











Membangun sistem yang dapat menangani jutaan pengguna membutuhkan lebih dari sekadar perangkat keras yang kuat atau kode yang efisien. Fondasi sebenarnya terletak pada struktur data itu sendiri. Diagram Hubungan Entitas (ERD) bukan sekadar dokumen dokumentasi; ia adalah gambaran rancangan untuk kelangsungan hidup aplikasi Anda. Ketika arsitek merancang untuk pertumbuhan, mereka memprediksi beban di masa depan, kompleksitas hubungan, dan kebutuhan integritas data. Skema yang dibuat dengan baik mencegah utang teknis menumpuk bahkan sebelum komit pertama dilakukan.
Panduan ini mengeksplorasi cara mendekati desain Diagram Hubungan Entitas khususnya untuk lingkungan yang dapat diperluas. Kami akan membahas dasar-dasar teoretis, pertimbangan praktis, serta pola struktural yang mendukung sistem dengan throughput tinggi tanpa mengorbankan konsistensi.
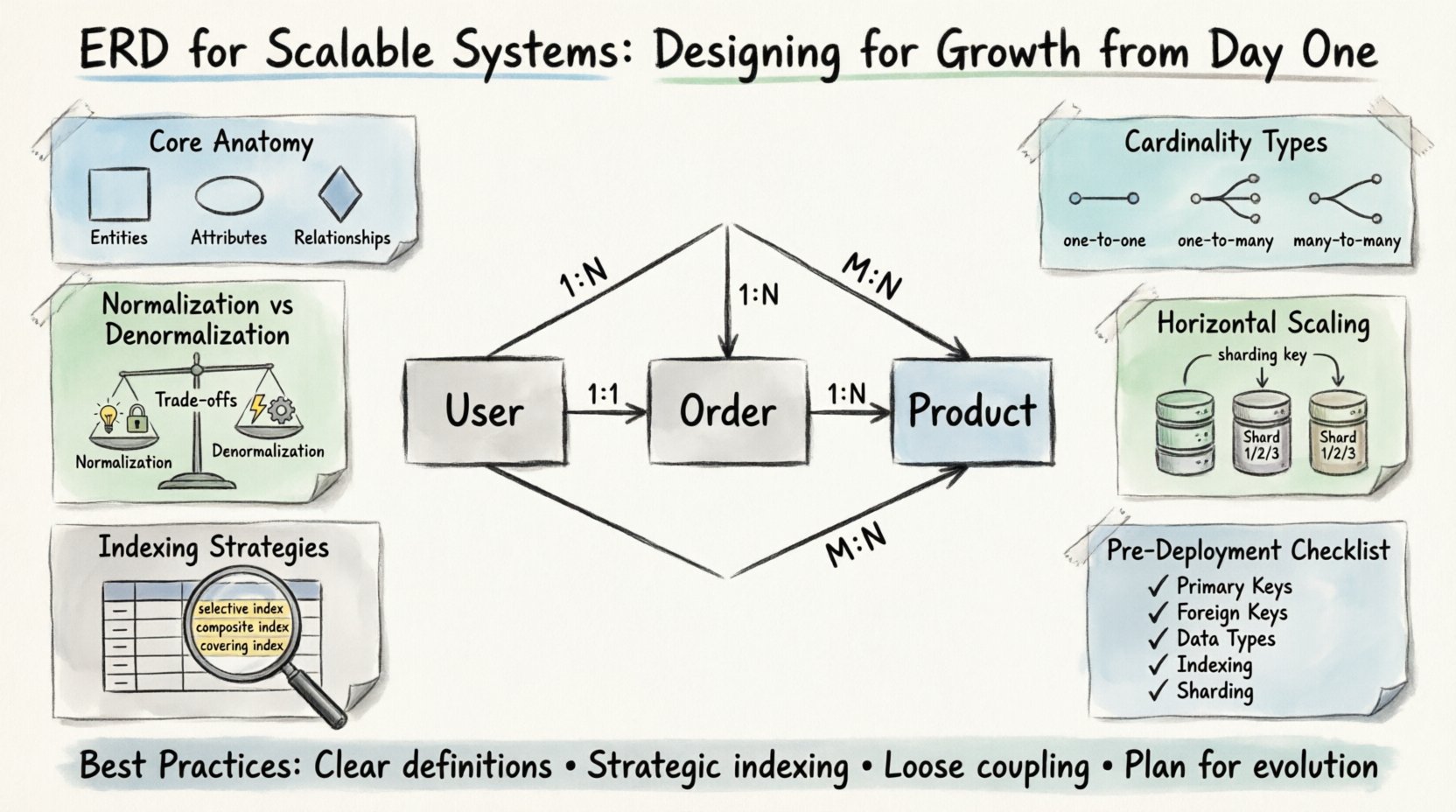
🧩 Anatomi Inti dari ERD yang Dapat Diperluas
Sebelum mempertimbangkan skala, seseorang harus memahami blok bangunan dasar. Setiap diagram terdiri dari entitas, atribut, dan hubungan. Dalam konteks yang dapat diperluas, elemen-elemen ini harus didefinisikan secara tepat untuk menghindari kemacetan di kemudian hari.
