











Jede Anwendung beginnt mit einer Idee. Diese Idee erfordert Datenspeicherung, und diese Speicherung erfordert eine Bauplanung. Dieser Bauplan ist das Entitäts-Beziehungs-Diagramm (ERD). Es ist das grundlegende Dokument, das bestimmt, wie Ihr System Informationen versteht. Doch ein Bauplan für eine kleine Hütte funktioniert nicht für ein Hochhaus. Ebenso scheitert ein Datenbank-Schema, das für eine Prototypenphase konzipiert wurde, oft unter der Last von Produktionsverkehr und komplexer Geschäftslogik.
Das Verständnis der ERD-Evolution ist für technische Leiter, Datenbankadministratoren und Softwarearchitekten entscheidend. Es beinhaltet das Bewältigen des Spannungsverhältnisses zwischen Flexibilität und Integrität. Wenn sich Ihre Nutzerbasis ausweitet, ändern sich Ihre Datenanforderungen. Sie können das ursprüngliche Modell nicht für immer beibehalten. Sie müssen es anpassen. Dieser Leitfaden untersucht den Lebenszyklus eines Datenmodells, von der ersten Codezeile bis hin zur Unternehmensarchitektur.
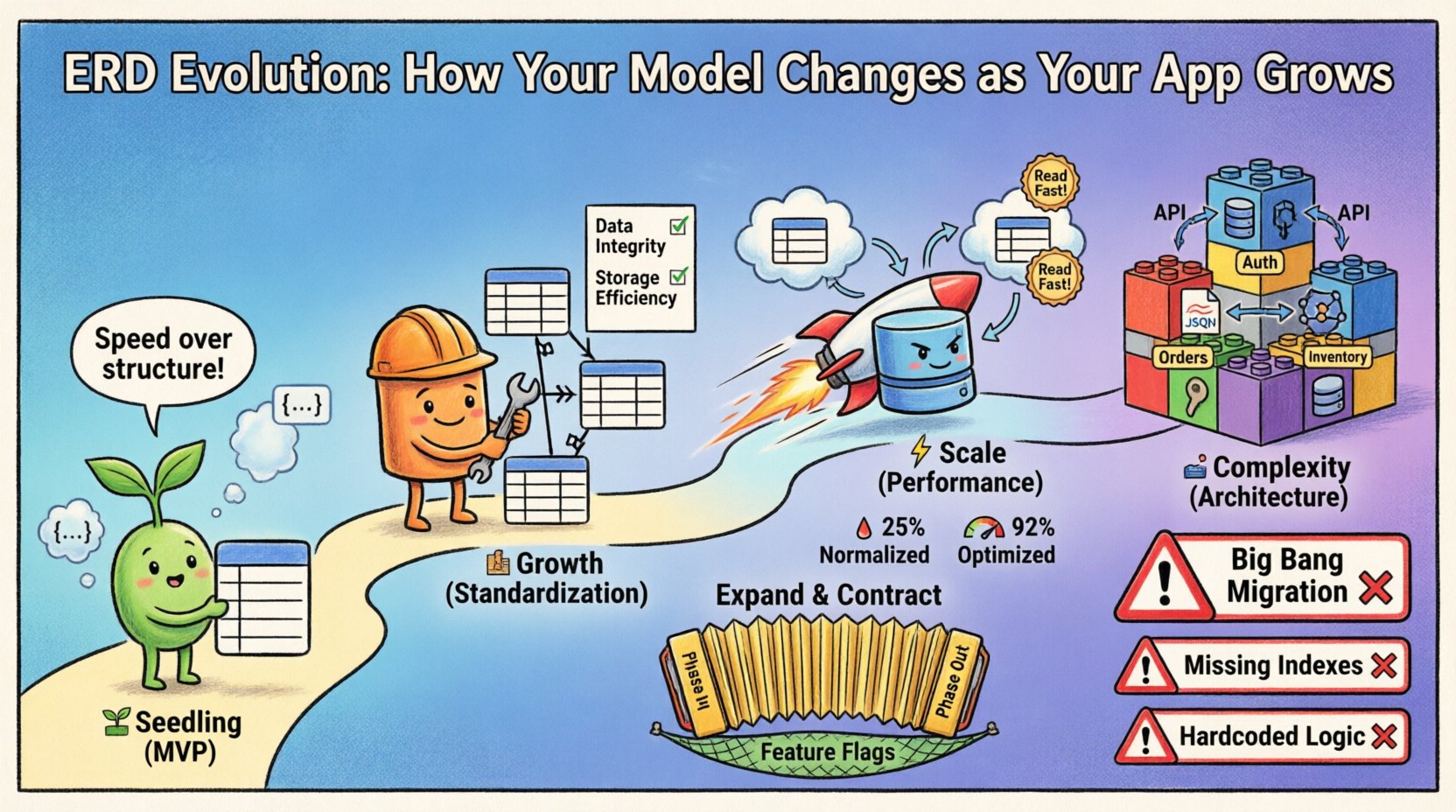
Phase 1: Die Keimphase (MVP) 🌱
Zu Beginn ist Geschwindigkeit die primäre Metrik. Ziel ist es, die zentrale Hypothese mit minimalem Aufwand zu validieren. In dieser Phase ist das ERD oft fließend und spiegelt unmittelbare Bedürfnisse wider, statt langfristige Vorhersagen.
- Schwerpunkt:Funktionalität vor Struktur.
- Struktur:Flache Schemata sind üblich. Beziehungen sind oft nicht normalisiert, um die Komplexität von Joins zu reduzieren.
- Einschränkungen:Fremdschlüssel können lose gehalten oder weggelassen werden, um eine schnelle Iteration zu ermöglichen.
