









Die Gestaltung eines robusten Datenmodells ist eine der wichtigsten Aufgaben im Softwareengineering. Ein Entity-Relationship-Diagramm (ERD) dient als Bauplan dafür, wie Informationen gespeichert, abgerufen und verwaltet werden. Im Zentrum dieses Bauplans steht die Normalisierung. Viele Praktiker betrachten die Normalisierung als starre Checkliste, die abgeschlossen werden muss, bevor mit der Implementierung begonnen wird. Tatsächlich ist die Realität jedoch viel nuancierter. Es besteht ein feiner Balanceakt zwischen Datenintegrität und Abfrageleistung, der ein tiefes Verständnis erfordert.
Diese Anleitung untersucht die technischen Realitäten der ERD-Normalisierung. Sie geht über die Lehrbuchdefinitionen hinaus und behandelt praktische Szenarien, in denen eine strikte Einhaltung der Regeln zu einem Nachteil wird. Unabhängig davon, ob Sie ein transaktionsbasiertes System oder eine analytische Plattform entwickeln, ist es entscheidend zu wissen, wann man bei der Normalisierung aufhören und wann man Redundanz einführen sollte, um langfristige Stabilität zu gewährleisten.
🔍 Verständnis der Grundprinzipien der relationalen Gestaltung
Die Normalisierung geht nicht nur darum, Daten zu organisieren; es geht vielmehr darum, Abhängigkeiten zu verwalten. In einem relationalen Modell muss jeder Spalte eine klare Beziehung zum Primärschlüssel ihrer Tabelle zugeordnet sein. Wenn diese Beziehung schwach oder indirekt ist, treten Anomalien auf. Diese Anomalien äußern sich in Dateninkonsistenzen, verschwendetem Speicherplatz und komplexer Aktualisierungslogik.
Die primären Ziele der Normalisierung umfassen:
- Datenintegrität: Sicherstellen, dass die Daten im gesamten System genau und konsistent bleiben.
- Speichereffizienz: Beseitigung redundanter Kopien desselben Datenmaterials.
- Skalierbarkeit: Gestaltung von Schemata, die Wachstum ohne strukturelle Neuschreibungen unterstützen können.
