











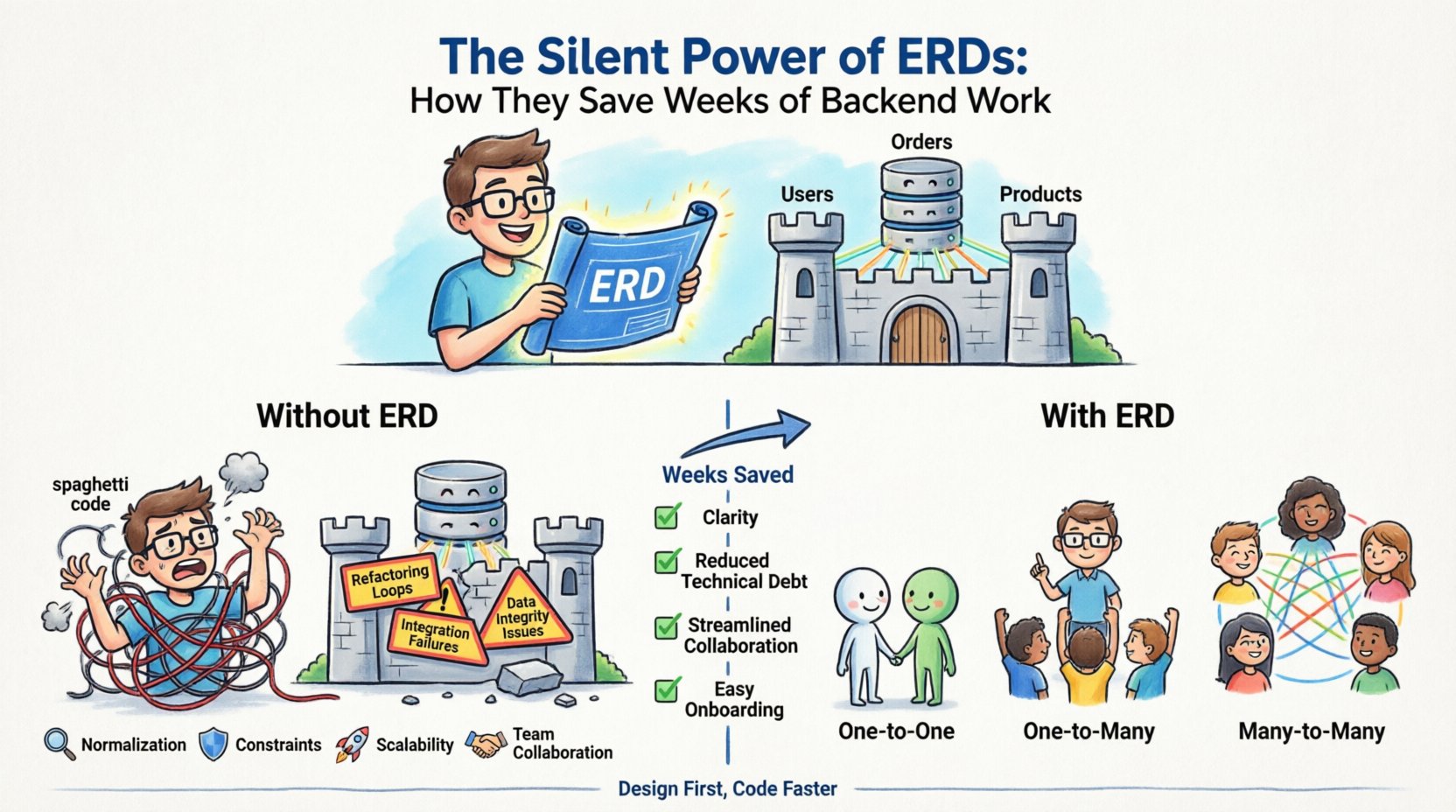
Le développement côté serveur ressemble souvent à la construction d’une maison sans plan. Vous commencez à poser des briques, à ajouter des fenêtres et à construire des murs selon votre intuition. Parfois, cela fonctionne. Souvent, non. Des semaines plus tard, vous vous retrouvez à démolir des murs pour intégrer une porte que vous aviez oubliée de prévoir. Voilà la réalité du développement sans un solideDiagramme d’entité-association (ERD). Le diagramme ER est l’architecte silencieux de votre infrastructure de données, opérant en coulisses pour éviter les échecs structurels coûteux. En investissant du temps à concevoir votre modèle de données avant d’écrire la moindre ligne de code, vous gagnez en clarté, réduisez la dette technique et facilitez la collaboration entre les équipes.
