









Diseñar un modelo de datos robusto es una de las tareas más críticas en la ingeniería de software. Un diagrama de entidades y relaciones (ERD) sirve como plano maestro para cómo se almacena, recupera y mantiene la información. En el corazón de este plano está la normalización. Muchos profesionales abordan la normalización como una lista rígida de verificación que debe completarse antes de pasar a la implementación. Sin embargo, la realidad es mucho más matizada. Existe un equilibrio delicado entre la integridad de los datos y el rendimiento de las consultas, que requiere una comprensión profunda.
Esta guía explora las realidades técnicas de la normalización de ERD. Va más allá de las definiciones de los libros de texto para abordar escenarios prácticos en los que el cumplimiento estricto de las reglas se convierte en una carga. Ya sea que esté construyendo un sistema transaccional o una plataforma analítica, saber cuándo detener la normalización y cuándo introducir redundancia es esencial para la estabilidad a largo plazo.
🔍 Comprender los principios fundamentales del diseño relacional
La normalización no se trata únicamente de organizar datos; se trata de gestionar dependencias. En un modelo relacional, cada columna debe tener una relación clara con la clave primaria de su tabla. Cuando esta relación es débil o indirecta, ocurren anomalías. Estas anomalías se manifiestan como inconsistencias de datos, almacenamiento desperdiciado y lógica de actualización compleja.
Los objetivos principales de la normalización incluyen:
- Integridad de los datos:Garantizar que los datos permanezcan precisos y consistentes en todo el sistema.
- Eficiencia de almacenamiento:Eliminar copias redundantes de los mismos datos.
- Escalabilidad:Diseñar esquemas que puedan acomodar el crecimiento sin reescrituras estructurales.
- Mantenibilidad:Reducir la complejidad necesaria para actualizar la información.
Sin embargo, alcanzar estos objetivos a menudo conlleva un costo. Cada nivel de normalización aumenta típicamente el número de tablas y la complejidad de las consultas necesarias para recuperar datos unidos. Comprender esta compensación es el primer paso en el diseño eficaz de esquemas.
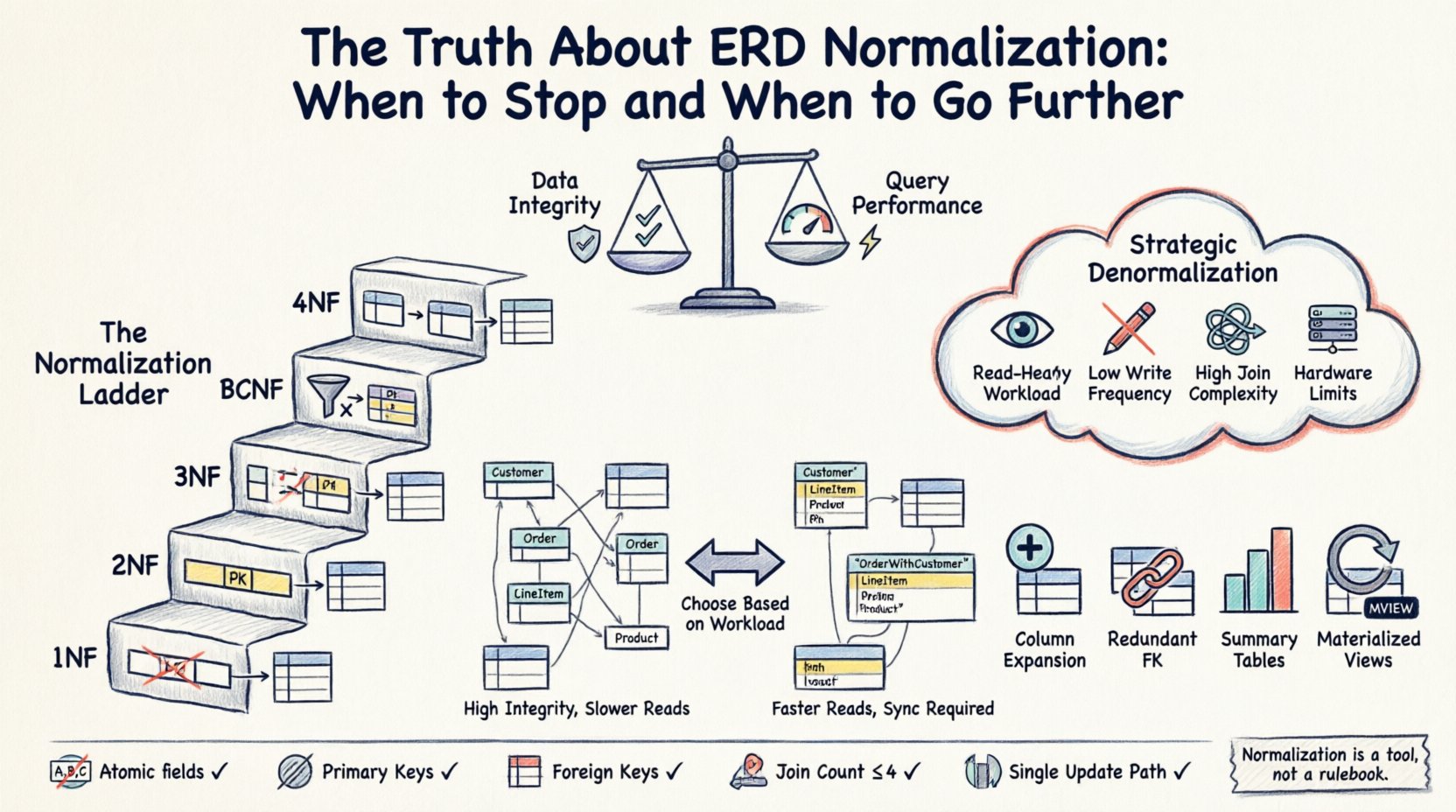
⚙️ Las tres columnas fundamentales de la normalización estándar (1FN, 2FN, 3FN)
Antes de decidir detenerse o seguir adelante, uno debe comprender la base. Las formas estándar proporcionan una escalera de refinamiento estructural.
