











Modelowanie danych często postrzegane jest jako statyczne ćwiczenie polegające na definiowaniu relacji i encji. Jednak diagram relacji encji (ERD) nie jest jedynie szkicem przechowywania danych; jest bezpośrednim wyznacznikiem tego, jak skutecznie silnik bazy danych pobiera i modyfikuje informacje. Każda linia narysowana, każda zdefiniowana relacja i każdy wybrany typ danych ma wpływ na plan wykonania Twoich zapytań. Zrozumienie mechanizmów projektowania schematu pozwala tworzyć systemy, które wykazują płynne skalowanie pod obciążeniem.
Ten przewodnik bada techniczne związki między strukturami ERD a wydajnością zapytań. Przekroczymy podstawowe definicje, aby zbadać, jak konkretne decyzje w modelowaniu wpływają na operacje wejścia/wyjścia, zużycie procesora i mechanizmy blokowania w środowisku relacyjnym.
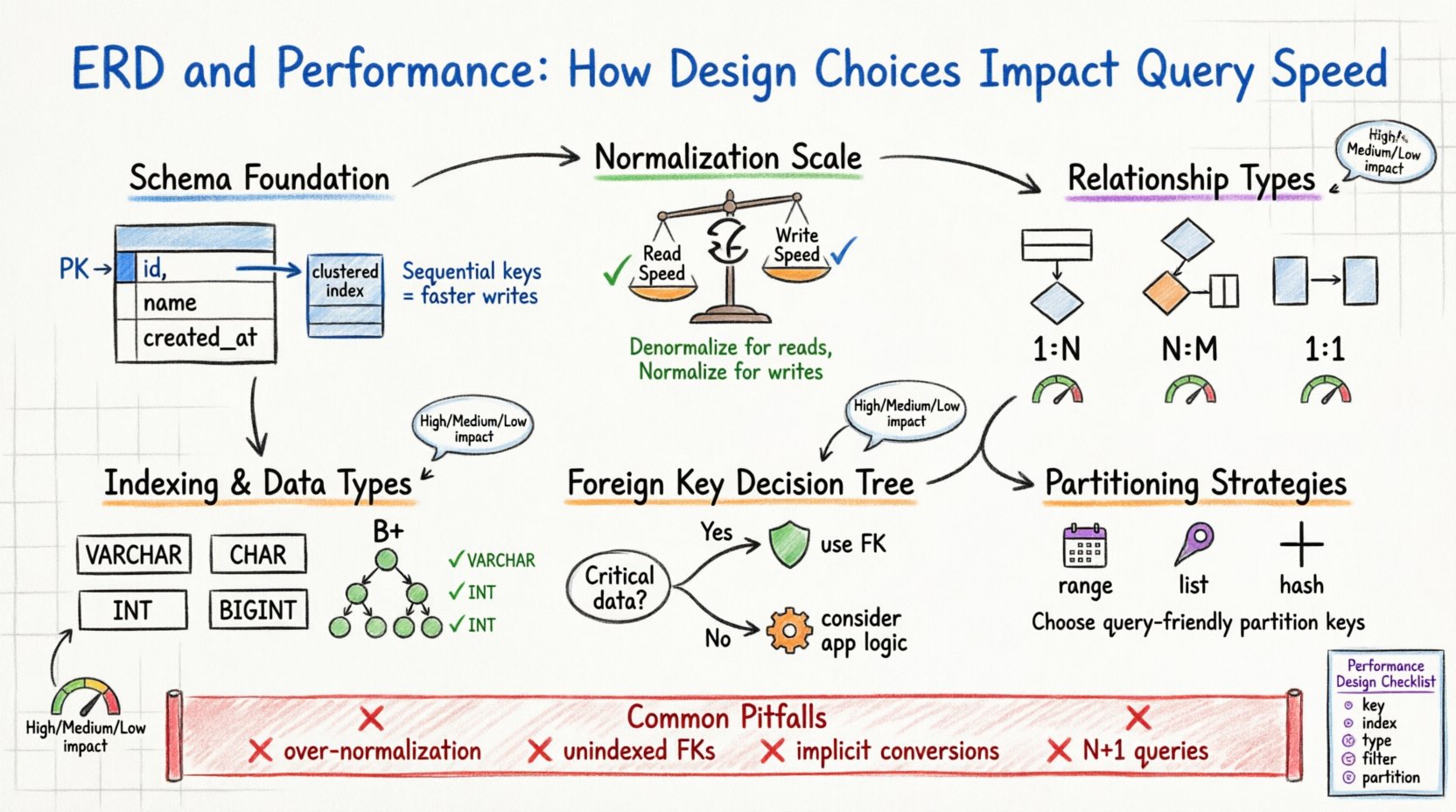
1. Podstawa: Struktura schematu i przechowywanie fizyczne 🏗️
Projekt logiczny, który tworzysz w ERD, w końcu przekłada się na pliki fizyczne na dysku. Silnik bazy danych musi przypisać te jednostki logiczne do stron, bloków i wierszy. Gdy schemat jest zoptymalizowany, silnik minimalizuje liczbę odczytów dysku wymaganych do spełnienia żądania. Gdy nie jest, silnik może być zmuszony do wykonywania pełnych skanowań tabel, co jest kosztownymi operacjami.
