











Concevoir des modèles de données dans une architecture de microservices exige un changement fondamental de pensée par rapport aux applications monolithiques. Dans un système traditionnel, un seul diagramme Entité-Relation (ERD) couvre souvent toute la base de données. Dans un environnement distribué, cette vue unique se fragmente en plusieurs schémas indépendants. Le défi réside dans le maintien de la cohérence sans coupler les services entre eux. Ce guide explore comment structurer efficacement les modèles de données, en assurant échelle et résilience tout en évitant les pièges courants de la gestion des données distribuées.
Lorsque les services partagent des données directement, ils héritent des dépendances mutuelles. Ce couplage étroit entraîne des systèmes fragiles où un changement dans une zone entraîne une panne dans une autre. L’objectif est de créer des frontières permettant aux équipes de déployer de manière indépendante. Pour y parvenir, il faut planifier soigneusement les relations, les modèles de cohérence et les patterns d’intégration.
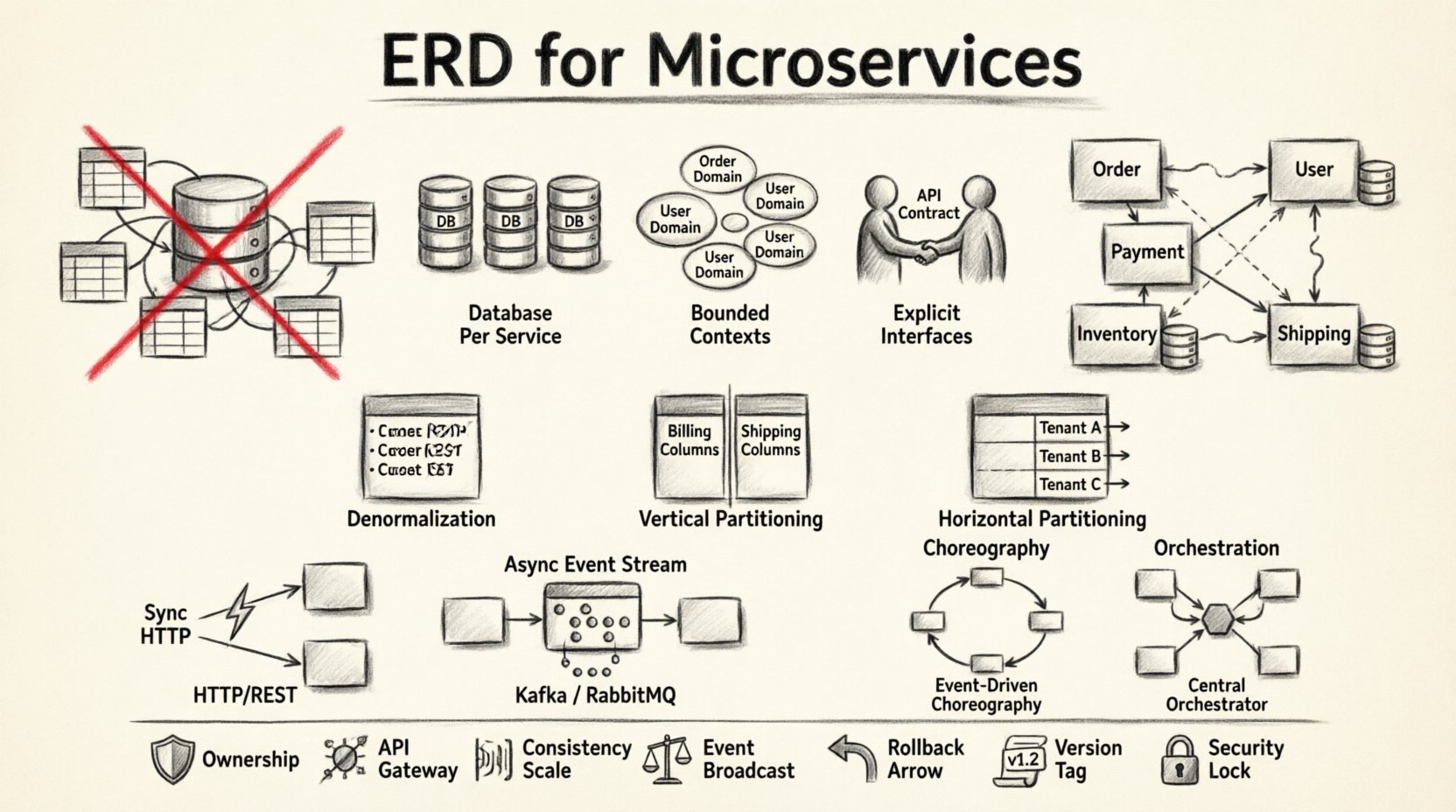
🧱 Pourquoi les ERD traditionnels échouent dans les systèmes distribués
Un ERD standard suppose une autorité centrale. Il mappe les tables, les colonnes et les clés étrangères dans une seule frontière transactionnelle. Les microservices rejettent cette centralisation. Lorsque vous appliquez une mentalité d’ERD monolithique à un système distribué, vous risquez de créer un monolithe distribué. Cela se produit lorsque les services dépendent de tables de base de données partagées plutôt que d’API définies.
Les problèmes suivants apparaissent généralement lorsqu’on ignore ces principes :
- Couplage du déploiement :Les modifications apportées à une table partagée exigent des déploiements simultanés sur plusieurs services.
- Frontières des transactions :Les transactions ACID s’étendent sur plusieurs services, augmentant la latence et les points de défaillance.
- Verrouillage du schéma :Les verrous de base de données dans un service peuvent bloquer les requêtes dans un autre service.
- Problèmes de visibilité :Aucune équipe unique ne possède l’état global des données, ce qui entraîne des silos de données.