Primera Forma Normal (1FN)
La base de cualquier base de datos relacional es la 1FN. Una tabla está en 1FN si cumple con los siguientes criterios:
- Todos los valores de las columnas son atómicos (indivisibles).
- Cada columna contiene valores de un solo tipo.
- No hay grupos repetidos ni arreglos dentro de una fila.
Por ejemplo, almacenar una lista de nombres de productos en una sola columna viola la 1FN. En su lugar, cada producto debería ocupar su propia fila. Aunque los sistemas modernos manejan con frecuencia tipos de datos complejos, el cumplimiento estricto de la atomicidad garantiza que las consultas permanezcan predecibles y que las estrategias de indexación funcionen según lo previsto.
Segunda Forma Normal (2FN)
Una vez que una tabla está en 1FN, debe cumplir con los requisitos de 2FN. Esta forma se aplica específicamente a tablas con claves primarias compuestas (claves formadas por múltiples columnas). Una tabla está en 2FN si:
- Ya está en 1FN.
- Todos los atributos no clave dependen completamente de toda la clave primaria, y no solo de parte de ella.
Considere una tabla de detalles de pedidos donde la clave es una combinación de ID de pedido e ID de producto. Si almacena el nombre del producto en esta tabla, tiene una dependencia parcial. El nombre del producto depende únicamente del ID de producto, no del ID de pedido. Para corregir esto, mueva el nombre del producto a una tabla separada de Productos. Esto reduce las anomalías de actualización; si cambia el nombre de un producto, lo actualiza en un solo lugar, no en miles de registros de pedidos.
Tercera Forma Normal (3FN)
La 3FN a menudo se considera el punto óptimo para la mayoría de los sistemas operativos. Una tabla está en 3FN si:
- Está en 2NF.
- No hay dependencias transitivas. Los atributos no clave deben depender únicamente de la clave primaria.
Una dependencia transitiva ocurre cuando la Columna A determina la Columna B, y la Columna B determina la Columna C. En una base de datos, si el ID de Cliente determina la Ciudad, y la Ciudad determina la Región, almacenar la Región en la tabla de Clientes crea una dependencia transitiva. Si la Región cambia para esa Ciudad, debe actualizarse cada registro de cliente en esa ciudad. Normalizar esto elimina la dependencia, moviendo los datos de Región a una ubicación separada, asegurando que las actualizaciones ocurran solo una vez.