Zastanów się nad kluczem podstawowym. Służy on jako unikalny identyfikator wiersza. W wielu silnikach przechowywania klucz podstawowy określa fizyczną kolejność danych na dysku (indeks zgrupowany). Wybierając klucz podstawowy sekwencyjny i krótki, zapewnisz, że dane są przechowywane ciągle. Zmniejsza to fragmentację i pozwala na szybsze skanowanie zakresów. Z kolei losowy, długi klucz podstawowy może powodować podziały stron podczas wstawiania, co pogarsza wydajność zapisu i zwiększa obciążenie przechowywania.
Kluczowe kwestie dotyczące kluczy podstawowych
- Sequencja:Liczby całkowite z automatycznym zwiększaniem są zazwyczaj preferowane w przypadku obciążeń zapisu.
- Rozmiar:Mniejsze klucze zmniejszają rozmiar indeksów pomocniczych, ponieważ są przechowywane jako wskaźniki w tych indeksach.
- Stabilność:Klucze podstawowe nie powinny się zmieniać. Aktualizacja klucza podstawowego często wymaga aktualizacji wszystkich powiązanych kluczy obcych.
2. Normalizacja wobec wydajności – kompromisy ⚖️
Normalizacja to proces organizowania danych w celu zmniejszenia nadmiarowości i poprawy integralności. Choć tradycyjnie związana z jakością danych, ma głęboki wpływ na wydajność. Schemat bardzo znormalizowany (np. Trzecia postać normalna) często wymaga więcej połączeń do odtworzenia danych, podczas gdy schemat zdenormalizowany zmniejsza liczbę połączeń, ale zwiększa złożoność przechowywania i aktualizacji.
Decyzja o normalizacji czy zdenormalizacji to równowaga między szybkością odczytu a szybkością zapisu. W środowisku o dużym obciążeniu odczytu zdenormalizacja może znacznie skrócić czas zapytania, unikając skomplikowanych połączeń. W środowisku o dużym obciążeniu zapisu normalizacja zmniejsza liczbę wierszy, które należy aktualizować w wielu tabelach.
Analiza wpływu normalizacji
| Aspekt | Wysoko znormalizowane | Zdenormalizowane |
|---|---|---|
| Wydajność odczytu | Niższa (wymaga połączeń) | Wyższa (dostęp do jednej tabeli) |
| Wydajność zapisu | Wyższa (mniejsza nadmiarowość) | Niższa (aktualizacja wielu kopii) |
| Integralność danych | Wysoka (jedyna źródłowa prawda) | Niższa (ryzyko niezgodności) |
| Użycie pamięci | Niższy | Wyższy |
3. Klucze obce i narzut integralności 🔗
Klucze obce zapewniają integralność referencyjną. Gwarantują one, że wartość w jednej tabeli odpowiada wartości w innej. Choć zapobiega to istnieniu zaniedbanych rekordów, wprowadza on narzut czasu działania. Gdy wstawiasz, aktualizujesz lub usuwasz wiersz, baza danych musi sprawdzić ograniczenie klucza obcego.
Ta sprawdzianie nie jest darmowe. Silnik musi znaleźć odniesiony wiersz i zweryfikować jego istnienie. Jeśli tabela odniesiona jest duża i nie ma indeksu na kolumnie klucza obcego, sprawdzian staje się pełnym skanowaniem tabeli. Dodatkowo, usunięcie rekordu nadrzędnego wymaga od silnika sprawdzenia wszystkich rekordów potomnych, aby upewnić się, że nie pozostają żadne odniesienia, co może prowadzić do zablokowania wielu wierszy.
Kiedy używać kluczy obcych
- Krytyczna integralność danych: Jeśli poprawność danych jest kluczowa (np. transakcje finansowe), używaj kluczy obcych.
- Logika aplikacji: Jeśli logika aplikacji jest skomplikowana, przekazanie odpowiedzialności za integralność do bazy danych upraszcza kod.
- Małe zestawy danych: Narzut jest zaniedbywalny na małych tabelach.
Kiedy unikać kluczy obcych
- Wysoka przepustowość zapisu: Usunięcie ograniczeń może zmniejszyć zawieszenie blokad.