Plutôt qu’un seul diagramme, vous avez besoin d’une collection de schémas spécifiques aux services qui communiquent par le biais d’interfaces bien définies. Cette approche privilégie l’autonomie sur la cohérence immédiate.
🧬 Principes fondamentaux de la modélisation des données distribuées
Pour maintenir l’ordre, vous devez respecter des principes architecturaux spécifiques. Ces directives aident les équipes à prendre des décisions concernant la propriété des données et les modèles d’accès.
1. Base de données par service
Chaque microservice doit posséder son propre magasin de données. Cela garantit que le schéma interne d’un service n’est pas visible par les autres. Si le Service A a besoin de données du Service B, il doit les demander via une API, et non interroger la base de données directement. Cette isolation protège l’intégrité de chaque domaine.
- Les services gèrent eux-mêmes l’évolution de leur schéma.
- Les équipes peuvent choisir la meilleure technologie de base de données selon leurs besoins spécifiques (persistance polyglotte).
- Une défaillance dans une base de données n’entraîne pas l’arrêt de toute l’application.
2. Contextes bornés
Les données doivent s’aligner sur les capacités métiers. En conception pilotée par le domaine, un contexte borné définit la frontière sémantique d’un modèle. Deux services peuvent utiliser le terme « client », mais les données dans ces contextes diffèrent. L’un peut stocker les coordonnées, tandis que l’autre stocke l’historique financier. Les fusionner dans un seul ERD crée de la confusion et une dette technique.
3. Interfaces explicites
Puisque les services ne peuvent pas voir directement les données de l’autre, l’API devient le contrat de données. Le schéma de la réponse de l’API définit la réalité des données pour le consommateur. Cela déconnecte l’implémentation interne du stockage de la consommation externe.
📐 Modèles de conception de schémas pour l’indépendance
La conception de schémas pour les microservices implique des modèles spécifiques pour gérer les relations qui seraient traditionnellement gérées par des clés étrangères. Vous ne pouvez pas compter sur des contraintes au niveau de la base de données pour imposer des relations entre services.
