











Die Gestaltung einer robusten Datenbank erfordert eine klare Karte der Datenstrukturen. Ein Entity-Relationship-Diagramm (ERD) dient als dieses Bauplan, der visualisiert, wie Daten innerhalb eines Systems miteinander verbunden sind. Das Verständnis der zentralen Komponenten – Entitäten, Attribute und Beziehungen – ist entscheidend für die Entwicklung skalierbarer Lösungen. Dieser Leitfaden untersucht diese Elemente ausführlich und stellt eine solide Grundlage für die Datenbankarchitektur sicher.
🏗️ Was ist ein ERD?
Ein ERD ist eine visuelle Darstellung der Struktur einer Datenbank. Er zeigt die Datenbestandteile und ihre Verbindungen auf. Stellen Sie sich vor, es sei ein Architekturplan für ein Gebäude, bei dem die Datenbank die Struktur und die Daten die Bewohner sind. Er schließt die Lücke zwischen abstrakten geschäftlichen Anforderungen und konkreter technischer Umsetzung.
Zu den wichtigsten Vorteilen gehören:
- Klarheit:Interessenten können den Datenfluss verstehen, ohne Code schreiben zu müssen.
- Konsistenz:Stellt sicher, dass Datenregeln einheitlich im gesamten System angewendet werden.
- Effizienz:Reduziert Fehler in der Entwicklungsphase, indem Designmängel früh erkannt werden.
- Kommunikation:Bietet eine gemeinsame Sprache für Entwickler, Analysten und Geschäftsinhaber.
🔑 Komponente 1: Entitäten
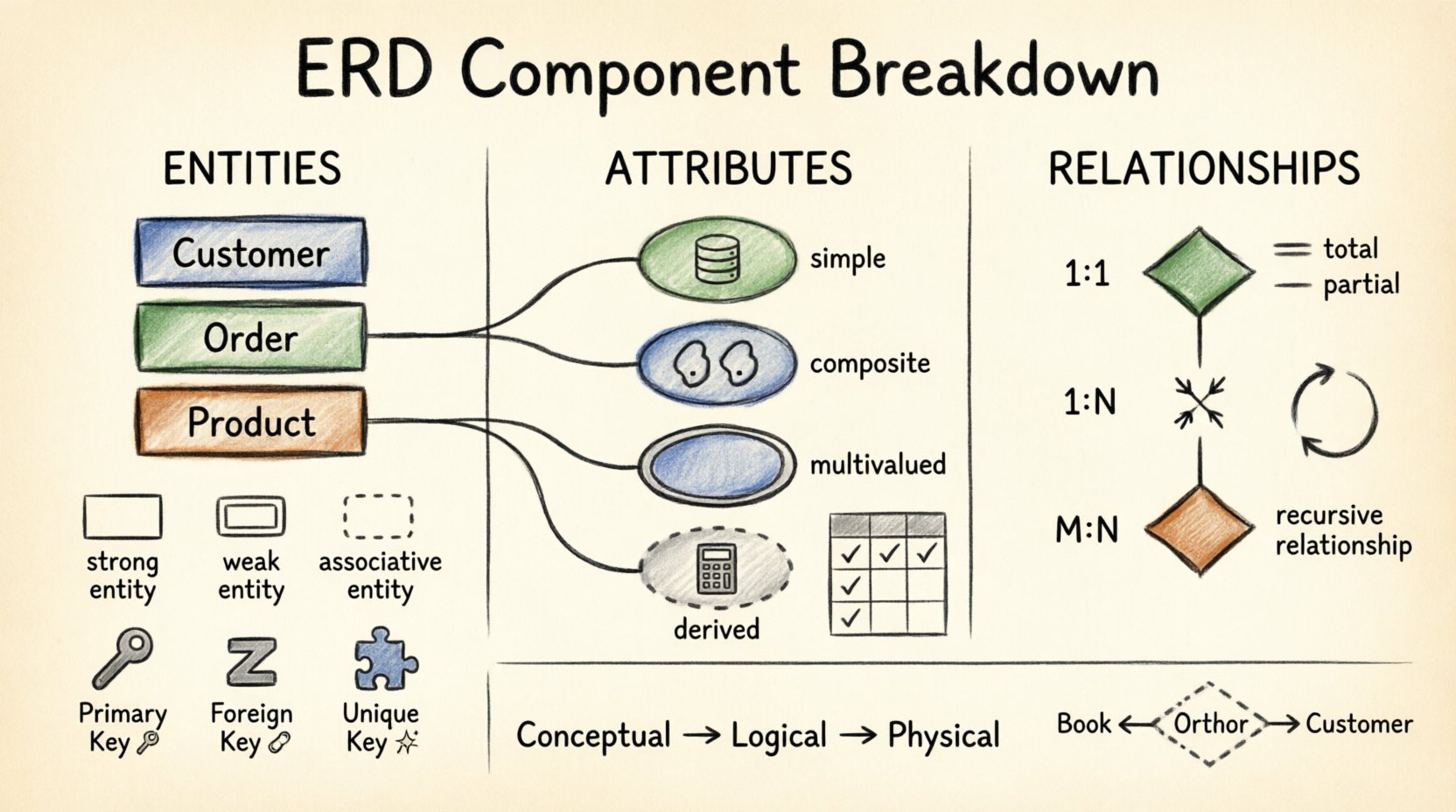
Entitäten stellen Gegenstände oder Konzepte der realen Welt dar, die in der Datenbank gespeichert werden müssen. Sie sind die grundlegenden Bausteine des Modells. Jede Entität sollte eindeutig und identifizierbar sein.
1.1 Definition von Entitäten
Eine Entität ist typischerweise ein Substantiv, wie zum BeispielKunde, Bestellung, oderProdukt. Im Diagramm werden sie oft als Rechtecke dargestellt. Jede Entität steht für eine Sammlung ähnlicher Objekte.
1.2 Arten von Entitäten
