











Construire un système capable de gérer des millions d’utilisateurs exige plus que des matériels puissants ou un code efficace. La fondation réside dans la structure des données elle-même. Un diagramme d’entité-association (ERD) n’est pas simplement un document de documentation ; c’est le plan directeur pour la pérennité de votre application. Lorsque les architectes conçoivent pour la croissance, ils anticipent la charge future, la complexité des relations et la nécessité d’intégrité des données. Un schéma bien conçu empêche l’accumulation de dette technique avant même le premier commit.
Ce guide explore comment aborder la conception des diagrammes d’entité-association spécifiquement dans des environnements évolutifs. Nous aborderons les fondements théoriques, les compromis pratiques et les modèles structurels qui soutiennent les systèmes à haut débit sans compromettre la cohérence.
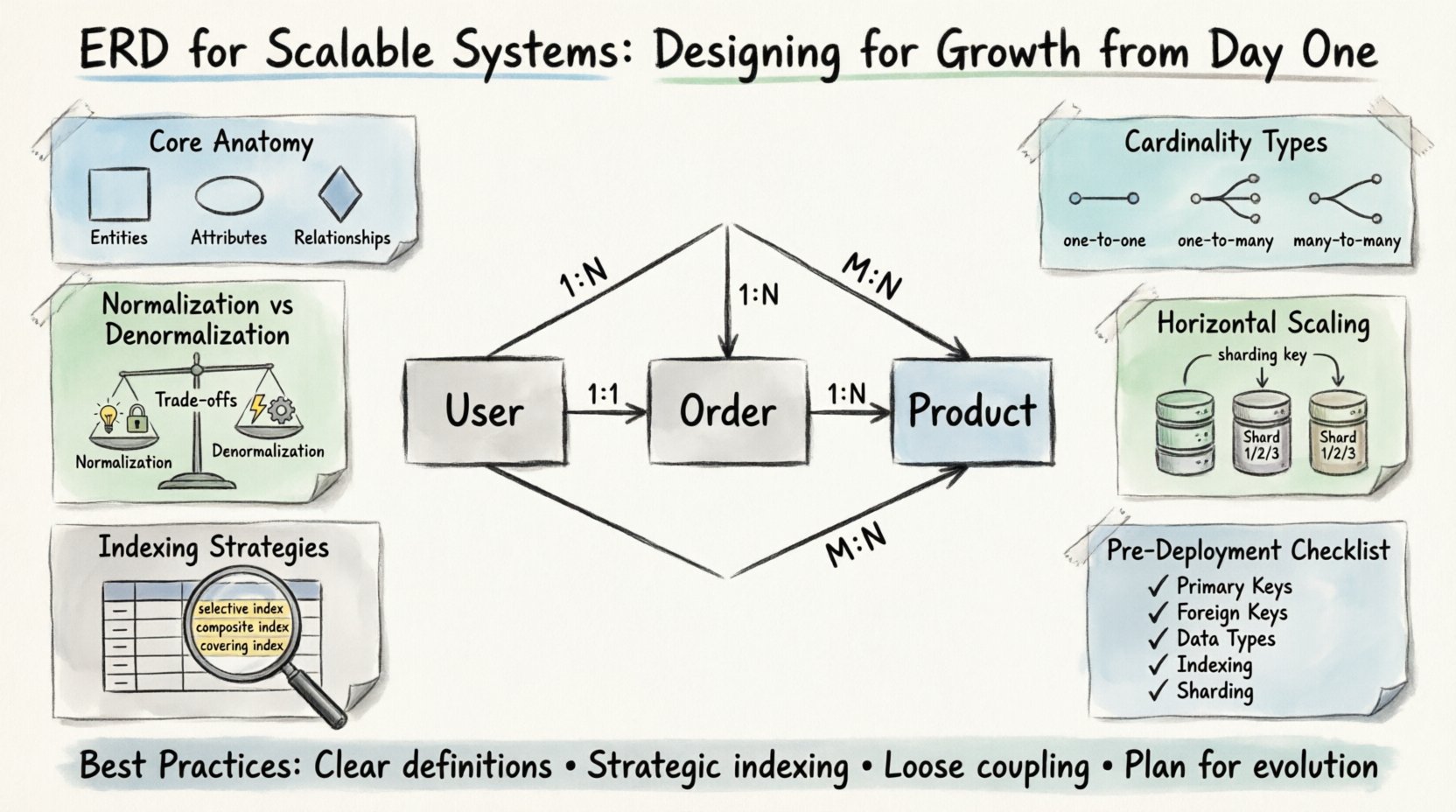
🧩 L’anatomie fondamentale d’un ERD évolutif
Avant de considérer l’évolutivité, il faut comprendre les blocs de construction fondamentaux. Chaque diagramme se compose d’entités, d’attributs et de relations. Dans un contexte évolutif, ces éléments doivent être définis avec précision pour éviter les goulets d’étranglement ultérieurement.
