sem grupos repetidos | Garante que cada célula contenha um único valor |
| 2FN (Segunda Forma Normal) | Sem dependências parciais | Garante que colunas não-chave dependam da chave inteira |
| 3FN (Terceira Forma Normal) | Sem dependências transitivas | Garante que colunas não-chave dependam apenas da chave |
- Evite redundância: Se uma informação for armazenada em várias tabelas, ela deverá ser armazenada em um único local para evitar anomalias de atualização.
- Equilíbrio com desempenho: A normalização rigorosa pode levar a junções complexas. Documente quaisquer decisões intencionais de desnormalização feitas para fins de otimização de consultas.
- Verifique as dependências de dados: Garanta que as colunas dependam logicamente da chave primária e não de outras colunas não-chave.
5. Selecione tipos de dados apropriados 📏
Escolher o tipo de dado incorreto desperdiça espaço de armazenamento e pode levar a erros de cálculo.
- Precisão de inteiros: Use
TINYINTpara números pequenos (0-255) eBIGINTpara identificadores grandes. Não useINTpara tudo seSMALLINTfornece o suficiente. - Comprimentos de string: Evite usar genéricos
TEXTOouVARCHAR(MAX)a menos que necessário. Defina comprimentos específicos (por exemplo,VARCHAR(50)para um código de estado) para impor limites de dados e melhorar a eficiência de indexação. - Data e Hora: Use
TIMESTAMPouDATETIMEdependendo das exigências de fuso horário. Certifique-se de que o formato seja consistente (ISO 8601 é um padrão). Evite armazenar datas como strings. - Valores Booleanos: Use um tipo booleano nativo, se disponível. Caso contrário, use
TINYINT(1)ouCHAR(1). Evite armazenar valores booleanos como strings (“sim”/”não”).
6. Impor Restrições e Valores Padrão ⚖️
Restrições protegem a qualidade dos dados ao nível do banco de dados. Depender exclusivamente da validação em nível de aplicativo é arriscado.
- Não Nulo: Marque colunas críticas como
NÃO NULO. Isso evita que dados ausentes corrompam relatórios ou lógica. - Restrições Únicas: Aplique restrições únicas a colunas como endereços de e-mail ou nomes de usuário para evitar entradas duplicadas.
- Valores Padrão: Defina valores padrão razoáveis para colunas de status (por exemplo,
status = 'ativo') ou marcas de tempo para evitar erros de entrada manual. - Restrições de Verificação:Use restrições de verificação para validar regras de negócios (por exemplo,
idade > 18oupreço > 0). Isso garante que os dados sigam regras lógicas, independentemente da fonte.
7. Planeje a Estratégia de Indexação 🚀
Índices aceleram a recuperação de dados, mas retardam operações de escrita. É necessária uma abordagem equilibrada.
- Índices de Chave Estrangeira:Sempre indexe colunas de chave estrangeira. Isso é crítico para o desempenho das operações de junção entre tabelas.
- Colunas de Pesquisa:Identifique colunas frequentemente usadas em
WHERE,ORDER BY, ouGROUP BYcláusulas. Adicione índices a essas colunas. - Índices Compostos:Se as consultas filtrarem em múltiplas colunas, crie um índice composto. A ordem das colunas no índice é importante e deve corresponder aos padrões de consulta.
- Evite excesso de indexação:Muitos índices aumentam o uso de disco e retardam as operações de
INSERT,UPDATE, eDELETEoperações. Revise a necessidade de cada índice.
8. Inclua Campos de Auditoria 🕒
A rastreabilidade é vital para depuração e conformidade. Cada tabela que manipula lógica de negócios deve rastrear alterações.