Nicht alle Entitäten funktionieren auf die gleiche Weise. Die Unterscheidung zwischen ihnen hilft bei der Modellierung komplexer Szenarien.
- Starke (reguläre) Entitäten: Sie existieren unabhängig. Sie verfügen über einen eigenen Primärschlüssel und sind nicht von einer anderen Entität abhängig, um zu existieren.
- Schwache Entitäten: Sie hängen für ihre Identität von einer starken Entität ab. Sie können ohne die übergeordnete Entität nicht existieren. Sie werden oft mit einem doppelten Rechteck dargestellt.
- Assoziative Entitäten: Diese lösen viele-zu-viele-Beziehungen auf, indem sie sie in zwei viele-zu-eins-Beziehungen aufgeteilt werden. Sie fungieren als Brückentabelle, die Fremdschlüssel aus beiden verwandten Entitäten enthält.
1.3 Identifizierung von Entitäten
Jede Entität muss einen eindeutigen Bezeichner haben. Ohne diesen ist es unmöglich, zwei Datensätze voneinander zu unterscheiden. Häufige Strategien sind:
- Verwendung einer vom System generierten ID (z. B. UUID).
- Verwendung eines natürlichen Schlüssels (z. B. Sozialversicherungsnummer, ISBN).
- Verwendung eines zusammengesetzten Schlüssels (Kombination mehrerer Attribute).
📝 Komponente 2: Attribute
Attribute sind die Eigenschaften oder Merkmale, die eine Entität beschreiben. Wenn eine Entität eine Person ist, sind die Attribute Name, Alter und Adresse. Sie werden gewöhnlich durch Ovale dargestellt, die mit dem Rechteck der Entität verbunden sind.
2.1 Klassifizierung von Attributen
Attribute unterscheiden sich in Komplexität und Funktion. Das Verständnis dieser Kategorien unterstützt die Normalisierung und die Optimierung von Abfragen.
- Einfache Attribute:Atomare Werte, die nicht weiter unterteilt werden können. Beispiel: Alter oder Farbe.
- Zusammengesetzte Attribute: Können in andere Attribute unterteilt werden. Beispiel: Adresse kann in Straße, Stadt, und Postleitzahl.