- Entitas: Ini mewakili objek inti dari domain bisnis Anda. Contohnya adalah Pengguna, Pesanan, dan Produk. Dalam sistem dengan pertumbuhan tinggi, entitas harus cukup halus untuk memungkinkan peningkatan skala secara independen, tetapi cukup terpadu untuk mempertahankan batas logis.
- Atribut: Ini adalah sifat-sifat yang menggambarkan entitas. Tipe data sangat penting di sini. Memilih tipe yang tepat memengaruhi efisiensi penyimpanan dan kinerja kueri. Sebagai contoh, menggunakan tipe bilangan bulat khusus untuk ID jauh lebih unggul daripada string untuk tujuan indeksing.
- Hubungan: Ini mendefinisikan bagaimana entitas berinteraksi. Kardinalitas adalah aspek paling penting yang harus didefinisikan sejak awal. Salah memahami hubungan satu-ke-banyak sebagai banyak-ke-banyak dapat menyebabkan penggabungan yang tidak perlu dan penurunan kinerja yang parah.
📐 Memahami Kardinalitas dan Kendala
Kardinalitas menentukan jumlah contoh satu entitas yang dapat atau harus terkait dengan contoh entitas lain. Dalam sistem yang dapat diperluas, pilihan kardinalitas sering menentukan bagaimana data dibagi.
- Satu-ke-Satu (1:1): Jarang digunakan untuk optimasi kinerja. Sering mengindikasikan pemisahan entitas besar untuk mengurangi kontensi kunci. Gunakan hanya jika pola akses data benar-benar berbeda.
- Satu-ke-Banyak (1:N): Hubungan yang paling umum. Seorang Pengguna memiliki banyak Pesanan. Struktur ini mendukung indeksing yang efisien di sisi kunci asing, memungkinkan pengambilan cepat catatan yang terkait.
- Banyak-ke-Banyak (M:N): Membutuhkan tabel sambungan. Meskipun fleksibel, hal ini dapat menjadi penghalang kinerja seiring volume data meningkat. Pertimbangkan denormalisasi atau tampilan yang dibuat secara material jika frekuensi baca tinggi.
Saat menentukan kendala, pertimbangkan beban pelaksanaannya. Dalam sistem terdistribusi, menerapkan kendala kunci asing yang ketat di seluruh shard dapat menimbulkan latensi. Dalam kasus seperti ini, validasi di tingkat aplikasi mungkin diperlukan untuk menjaga throughput sistem sambil tetap menjaga integritas data.
⚖️ Normalisasi vs. Pertimbangan Kinerja
Normalisasi mengurangi redundansi dan meningkatkan integritas data. Namun, sistem berkinerja tinggi sering kali membutuhkan penyimpangan dari aturan normalisasi yang ketat. Memahami lapisan-lapisan ini membantu dalam pengambilan keputusan yang bijak.
- Bentuk Normal Pertama (1NF): Nilai atomik. Memastikan setiap sel berisi satu nilai tunggal. Ini tidak dapat ditawar untuk menjaga integritas relasional.
- Bentuk Normal Kedua (2NF): Tidak ada ketergantungan parsial. Semua atribut non-kunci harus tergantung pada seluruh kunci utama. Berguna untuk mengurangi anomali pembaruan.
- Bentuk Normal Ketiga (3NF): Tidak ada ketergantungan transitif. Atribut non-kunci tidak boleh tergantung pada atribut non-kunci lainnya. Ini adalah target standar untuk sebagian besar sistem transaksional.
Meskipun 3NF ideal untuk konsistensi, sering kali membutuhkan penggabungan yang kompleks. Dalam sistem yang banyak membaca, menggabungkan beberapa tabel dapat membebani mesin basis data. Denormalisasi melibatkan penggandaan data untuk mengurangi kebutuhan penggabungan. Ini meningkatkan kompleksitas penulisan tetapi secara signifikan mempercepat pembacaan.
