








Concevoir un modèle de données robuste est l’une des tâches les plus critiques en génie logiciel. Un diagramme entité-association (ERD) sert de plan directeur pour le stockage, la récupération et la maintenance des informations. Au cœur de ce plan se trouve la normalisation. De nombreux praticiens abordent la normalisation comme une liste de vérification rigide à remplir avant de passer à l’implémentation. Toutefois, la réalité est bien plus nuancée. Un équilibre délicat entre l’intégrité des données et les performances des requêtes exige une compréhension approfondie.
Ce guide explore les réalités techniques de la normalisation des diagrammes entité-association. Il va au-delà des définitions théoriques pour aborder des scénarios pratiques où une application stricte des règles devient un fardeau. Que vous construisiez un système transactionnel ou une plateforme analytique, savoir quand cesser de normaliser et quand introduire une redondance est essentiel pour la stabilité à long terme.
🔍 Comprendre les principes fondamentaux de la conception relationnelle
La normalisation n’est pas seulement une question d’organisation des données ; c’est une question de gestion des dépendances. Dans un modèle relationnel, chaque colonne doit avoir une relation claire avec la clé primaire de sa table. Lorsque cette relation est faible ou indirecte, des anomalies surviennent. Ces anomalies se manifestent par des incohérences de données, un gaspillage de stockage et une logique de mise à jour complexe.
Les objectifs principaux de la normalisation incluent :
- Intégrité des données : Assurer que les données restent précises et cohérentes dans l’ensemble du système.
- Efficacité du stockage : Éliminer les copies redondantes des mêmes données.
- Évolutivité : Concevoir des schémas capables d’accueillir la croissance sans réécriture structurelle.
- Maintenabilité : Réduire la complexité nécessaire pour mettre à jour les informations.
Toutefois, atteindre ces objectifs comporte souvent un coût. Chaque niveau de normalisation augmente généralement le nombre de tables et la complexité des requêtes nécessaires pour récupérer des données jointes. Comprendre ce compromis est la première étape d’une conception de schéma efficace.
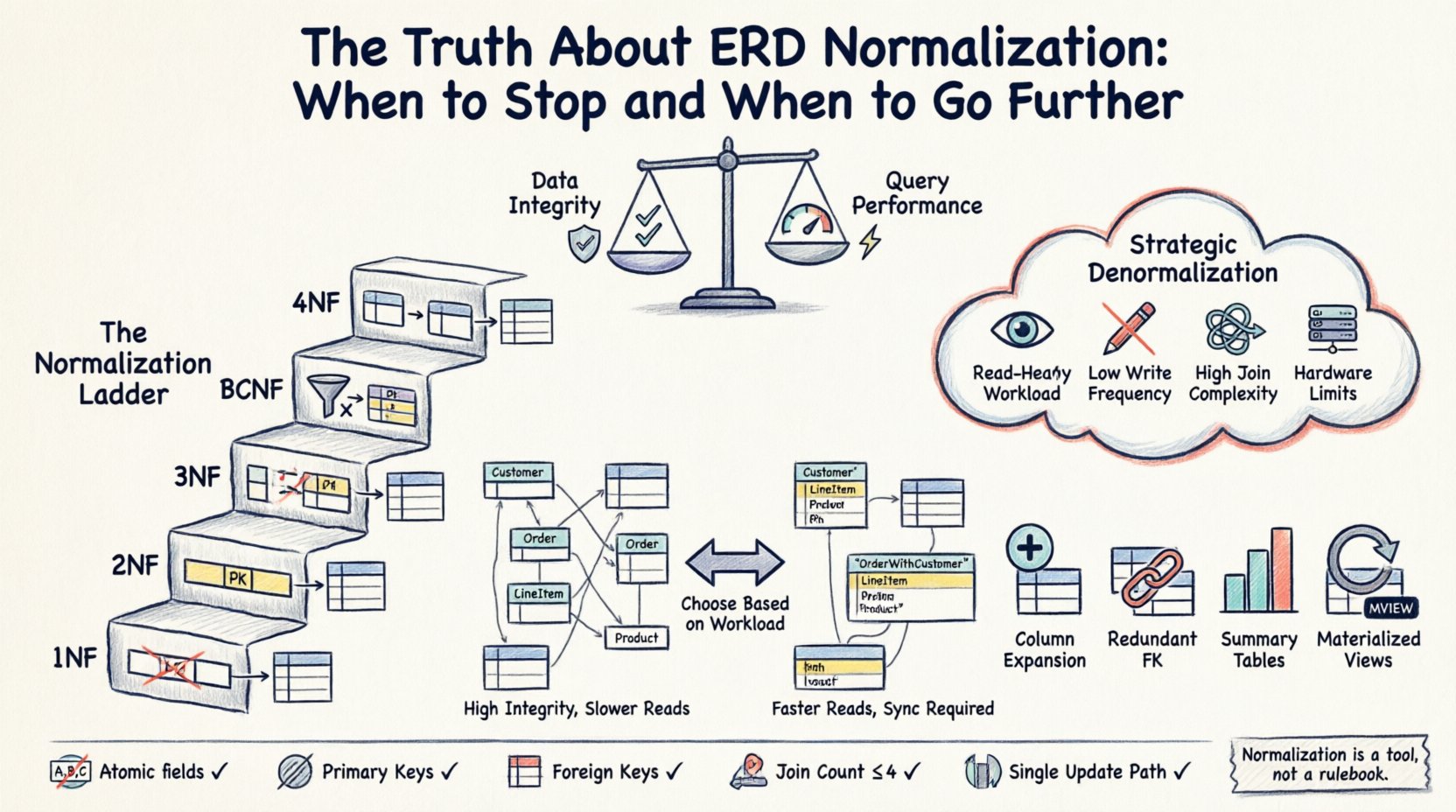
⚙️ Les trois piliers de la normalisation standard (1NF, 2NF, 3NF)
Avant de décider de s’arrêter ou d’aller plus loin, il faut comprendre le niveau de base. Les formes standard constituent une échelle de raffinement structurel.
Première forme normale (1NF)
La fondation de toute base de données relationnelle est la 1NF. Une table est en 1NF si elle remplit les critères suivants :