- Criado em: Adicione uma
created_atcoluna para registrar quando um registro foi inserido pela primeira vez. - Atualizado em: Adicione uma
updated_atcoluna para registrar o horário da última modificação. - Exclusão suave: Em vez de exclusão definitiva, considere adicionar uma
deleted_atcoluna. Isso permite que os dados sejam restaurados se necessário e preserva a integridade referencial. - Quem alterou: Para rastreamentos críticos de auditoria, inclua uma
created_byeupdated_bycoluna para armazenar o ID do usuário responsável pela ação.
9. Aborde segurança e conformidade 🔒
A segurança de dados deve ser incorporada ao esquema, e não adicionada como um pensamento posterior.
- Tratamento de Dados Pessoais (PII): Identifique Informações Pessoais Identificáveis (PII), como números de seguro social, números de cartão de crédito ou registros médicos. Esses dados devem ser criptografados ou tokenizados.
- Classificação de Dados: Marque as colunas sensíveis na documentação do esquema para que os desenvolvedores saibam quais campos exigem medidas de segurança adicionais.
- Controle de Acesso: Embora permissões específicas geralmente sejam definidas no nível da aplicação ou do usuário do banco de dados, o esquema deve refletir a sensibilidade dos dados (por exemplo, tabelas separadas para dados públicos versus privados).
- Políticas de Retenção: Certifique-se de que o esquema suporte os requisitos de retenção de dados. Algumas jurisdições exigem a exclusão de dados após um determinado período.
10. Documente e valide o esquema 📄
Um esquema sem documentação é uma responsabilidade. A documentação garante a manutenibilidade futura.
- Dicionário de Dados:Mantenha um documento que descreva cada tabela, coluna e relacionamento. Inclua definições comerciais para cada campo.
- Comentários:Use comentários SQL nos scripts de DDL (Linguagem de Definição de Dados) para explicar lógicas complexas ou regras de negócios específicas.
- Revisão Visual:Gere o ERD visualmente para verificar referências circulares, tabelas órfãs ou relacionamentos ausentes.
- Revisão por Pares:Tenha outro arquiteto ou desenvolvedor sênior revisar o modelo. Um par de olhos novos frequentemente detecta erros lógicos que foram negligenciados durante o projeto inicial.
Erros Comuns de Modelagem e Soluções 🛠️
Revisar a lista de verificação não é suficiente. Você também deve estar ciente dos armadilhas comuns.
| Erro | Consequência | Correção |
|---|---|---|
| Chaves Estrangeiras Ausentes | Registros órfãos, inconsistência de dados | Adicione restrições de chave estrangeira explícitas |
| Tabelas Amplas | Difícil de ler, consultas lentas | Divida em tabelas relacionadas (Normalização) |
| Relacionamentos Implícitos | Confusão durante o desenvolvimento | Desenhe linhas explícitas no ERD, adicione colunas de FK |
| Problemas de Nulidade | Erros de lógica na aplicação | Defina NÃO NULO onde os dados são obrigatórios |
| IDs Codificados | Dificuldades de migração | Use chaves estrangeiras em vez de IDs codificados |
Pensamentos Finais sobre o Design de Esquema 🎯
Construir um modelo de banco de dados é um equilíbrio entre integridade rigorosa e desempenho prático. Seguir esta lista de verificação garante que sua estrutura de dados atenda às necessidades do negócio sem comprometer a qualidade. Dedique tempo para revisar cada etapa antes de confirmar o esquema no controle de versão. Algumas horas gastas validando o MDR podem poupar semanas de depuração e refatoração posterior.
Lembre-se de que um modelo de banco de dados é um documento vivo. À medida que os requisitos do negócio mudam, o esquema deve evoluir. Auditorias regulares com base nesta lista de verificação manterão sua arquitetura de dados saudável e alinhada aos seus objetivos. Priorize clareza, consistência e integridade em cada decisão que tomar.
Ao seguir esses dez passos, você estabelece uma base sólida para sua aplicação. Sua equipe apreciará a clareza, e seu ambiente de produção se beneficiará de erros reduzidos e melhor desempenho. Torne a lista de verificação um padrão em seu fluxo de desenvolvimento.