📊 Perbandingan Normalisasi vs. Denormalisasi
| Fitur | Normalisasi (3NF) | Denormalisasi |
|---|---|---|
| Integritas Data | Tinggi (Sumber Kebenaran Tunggal) | Lebih Rendah (Memerlukan Logika Sinkronisasi) |
| Kinerja Menulis | Lebih Cepat (Data yang Ditulis Lebih Sedikit) | Lebih Lambat (Penulisan Berulang) |
| Kinerja Membaca | Lebih Lambat (Memerlukan Gabungan) | Lebih Cepat (Akses Langsung) |
| Penggunaan Penyimpanan | Efisien | Lebih Tinggi (Redundansi) |
| Kasus Penggunaan | Sistem Transaksional (OLTP) | Pelaporan & Analitik (OLAP) |
🚀 Merancang untuk Skalabilitas Horizontal
Ketika volume data meningkat, satu node basis data menjadi hambatan. Skalabilitas horizontal melibatkan penambahan node lebih banyak untuk mendistribusikan beban. ERD Anda harus mendukung arsitektur ini sejak awal.
- Kunci Sharding:Identifikasi kolom yang memungkinkan data dibagi secara merata di seluruh shard. Kolom ini harus ada dalam setiap query yang mengakses data. Jika query memerlukan pemindaian semua shard, kinerja akan menurun.
- Kunci Asing Antar Shard:Menggabungkan tabel yang berada di shard yang berbeda sangat mahal secara komputasi. Minimalkan hubungan antar-shard pada tahap desain. Jika hubungan tersebut diperlukan, pertimbangkan untuk menyimpan data referensi dalam cache.
- ID Global:Gunakan pengenal unik yang tidak bergantung pada penghitung otomatis, karena hal ini dapat menyebabkan persaingan. UUID atau generator ID terdistribusi lebih disukai.
Saat membuat model untuk sharding, pertimbangkan distribusi data. Hotspot terjadi ketika satu shard menerima lalu lintas yang jauh lebih besar dibandingkan yang lain. Analisis pola akses untuk memastikan kunci sharding sesuai dengan filter query yang paling sering digunakan.
📑 Strategi Indeks untuk Dataset Besar
Indeks sangat penting untuk kinerja query, tetapi memiliki biaya. Setiap indeks mengonsumsi penyimpanan dan memperlambat operasi penulisan. Pendekatan strategis terhadap indeks sangat penting.
- Indeks Selektif: Buat indeks pada kolom yang menyaring data secara signifikan. Kolom dengan kardinalitas rendah (misalnya, jenis kelamin) sering kali bukan kandidat yang baik untuk indeks utama.
- Indeks Komposit: Gabungkan beberapa kolom dalam urutan yang sesuai dengan pola kueri. Aturan awalan kiri berlaku, artinya kolom pertama dalam indeks harus cocok dengan kueri agar indeks dapat digunakan secara efektif.
- Indeks Meliputi: Sertakan semua kolom yang dibutuhkan oleh kueri dalam indeks itu sendiri. Ini memungkinkan basis data memenuhi kueri tanpa mengakses data tabel, yang dikenal sebagai operasi ‘meliputi’.
- Indeks Parsial: Indeks hanya pada sebagian baris tabel. Ini berguna untuk penghapusan lunak atau bendera status tertentu, mengurangi ukuran struktur indeks.
Tinjau rencana eksekusi kueri secara rutin. Indeks yang tampak baik di kertas bisa diabaikan oleh optimizer kueri jika statistik sudah usang. Pemeliharaan rutin memastikan mesin basis data membuat keputusan optimal.
🔄 Evolusi dan Migrasi Skema
Sistem tidak statis. Kebutuhan berubah, dan model data harus berkembang. Berpindah dari versi A ke versi B tanpa downtime adalah keterampilan kritis.
- Perubahan Aditif: Menambahkan kolom atau tabel umumnya aman. Ini tidak merusak kueri yang sudah ada. Ini adalah metode yang disukai untuk memperkenalkan fitur baru.
- Operasi Penggantian Nama: Mengganti nama kolom berisiko. Ini memerlukan pembaruan kode aplikasi. Rencanakan periode deprecasi di mana kedua nama lama dan baru didukung.
- Penambahan Keterbatasan: Menambahkan keterbatasan (seperti NOT NULL) pada data yang sudah ada bisa gagal jika data sudah ada. Validasi data terlebih dahulu, lalu tambahkan keterbatasan dalam langkah terpisah.
