






Construire un logiciel, c’est comme construire un gratte-ciel. Vous pouvez commencer par une fondation solide, mais si les plans sont flous, la structure finira par vaciller. Dans le monde du développement logiciel, les données sont la fondation. Sans un plan clair, les données s’accumulent en un chaos qui ralentit les performances, casse les fonctionnalités et frustrer les développeurs. C’est là qu’intervient le diagramme entité-association (ERD). Un ERD n’est pas seulement un dessin ; c’est le plan architectural de votre stockage d’information. Il montre comment les données sont connectées, garantissant que, au fur et à mesure que votre application grandit, votre base de données reste stable et fiable.
Lorsque les applications grandissent, la complexité des relations entre les données augmente de façon exponentielle. Un début simple pourrait impliquer une seule table pour les utilisateurs, mais bientôt vous avez besoin de commandes, de produits, de paiements et de journaux. Sans une structure formalisée, ces tables deviennent des îlots d’information qui ne communiquent pas correctement entre eux. Cela entraîne une redondance des données, des erreurs d’intégrité et des temps de requête lents. En utilisant un ERD dès le départ et en le maintenant tout au long du cycle de vie, vous créez une source unique de vérité qui guide chaque aspect de la gestion des données.
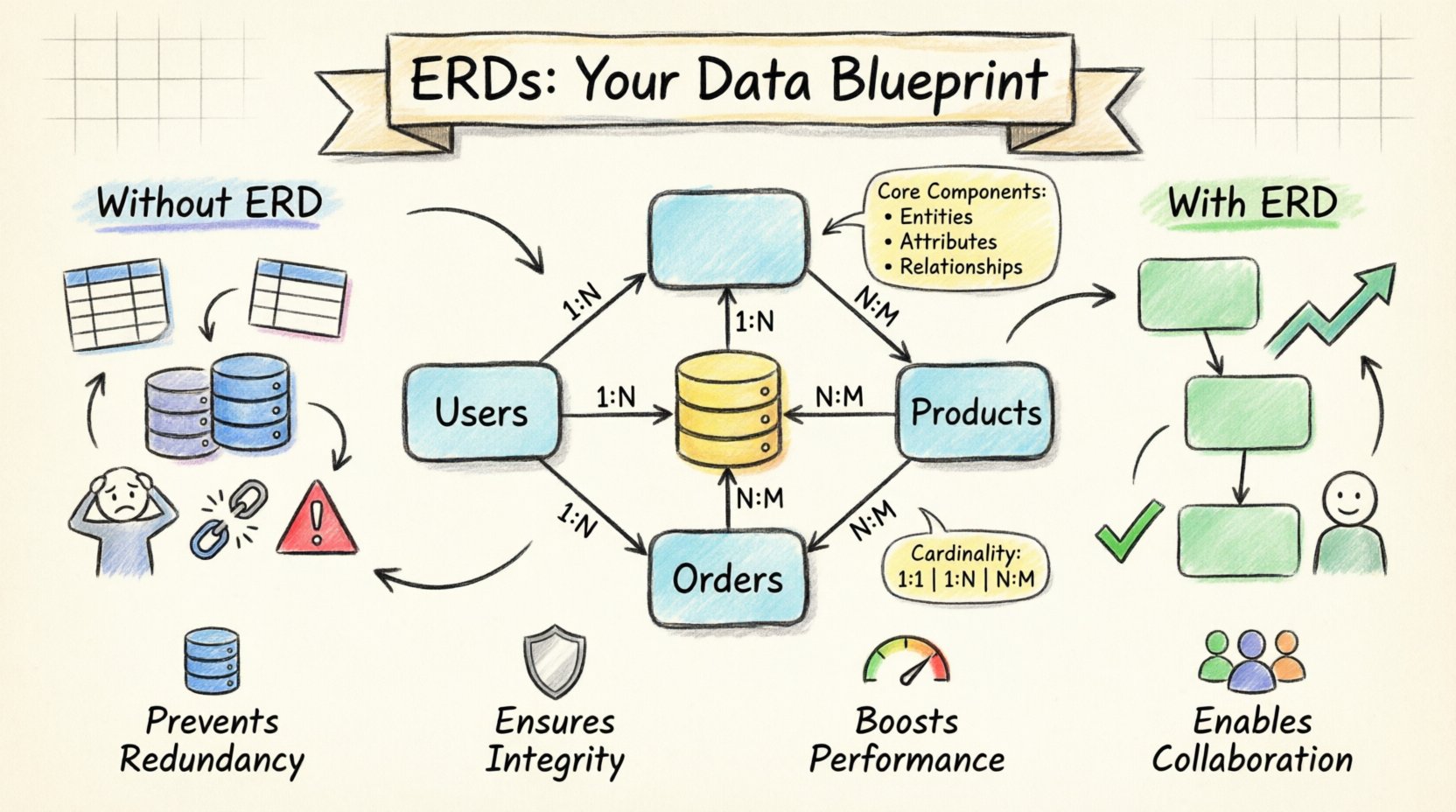
🧩 Comprendre les composants fondamentaux d’un ERD
Pour comprendre comment un ERD prévient le chaos, il faut comprendre ce qui compose ce diagramme. Il s’agit d’une représentation visuelle de la structure de la base de données, qui traduit les besoins abstraits du métier en contraintes techniques concrètes. Chaque diagramme se compose de trois éléments fondamentaux qui travaillent ensemble pour maintenir l’ordre.
- Entités : Elles représentent les objets ou concepts du monde réel que vous suivez. Dans une base de données, une entité devient généralement une table. Des exemples courants incluent Utilisateurs, Commandes, et Produits.
- Attributs : Ce sont les détails spécifiques qui décrivent une entité. Pour une entité Utilisateur , les attributs pourraient inclure nom_utilisateur, email, et date_creation. Les attributs deviennent des colonnes dans la table.