- Änderungen:Schema-Änderungen finden wöchentlich, manchmal täglich statt.
In dieser Phase können Sie Entitäten sehen, die eng miteinander verknüpft sind. Zum Beispiel enthält eine BenutzerTabelle möglicherweise ein JSON-Blob mit Profil-Einstellungen, anstatt eine separate ProfilTabelle. Dies reduziert die Notwendigkeit von Joins und beschleunigt Leseoperationen für das Dashboard. Allerdings entsteht dadurch technische Schuld. Wenn die Anwendung reift, wird das Abfragen dieser verschachtelten Daten langsamer und schwerer zu pflegen.
Wichtige Merkmale von Modellen der frühen Phase
- Minimale Fremdschlüsselbeschränkungen.
- Flexible Spaltentypen (z. B. Verwendung von VARCHAR für alles).
- Einzelne Datenbankinstanz.
- Direkte Abbildung zwischen Anwendungsobjekten und Datenbanktabellen.
Phase 2: Die Wachstumsphase (Standardisierung) 🏗️
Sobald das Produkt an Bedeutung gewinnt, wird die ursprüngliche Flexibilität zur Belastung. Daten-Duplikation führt zu Inkonsistenzen. Wenn ein Benutzer seine E-Mail-Adresse an einer Stelle aktualisiert, aber nicht an einer anderen, bricht das System das Vertrauen. Dies ist die Phase, in der Normalisierung Vorrang hat.
Warum jetzt normalisieren?
- Datenintegrität:Die Durchsetzung der Referenzintegrität verhindert verwaiste Datensätze.
- Speichereffizienz:Das Entfernen redundanter Daten spart Speicherplatz.
- Wartbarkeit:Die Aktualisierung eines einzelnen Datensatzes in einer normalisierten Tabelle aktualisiert ihn logisch überall.
- Abfragevorhersagbarkeit:Standardisierte Strukturen machen das Schreiben von Abfragen weniger fehleranfällig.