- Entités : Elles représentent les objets centraux de votre domaine métier. Des exemples incluent les Utilisateurs, les Commandes et les Produits. Dans les systèmes à croissance rapide, les entités doivent être suffisamment granulaires pour permettre un dimensionnement indépendant, mais assez cohérentes pour maintenir des frontières logiques.
- Attributs : Ce sont les propriétés qui décrivent les entités. Les types de données sont cruciaux ici. Le choix du bon type affecte l’efficacité du stockage et les performances des requêtes. Par exemple, utiliser un type entier dédié pour les identifiants est préférable aux chaînes de caractères pour les opérations d’indexation.
- Relations : Elles définissent la manière dont les entités interagissent. La cardinalité est l’aspect le plus important à définir dès le départ. Interpréter une relation un-à-plusieurs comme une relation plusieurs-à-plusieurs peut entraîner des jointures inutiles et une dégradation sévère des performances.
📐 Comprendre la cardinalité et les contraintes
La cardinalité détermine le nombre d’instances d’une entité qui peuvent ou doivent être liées à des instances d’une autre entité. Dans les systèmes évolutifs, le choix de la cardinalité détermine souvent la manière dont les données sont partitionnées.
- Un-à-un (1:1) : Peu utilisé pour l’optimisation des performances. Souvent implique la séparation d’une grande entité afin de réduire les conflits d’accès. À utiliser uniquement lorsque les modèles d’accès aux données sont strictement distincts.
- Un-à-plusieurs (1:N) : La relation la plus courante. Un Utilisateur a plusieurs Commandes. Cette structure permet un indexage efficace du côté clé étrangère, permettant une récupération rapide des enregistrements associés.
- Plusieurs-à-plusieurs (M:N) : Nécessite une table de jonction. Bien qu’élargie, elle peut devenir un goulot d’étranglement des performances à mesure que le volume de données augmente. Pensez à la dénormalisation ou aux vues matérialisées si la fréquence de lecture est élevée.
Lors de la définition des contraintes, considérez le surcoût de leur application. Dans les systèmes distribués, appliquer des contraintes de clés étrangères strictes à travers des shards peut introduire une latence. Dans de tels cas, une validation au niveau de l’application peut être nécessaire pour maintenir le débit du système tout en préservant l’intégrité des données.
⚖️ Normalisation vs. compromis performance
La normalisation réduit la redondance et améliore l’intégrité des données. Toutefois, les systèmes à haute performance exigent souvent un écart par rapport aux règles strictes de normalisation. Comprendre les couches aide à prendre des décisions éclairées.
- Première forme normale (1NF) : Valeurs atomiques. Assure que chaque cellule contient une seule valeur. Cela est impératif pour l’intégrité relationnelle.
- Deuxième forme normale (2NF) : Pas de dépendance partielle. Tous les attributs non clés doivent dépendre de la clé primaire entière. Utile pour réduire les anomalies de mise à jour.
- Troisième forme normale (3NF) : Pas de dépendance transitive. Les attributs non clés ne doivent pas dépendre d’autres attributs non clés. C’est la cible standard pour la plupart des systèmes transactionnels.
Bien que la 3NF soit idéale pour la cohérence, elle nécessite souvent des jointures complexes. Dans les systèmes à forte lecture, joindre plusieurs tables peut surcharger le moteur de base de données. La dénormalisation consiste à dupliquer des données afin de réduire le besoin de jointures. Cela augmente la complexité des écritures, mais accélère considérablement les lectures.