- Toutes les valeurs de colonnes sont atomiques (indivisibles).
- Chaque colonne contient des valeurs d’un seul type.
- Il n’y a pas de groupes répétés ou de tableaux au sein d’une ligne.
Par exemple, stocker une liste de noms de produits dans une seule colonne viole la 1NF. À la place, chaque produit doit occuper sa propre ligne. Bien que les systèmes modernes puissent gérer des types de données complexes, une application stricte de l’atomicité garantit que les requêtes restent prévisibles et que les stratégies d’indexation fonctionnent comme prévu.
Deuxième forme normale (2NF)
Une fois qu’une table est en 1NF, elle doit satisfaire aux exigences de la 2NF. Cette forme s’applique spécifiquement aux tables possédant une clé primaire composée (clés constituées de plusieurs colonnes). Une table est en 2NF si :
- Elle est déjà en 1NF.
- Toutes les attributs non clés dépendent entièrement de la clé primaire complète, et non seulement d’une partie de celle-ci.
Prenons une table des détails de commande dont la clé est une combinaison de l’ID de commande et de l’ID de produit. Si vous stockez le nom du produit dans cette table, vous avez une dépendance partielle. Le nom du produit dépend uniquement de l’ID du produit, et non de l’ID de commande. Pour corriger cela, vous déplacez le nom du produit vers une table distincte des Produits. Cela réduit les anomalies de mise à jour ; si le nom d’un produit change, vous le mettez à jour à un seul endroit, et non sur des milliers d’enregistrements de commandes.
Troisième forme normale (3NF)
La 3NF est souvent considérée comme le point idéal pour la plupart des systèmes opérationnels. Une table est en 3NF si :
- Il est en 2NF.
- Il n’y a pas de dépendances transitives. Les attributs non clés doivent dépendre uniquement de la clé primaire.
Une dépendance transitive se produit lorsque la colonne A détermine la colonne B, et que la colonne B détermine la colonne C. Dans une base de données, si l’ID client détermine la ville, et que la ville détermine la région, le stockage de la région dans la table client crée une dépendance transitive. Si la région change pour cette ville, vous devez mettre à jour chaque enregistrement client de cette ville. Normaliser cela déplace les données de région vers un emplacement distinct, garantissant que les mises à jour n’ont lieu qu’une seule fois.
📉 Le coût des performances de la normalisation stricte
Bien que la 3NF minimise la redondance, elle maximise le nombre de tables. Dans un schéma normalisé, la récupération d’un seul enregistrement logique nécessite souvent la jointure de plusieurs tables. Ce processus a un coût computationnel.