Während dieser Übergangsphase müssen Sie das ERD überarbeiten. Eine flache Benutzertabelle könnte in Benutzer und Benutzerdetails. Dies führt zu Beziehungen ein. Sie müssen definieren, ob es sich um ein-zu-eins-, ein-zu-viele- oder viele-zu-viele-Beziehungen handelt.
Übergangs-Checkliste
- Identifizieren Sie alle doppelten Felder über alle Tabellen hinweg.
- Definieren Sie Primärschlüssel für alle Entitäten.
- Implementieren Sie Fremdschlüsselbeschränkungen, um Beziehungen durchzusetzen.
- Überprüfen Sie bestehende Abfragen auf Leistungseinbußen durch neue Joins.
- Planen Sie die Abwärtskompatibilität während der Migration.
Phase 3: Die Skalierungsphase (Leistung) ⚡
Wenn Millionen von Datensätzen existieren, kann die normalisierte Struktur zu einer Engstelle werden. Joins sind bei großer Skalierung rechnerisch kostspielig. Hier entwickelt sich das Modell erneut, oft weg von strenger Normalisierung hin zu strategischer De-Normalisierung zur Leistungssteigerung.
Strategische De-Normalisierung
Dies ist keine Rückkehr zur MVP-Phase. Es ist eine bewusste Entscheidung. Sie duplizieren Daten absichtlich, um kostspielige Joins bei großen Tabellen zu vermeiden.
- Leseintensive Workloads: Wenn Ihre Anwendung hauptsächlich Lesevorgänge ausführt, reduziert das Cachen von Daten in der Schema-Struktur die Datenbanklast.
- Berichtstabellen:Voraggregierte Daten für Dashboards vermeiden das On-the-fly-Berechnen von Summen.
- Partitionierung: Die Aufteilung von Tabellen nach Datum oder Region erfordert eine spezifische Schema-Design, um eine effiziente Abfrage zu ermöglichen.
Vergleich: Normalisiert vs. Optimiert
| Funktion | Normalisiert (Phase 2) | Optimiert (Phase 3) |
|---|---|---|
| Integrität | Hoch (Durch die DB erzwungen) | Verwaltet durch Anwendungslogik |
| Schreibgeschwindigkeit | Schnell | Langsam (Aktualisiert mehrere Tabellen) |
| Lesegeschwindigkeit | Langsam (Erfordert Joins) | Schnell (Einzelabfrage) |
| Speicherung | Effizient | Weniger effizient (Redundanz) |
Phase 4: Die Komplexitätsphase (Architektur) 🏛️
Auf Unternehmensebene ist ein einzelnes Datenbankmodell oft nicht ausreichend. Das System kann sich in Mikrodienste aufteilen oder polyglotte Persistenz nutzen. Das ERD stellt nun nicht mehr ein einzelnes physisches Diagramm dar, sondern eine Sammlung von Modellen, die miteinander kommunizieren.
Mikrodienste und Datenbesitz
Bei einer monolithischen Architektur ist die BestellungenTabelle wird von den Abrechnungs-, Versand- und Benachrichtigungsdiensten gemeinsam genutzt. In einem verteilten System besitzt jeder Dienst seine eigenen Daten. Dies erfordert eine Änderung der Art und Weise, wie Sie Beziehungen modellieren.
- Eventuelle Konsistenz:Sie können sich nicht auf ACID-Transaktionen über Dienste hinweg verlassen. Das ERD muss die Zustandsabstimmung berücksichtigen.
- API-Verträge:Beziehungen werden oft durch API-Antworten definiert, anstatt durch Fremdschlüssel.
- Datenabstimmung:Tools sind erforderlich, um die Datenkonsistenz über verschiedene Speicherorte hinweg aufrechtzuerhalten (z. B. SQL für Bestellungen, NoSQL für Protokolle).
Polyglotte Persistenz
Verschiedene Daten erfordern unterschiedliche Speicher-Engines. Das ERD entwickelt sich weiter, um nicht-relationale Konzepte einzuschließen.
- Graphdaten: Für soziale Netzwerke oder Empfehlungssysteme ersetzt ein Graphmodell relationale Tabellen.