Ce guide explore l’impact concret des diagrammes ER sur les flux de travail côté serveur. Nous analyserons les mécanismes du modélisation des données, les coûts cachés liés à l’omission de la conception, et les avantages stratégiques d’un schéma bien documenté. En comprenant ces principes, vous pourrez passer du développement réactif à une architecture proactive.
Qu’est-ce qu’un diagramme ER exactement ? 📐
Un diagramme d’entité-association est une représentation visuelle de la structure logique d’une base de données. Il montre comment les différentes pièces de données sont liées entre elles. Pensez-y comme une carte pour la mémoire de votre application. Sans cette carte, les développeurs s’orientent à l’aveugle, risquant des collisions entre des points de données qui devraient rester distincts.
Au cœur de tout diagramme ER se trouvent trois composants principaux :
- Entités : Elles représentent les objets ou les concepts que vous suivez. Dans une base de données, elles se traduisent par des tables. Des exemples incluentUtilisateurs, Commandes, ouProduits.
- Attributs : Ce sont les propriétés spécifiques d’une entité. Elles deviennent les colonnes de vos tables. Pour une entitéUtilisateur , les attributs pourraient inclureemail, mot_de_passe_haché, etcréé_le.
- Relations : Elles définissent la manière dont les entités interagissent. Elles déterminent la cardinalité et la connectivité entre les tables, comme unUtilisateur ayant plusieursCommandes.
Bien que le concept semble simple, la complexité apparaît lors de la gestion à grande échelle. Un simple blog n’a peut-être besoin que de quelques tables. Un système d’entreprise nécessite des dizaines, voire des centaines, d’entités interconnectées. Le schéma ERD agit comme la source unique de vérité pour toutes ces interactions.
Le coût caché de sauter la conception 💸
De nombreuses équipes de développement se précipitent vers le code pour respecter les délais. Elles supposent qu’elles pourront refactoriser la base de données plus tard. C’est une supposition dangereuse. Modifier un schéma de base de données est nettement plus coûteux que modifier la logique de l’application. Une fois les données écrites, modifier leur structure nécessite des scripts de migration, des temps d’arrêt potentiels et une gestion soigneuse des enregistrements existants.
Pensez aux scénarios suivants où l’absence d’un schéma ERD crée des frictions :
- Boucles de refactorisation : Vous développez une fonctionnalité, réalisez que la structure des données ne la supporte pas, et devez réécrire les requêtes. Ce cycle se répète, consommant des semaines de temps de sprint.
- Échecs d’intégration : Lorsque les équipes frontend et backend travaillent sans définition de schéma partagée, les API cassent souvent. Le backend envoie une structure ; le frontend s’attend à une autre.
- Problèmes d’intégrité des données : Sans contraintes définies, des données invalides entrent dans le système. Vous finissez par nettoyer manuellement des enregistrements orphelins ou corriger des états incohérents.
- Délais d’intégration : Les nouveaux développeurs peinent à comprendre le système. Ils passent des jours à lire le code au lieu de développer des fonctionnalités, car le flux de données n’est pas documenté.
Au moment où vous remarquez le problème, le coût s’est accumulé. La « correction » exige désormais non seulement des modifications de code, mais aussi une migration des données, des tests et une vérification du déploiement.
Cartographier les relations comme un pro 🔗
Comprendre comment les données sont connectées est le cœur de la conception d’un schéma ERD. Les relations déterminent la manière dont les requêtes sont écrites et comment les performances sont optimisées. Il existe trois types principaux de relations que vous devez définir clairement.