- Relations : C’est la partie la plus critique pour prévenir le chaos. Les relations définissent comment les entités interagissent. Un utilisateur passe une commande. Une commande contient des produits. Ces connexions sont représentées par des lignes reliant les entités, souvent annotées par la cardinalité (par exemple, un-à-plusieurs).
Lorsque ces composants sont clairement définis avant d’écrire la moindre ligne de code, l’équipe de développement évite les suppositions. Tout le monde sait exactement quelles données sont nécessaires et comment elles sont liées aux autres données. Cette clarté réduit considérablement les erreurs lors de la phase de mise en œuvre.
🌪️ Le mécanisme du chaos des données
Qu’est-ce qui se passe réellement lorsque vous sautez la phase ERD ? Il est facile de penser : « Je peux simplement commencer à ajouter des tables au fur et à mesure que j’en ai besoin. » À court terme, cela semble efficace. Cependant, à long terme, cela crée une dette qui s’accumule avec le temps. Voici une analyse des problèmes spécifiques qui surviennent sans modèle de données structuré.
1. Redondance et duplication
Sans un schéma clair, les développeurs copient souvent des données pour faire fonctionner rapidement certaines fonctionnalités. Vous pourriez stocker le nom d’un client dans la table des commandes et aussi dans la table des clients. Si ce client change de nom, vous devez le mettre à jour à deux endroits. Si vous en oubliez un, vos données deviennent incohérentes. Un ERD impose la normalisation, garantissant que les données sont stockées dans un seul endroit logique.
2. Violations d’intégrité référentielle
Cela se produit lorsque le lien entre des points de données est rompu. Par exemple, une commande existe dans la base de données, mais l’utilisateur qui l’a passée a été supprimé. Sans contrainte de clé étrangère définie dans le MCD, la base de données autorise la persistance de cet enregistrement orphelin. Cela entraîne des rapports corrompus et des états de l’interface utilisateur confus, où les données pointent vers rien.
3. Détérioration des performances des requêtes
À mesure que le volume de données augmente, la manière dont vous les interrogez est essentielle. Un schéma mal structuré manque d’index ou de regroupements logiques. Les jointures deviennent coûteuses et ralentissent toute l’application. Un MCD vous aide à visualiser où placer les index en fonction de la fréquence d’accès aux données.