- Wartbarkeit: Reduzierung der Komplexität, die für die Aktualisierung von Informationen erforderlich ist.
Allerdings erfordert die Erreichung dieser Ziele oft einen Preis. Jeder Normalisierungsgrad erhöht typischerweise die Anzahl der Tabellen und die Komplexität der Abfragen, die erforderlich sind, um verbundene Daten abzurufen. Das Verständnis dieses Kompromisses ist der erste Schritt bei der effektiven Schema-Design.
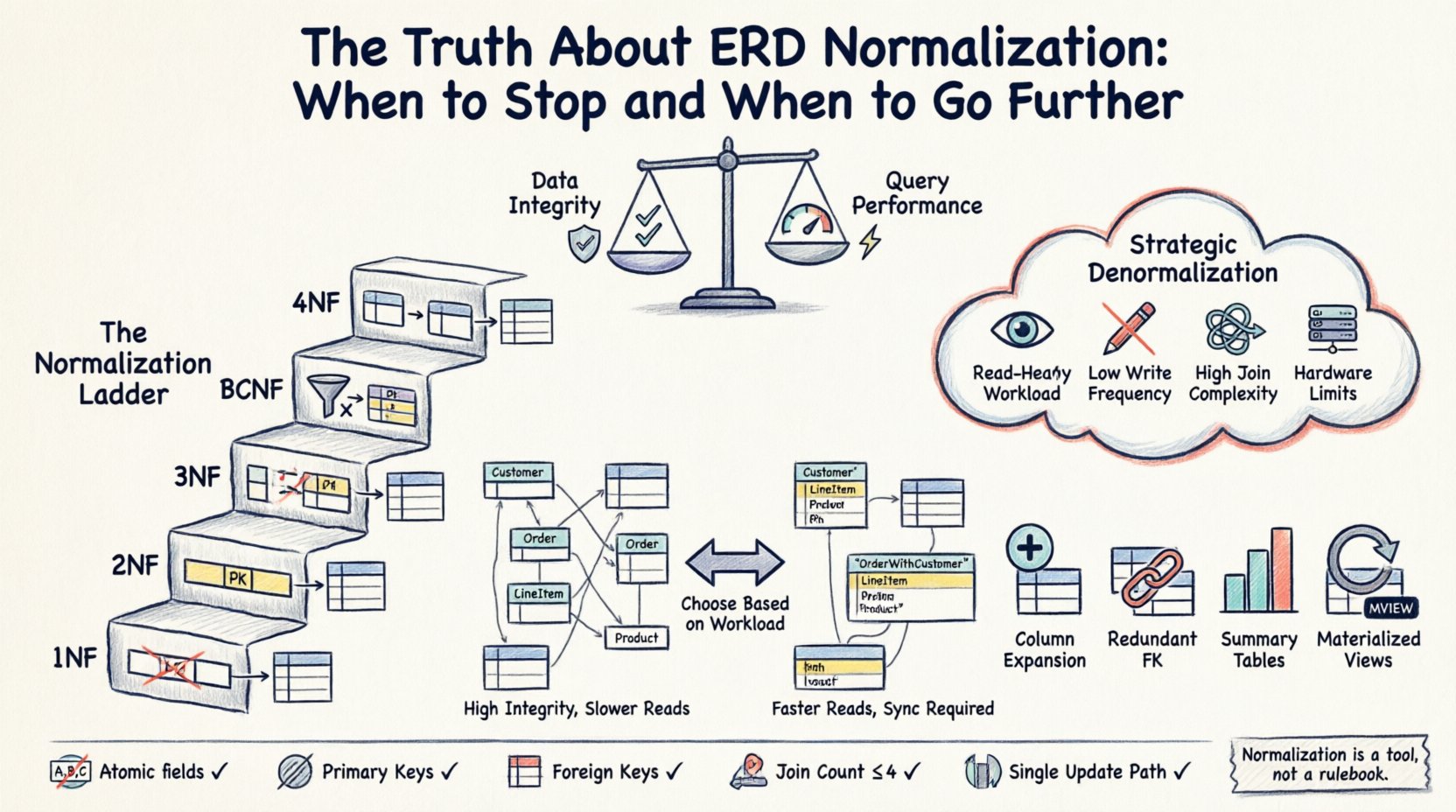
⚙️ Die drei Säulen der Standardnormalisierung (1NF, 2NF, 3NF)
Bevor man entscheidet, aufzuhören oder weiterzugehen, muss man die Grundlage verstehen. Die Standardformen bieten eine Stufenleiter der strukturellen Verbesserung.
Erste Normalform (1NF)
Die Grundlage jedes relationalen Datenbanksystems ist die 1NF. Eine Tabelle befindet sich in der 1NF, wenn sie folgende Kriterien erfüllt:
- Alle Spaltenwerte sind atomar (unteilbar).
- Jede Spalte enthält Werte eines einzigen Typs.
- Innerhalb einer Zeile gibt es keine sich wiederholenden Gruppen oder Arrays.
Zum Beispiel verstößt das Speichern einer Liste von Produktbezeichnungen in einer einzigen Spalte gegen die 1NF. Stattdessen sollte jedes Produkt eine eigene Zeile einnehmen. Obwohl moderne Systeme oft komplexe Datentypen verarbeiten können, sorgt die strikte Einhaltung der Atomarität dafür, dass Abfragen vorhersehbar bleiben und Indexstrategien wie vorgesehen funktionieren.
Zweite Normalform (2NF)
Sobald eine Tabelle in der 1NF ist, muss sie die Anforderungen der 2NF erfüllen. Diese Form gilt speziell für Tabellen mit zusammengesetzten Primärschlüsseln (Schlüssel aus mehreren Spalten). Eine Tabelle befindet sich in der 2NF, wenn:
- Sie bereits in der 1NF ist.
- Alle Nicht-Schlüssel-Attribute hängen vollständig vom gesamten Primärschlüssel ab, nicht nur von einem Teil davon.