- Mehrwertige Attribute: Eine Entität kann mehrere Werte für dieses Attribut haben. Beispiel: Telefonnummern oder Bildungsabschlüsse. Diese werden oft durch ein doppeltes Oval dargestellt.
- Abgeleitete Attribute: Berechnet aus anderen Attributen. Beispiel: Alter kann abgeleitet werden aus Geburtsdatum. Diese werden typischerweise nicht physisch gespeichert, um Platz zu sparen.
2.2 Schlüsselattribute
Bestimmte Attribute erfüllen spezifische Funktionen für die Datenintegrität. Eine Tabelle fasst die wichtigsten Typen zusammen:
| Schlüsseltyp | Funktion | Beispiel |
|---|---|---|
| Primärschlüssel | Identifiziert eindeutig jedes Datensatz in einer Tabelle. | KundenID |
| Fremdschlüssel | Verknüpft eine Tabelle mit einer anderen über einen Primärschlüssel. | BestellID (in Bestellpositionen) |
| Eindeutiger Schlüssel | Stellt sicher, dass keine doppelten Werte vorhanden sind, erlaubt jedoch NULL-Werte. | E-Mail-Adresse |
| Kandidatenschlüssel | Jedes Attribut, das als Primärschlüssel dienen könnte. | Sozialversicherungsnummer, Reisepassnummer |
2.3 Null vs. Nicht-Null
Beschränkungen definieren, ob ein Attribut Daten enthalten muss. Eine NICHT NULLBeschränkung stellt sicher, dass Daten vorhanden sind, was für Primärschlüssel entscheidend ist.NULL Werte deuten auf fehlende oder unbekannte Daten hin, die in der Anwendungslogik sorgfältig behandelt werden müssen.
🔗 Komponente 3: Beziehungen
Beziehungen definieren, wie Entitäten miteinander interagieren. Sie beschreiben die Geschäftslogik, die Datenpunkte verbindet. In einem ERD werden Beziehungen als Rauten dargestellt, die Entitätsrechtecke verbinden.
3.1 Kardinalität
Die Kardinalität legt die Anzahl der Instanzen einer Entität fest, die mit der Anzahl der Instanzen einer anderen Entität verknüpft sind. Sie ist der wichtigste Aspekt der Beziehungsmodellierung.
- Ein-zu-Eins (1:1): Eine Instanz der Entität A steht genau mit einer Instanz der Entität B in Beziehung. Beispiel: Person zu Reisepass.
- Ein-zu-Viele (1:N): Eine Instanz der Entität A steht mit vielen Instanzen der Entität B in Beziehung. Beispiel: Abteilung zu Mitarbeiter.
- Viele-zu-Viele (M:N): Viele Instanzen der Entität A stehen mit vielen Instanzen der Entität B in Beziehung. Beispiel: Student zu Kurs. Dies erfordert eine assoziative Entität zur Auflösung.
3.2 Teilnahmeeinschränkungen
Die Teilnahme bestimmt, ob eine Entität in einer Beziehung beteiligt sein muss. Sie wird oft als Existenzabhängigkeit bezeichnet.
- Totale Teilnahme: Jede Instanz einer Entität muss an der Beziehung beteiligt sein. Dargestellt durch eine doppelte Linie. Beispiel: Jede Bestellung muss mindestens eine Kunde.
- Teilnahme: Einige Instanzen können nicht teilnehmen. Dargestellt durch eine einzelne Linie. Beispiel: Ein Mitarbeiter könnte noch keine EhepartnerAufzeichnung haben.
3.3 Beziehungstypen
Abgesehen von der Kardinalität können Beziehungen nach ihrer Art klassifiziert werden.
| Typ | Beschreibung | Beispiel |
|---|---|---|
| Identifizierend | Die schwache Entität hängt für ihre Identität von der starken Entität ab. | Kind hängt von Elternteil ab |
| Nicht-identifizierend | Die Beziehung besteht, aber das Kind hat seine eigene Identität. | Manager verwaltet Mitarbeiter |
| Rekursiv | Eine Entität steht in Beziehung zu sich selbst. | Mitarbeiter überwacht Mitarbeiter |
📊 Komponente 4: Notationsstile
Während die Logik gleich bleibt, variiert die visuelle Darstellung. Das Wissen über gängige Stile hilft beim Lesen von Diagrammen, die von verschiedenen Teams erstellt wurden.