- Dokumentenspeicher: Für flexible Inhalte wie Produktkataloge ersetzen JSON-Dokumente starre Spalten.
- Schlüssel-Wert-Speicher: Für die Sitzungsverwaltung und das Caching werden einfache Schlüssel-Wert-Paare anstelle komplexer Zeilen verwendet.
Technischer Tiefenblick: Normalisierungsstufen 🔬
Um Ihr Modell effektiv weiterzuentwickeln, müssen Sie die Regeln verstehen, die Sie befolgen oder brechen. Normalisierung ist der Prozess der Organisation von Daten, um Redundanz zu reduzieren.
Erste Normalform (1NF)
- Atomare Werte: Jede Spalte enthält nur einen Wert.
- Keine wiederholenden Gruppen: Sie können keine Spalten wie
Farbe1,Farbe2,Farbe3. - Eindeutige Identifikatoren: Jede Zeile muss eindeutig identifizierbar sein.
Zweite Normalform (2NF)
- Muss in 1NF sein.
- Alle nicht-schlüsselbasierten Attribute müssen vollständig vom Primärschlüssel abhängen.
- Beseitigt partielle Abhängigkeiten (z. B. Verschieben von Lieferanteninformationen in eine separate Tabelle, wenn sie nur vom Lieferanten-ID, nicht von der Bestell-ID abhängt).
Dritte Normalform (3NF)
- Muss in 2NF sein.
- Transitive Abhängigkeiten werden beseitigt.
- Eine Spalte darf nicht von einer anderen nicht-schlüsselbasierten Spalte abhängen (z. B.
Stadthängt ab vonBundesland, nicht nurPostleitzahl). Verschieben SieStadtundBundeslandzu einerStandortTabelle.
Häufige Fehler bei der ERD-Evolution ⚠️
Sogar erfahrene Teams begehen Fehler beim Refactoring von Modellen. Das Erkennen dieser Muster hilft, kostspielige Ausfallzeiten zu vermeiden.
1. Die „Big Bang“-Migration
Versuch, die gesamte Schema in einer einzigen Bereitstellung zu ändern. Dies birgt ein hohes Risiko. Wenn das Migrations-Skript fehlschlägt, ist das System defekt.
- Lösung: Verwenden Sie schrittweise Migrationen. Fügen Sie Spalten hinzu, füllen Sie Daten auf, wechseln Sie die Logik und entfernen Sie dann die alten Spalten.
2. Ignorieren der Auswirkungen der Indizierung
Die Änderung von Beziehungen verändert die Abfragemuster. Eine neue Fremdschlüsselbeziehung könnte möglicherweise einen neuen Index erfordern, um gut zu performen.
- Lösung: Analysieren Sie die langsamen Abfrage-Logs vor und nach Schemaänderungen.
- Lösung: Planen Sie die Indexerstellung während der Ruhezeiten.
3. Fixieren von Einschränkungen in der Anwendungslogik
Einige Teams bevorzugen die Datenüberprüfung im Code statt in der Datenbank. Dies führt zu Datenkorruption, wenn mehrere Dienste in denselben Speicher schreiben.
- Lösung: Behalten Sie Einschränkungen in der Datenbankebene (NOT NULL, CHECK-Einschränkungen) bei, auch wenn die Anwendung verteilt ist.
Migrationsstrategien 🔄
Wenn Sie die ERD evolvieren müssen, benötigen Sie eine Strategie, die Ausfallzeiten und Datenverlust minimiert.
Expandieren-und-Verkleinern-Muster
Dies ist der Goldstandard für sichere Schema-Evolution.
- Hinzufügen: Fügen Sie die neue Spalte oder Tabelle zum Schema hinzu. Ändern Sie die bestehende Logik noch nicht.
- Schreiben: Aktualisieren Sie die Anwendung, um in beide Strukturen (alte und neue) zu schreiben.