4. Friction dans la collaboration
Lorsque la structure des données n’est pas documentée, les développeurs passent des heures à essayer de comprendre ce qu’une colonne signifie ou pourquoi une table spécifique existe. Cela ralentit l’intégration et le développement de fonctionnalités. Un schéma sert de contrat visuel entre l’équipe produit et l’équipe ingénierie.
📐 Mise en œuvre stratégique : bâtir la fondation
La création d’un MCD n’est pas une action ponctuelle. C’est un processus stratégique qui évolue avec l’entreprise. L’objectif est de trouver un équilibre entre flexibilité et structure. Voici comment aborder la création d’un schéma robuste.
- Commencez par les exigences métiers :Avant de penser aux tables, pensez à l’entreprise. Quels sont les objets principaux ? Qui sont les acteurs ? Quelles transactions ont lieu ? Cela garantit que le modèle technique s’aligne sur l’utilisation réelle.
- Définissez les clés primaires :Chaque table nécessite un identifiant unique. C’est l’ancrage de toutes les relations. Décidez d’utiliser des clés naturelles (comme une adresse e-mail) ou des clés surrogées (comme un ID auto-incrémenté). Les clés surrogées sont généralement préférées pour leur stabilité.
- Établissez la cardinalité :Déterminez la nature des relations. S’agit-il d’une relation Un-à-Un ? Un-à-Plusieurs ? Ou Plusieurs-à-Plusieurs ? Cela détermine la manière dont vous concevez les clés étrangères et les tables de jonction.
- Appliquez la normalisation :Viser la Troisième Forme Normale (3FN) lorsque cela est pertinent. Cela minimise la redondance. Assurez-vous que les attributs non clés dépendent uniquement de la clé primaire.
Considérez les types de relations courants suivants et la manière dont ils sont représentés dans un schéma.
| Type de relation | Description | Stratégie d’implémentation |
|---|---|---|
| Un-à-Un (1:1) | Un enregistrement dans la table A est lié à exactement un enregistrement dans la table B. | Placez une clé étrangère dans l’une des deux tables. |
| Un-à-Plusieurs (1:N) | Un enregistrement dans la table A est lié à plusieurs enregistrements dans la table B. | Placez une clé étrangère dans la table B qui pointe vers la table A. |
| Plusieurs-à-Plusieurs (N:M) | Plusieurs enregistrements dans la table A sont liés à plusieurs enregistrements dans la table B. | Créez une table de jonction (pont) contenant des clés étrangères provenant des deux tables. |
🚀 Évolutivité avec le MCD
Les applications ne restent pas statiques. Elles évoluent. Des fonctionnalités sont ajoutées, les bases d’utilisateurs s’élargissent et le volume de données augmente. Un schéma statique peut devenir obsolète, mais un ERD vivant s’adapte. Comment un ERD aide-t-il pendant la phase d’extension ?
- Identification des goulets d’étranglement : En examinant le schéma, vous pourriez remarquer qu’une table spécifique devient le centre de gravité. Cela indique la nécessité de partitionner ou de fractionner la base. La disposition visuelle vous aide à identifier où la charge est concentrée.
- Planification de la migration : Lorsque vous devez modifier un schéma (par exemple, diviser une table), l’ERD vous montre toutes les relations dépendantes. Vous pouvez planifier la migration pour vous assurer qu’aucune contrainte de clé étrangère n’est violée pendant la transition.
- Décisions architecturales : Parfois, les besoins en données passent du relationnel au non relationnel. Un ERD vous aide à comprendre les relations fondamentales qui doivent être préservées, même si la technologie sous-jacente change.
Par exemple, si vous décidez d’introduire une couche de mise en mémoire tampon, vous devez savoir quelles données sont très lues. L’ERD met en évidence les entités centrales de l’application, vous guidant sur ce qu’il faut mettre en cache et ce qu’il faut laisser dans le magasin principal.
🛠️ Maintenance et évolution
Créer le schéma n’est que la moitié de la bataille. La vraie valeur réside dans le fait de le tenir à jour. Un schéma qui ne correspond pas à la base de données réelle est pire qu’aucun schéma, car il crée une fausse confiance. Voici les meilleures pratiques pour la maintenance.