📉 El costo de rendimiento de la normalización estricta
Mientras que la 3FN minimiza la redundancia, maximiza el número de tablas. En un esquema normalizado, recuperar un solo registro lógico a menudo requiere unir múltiples tablas. Este proceso tiene un costo computacional.
- Sobrecarga de unión:Cada operación de unión requiere que el motor de base de datos coincida filas de diferentes tablas. A medida que las tablas crecen, este proceso de coincidencia consume CPU y memoria.
- Operaciones de E/S:Los datos distribuidos en muchas tablas requieren más lecturas de disco. Si los datos no se almacenan eficientemente en caché, aumenta la latencia de lectura.
- Complejidad:Las consultas complejas con muchas uniones son más difíciles de optimizar y mantener. También son más propensas a fallar si cambia el esquema.
Para sistemas con cargas de escritura intensas, la normalización suele ser la opción correcta. Evita la duplicación de datos y asegura que una actualización de un hecho único se propague correctamente. Sin embargo, para sistemas con cargas de lectura intensas, el costo de las uniones puede convertirse en un cuello de botella.
🚀 Denormalización estratégica: cuándo romper las reglas
La denormalización es la introducción intencional de redundancia para optimizar el rendimiento. No es un error; es una decisión arquitectónica deliberada tomada cuando el costo de la normalización supera sus beneficios.
Gatillos para la denormalización
Debería considerar relajar las reglas de normalización cuando:
- Las operaciones de lectura dominan:Si su aplicación es intensiva en lecturas (por ejemplo, un panel de informes), reducir las uniones puede reducir significativamente la latencia.
- La complejidad de la consulta es alta:Si los usuarios requieren datos de 10 o más tablas para ver una sola página, la consulta se vuelve lenta y difícil de depurar.
- La frecuencia de escritura es baja:Si los datos rara vez se actualizan, el riesgo de inconsistencia derivado de la redundancia se minimiza.
- Existen restricciones de hardware:En entornos donde la E/S de disco es costosa o limitada, almacenar en caché datos redundantes puede reducir las lecturas físicas.
Estrategias comunes de denormalización
- Expansión de columnas:Almacenar un valor derivado directamente en una tabla. Por ejemplo, agregar una columna «Precio Total» a una tabla de Pedidos, calculada a partir de los artículos, para que no tenga que sumarlos en cada lectura.
- Claves foráneas redundantes:Agregar un ID de Padre a una tabla de Hijos para evitar una unión al recuperar la jerarquía.
- Tablas de resumen: Pre-calculo de agregados (conteos, sumas) en una tabla separada que se actualiza periódicamente o mediante desencadenadores.
- Vistas materializadas:Almacenar el resultado de una consulta compleja como una tabla física que se actualiza según un horario.
📊 Comparación: Normalización frente a Denormalización
Para visualizar las compensaciones, considere la siguiente tabla de comparación.
| Aspecto | Alta normalización (3FN+) | Diseño denormalizado |
|---|---|---|
| Integridad de los datos | Alta – Fuente única de verdad | Más baja – Requiere lógica de sincronización |
| Uso de almacenamiento | Eficiente – Sin duplicados | Ineficiente – Datos redundantes |
| Rendimiento de escritura | Rápido – Actualización de una sola fila | Más lento – Actualización de múltiples filas |
| Rendimiento de lectura | Más lento – Requiere uniones | Rápido – Acceso directo |
| Complejidad de la consulta | Alta – Se necesitan muchas uniones | Baja – Consultas simples |
| Esfuerzo de mantenimiento | Bajo – Actualizar una vez | Alto – Sincronizar múltiples lugares |
Esta tabla destaca que no existe una práctica óptima universal. La elección depende completamente de la carga de trabajo específica de la aplicación.
🛠️ Marco de decisión para el diseño de esquemas
Para determinar el nivel adecuado de normalización para su proyecto específico, utilice este marco de decisión. Evalúe cada punto según los requisitos de su proyecto.
1. Analice el patrón de carga de trabajo
Identifique la proporción de lecturas frente a escrituras. Si su sistema es OLTP (procesamiento de transacciones en línea), priorice la integridad y la 3FN. Si es OLAP (procesamiento analítico en línea), priorice la velocidad de lectura y considere la denormalización.
2. Evalúe los requisitos de actualidad de los datos
¿Necesitan los datos ser en tiempo real? Si denormaliza, introduce un retraso entre una actualización de origen y el cambio reflejado en los datos redundantes. Si sus usuarios necesitan consistencia inmediata, la normalización estricta es más segura.