4.1 Crow’s-Foot-Notation
Dies ist der am häufigsten verwendete Stil. Er verwendet Symbole wie eine Linie, einen Kreis und einen Krähenfuß (drei Linien), um die Kardinalität anzugeben.
- Eine Linie:Pflichtige Eins.
- Kreis:Optional (Null).
- Krähenfuß: Viele.
4.2 Chen-Notation
Benannt nach Peter Chen, dem Erfinder der ERDs. Es verwendet Rechtecke für Entitäten, Rauten für Beziehungen und Ellipsen für Attribute. Es ist abstrakter und wird häufig in akademischen Kontexten verwendet.
4.3 UML-Klassendiagramme
Unified Modeling Language-Diagramme verwenden ähnliche Konzepte, sind aber auf objektorientierte Programmierung abgestimmt. Sie enthalten Sichtbarkeitsindikatoren (+, -, #) und Methodenlisten.
🛠️ Komponente 5: Normalisierung und ERD
Die Normalisierung ist der Prozess der Organisation von Daten, um Redundanz zu reduzieren und die Integrität zu verbessern. Die ERD ist die visuelle Ausgabe dieses Prozesses.
5.1 Der Prozess
- Erste Normalform (1NF): Stellen Sie atomare Werte sicher. Keine wiederholenden Gruppen.
- Zweite Normalform (2NF): Entfernen Sie partielle Abhängigkeiten. Alle nicht-schlüsselbasierten Attribute müssen auf den gesamten Primärschlüssel abhängen.
- Dritte Normalform (3NF): Entfernen Sie transitive Abhängigkeiten. Nicht-schlüsselbasierte Attribute sollten nicht von anderen nicht-schlüsselbasierten Attributen abhängen.
5.2 Einfluss auf die Gestaltung
Die Normalisierung erhöht oft die Anzahl der Tabellen. Obwohl dies die Datenintegrität verbessert, kann dies Abfragen komplizierter machen. Die ERD hilft dabei, diesen Kompromiss visuell darzustellen und zeigt auf, wo Joins erforderlich sind, um die vollständigen Informationen abzurufen.
⚠️ Häufige Fehlerquellen
Selbst erfahrene Designer machen Fehler. Die Aufmerksamkeit für häufige Fehler verhindert zukünftige technische Schulden.
- Bedeutungslose Namen: Die Verwendung von Begriffen wie Daten oder Info macht das Modell schwer verständlich. Verwenden Sie spezifische Substantive wie Transaktionsprotokoll.
- Fehlende Kardinalität: Das Vergessen, festzulegen, ob eine Beziehung optional oder obligatorisch ist, führt zu Datenintegritätsproblemen.
- Zirkuläre Abhängigkeiten: Entität A hängt von B ab, und B hängt von A ab. Dies erzeugt eine logische Schleife, die Datenbank-Engines nicht auflösen können.
- Über-Normalisierung: Zu viele Tabellen zu erstellen kann das Abfragen verlangsamen. Gleichgewicht zwischen Normalisierung und Leistungsanforderungen finden.
- Ignorieren von Geschäftsregeln: Ein Diagramm, das strukturell perfekt aussieht, könnte scheitern, wenn es nicht tatsächliche geschäftliche Beschränkungen widerspiegelt.
🚀 Best Practices
Die Einhaltung von Standards sichert Wartbarkeit und Zusammenarbeit.
6.1 Namenskonventionen
Konsistenz ist entscheidend. Verwenden Sie ein einheitliches Format für alle Namen.
- Plural versus Singular: Wählen Sie eine Variante und bleiben Sie dabei. (z. B. Kunde versus Kunden).
- Unterstriche: Verwenden Sie snake_case für Datenbankspalten (z. B. kunde_id).
- Bedeutungsvolle Präfixe: Kennzeichnen Sie Tabellentypen (z. B. tbl_ oder dim_).