- Contrôle de version :Traitez l’ERD comme du code. Stockez-le dans votre dépôt. Validez les modifications lorsque des changements de schéma sont effectués. Cela crée une trace d’audit de l’évolution du modèle de données au fil du temps.
- Cycles de revue :Incluez la revue du schéma dans votre planification de sprint. Avant de déployer une migration de base de données, vérifiez-la par rapport au schéma. Cela permet de détecter les incohérences avant qu’elles n’atteignent la production.
- Normes de documentation :Utilisez des conventions de nommage cohérentes. Évitez les abréviations cryptiques. Si le nom d’une table est
tbl_usr, changez-le enusers. La cohérence réduit la charge cognitive pour quiconque lit le schéma. - Génération automatisée : Là où c’est possible, générez le schéma à partir du schéma existant. Cela garantit que la représentation visuelle correspond toujours à la réalité physique. Utilisez des outils capables de reverse-ingénierie de la structure de la base de données.
🚫 Pièges courants à éviter
Même les équipes expérimentées tombent dans des pièges lors de la modélisation des données. Être conscient de ces erreurs courantes vous aide à éviter le chaos futur.
- Sur-normalisation : Bien que la normalisation soit bénéfique, diviser les données en trop nombreuses tables peut rendre les requêtes incroyablement complexes et lentes. Trouvez un équilibre entre le besoin de structure et celui de performance des requêtes.
- Ignorer les suppressions douces :Dans les applications modernes, les données sont rarement supprimées de façon définitive. Vous avez besoin d’un champ
deleted_atpour indiquer la suppression logique. Assurez-vous que votre ERD tient compte de cette stratégie de suppression logique dès le départ. - Relations cachées : Ne cachez pas les relations au sein de la logique de l’application. Si la table A est liée à la table B, rendez cette relation explicite dans le schéma de la base de données. Faire dépendre l’application pour imposer des relations est fragile.
- Dénormalisation sans objectif : Parfois, vous dupliquez intentionnellement des données pour gagner en vitesse. Cependant, cela doit être un choix réfléchi, et non le résultat d’une mauvaise planification. Documentez pourquoi vous dénormalisez.
🤝 L’élément humain de la modélisation des données
Les données ne sont pas seulement des chiffres ; elles représentent des personnes, des produits et des actions. Un MCD (modèle conceptuel de données) comble le fossé entre les contraintes techniques et la logique métier. Lorsqu’un responsable produit propose une nouvelle fonctionnalité, le MCD lui permet de voir immédiatement les implications sur les données. Cela empêche le « creep fonctionnel » qui casse souvent les bases de données.
Pensez à un scénario où une entreprise souhaite suivre les préférences des utilisateurs. Sans MCD, un développeur pourrait créer une nouvelle colonne pour chaque préférence. Cela conduit à une table large et éparse, difficile à interroger. Avec un MCD, ils reconnaissent un schéma : clés et valeurs. Ils créent une table préférences table. Cette structure est souple et évolutif.
En outre, le MCD facilite une meilleure communication entre les départements. Lorsque l’équipe juridique demande des informations sur la conservation des données, le modèle de données montre exactement où ces données sont stockées. Cette transparence est cruciale pour les audits de conformité et de sécurité.
🔍 Approfondissement : Contraintes d’intégrité
L’une des fonctionnalités les plus puissantes d’une base de données relationnelle est la capacité à imposer des règles au niveau de la base de données. Ces règles sont appelées contraintes. Un MCD est le précurseur visuel de ces contraintes. Il définit où elles doivent être appliquées.
- NON NULL : Assure qu’un champ doit avoir une valeur. Essentiel pour les identifiants principaux comme les identifiants utilisateur ou les adresses e-mail.
- UNIQUE : Assure qu’aucune valeur en double n’existe dans une colonne. Essentiel pour éviter les e-mails ou noms d’utilisateur en double.
- VÉRIFIER : Permet des logiques personnalisées, comme s’assurer qu’un prix est toujours supérieur à zéro.
- PAR DÉFAUT : Fournit une valeur par défaut si aucune n’est fournie. Utile pour les horodatages ou les indicateurs d’état.
En définissant ces contraintes dans le schéma, vous vous assurez que la base de données elle-même protège les données, plutôt que de dépendre du code de l’application pour valider les entrées. C’est une couche fondamentale de protection contre la corruption des données.