Betrachten Sie eine Tabelle für Bestellpositionen, deren Schlüssel aus der Kombination von Bestell-ID und Produkt-ID besteht. Wenn Sie den Produktnamen in dieser Tabelle speichern, liegt eine partielle Abhängigkeit vor. Der Produktname hängt nur von der Produkt-ID ab, nicht von der Bestell-ID. Um dies zu beheben, verschieben Sie den Produktnamen in eine separate Tabelle „Produkte“. Dadurch werden Aktualisierungsanomalien reduziert; wenn sich ein Produktnamen ändert, wird er an einer einzigen Stelle aktualisiert, nicht über Tausende von Bestellpositionen hinweg.
Dritte Normalform (3NF)
Die 3NF gilt oft als ideale Balance für die meisten operativen Systeme. Eine Tabelle befindet sich in der 3NF, wenn:
- Es ist in 2NF.
- Es gibt keine transitiven Abhängigkeiten. Nicht-Schlüsselattribute dürfen sich nur auf den Primärschlüssel beziehen.
Eine transitive Abhängigkeit tritt auf, wenn Spalte A Spalte B bestimmt und Spalte B Spalte C bestimmt. In einer Datenbank führt die Bestimmung von Stadt durch Kunden-ID und die Bestimmung von Region durch Stadt dazu, dass die Region in der Kunden-Tabelle gespeichert wird und eine transitive Abhängigkeit entsteht. Wenn sich die Region für diese Stadt ändert, müssen Sie jede Kunden-Datei in dieser Stadt aktualisieren. Die Normalisierung dieses Zustands verschiebt die Regionsdaten an einen separaten Ort, wodurch sichergestellt wird, dass Aktualisierungen nur einmal erfolgen.
📉 Die Leistungskosten strenger Normalisierung
Während 3NF die Redundanz minimiert, maximiert es die Anzahl der Tabellen. In einem normalisierten Schema erfordert die Abfrage eines einzelnen logischen Datensatzes oft das Verknüpfen mehrerer Tabellen. Dieser Vorgang hat eine rechnerische Kosten.
- Join-Aufwand: Jeder Join-Vorgang erfordert, dass die Datenbankengine Zeilen aus verschiedenen Tabellen verknüpft. Je größer die Tabellen werden, desto mehr CPU- und Speicherressourcen verbraucht dieser Verknüpfungsprozess.
- I/O-Operationen: Daten, die über viele Tabellen verteilt sind, erfordern mehr Festplattenlesungen. Wenn die Daten nicht effizient im Cache gespeichert werden, steigt die Leseverzögerung.
- Komplexität: Komplexe Abfragen mit vielen Joins sind schwerer zu optimieren und zu pflegen. Sie sind außerdem anfälliger für Fehler, wenn sich das Schema ändert.
Für Systeme mit hohem Schreibvolumen ist die Normalisierung in der Regel die richtige Wahl. Sie verhindert Datenredundanz und stellt sicher, dass eine Aktualisierung eines einzelnen Fakts korrekt propagiert wird. Für Systeme mit hohem Lesevolumen können jedoch die Kosten für Joins zu einer Engstelle werden.
🚀 Strategische Denormalisierung: Wann man die Regeln brechen sollte
Die Denormalisierung ist die bewusste Einführung von Redundanz zur Optimierung der Leistung. Es ist kein Fehler; es ist eine bewusste architektonische Entscheidung, die getroffen wird, wenn die Kosten der Normalisierung ihre Vorteile übersteigen.
Auslöser für die Denormalisierung
Sie sollten die Normalisierungsregeln lockern, wenn:
- Lesevorgänge dominieren: Wenn Ihre Anwendung leseschwer ist (z. B. ein Berichts-Dashboard), kann die Reduzierung von Joins die Latenz erheblich senken.
- Die Abfragekomplexität ist hoch: Wenn Benutzer Daten aus 10 oder mehr Tabellen benötigen, um eine einzelne Seite anzuzeigen, wird die Abfrage langsam und schwer zu debuggen.
- Die Schreibhäufigkeit ist gering: Wenn die Daten selten aktualisiert werden, ist das Risiko von Inkonsistenzen durch Redundanz minimiert.
- Hardware-Beschränkungen bestehen: In Umgebungen, in denen die Festplatten-I/O teuer oder begrenzt ist, kann das Cachen redundanter Daten die physischen Lesevorgänge reduzieren.