Dénormalisation
Dans un monolithe, la normalisation réduit la redondance. Dans les microservices, la dénormalisation est souvent préférée. Le stockage de données redondantes réduit le besoin d’appels distants. Par exemple, un service de commandes peut stocker le nom et l’adresse du client dans l’enregistrement de la commande. Cela évite une recherche synchrone vers le service utilisateur à chaque affichage d’une commande.
- Avantage : Meilleure performance de lecture et moins de sauts réseau.
- Risque : Incohérence des données si les données sources changent. Vous devez gérer les mises à jour via des événements.
Partitionnement vertical
Diviser de grandes tables en ensembles plus petits et ciblés. Si une table contient à la fois des informations de facturation et des adresses de livraison, séparez ces préoccupations. Les données de facturation pourraient appartenir à un service de paiement, tandis que les adresses de livraison appartiennent à un service de logistique. Cela réduit la surface des changements et améliore la sécurité en limitant l’accès.
Partitionnement horizontal
Diviser les données en fonction de l’ID du locataire ou de la région géographique. Cela est utile pour scaler des services spécifiques sans affecter les autres. Cela vous permet de répliquer des services pour les régions à fort trafic tout en maintenant les autres légers.
| Modèle | Meilleur cas d’utilisation | Considération clé |
|---|---|---|
| Dénormalisation | Charge de travail orientée lecture | Nécessite une logique de synchronisation |
| Partitionnement vertical | Domaines distincts | Frontières d’API claires |
| Partitionnement horizontal | Haute échelle / Multi-locataire | Complexité de la logique de routage |
🔄 Gestion des relations et de la cohérence
La partie la plus difficile du modèle de données des microservices est de maintenir la cohérence sans transactions distribuées. Vous devez choisir entre la cohérence forte et la cohérence éventuelle.
Communication synchrone
Les services peuvent s’appeler directement via HTTP ou gRPC. Cela assure une cohérence forte pour les opérations immédiates. Toutefois, cela introduit une latence et crée une chaîne de dépendances. Si le service A appelle le service B, et que le service B est hors ligne, le service A échoue.
Communication asynchrone
Les services communiquent via des files de messages ou des flux d’événements. Cela découple le moment des opérations. Le service A publie un événement, et le service B le consomme plus tard. Cela supporte la cohérence éventuelle.
- Avantages : Résilience, évolutivité et faible couplage.
- Inconvénients : Les données sont temporairement incohérentes. Le débogage nécessite un suivi à travers plusieurs journaux.
🗓️ Le modèle Saga pour l’intégrité des données
Une saga est une séquence de transactions locales. Chaque transaction met à jour la base de données locale et publie un événement pour déclencher l’étape suivante. Si une étape échoue, la saga exécute des transactions compensatoires pour annuler les modifications précédentes.
Chorégraphie vs. Orchestration
Les sagas peuvent être implémentées de deux manières :
- Chorégraphie :Les services écoutent les événements et décident quoi faire ensuite. Il n’y a pas de contrôleur central. Cela offre une grande flexibilité mais est plus difficile à visualiser.
- Orchestration :Un coordinateur central indique aux services ce qu’ils doivent faire. Cela offre une meilleure visibilité et un meilleur contrôle sur le flux de travail, mais introduit un point de défaillance unique.
Lors de la modélisation des diagrammes ERD pour les sagas, vous devez tenir compte des changements d’état. Chaque service impliqué dans une saga doit stocker son état pour gérer les annulations. Cela signifie que votre schéma doit prendre en charge les états transactionnels, et non seulement les données finales.
📝 Gestion de l’évolution du schéma
L’évolution du schéma est inévitable. Les champs changent, les types évoluent, et les contraintes se relâchent. Dans un système distribué, vous ne pouvez pas modifier un schéma de base de données tant que d’autres services en dépendent. Vous devez prévoir la versionning.
Compatibilité descendante
Maintenez toujours la compatibilité descendante. Lors de l’ajout d’un nouveau champ, ne supprimez pas immédiatement l’ancien. Permettez aux consommateurs de migrer progressivement. Si vous devez changer le nom d’un champ, créez un alias de l’ancien nom vers le nouveau pendant la période de transition.