📊 Comparaison entre normalisation et dénormalisation
| Fonctionnalité | Normalisé (3NF) | Dénormalisé |
|---|---|---|
| Intégrité des données | Élevée (source unique de vérité) | Moins élevée (nécessite une logique de synchronisation) |
| Performance d’écriture | Plus rapide (moins de données écrites) | Plus lent (écritures redondantes) |
| Performance de lecture | Plus lent (nécessite des jointures) | Plus rapide (accès direct) |
| Utilisation du stockage | Efficace | Plus élevé (redondance) |
| Cas d’utilisation | Systèmes transactionnels (OLTP) | Reporting et analyse (OLAP) |
🚀 Conception pour le dimensionnement horizontal
À mesure que le volume de données augmente, un seul nœud de base de données devient un goulot d’étranglement. Le dimensionnement horizontal consiste à ajouter plus de nœuds pour répartir la charge. Votre schéma ER doit supporter cette architecture dès le départ.
- Clés de fractionnement : Identifiez une colonne qui permet de répartir les données de manière équilibrée entre les fragments. Cette colonne doit être présente dans chaque requête qui accède aux données. Si une requête nécessite le balayage de tous les fragments, les performances seront compromises.
- Clés étrangères entre les fragments : La jointure de tables situées sur des fragments différents est coûteuse en termes de calcul. Minimisez les relations entre fragments pendant la phase de conception. Si une relation est nécessaire, envisagez de mettre en cache les données de référence.
- Identifiants globaux : Utilisez des identifiants uniques qui ne dépendent pas des compteurs auto-incrémentés, car ceux-ci peuvent entraîner des conflits. Les UUID ou les générateurs d’identifiants distribués sont préférés.
Lors de la modélisation pour le fractionnement, tenez compte de la répartition des données. Les points chauds surviennent lorsque un fragment reçoit significativement plus de trafic que les autres. Analysez les modèles d’accès pour vous assurer que la clé de fractionnement correspond aux filtres de requête les plus fréquents.
📑 Stratégies d’indexation pour les grands ensembles de données
Les index sont essentiels pour les performances des requêtes, mais ils ont un coût. Chaque index consomme de l’espace de stockage et ralentit les opérations d’écriture. Une approche stratégique de l’indexation est vitale.
- Index sélectifs : Créez des index sur les colonnes qui filtrent les données de manière significative. Une colonne à faible cardinalité (par exemple, le sexe) est souvent un mauvais candidat pour un index principal.
- Index composés : Combinez plusieurs colonnes dans un ordre qui correspond aux modèles de requête. La règle du préfixe gauche s’applique, ce qui signifie que la première colonne de l’index doit correspondre à la requête pour que l’index soit utilisé efficacement.
- Index couvrants : Incluez toutes les colonnes nécessaires à une requête directement dans l’index. Cela permet à la base de données de répondre à la requête sans accéder aux données de la table, ce qu’on appelle une opération « couvrante ».
- Index partiels : Indexez uniquement un sous-ensemble des lignes de la table. Cela est utile pour les suppressions douces ou des indicateurs d’état spécifiques, ce qui réduit la taille de la structure d’index.
Revoyez régulièrement les plans d’exécution des requêtes. Un index qui semble bon sur papier peut être ignoré par l’optimiseur de requêtes si les statistiques sont obsolètes. Une maintenance régulière garantit que le moteur de base de données prend des décisions optimales.
🔄 Évolution et migrations de schéma
Les systèmes ne sont pas statiques. Les exigences évoluent, et le modèle de données doit évoluer également. Passer de la version A à la version B sans interruption est une compétence essentielle.
- Modifications additives :Ajouter une colonne ou une table est généralement sans risque. Cela n’interrompt pas les requêtes existantes. C’est la méthode préférée pour introduire de nouvelles fonctionnalités.
- Opérations de renommage :Renommer une colonne est risqué. Cela nécessite de mettre à jour le code de l’application. Prévoyez une période de dépréciation durant laquelle les anciens et nouveaux noms seront pris en charge.
- Ajout de contraintes :Ajouter une contrainte (comme NOT NULL) aux données existantes peut échouer si des données existent déjà. Validez d’abord les données, puis ajoutez la contrainte en une étape séparée.