Le tableau ci-dessous décrit les différences entre ces types de relations :
| Type de relation | Définition | Scénario d’exemple | Note d’implémentation |
|---|---|---|---|
| Un à un (1:1) | Un seul enregistrement dans la table A est lié à exactement un enregistrement dans la table B. | Un profil utilisateur lié à une table de paramètres utilisateur. | Souvent implémenté en plaçant la clé primaire de B dans A. |
| Un à plusieurs (1:N) | Un seul enregistrement dans la table A est lié à plusieurs enregistrements dans la table B. | Une catégorie contenant plusieurs produits. | Placement standard de la clé étrangère dans la table du côté « plusieurs ». |
| Many-to-Many (M:N) | Plusieurs enregistrements dans la table A sont liés à plusieurs enregistrements dans la table B. | Des étudiants inscrits à plusieurs cours. | Nécessite une table de jonction pour résoudre le lien. |
Ignorer ces distinctions entraîne des requêtes inefficaces. Par exemple, stocker une liste d’identifiants de produits dans une seule colonne pour une catégorie viole les principes de normalisation. Cela vous oblige à analyser des chaînes de caractères au lieu d’utiliser des jointures, ce qui ralentit les performances à mesure que les données augmentent.
Normalisation : garder les données propres 🧹
La normalisation est le processus d’organisation des données afin de réduire la redondance et d’améliorer l’intégrité. Bien que les systèmes modernes dévient parfois de la normalisation stricte pour des raisons de performance, comprendre ces principes reste essentiel.
Les formes standards de normalisation incluent :
- Première forme normale (1NF) : Assure l’atomicité. Chaque colonne contient une seule valeur. Aucune liste ou tableau dans une seule cellule.
- Deuxième forme normale (2NF) : S’appuie sur le 1NF. Exige que toutes les attributs non clés soient pleinement dépendants de la clé primaire. Aucune dépendance partielle.
- Troisième forme normale (3NF) : S’appuie sur le 2NF. Exige que les attributs non clés dépendent uniquement de la clé primaire, et non d’autres attributs non clés.
Pourquoi cela importe-t-il ? Pensez à une Commande table. Si vous stockez le Nom du client dans chaque ligne de commande, vous créez une redondance. Si le client change de nom, vous devez mettre à jour des milliers de lignes. Si vous en oubliez une, vos données deviennent incohérentes. En déplaçant Nom du client vers une Clients table et en le liant via l’ID, vous vous assurez d’une source unique de vérité.
Cependant, la normalisation n’est pas une solution miracle. Une sur-normalisation peut entraîner des jointures complexes qui nuisent aux performances. L’objectif est l’équilibre. Vous devez comprendre les compromis entre l’efficacité du stockage et la vitesse des requêtes.
Péchés courants dans la conception de schémas 🚧
Même les développeurs expérimentés commettent des erreurs lors de la conception des modèles entité-relation. Reconnaître ces pièges courants peut vous épargner de graves soucis plus tard.
- Dépendances circulaires : L’entité A a besoin de l’entité B, et l’entité B a besoin de l’entité A. Cela crée un blocage lors de l’initialisation et rend la rédaction des scripts de migration difficile.
- Contraintes manquantes : Oublier de définir des clés étrangères, des contraintes uniques ou des contraintes de vérification permet à des données invalides de passer inaperçues. La base de données doit imposer les règles, et non le code de l’application.
- Valeurs codées en dur :Le stockage des codes d’état comme « actif » ou « inactif » sous forme d’entiers sans table de correspondance rend le système fragile. Si vous devez ajouter « suspendu », vous devez modifier la logique partout.
- Ignorer les suppressions douces :Supprimer les données de manière permanente efface l’historique. Concevoir pour des suppressions douces (marquer un enregistrement comme supprimé au lieu de l’effacer) préserve les traces d’audit.
- Surconception :Concevoir pour un cas d’utilisation qui n’existe pas encore. Construisez pour les besoins actuels, mais assurez-vous que le schéma est suffisamment souple pour gérer une croissance raisonnable.
Chacun de ces pièges ajoute des couches de complexité à votre base de code. Un MCD vous aide à visualiser ces problèmes avant qu’ils ne soient intégrés en production.