Häufige Denormalisierungsstrategien
- Spalten-Erweiterung:Das Speichern eines abgeleiteten Werts direkt in einer Tabelle. Zum Beispiel das Hinzufügen einer Spalte „Gesamtpreis“ in einer Auftrags-Tabelle, der aus den Zeilenartikeln berechnet wird, sodass Sie sie bei jedem Lesen nicht summieren müssen.
- Redundante Fremdschlüssel: Hinzufügen einer Eltern-ID in einer Kind-Tabelle, um einen Join zu vermeiden, wenn die Hierarchie abgerufen wird.
- Zusammenfassungstabellen: Vorab-Berechnung von Aggregaten (Zählungen, Summen) in einer separaten Tabelle, die periodisch oder über Trigger aktualisiert wird.
- Materialisierte Ansichten: Speichern des Ergebnisses einer komplexen Abfrage als physische Tabelle, die nach einem Zeitplan aktualisiert wird.
📊 Vergleich: Normalisierung vs. Denormalisierung
Um die Kompromisse zu visualisieren, betrachten Sie die folgende Vergleichstabelle.
| Aspekt | Hohe Normalisierung (3NF+) | Denormalisiertes Design |
|---|---|---|
| Datenintegrität | Hoch – Einzige Quelle der Wahrheit | Niedriger – Erfordert Synchronisationslogik |
| Speicherplatznutzung | Effizient – Keine Duplikate | Ineffizient – Redundante Daten |
| Schreibleistung | Schnell – Einzelne Zeilenaktualisierung | Langsam – Aktualisierung mehrerer Zeilen |
| Lesepreformance | Langsam – Erfordert Joins | Schnell – Direkter Zugriff |
| Abfragekomplexität | Hoch – Viele Joins erforderlich | Niedrig – Einfache Abfragen |
| Wartungsaufwand | Niedrig – Einmalige Aktualisierung | Hoch – Synchronisation an mehreren Stellen |
Diese Tabelle zeigt, dass es keine universelle Bestpraxis gibt. Die Wahl hängt vollständig von der spezifischen Arbeitslast der Anwendung ab.
🛠️ Entscheidungsrahmen für die Schema-Design
Um das richtige Maß an Normalisierung für Ihr spezifisches Projekt zu bestimmen, verwenden Sie diesen Entscheidungsrahmen. Bewerten Sie jeden Punkt anhand Ihrer Projektanforderungen.
1. Analyse des Arbeitslastmusters
Ermitteln Sie das Verhältnis von Lese- zu Schreibvorgängen. Wenn Ihr System OLTP (Online-Transaktionsverarbeitung) ist, legen Sie den Fokus auf Integrität und 3NF. Wenn es sich um OLAP (Online-Analytische Verarbeitung) handelt, legen Sie den Fokus auf Lese-Geschwindigkeit und erwägen Sie die De-Normalisierung.
2. Beurteilen Sie die Anforderungen an die Datenaktualität
Müssen die Daten in Echtzeit vorliegen? Wenn Sie de-normalisieren, entsteht eine Verzögerung zwischen einer Quellaktualisierung und der entsprechenden Änderung in den redundanten Daten. Wenn Ihre Benutzer eine sofortige Konsistenz benötigen, ist eine strikte Normalisierung sicherer.
3. Beurteilen Sie die Häufigkeit von Aktualisierungen
Schauen Sie sich die Primärschlüssel an. Wenn eine Abfrage-Tabelle (wie eine Liste von Ländern) selten geändert wird, ist es sicher, ihre Daten in Transaktions-Tabellen zu de-normalisieren. Wenn eine Abfrage-Tabelle häufig geändert wird, halten Sie sie getrennt, um Synchronisationsfehler zu minimieren.
4. Berücksichtigen Sie Hardware und Caching
Moderne Datenbanken speichern Daten oft im Arbeitsspeicher. Wenn Ihr Arbeitsset in den RAM passt, sinkt die Kosten für Joins. In diesem Fall können Sie ein etwas stärker normalisiertes Schema verwenden, ohne die Leistung zu beeinträchtigen.
🧠 Fortgeschrittene Normalisierung: BCNF und 4NF
Über 3NF hinaus gibt es höhere Formen wie die Boyce-Codd-Normalform (BCNF) und die Vierte Normalform (4NF). Diese behandeln spezifische Sonderfälle.