Stratégies de versionning
- Versionning dans l’URI :Inclure les numéros de version dans le chemin de l’API.
- Versionning via en-tête :Utilisez des en-têtes personnalisés pour spécifier la version attendue du schéma.
- Négociation de contenu :Utilisez des en-têtes HTTP standards pour demander des types de médias spécifiques.
La documentation doit être synchronisée avec le code. Les tests automatisés doivent vérifier que le contrat API correspond au schéma. Cela empêche les modifications cassantes d’atteindre la production.
🛡️ Pièges courants à éviter
Même avec un plan solide, les équipes rencontrent souvent des problèmes spécifiques. La prise de conscience de ces pièges aide à concevoir un système robuste.
1. Le piège de la base de données partagée
Ne partagez pas de tables entre les services. Cela crée un couplage caché. Si le service de paiement lit la table du service de commande, il connaît trop de détails sur la structure interne. Cela entraîne un couplage étroit et des conflits de déploiement.
2. Sur-normalisation
Essayer de normaliser les données entre les services entraîne des jointures excessives et des appels réseau. Acceptez une certaine redondance. Il vaut mieux avoir des données dupliquées qu’un système lent et couplé.
3. Ignorer l’idempotence
Les appels réseau échouent. Les messages sont dupliqués. Votre schéma et votre logique API doivent gérer les requêtes en doublon sans provoquer d’erreurs. Concevez vos points d’entrée pour être idempotents afin que la répétition d’une requête ne crée pas de doublons.
4. Manque de visibilité
Lorsque les données sont distribuées, vous ne pouvez pas interroger une seule base de données pour suivre une transaction. Vous avez besoin de la traçabilité distribuée et de la journalisation centralisée. Votre schéma doit inclure des identifiants de corrélation pour suivre les requêtes à travers les frontières des services.
📋 Liste de contrôle de gouvernance
Avant de déployer un nouveau service, passez en revue la liste suivante pour vous assurer que votre modèle de données est solide.
- Propriété :Un seul service est-il responsable de ces données ?
- Interface :Les données sont-elles exposées uniquement via une API ?
- Consistance :Le modèle de consistance est-il documenté (forte vs. éventuelle) ?
- Événements :Les changements d’état sont-ils publiés sous forme d’événements pour les autres services ?
- Compensation :Existe-t-il un mécanisme d’annulation pour les transactions échouées ?
- Versioning :Le schéma est-il versionné pour gérer les évolutions futures ?
- Sécurité :Les données sensibles sont-elles chiffrées au repos et en transit ?
🔍 Visualisation de l’architecture
Bien que vous ne puissiez pas dessiner un seul ERD pour l’ensemble du système, vous pouvez créer une carte de haut niveau. Cette carte montre les services et leurs frontières de données, et non des colonnes spécifiques.
- Dessinez des boîtes pour chaque service.
- Étiquetez le domaine de données à l’intérieur de la boîte (par exemple, « Données du profil utilisateur »).
- Dessinez des flèches pour les appels d’API indiquant le flux de données.
- Indiquez les flux d’événements séparément des flux de requête/réponse.
Ce support visuel aide les parties prenantes à comprendre le flux d’information sans s’embrouiller dans les détails techniques du schéma. Il sert d’outil de communication pour les architectes et les analystes métier.
🚀 Conclusion
Concevoir des ERD pour les microservices ne consiste pas à dessiner des lignes entre des tables. Cela consiste à définir des frontières entre les capacités métiers. En adoptant la base de données par service, en acceptant la consistance éventuelle et en gérant rigoureusement les API, vous pouvez construire des systèmes évolutifs. Le chaos des données distribuées est maîtrisable grâce à la discipline et à des contrats clairs. Concentrez-vous sur l’autonomie, minimisez le couplage, et assurez-vous que chaque service possède entièrement ses données.
Souvenez-vous que la modélisation des données est un processus itératif. Au fur et à mesure que les services grandissent, votre schéma devra évoluer. Revoyez régulièrement votre architecture à la lumière de ces principes afin de maintenir un système sain et résilient.