Du schéma à la mise en œuvre 🚀
Une fois le MCD finalisé, la prochaine étape consiste à le traduire en code. Ce processus, souvent appelé migration de schéma, exige une discipline.
Suivez ces étapes pour assurer une transition fluide :
- Contrôle de version :Traitez votre schéma de base de données comme du code d’application. Chaque modification doit être un fichier de migration stocké dans votre référentiel.
- Compatibilité descendante :Lors de l’ajout d’une colonne, rendez-la d’abord nullable. Remplissez les données existantes, puis imposez la contrainte dans une migration ultérieure. Cela évite les temps d’arrêt.
- Test des migrations :Exécutez les scripts de migration dans un environnement de préproduction identique à la production. Vérifiez les régressions de performance.
- Plans de retour en arrière :Disposez toujours d’un moyen d’annuler une migration en cas d’échec. La perte de données est inacceptable.
Les outils d’automatisation peuvent aider à générer du SQL à partir de MCD, mais une revue manuelle est cruciale. Les générateurs automatiques manquent souvent des subtilités de logique métier que capturerait un architecte humain.
Collaboration et communication 🤝
Un MCD n’est pas seulement destiné aux administrateurs de bases de données. Il sert d’outil de communication pour toute l’équipe. Les chefs de produit, les développeurs frontend et les ingénieurs QA tirent tous profit de la compréhension de la structure des données.
Lorsque les parties prenantes examinent le MCD, ils peuvent repérer des problèmes potentiels tôt :
- Faisabilité des fonctionnalités :La base de données peut-elle supporter la fonctionnalité demandée ? Si non, quelles modifications sont nécessaires ?
- Attentes de performance :Le design permet-il des requêtes efficaces à grande échelle ?
- Exigences de sécurité :Les champs sensibles sont-ils identifiés et protégés ? Le contrôle d’accès est-il réalisable au niveau des données ?
Cette compréhension partagée réduit les frictions lors de la planification des sprints. Au lieu de deviner le flux des données, l’équipe en discute à partir d’un modèle visuel. Les désaccords sont résolus en se référant au schéma plutôt qu’à l’opinion.
Considérations sur la scalabilité 📈
À mesure que votre application grandit, votre modèle de données doit évoluer. Un schéma ER vous aide à anticiper ces changements. Il vous permet de visualiser comment l’ajout d’une nouvelle entité affecte les relations existantes.
Principaux facteurs d’évolutivité à prendre en compte lors de la conception :
- Stratégie d’indexation :Identifiez les colonnes qui seront fréquemment interrogées. Prévoyez des index sur ces champs pour accélérer la récupération.
- Partitionnement :Certaines tables risquent-elles de devenir trop grandes ? Prévoyez un partitionnement horizontal si nécessaire.
- Séparation lecture/écriture :Le design supporte-t-il des réplicas distincts pour les lectures et les écritures ? Assurez-vous que les clés étrangères n’ajoutent pas de complexité à la réplication.
- Niveaux de mise en cache :Comment le modèle de données interagit-il avec les systèmes de mise en cache ? Les données immuables sont plus faciles à mettre en cache que les données qui changent fréquemment.
Penser à l’évolutivité dès le départ évite la nécessité d’une refonte complète plus tard. Il est plus facile d’ajouter une nouvelle table que de déplacer des données d’un serveur à un autre.
Réflexions finales sur l’architecture des données 🧠
Les efforts consacrés à la création d’un schéma ER détaillé rapportent des bénéfices tout au long du cycle de vie d’un projet. Il transforme la modélisation des données d’une tâche réactive en un atout stratégique. En visualisant les relations, en imposant des contraintes et en planifiant la croissance, vous construisez des systèmes robustes et maintenables.
Ne traitez pas la base de données comme un après-pensé. Elle est la fondation de votre application. Investissez dans la phase de conception, et vous économiserez des semaines de travail côté backend à long terme. Le pouvoir silencieux du schéma ER réside dans sa capacité à prévenir les problèmes avant même qu’ils ne surviennent.
Commencez à cartographier vos données dès aujourd’hui. La clarté que vous gagnerez fera la différence entre un codebase chaotique et un système optimisé.