- Analiza na dużą skalę: W magazynach danych wydajność często przeważa nad ściśle określonymi zasadami integralności.
- Warstwy architektury: W mikroserwisach utrzymanie kluczy obcych przez granice usług jest często nierealistyczne.
4. Strategie indeksowania i typy kolumn 📑
Diagram ERD definiuje typy danych dla każdej kolumny. Wybór między VARCHAR a CHAR, lub między INT a BIGINT, wpływa na sposób przechowywania i indeksowania danych. Mniejsze typy danych zużywają mniej pamięci i miejsca na dysku, co pozwala na umieszczenie większej ilości danych w puli buforów (RAM).
Gdy zapytanie filtrowane jest według kolumny, silnik bazy danych opiera się na indeksach, aby szybko znaleźć wiersze. Jeśli projekt schematu nie odpowiada wzorców zapytań, indeksy stają się bezużyteczne. Na przykład tworzenie indeksu na kolumnie, która rzadko używana jest w klauzulach WHERE, jest marnotrawstwem zasobów.
Optymalizacja typów kolumn
- Stała długość vs. zmienna długość: Używaj CHAR dla danych o stałej długości (np. kody krajów), aby zmniejszyć fragmentację. Używaj VARCHAR dla danych o zmiennej długości.
- Zakresy liczb całkowitych: Nie używaj BIGINT, jeśli wystarczy INT. Mniejsze liczby całkowite mieszczą się więcej wierszy na stronie.
- Reprezentacja wartości logicznej: Używaj typów TINYINT(1) lub BOOLEAN zamiast przechowywania ciągów ‘Tak’/ ‘Nie’.
5. Implikacje kardynalności relacji 📊
Mocność relacji (jeden do jednego, jeden do wielu, wiele do wielu) określa sposób łączenia danych. Każda z typów relacji ma różne charakterystyki wydajności.
Jeden do wielu (1:N)
Jest to najpowszechniejsza relacja. Tabela rodzica zawiera jeden rekord, a tabela potomna zawiera wiele. Wydajność zależy w dużej mierze od indeksu w kolumnie klucza obcego w tabeli potomnej. Bez tego indeksu znalezienie wszystkich potomków dla rodzica wymaga przeszukania całej tabeli potomnej.
Wiele do wielu (N:M)
Wymaga tabeli pośredniej (jednostki asocjacyjnej). Dodaje dodatkowy poziom pośrednictwa. Zapytania dotyczące relacji N:M zwykle wymagają trzech połączeń: Tabela A, Tabela pośrednia, Tabela B. Ta złożoność zwiększa zużycie procesora i wymagania pamięci.
Jeden do jednego (1:1)
Często używane do podziału dużej tabeli na logiczne grupy. Może poprawić wydajność, jeśli tylko jedna podzbiór kolumn jest często zapytywany. Jednak dodaje koszt połączenia w celu pobrania pełnego rekordu.
6. Rozważania dotyczące partycjonowania i rozdzielania danych 🗃️
Wraz ze wzrostem danych pojedyncza tabela może stać się zbyt duża, aby mogła być skutecznie zarządzana. Partycjonowanie pozwala podzielić dużą tabelę na mniejsze, łatwiejsze do zarządzania fragmenty oparte na kluczu (np. data). Projekt ERD musi uwzględniać tę możliwość.
Jeśli projektujesz schemat dla systemu, który w przyszłości zostanie rozdzielony (podzielony na wiele serwerów), klucz partycjonowania musi być starannie wybrany. Klucz powinien być często używany w zapytaniach, aby silnik mógł kierować żądania do odpowiedniej partycji. Wybór klucza, który nie jest używany w zapytaniach, zmusza system do agregowania danych ze wszystkich partycji, co jest powolne.
Strategie partycjonowania
- Partycjonowanie zakresowe: Podział według zakresów dat lub ID. Dobrze nadaje się do danych czasowych.
- Partycjonowanie listowe: Podział według określonych wartości (np. kody regionów).
- Partycjonowanie haszowe: Rozdziela dane równomiernie, aby uniknąć obszarów nadmiernego obciążenia.
7. Powszechne pułapki w projektowaniu 🚫
Nawet doświadczeni architekci mogą wprowadzać wąskie gardła wydajności dzięki wyborom projektowym. Wczesne rozpoznanie tych wzorców zapobiega kosztownemu przepisaniu kodu w przyszłości.
- Zbyt duża normalizacja:Podział danych na zbyt wiele małych tabel zwiększa złożoność połączeń i zmniejsza wydajność pamięci podręcznej.