- Kompatibilitas Mundur: Pastikan versi skema baru tidak merusak klien yang sudah ada. Gunakan bendera fitur untuk mengaktifkan logika baru hanya ketika skema siap.
🚫 Kesalahan Umum yang Harus Dihindari
Bahkan desainer berpengalaman menghadapi masalah. Mengenali pola-pola ini sejak dini dapat menghemat waktu rekayasa yang signifikan.
- Keterikatan Keras: Menciptakan hubungan yang memaksa sinkronisasi ketat antara entitas yang tidak saling terkait. Pertahankan modul yang terikat longgar agar memungkinkan penyebaran independen.
- Over-Engineering: Merancang untuk skenario yang mungkin tidak pernah terjadi. Fokus pada 80% kasus penggunaan yang menggerakkan 90% lalu lintas. Kesederhanaan membantu pemeliharaan.
- Mengabaikan Penghapusan Lunak: Penghapusan keras menghapus data secara permanen. Untuk jejak audit atau pemulihan, gunakan bendera status (misalnya, is_deleted) alih-alih penghapusan fisik.
- Masalah Kueri N+1: Gagal memprediksi bagaimana data akan diambil. Rencanakan pemuatan cepat atau pengambilan batch di lapisan akses data untuk menghindari perjalanan database yang berlebihan.
✅ Daftar Periksa Desain Sebelum Deploi
Sebelum menyelesaikan skema, lakukan pemeriksaan daftar ini untuk memastikan kesiapan untuk skala.
- ☐ Kunci Utama:Apakah semua tabel dilengkapi dengan kunci utama yang unik dan terindeks?
- ☐ Kunci Asing:Apakah hubungan didefinisikan dengan benar? Apakah kardinalitas akurat?
- ☐ Jenis Data:Apakah tipe numerik digunakan untuk ID dan jumlah? Apakah tipe tanggal distandarkan?
- ☐ Kemampuan Null:Apakah bidang yang diperlukan ditandai sebagai NOT NULL?
- ☐ Pengindeksan:Apakah kolom-kolom yang sering digunakan dalam query dengan lalu lintas tinggi diindeks?
- ☐ Sharding:Apakah ada kunci sharding yang layak jika skala horizontal diantisipasi?
- ☐ Kendala:Apakah kendala diperlukan untuk logika bisnis, atau dapat ditangani di lapisan aplikasi?
- ☐ Dokumentasi:Apakah ERD diperbarui untuk mencerminkan implementasi akhir?
🛡️ Integritas Data dalam Lingkungan Terdistribusi
Dalam pengaturan terdistribusi, sifat-sifat ACID (Atomisitas, Konsistensi, Isolasi, Daya Tahan) lebih sulit dijamin di seluruh node. Memahami implikasi bagi ERD Anda sangat penting.
- Konsistensi Akhir:Terima bahwa data mungkin bersifat tidak konsisten secara sementara di antara replika. Rancang aplikasi Anda agar dapat menangani keadaan ini secara mulus.
- Idempotensi:Pastikan operasi dapat diulang tanpa efek samping. Ini sangat penting untuk kegagalan jaringan di mana penulisan mungkin berhasil tetapi pengakuan hilang.
- Penyelesaian Konflik: Tentukan cara menangani pembaruan bersamaan terhadap catatan yang sama. Timestamp atau jam vektor dapat membantu menentukan versi terbaru.
Dengan memasukkan pertimbangan ini ke dalam Diagram Hubungan Entitas Anda, Anda menciptakan sistem yang tidak hanya berfungsi hari ini tetapi juga kuat untuk masa depan. Biaya mengubah skema di lingkungan produksi jauh lebih tinggi dibandingkan merancangnya dengan benar dari awal.
🔍 Ringkasan Praktik Terbaik
Untuk mengingatkan kembali, skalabilitas yang sukses bergantung pada pendekatan disiplin dalam pemodelan data. Fokus pada definisi yang jelas, normalisasi yang tepat, dan indeks strategis. Hindari jalan pintas yang mengorbankan integritas data. Tinjau diagram Anda secara rutin seiring berkembangnya sistem. ERD yang statis adalah beban; model yang hidup adalah aset.
Luangkan waktu di tahap desain. Ini akan memberi keuntungan dalam pengurangan biaya pemeliharaan dan peningkatan keandalan sistem. Pengguna Anda tidak akan pernah melihat diagram tersebut, tetapi mereka akan merasakan kinerja sistem yang didukung oleh diagram itu.