- Compatibilité descendante :Assurez-vous que les nouvelles versions de schéma n’interrompent pas les clients existants. Utilisez des indicateurs de fonctionnalité pour activer la nouvelle logique uniquement lorsque le schéma est prêt.
🚫 Pièges courants à éviter
Même les concepteurs expérimentés rencontrent des problèmes. Reconnaître ces schémas tôt peut économiser un temps ingénieux.
- Couplage étroit :Créer des relations qui imposent une synchronisation stricte entre des entités sans lien. Gardez les modules faiblement couplés pour permettre un déploiement indépendant.
- Surconception :Concevoir pour des scénarios qui pourraient ne jamais se produire. Concentrez-vous sur les 80 % des cas d’utilisation qui génèrent 90 % du trafic. La simplicité facilite la maintenance.
- Ignorer les suppressions douces :Les suppressions rigides suppriment les données de manière permanente. Pour les journaux d’audit ou la récupération, utilisez un indicateur d’état (par exemple, is_deleted) plutôt que la suppression physique.
- Problèmes de requêtes N+1 :Ne pas anticiper la manière dont les données seront récupérées. Prévoyez le chargement eager ou le chargement par lots au niveau de la couche d’accès aux données pour éviter des allers-retours excessifs vers la base de données.
✅ Liste de vérification de conception avant déploiement
Avant de finaliser le schéma, passez en revue cette liste de vérification pour vous assurer de la préparation à l’échelle.
- ☐ Clés primaires :Toutes les tables sont-elles équipées d’une clé primaire unique et indexée ?
- ☐ Clés étrangères :Les relations sont-elles correctement définies ? La cardinalité est-elle précise ?
- ☐ Types de données :Les types numériques sont-ils utilisés pour les identifiants et les montants ? Les types de date sont-ils standardisés ?
- ☐ Nullabilité :Les champs obligatoires sont-ils marqués comme NOT NULL ?
- ☐ Indexation :Les colonnes des requêtes à fort trafic sont-elles indexées ?
- ☐ Fractionnement (sharding) :Existe-t-il une clé de fractionnement viable si une mise à l’échelle horizontale est prévue ?
- ☐ Contraintes :Les contraintes sont-elles nécessaires pour la logique métier, ou peuvent-elles être gérées au niveau de la couche application ?
- ☐ Documentation :Le schéma ERD est-il mis à jour pour refléter l’implémentation finale ?
🛡️ Intégrité des données dans les environnements distribués
Dans une configuration distribuée, il est plus difficile de garantir les propriétés ACID (Atomicité, Cohérence, Isolation, Durabilité) à travers les nœuds. Comprendre les implications pour votre schéma ERD est crucial.
- Cohérence éventuelle :Acceptez que les données puissent être temporairement incohérentes entre les réplicas. Concevez votre application pour gérer cet état de manière fluide.
- Idempotence :Assurez-vous que les opérations peuvent être répétées sans effets secondaires. Cela est essentiel en cas d’échecs réseau où une écriture pourrait réussir mais où l’accusé de réception est perdu.
- Résolution des conflits : Définissez comment gérer les mises à jour simultanées du même enregistrement. Les horodatages ou les horloges vectorielles peuvent aider à déterminer la version la plus récente.
En intégrant ces considérations dans votre diagramme d’entités et de relations, vous créez un système qui est non seulement fonctionnel aujourd’hui, mais suffisamment robuste pour demain. Le coût de la modification d’un schéma en production est exponentiellement plus élevé que la conception correcte dès le départ.
🔍 Résumé des meilleures pratiques
Pour résumer, une montée en charge réussie repose sur une approche rigoureuse de la modélisation des données. Concentrez-vous sur des définitions claires, une normalisation appropriée et un indexage stratégique. Évitez les raccourcis qui compromettent l’intégrité des données. Revoyez régulièrement vos diagrammes au fur et à mesure de l’évolution du système. Un ERD statique est une charge ; un modèle vivant est un atout.
Investissez du temps dans la phase de conception. Cela vous rapportera en réduisant les coûts de maintenance et en améliorant la fiabilité du système. Vos utilisateurs ne verront jamais le diagramme, mais ils ressentiront les performances du système qu’il soutient.