- Ignorowanie selektywności:Indeksowanie kolumn o niskiej selektywności (np. płeć lub flagi stanu) często daje słabe wyniki, ponieważ optymalizator może zignorować indeks i nadal przeszukiwać całą tabelę.
- Niejawne konwersje: Projektowanie kolumny jako ciągu znaków, gdy oczekiwane są wartości numeryczne, zmusza silnik do konwersji typów podczas zapytań, co uniemożliwia wykorzystanie indeksu.
- Wzorce zapytań N+1:Projektowanie relacji, które zachęcają do pobierania danych w pętlach zamiast połączeń wsadowych, może przeciążyć serwer.
8. Przyszłościowe zabezpieczenia i ewolucja 🛡️
Bazy danych ewoluują. Wymagania się zmieniają, a do systemu dodawane są nowe funkcje. Schemat, który jest wydajny dziś, może stać się wąskim gardłem jutro, jeśli nie ma elastyczności. ERD powinien umożliwiać rozwój bez konieczności całkowitego przepisania.
Rozważ dodanie kolumn, które mogą zostać użyte do filtrowania w przyszłości. Choć zwiększa to nieco rozmiar wiersza, oszczędza koszt zmiany struktury tabeli w przyszłości, co może być kosztowne operacją na dużych zestawach danych. Również rozważ wpływ dodawania nowych indeksów. Każdy indeks zużywa zasoby zapisu. Projektuj schemat tak, aby minimalizować liczbę koniecznych indeksów.
Lista kontrolna projektu pod kątem wydajności
- Czy klucze główne są krótkie i sekwencyjne?
- Czy klucze obce są indeksowane?
- Czy typy danych są najmniejszym możliwym poprawnym typem?
- Czy częste filtry są obsługiwane przez indeksy?
- Czy poziom normalizacji jest odpowiedni dla obciążenia?
- Czy rozważyłeś podział tabel dla dużych tabel?
- Czy istnieją kolumny przechowujące skomplikowane dane JSON lub tekst, które mogłyby zostać zorganizowane?
9. Rola planu wykonania 📋
Na końcu silnik bazy danych decyduje, jak wykonać zapytanie, na podstawie schematu i statystyk. ERD wpływa na statystyki zbierane przez silnik. Na przykład kolumna z rozkładem wartości różnorodnych będzie obsługiwana inaczej niż kolumna z zniekształconymi danymi. Zrozumienie działania planu wykonania pomaga zrozumieć, dlaczego zapytanie jest wolne.
Jeśli zapytanie wykonuje pełne skanowanie tabeli, często wskazuje to na brakujący indeks lub projekt, który nie wspiera efektywnego filtrowania. Jeśli wykonuje wiele zagnieżdżonych pętli, sugeruje to złożone połączenia, które mogłyby zostać uproszczone. Poprzez dopasowanie ERD do oczekiwanych wzorców dostępu prowadzisz silnik do optymalnych planów wykonania.
10. Zrównoważenie integralności i szybkości ⚖️
Nie ma idealnego schematu. Każde decyzje projektowe wiążą się z kompromisem. Celem nie jest usunięcie problemów wydajności, ale zarządzanie nimi strategicznie. W niektórych przypadkach zaakceptowanie niewielkiego ryzyka niezgodności danych (poprzez sprawdzanie na poziomie aplikacji zamiast ograniczeń bazy danych) jest uzasadnionym kompromisem dla ekstremalnej przepustowości zapisu.
Regularnie przeglądaj swój ERD w świetle rzeczywistych dzienników zapytań. Zidentyfikuj najwolniejsze zapytania i śledź je z powrotem do schematu. Ta pętla zwrotna zapewnia, że Twój projekt ewoluuje w synchronizacji z potrzebami aplikacji.
Podsumowanie obszarów wpływu 📝
| Element projektowy | Wpływ na wydajność | Zalecenie |
|---|---|---|
| Typ klucza głównego | Wysoki (przechowywanie i indeksowanie) | Konsystentnie używaj liczb całkowitych lub UUID. |
| Klucze obce | Średni (nadmiar zapisu) | Indeksuj kolumny FK; usuń, jeśli integralność jest obsługiwana gdzie indziej. |
| Normalizacja | Wysoki (złożoność połączeń) | Zdenormalizuj tabele o dużym obciążeniu odczytu. |
| Typy danych | Średni (użycie pamięci) | Używaj najbardziej szczegółowego typu dostępny. |
| Moc zbioru | Wysokie (koszt łączenia) | Optymalizuj tabele pośrednie dla relacji N:M. |
Traktując diagram relacji encji jako element wydajności, a nie tylko jako mapę logiczną, możesz tworzyć systemy wytrzymałe, skalowalne i wydajne. Decyzje, które podejmujesz teraz, będą określały zachowanie Twojej aplikacji przez kolejne lata.