- Surcharge des jointures : Chaque opération de jointure nécessite que le moteur de base de données corresponde les lignes provenant de différentes tables. À mesure que les tables deviennent plus grandes, ce processus de correspondance consomme du CPU et de la mémoire.
- Opérations d’E/S : Les données réparties sur de nombreuses tables nécessitent plus de lectures disque. Si les données ne sont pas correctement mises en cache, la latence de lecture augmente.
- Complexité : Les requêtes complexes avec de nombreuses jointures sont plus difficiles à optimiser et à maintenir. Elles sont également plus sujettes à des erreurs si le schéma change.
Pour les systèmes avec des charges d’écriture importantes, la normalisation est généralement le choix correct. Elle empêche la duplication des données et garantit qu’une mise à jour d’un fait unique se propage correctement. Cependant, pour les systèmes avec des charges de lecture importantes, le coût des jointures peut devenir un goulot d’étranglement.
🚀 La dénormalisation stratégique : quand briser les règles
La dénormalisation consiste à introduire intentionnellement de la redondance afin d’optimiser les performances. Ce n’est pas une erreur ; c’est une décision architecturale délibérée prise lorsque le coût de la normalisation dépasse ses avantages.
Déclencheurs de la dénormalisation
Vous devriez envisager de relâcher les règles de normalisation lorsque :
- Les opérations de lecture dominent : Si votre application est fortement orientée lecture (par exemple, un tableau de bord de reporting), réduire les jointures peut réduire significativement la latence.
- La complexité des requêtes est élevée : Si les utilisateurs doivent extraire des données provenant de 10 tables ou plus pour afficher une seule page, la requête devient lente et difficile à déboguer.
- La fréquence des écritures est faible : Si les données sont rarement mises à jour, le risque d’incohérence provenant de la redondance est minimisé.
- Des contraintes matérielles existent : Dans les environnements où les E/S disque sont coûteuses ou limitées, le cache de données redondantes peut réduire les lectures physiques.
Stratégies courantes de dénormalisation
- Expansion de colonnes : Stocker une valeur dérivée directement dans une table. Par exemple, ajouter une colonne « Prix total » dans la table de commande, calculée à partir des lignes de commande, afin de ne pas devoir les additionner à chaque lecture.
- Clés étrangères redondantes : Ajouter un ID parent à une table enfant pour éviter une jointure lors de la récupération de la hiérarchie.
- Tables de résumé : Pré-calculer les agrégats (comptages, sommes) dans une table séparée qui est mise à jour périodiquement ou via des déclencheurs.
- Vues matérialisées :Stocker le résultat d’une requête complexe sous forme de table physique qui se rafraîchit selon un planning.
📊 Comparaison : Normalisation vs. Dénormalisation
Pour visualiser les compromis, considérez le tableau de comparaison suivant.
| Aspect | Haute normalisation (3NF+) | Conception dénormalisée |
|---|---|---|
| Intégrité des données | Élevée – source unique de vérité | Moins élevée – nécessite une logique de synchronisation |
| Utilisation du stockage | Efficace – pas de doublons | Inefficace – données redondantes |
| Performance d’écriture | Rapide – mise à jour d’une seule ligne | Plus lente – mise à jour de plusieurs lignes |
| Performance de lecture | Plus lente – nécessite des jointures | Rapide – accès direct |
| Complexité des requêtes | Élevée – de nombreuses jointures nécessaires | Faible – requêtes simples |
| Effort de maintenance | Faible – mise à jour une fois | Élevé – synchronisation à plusieurs endroits |
Ce tableau met en évidence qu’il n’existe pas de meilleure pratique universelle. Le choix dépend entièrement de la charge de travail spécifique de l’application.
🛠️ Cadre décisionnel pour la conception de schéma
Pour déterminer le bon niveau de normalisation pour votre projet spécifique, utilisez ce cadre décisionnel. Évaluez chaque point par rapport aux exigences de votre projet.
1. Analysez le modèle d’utilisation
Identifiez le ratio des lectures par rapport aux écritures. Si votre système est OLTP (traitement en ligne des transactions), privilégiez l’intégrité et la 3NF. Si c’est OLAP (traitement analytique en ligne), privilégiez la vitesse de lecture et envisagez la dénormalisation.
2. Évaluez les exigences de fraîcheur des données
Les données doivent-elles être en temps réel ? Si vous dénormalisez, vous introduisez un délai entre une mise à jour source et le changement reflété dans les données redondantes. Si vos utilisateurs ont besoin d’une cohérence immédiate, une normalisation stricte est plus sûre.