3. Evalúe la frecuencia de actualización
Revise las claves primarias. Si una tabla de búsqueda (como una lista de países) cambia raramente, denormalizar sus datos en tablas transaccionales es seguro. Si una tabla de búsqueda cambia con frecuencia, manténgala separada para minimizar los errores de sincronización.
4. Considere el hardware y la caché
Las bases de datos modernas suelen almacenar datos en caché en memoria. Si su conjunto de trabajo cabe en la RAM, el costo de las uniones disminuye. En este caso, puede permitirse un esquema ligeramente más normalizado sin sacrificar el rendimiento.
🧠 Normalización avanzada: BCNF y 4NF
Más allá de la 3FN, existen formas superiores como la Forma Normal de Boyce-Codd (BCNF) y la Cuarta Forma Normal (4NF). Estas abordan casos especiales específicos.
Forma Normal de Boyce-Codd (BCNF)
La BCNF es una versión más estricta de la 3FN. Maneja casos en los que un atributo no primo determina otro atributo no primo, incluso si la clave primaria es compuesta. Aunque teóricamente perfecta, la BCNF a veces puede provocar una pérdida de preservación de dependencias. En la práctica, la 3FN suele ser suficiente, y obligar a la BCNF a veces puede complicar el esquema sin añadir un valor significativo.
Cuarta Forma Normal (4NF)
La 4NF trata con dependencias multivaluadas. Esto ocurre cuando una sola fila contiene múltiples listas independientes de valores. Por ejemplo, una tabla de estudiantes que almacena múltiples aficiones y múltiples clases en la misma fila. Esto es raro en aplicaciones empresariales estándar, pero común en escenarios especializados de modelado de datos.
🚫 Errores comunes que deben evitarse
Aunque se tenga una comprensión sólida de la normalización, es fácil cometer errores. Evite estos errores comunes:
- Sobrenormalización: Crear cientos de tablas pequeñas para relaciones simples. Esto hace que la lógica de la aplicación sea difícil de seguir y ralentiza el desarrollo.
- Ignorar índices: Un esquema normalizado requiere uniones. Si las columnas de unión no están indexadas, el rendimiento se degradará independientemente del diseño del esquema.
- Denormalizar sin supervisión: Introducir redundancia sin un plan para mantenerla sincronizada conduce con el tiempo a la corrupción de datos.
- Codificar lógica directamente: No calcule valores derivados en la capa de aplicación si deberían estar en la base de datos. Mantenga las reglas de negocio cerca de los datos.
✅ Lista de verificación para la validación del esquema
Antes de implementar un nuevo esquema, páselo por esta lista de verificación de validación.
- Atomicidad: ¿Todos los campos son atómicos?
- Claves primarias: ¿Toda tabla tiene una clave primaria única?
- Claves foráneas:¿Se imponen las relaciones mediante claves foráneas?
- Redundancia:¿Hay grupos obvios de datos repetidos?
- Número de combinaciones:¿Requieren las consultas críticas más de 3-4 combinaciones?
- Ruta de actualización:¿Se puede realizar un cambio de datos en un solo lugar?
🔗 Conclusión sobre la arquitectura de datos
La normalización es una herramienta, no un manual de reglas. Existe para proteger sus datos de inconsistencias, pero no debería impedir que su aplicación funcione de manera eficiente. La «verdad» sobre la normalización de ERD es que es un espectro. Comienza con una estructura altamente normalizada para garantizar la integridad, y luego desnormaliza selectivamente según las necesidades de rendimiento.
No existe una solución única para todos los casos. Un sistema de trading de alta frecuencia se verá muy diferente de un sistema de gestión de contenidos. La clave está en comprender los mecanismos subyacentes de dependencias y combinaciones. Al equilibrar el costo del almacenamiento frente al costo de cálculo, puedes construir sistemas que sean tanto confiables como rápidos.
Al continuar diseñando, recuerda que la evolución del esquema es inevitable. Planifica los cambios. Usa versionado para tus migraciones de base de datos. Y prueba siempre tus consultas bajo carga antes de tomar una decisión estructural. El mejor esquema es aquel que apoya tus objetivos comerciales sin convertirse en un cuello de botella.