🔄 Le cycle de vie d’un changement de schéma
Le changement est inévitable. Vous devrez ajouter des colonnes, renommer des tables ou diviser des entités. Le MCD guide ce processus en toute sécurité.
- Visualisez le changement : Mettez à jour le schéma pour montrer l’état futur.
- Analysez l’impact : Suivez les lignes. Quelles tables seront affectées ? Quelles requêtes seront cassées ?
- Planifiez la migration : Écrivez des scripts qui gèrent la transition de manière fluide. Ajoutez d’abord la nouvelle colonne, remplissez-la, puis faites passer l’application à son utilisation, puis supprimez enfin la colonne ancienne.
- Mettez à jour le schéma : Une fois la migration terminée, mettez à jour le schéma ERD pour refléter la nouvelle réalité.
Ce processus empêche le « décalage de schéma » qui survient lorsque le code et la base de données divergent au fil du temps. Garder le schéma synchronisé est la clé de la stabilité à long terme.
📈 Mesurer l’impact
Comment savoir si votre stratégie ERD fonctionne ? Recherchez ces indicateurs de santé au sein de votre application.
- Moins d’erreurs de données : Les rapports montrent moins d’incohérences ou de données orphelines.
- Intégration plus rapide : Les nouveaux développeurs peuvent comprendre rapidement la structure des données.
- Requêtes optimisées : Les métriques de performance montrent des temps de requête stables ou améliorés à mesure que les données augmentent.
- Communication claire : Moins de réunions sont nécessaires pour expliquer le flux des données entre les systèmes.
Ces métriques démontrent que l’investissement initial dans la modélisation rapporte des bénéfices tout au long de la vie de l’application. Cela déplace l’accent de la résolution des problèmes vers leur prévention.
🛠️ Outils et techniques de documentation
Bien que vous deviez éviter de vous fier à des outils spécifiques des fournisseurs, la pratique de la documentation est universelle. Que vous utilisiez un stylo et du papier, des tableaux numériques ou un logiciel dédié à la modélisation, le principe reste le même. L’objectif est la clarté.
Assurez-vous que vos schémas incluent :
- Les noms de table en gras.
- Les clés primaires clairement indiquées.
- Les clés étrangères étiquetées avec leur type de relation.
- Descriptions pour les tables complexes.
Certaines équipes utilisent un schéma « en lecture seule » pour les développeurs frontend et un schéma « optimisé pour l’écriture » pour l’équipe backend. Cette séparation des préoccupations permet de maintenir la complexité maîtrisée. Assurez-vous toujours que la source de vérité finale est le schéma de la base de données elle-même, mais conservez le schéma ERD comme référence pour la compréhension.
🔗 Intégration avec DevOps
Dans les flux de travail modernes, la base de données est traitée comme du code. Le schéma ERD s’intègre dans cette chaîne. Lorsqu’un développeur valide un changement dans le schéma, la chaîne CI/CD doit le valider par rapport au schéma attendu. Si le schéma réel dévie de la conception, la construction peut échouer. Cette application automatisée de la conformité garantit que le plan directeur est toujours respecté.
Cette intégration empêche la suppression accidentelle de tables ou la création de champs non structurés. Elle impose une discipline au niveau de l’automatisation, en s’assurant que le chaos est bloqué avant même d’atteindre la production.
🧠 Réflexions finales sur l’architecture des données
Le chaos des données n’est pas un mystère ; c’est un résultat prévisible de la croissance non structurée. En investissant du temps dans les diagrammes de relations entre entités, vous construisez un système capable de résister à la pression de l’évolutivité. Il s’agit de créer de l’ordre à partir de la complexité. Il garantit que chaque morceau de données a une maison et une finalité.
La discipline nécessaire pour maintenir un ERD se traduit par une fiabilité accrue. Votre application devient une plateforme stable plutôt qu’un prototype fragile. Alors que vous continuez à construire, rappelez-vous que le schéma est un document vivant. Il grandit avec vous, guidant vos décisions et protégeant votre investissement. Le chemin vers une application robuste est pavé de relations de données claires et bien définies.