- Lesen: Aktualisieren Sie die Anwendung, um aus der neuen Struktur zu lesen.
- Nachfüllen: Führen Sie einen Hintergrundauftrag aus, um die neue Struktur mit alten Daten zu füllen.
- Vertrag: Sobald die Überprüfung abgeschlossen ist, entfernen Sie die alten Spalten und die Logik.
Feature-Flags
Verwenden Sie Feature-Flags, um zwischen dem alten Schema und dem neuen Schema zu wechseln. Dadurch können Sie sofort rückgängig machen, falls Probleme auftreten, ohne einen Rollback-Skript bereitstellen zu müssen.
Dokumentation und Versionsverwaltung 📝
Ein ERD ist kein einmaliger Liefergegenstand. Es ist ein lebendiges Dokument. Während sich das Modell weiterentwickelt, muss auch die Dokumentation Schritt halten.
Versionskontrolle für Schemas
- Behandeln Sie Schema-Dateien (SQL-Skripte) wie Code. Speichern Sie sie in Ihrem Versionskontrollsystem.
- Verwenden Sie Migrationswerkzeuge, um Änderungen im Laufe der Zeit zu verfolgen.
- Markieren Sie Releases mit Schema-Versionen (z. B.
v1.2.0-schema).
Visuelle Konsistenz
- Standardisieren Sie Namenskonventionen (z. B. snake_case vs camelCase).
- Stellen Sie sicher, dass Tabellennamen den Bereich widerspiegeln (z. B.
kundeanstelle vont1). - Behalten Sie Kommentare im Schema bei, um den Kontext der Geschäftslogik zu erhalten.
Zukunftssicherung Ihres Modells 🚀
Sie können die Zukunft nicht vorhersagen, aber Sie können Flexibilität schaffen. Während Überkonstruktion schlecht ist, ist das Gestalten für Veränderungen klug.
Erweiterbare Gestaltungsmuster
- EAV (Entität-Eigenschaft-Wert): Nützlich für sehr variable Daten, verliert aber an Abfrageleistung.
- JSON-Spalten: Moderne Datenbanken unterstützen JSON-Typen. Dadurch können Sie flexible Attribute speichern, ohne die Tabellenstruktur zu ändern.
- Tagging-Systeme: Verwenden Sie eine Many-to-Many-Beziehung für Metadaten, anstatt spezifische Attribute festzulegen.
Überwachung und Prüfung
- Verfolgen Sie Schemaänderungen. Wer hat was und wann geändert?
- Überwachen Sie Trends der Datenwachstums. Wenn eine Tabelle monatlich um 50 % wächst, planen Sie die Partitionierung, bevor es zu Verlangsamungen kommt.
- Richten Sie Warnungen für Verletzungen von Einschränkungen ein.
Schlussfolgerung zur Anpassungsfähigkeit 🔄
Die Entwicklung eines ERD spiegelt die Reife der Anwendung wider. Sie geht von Flexibilität über Integrität hin zu Leistung. Jede Phase bringt neue Herausforderungen mit sich. Der Schlüssel besteht darin, diese Veränderungen vorherzusehen und bewusst zu managen.
Es gibt kein einziges „perfektes“ Modell. Es gibt nur das Modell, das Ihren aktuellen Einschränkungen und Wachstumspfad entspricht. Indem Sie die Abwägungen zwischen Normalisierung, Denormalisierung und architektonischen Mustern verstehen, können Sie sicherstellen, dass Ihre Datenebene Ihr Unternehmen jahrelang unterstützt.
- Beginnen Sie einfach, planen Sie aber auf Struktur.
- Normalisieren Sie zur Integrität, Denormalisieren Sie zur Geschwindigkeit.
- Dokumentieren Sie jede Änderung.
- Testen Sie Migrationen gründlich.
Ihre Daten sind Ihr wertvollster Vermögenswert. Behandeln Sie das Modell, das sie hält, mit der Sorgfalt, die es verdient.