Boyce-Codd-Normalform (BCNF)
BCNF ist eine strengere Version von 3NF. Sie behandelt Fälle, in denen ein nicht-primer Attribut einen anderen nicht-primer Attribut bestimmt, selbst wenn der Primärschlüssel zusammengesetzt ist. Obwohl sie theoretisch perfekt ist, kann BCNF manchmal zu einem Verlust der Abhängigkeitsbewahrung führen. In der Praxis reicht 3NF oft aus, und die Erzwingung von BCNF kann das Schema manchmal komplizierter machen, ohne signifikanten Nutzen zu bringen.
Vierte Normalform (4NF)
4NF befasst sich mit mehrwertigen Abhängigkeiten. Dies tritt auf, wenn eine einzelne Zeile mehrere unabhängige Werteliste enthält. Zum Beispiel eine Schüler-Tabelle, die in derselben Zeile mehrere Hobbys und mehrere Klassen speichert. Dies ist in Standardgeschäftsanwendungen selten, kommt aber in spezialisierten Datenmodellierungs-Szenarien häufig vor.
🚫 Häufige Fehler, die Sie vermeiden sollten
Selbst mit einem fundierten Verständnis der Normalisierung ist es leicht, Fehler zu machen. Vermeiden Sie diese häufigen Fehler:
- Über-Normalisierung:Erstellen von Hunderten kleiner Tabellen für einfache Beziehungen. Dies macht die Anwendungslogik schwer nachzuvollziehen und verlangsamt die Entwicklung.
- Ignorieren von Indizes:Ein normalisiertes Schema erfordert Joins. Wenn die Join-Spalten nicht indiziert sind, verschlechtert sich die Leistung unabhängig von der Schema-Design.
- De-Normalisieren ohne Überwachung:Die Einführung von Redundanz ohne Plan zur Synchronisierung führt im Laufe der Zeit zu Datenkorruption.
- Logik hartcodieren:Berechnen Sie abgeleitete Werte nicht in der Anwendungsschicht, wenn sie in der Datenbank gehören sollten. Halten Sie Geschäftsregeln nahe an den Daten.
✅ Prüfliste zur Schema-Validierung
Führen Sie das neue Schema vor der Bereitstellung durch diese Prüfliste.
- Atomarität:Sind alle Felder atomar?
- Primärschlüssel:Hat jede Tabelle einen eindeutigen Primärschlüssel?
- Fremdschlüssel:Werden Beziehungen über Fremdschlüssel durchgesetzt?
- Redundanz:Gibt es offensichtliche wiederholte Datengruppen?
- Anzahl der Joins:Erfordern kritische Abfragen mehr als 3-4 Joins?
- Aktualisierungspfad:Kann eine einzelne Dateneingabe an einer Stelle vorgenommen werden?
🔗 Schlussfolgerung zur Datenarchitektur
Normalisierung ist ein Werkzeug, kein Regelbuch. Sie dient dazu, Ihre Daten vor Inkonsistenzen zu schützen, sollte aber nicht verhindern, dass Ihre Anwendung effizient arbeitet. Die „Wahrheit“ über die ERD-Normalisierung ist, dass es ein Spektrum ist. Sie beginnen mit einer stark normalisierten Struktur, um die Integrität zu gewährleisten, und denormalisieren gezielt aufgrund von Leistungsanforderungen.
Es gibt keine allgemeingültige Lösung. Ein Hochfrequenzhandelssystem wird sich stark von einem Content-Management-System unterscheiden. Entscheidend ist das Verständnis der zugrundeliegenden Mechanismen von Abhängigkeiten und Joins. Indem Sie die Kosten für Speicherplatz und die Kosten für Berechnungen ausbalancieren, können Sie Systeme bauen, die sowohl zuverlässig als auch schnell sind.
Wenn Sie weiterhin entwerfen, denken Sie daran, dass eine Schema-Evolution unvermeidlich ist. Planen Sie Änderungen. Verwenden Sie Versionierung für Ihre Datenbank-Migrationen. Testen Sie Ihre Abfragen immer unter Last, bevor Sie sich für eine strukturelle Entscheidung entscheiden. Das beste Schema ist das, das Ihre Geschäftsziele unterstützt, ohne zur Engstelle zu werden.