3. Évaluez la fréquence des mises à jour
Examinez les clés primaires. Si une table de référence (comme une liste de pays) change rarement, dénormaliser ses données dans des tables transactionnelles est sans risque. Si une table de référence change fréquemment, gardez-la séparée afin de minimiser les erreurs de synchronisation.
4. Prenez en compte le matériel et le cache
Les bases de données modernes stockent souvent les données en mémoire. Si votre ensemble de travail tient en RAM, le coût des jointures diminue. Dans ce cas, vous pouvez vous permettre un schéma légèrement plus normalisé sans sacrifier les performances.
🧠 Normalisation avancée : forme normale de Boyce-Codd (BCNF) et forme normale de quatrième (4NF)
Au-delà de la 3NF, il existe des formes supérieures telles que la forme normale de Boyce-Codd (BCNF) et la quatrième forme normale (4NF). Elles traitent des cas particuliers spécifiques.
Forme normale de Boyce-Codd (BCNF)
La BCNF est une version plus stricte de la 3NF. Elle traite les cas où un attribut non premier détermine un autre attribut non premier, même si la clé primaire est composite. Bien qu’elle soit théoriquement parfaite, la BCNF peut parfois entraîner une perte de préservation des dépendances. En pratique, la 3NF est souvent suffisante, et forcer la BCNF peut parfois compliquer le schéma sans ajouter de valeur significative.
Quatrième forme normale (4NF)
La 4NF traite des dépendances multivaluées. Cela se produit lorsque d’une seule ligne contient plusieurs listes indépendantes de valeurs. Par exemple, une table d’élèves stockant plusieurs loisirs et plusieurs cours dans la même ligne. Cela est rare dans les applications commerciales standard, mais courant dans des scénarios de modélisation de données spécialisés.
🚫 Pièges courants à éviter
Même avec une bonne compréhension de la normalisation, il est facile de commettre des erreurs. Évitez ces erreurs courantes :
- Sur-normalisation :Créer des centaines de petites tables pour des relations simples. Cela rend la logique de l’application difficile à suivre et ralentit le développement.
- Ignorer les index :Un schéma normalisé nécessite des jointures. Si les colonnes de jointure ne sont pas indexées, les performances se dégraderont, quel que soit le design du schéma.
- Dénormaliser sans surveillance :Introduire de la redondance sans plan de synchronisation entraîne une corruption des données au fil du temps.
- Codage dur de la logique :Ne calculez pas les valeurs dérivées au niveau de la couche application si elles doivent être dans la base de données. Gardez les règles métier proches des données.
✅ Liste de contrôle pour la validation du schéma
Avant de déployer un nouveau schéma, passez-le par cette liste de contrôle de validation.
- Atomicité :Tous les champs sont-ils atomiques ?
- Clés primaires :Chaque table possède-t-elle une clé primaire unique ?
- Clés étrangères :Les relations sont-elles assurées par des clés étrangères ?
- Redondance :Y a-t-il des groupes de données évidents qui se répètent ?
- Nombre de jointures :Les requêtes critiques nécessitent-elles plus de 3 à 4 jointures ?
- Chemin de mise à jour :Peut-on effectuer un changement de données en un seul endroit ?
🔗 Conclusion sur l’architecture des données
La normalisation est un outil, pas un manuel. Elle existe pour protéger vos données contre les incohérences, mais elle ne doit pas empêcher votre application de fonctionner efficacement. La « vérité » sur la normalisation des modèles entité-association est qu’elle constitue un spectre. Vous commencez par une structure fortement normalisée pour garantir l’intégrité, puis vous dénormalisez de manière sélective en fonction des besoins de performance.
Il n’existe pas de solution universelle. Un système de trading à haute fréquence aura un aspect très différent d’un système de gestion de contenu. L’essentiel est de comprendre les mécanismes fondamentaux des dépendances et des jointures. En équilibrant le coût du stockage contre celui du calcul, vous pouvez construire des systèmes à la fois fiables et rapides.
En continuant à concevoir, rappelez-vous que l’évolution du schéma est inévitable. Prévoyez les changements. Utilisez la versioning pour vos migrations de base de données. Et testez toujours vos requêtes sous charge avant de prendre une décision structurelle. Le meilleur schéma est celui qui soutient vos objectifs commerciaux sans devenir un goulot d’étranglement.