6.2 Dokumentation
Ein ERD ist kein eigenständiges Artefakt. Es benötigt Kontext.
- Fügen Sie ein Datenwörterbuch hinzu, das jedes Attribut erklärt.
- Dokumentieren Sie die Geschäftsregeln hinter den Einschränkungen.
- Versionenkontrolle der Diagramme, um Änderungen im Laufe der Zeit zu verfolgen.
6.3 Überprüfungszyklen
Finalisieren Sie niemals ein Design ohne Peer-Review.
- Technische Überprüfung: Überprüfen Sie die Normalisierung und die Schlüsselintegrität.
- Geschäftsüberprüfung: Stellen Sie sicher, dass das Modell den realen Ablauf der Welt entspricht.
- Leistungsüberprüfung: Beurteilen Sie die Indizierungsstrategien und die Komplexität von Joins.
🔍 Praktisches Beispiel
Betrachten Sie einen Online-Buchladen. Die zentralen Entitäten wärenBuch, Autor:, undKunde.
- Buch: Attribute umfassen ISBN (Primärschlüssel), Titel und Preis.
- Autor: Attribute umfassen AuthorID (Primärschlüssel) und Name.
- Beziehung: Ein Buch kann mehrere Autoren haben (Viele-zu-Viele). Ein Autor kann mehrere Bücher schreiben.
- Lösung: Erstellen Sie eine assoziative EntitätBuch_Autor mit ISBN und AuthorID.
Diese Struktur ermöglicht eine flexible Dateneingabe, ohne dass Autoreninformationen für jedes Buch dupliziert werden müssen.
📈 Entwicklung des Modells
Datenbankdesigns sind selten statisch. Wenn sich die geschäftlichen Anforderungen ändern, muss das ERD sich weiterentwickeln.
- Konzeptuelles Modell: Hochlevel-Übersicht für Stakeholder. Fokussiert auf Entitäten und Beziehungen ohne technische Details.
- Logisches Modell: Fügt Attribute und Schlüssel hinzu. Definiert Datentypen und Beziehungen präzise.
- Physisches Modell: Optimiert für eine spezifische Datenbank-Engine. Enthält Indizes, Partitionierung und Speicherdetails.
Übergänge zwischen diesen Stadien erfordern sorgfältige Validierung, um sicherzustellen, dass die Datenintegrität während des gesamten Lebenszyklus gewahrt bleibt.
🧩 Erweiterte Konzepte
Für komplexe Systeme können herkömmliche ERDs Erweiterungen erfordern.
7.1 Ober- und Untertypen
Generalisierung und Spezialisierung ermöglichen Vererbung. Eine FahrzeugEntität kann in Auto und LKW. Dies reduziert Redundanz bei gemeinsamen Attributen, ermöglicht aber eindeutige für Untertypen.
7.2 Aggregation
Wenn eine Beziehung selbst als Entität behandelt werden muss. Zum Beispiel hat eine Beratung zwischen einem Arzt und einem Patient eigene Attribute wie Datum und Diagnose.
7.3 Ternäre Beziehungen
Beziehungen, die drei Entitäten betreffen. Obwohl dies möglich ist, sind sie oft schwer in relationalen Datenbanken umzusetzen. Die Zerlegung in binäre Beziehungen wird normalerweise bevorzugt.
🔍 Schlussfolgerung
Die Beherrschung der Bestandteile eines Entity-Relationship-Diagramms ist grundlegend für eine effektive Datenverwaltung. Durch die klare Definition von Entitäten, Attributen und Beziehungen können Teams Systeme erstellen, die sowohl robust als auch flexibel sind. Sorgfalt bei der Gestaltung zahlt sich in den Entwicklungs- und Wartungsphasen aus. Regelmäßige Überprüfungen und die Einhaltung bewährter Praktiken stellen sicher, dass die Datenbank eine zuverlässige Ressource für die Organisation bleibt.
Mit wachsenden Datenmengen steigt die Notwendigkeit präziser Modellierung. Die Investition von Zeit in das Verständnis dieser zentralen Konzepte sichert langfristigen Erfolg in der Datenbankarchitektur.