











Projektowanie modeli danych w architekturze mikroserwisów wymaga podstawowej zmiany podejścia w porównaniu do aplikacji monolitycznych. W tradycyjnym systemie pojedynczy diagram relacji encji (ERD) często obejmuje całą bazę danych. W środowisku rozproszonym ten pojedynczy widok rozpadają się na wiele niezależnych schematów. Wyzwanie polega na utrzymaniu spójności bez łączenia usług ze sobą. Ten przewodnik omawia sposób skutecznego projektowania modeli danych, zapewniając skalowalność i odporność, unikając typowych pułapek zarządzania danymi w środowisku rozproszonym.
Gdy usługi współdzielą dane bezpośrednio, niosą ze sobą zależności od siebie. Takie silne sprzężenie prowadzi do niestabilnych systemów, gdzie zmiana w jednym obszarze powoduje awarię innego. Celem jest stworzenie granic, które pozwalają zespołom wdrażać się niezależnie. Dostosowanie tego wymaga starannego zaplanowania relacji, modeli spójności oraz wzorców integracji.
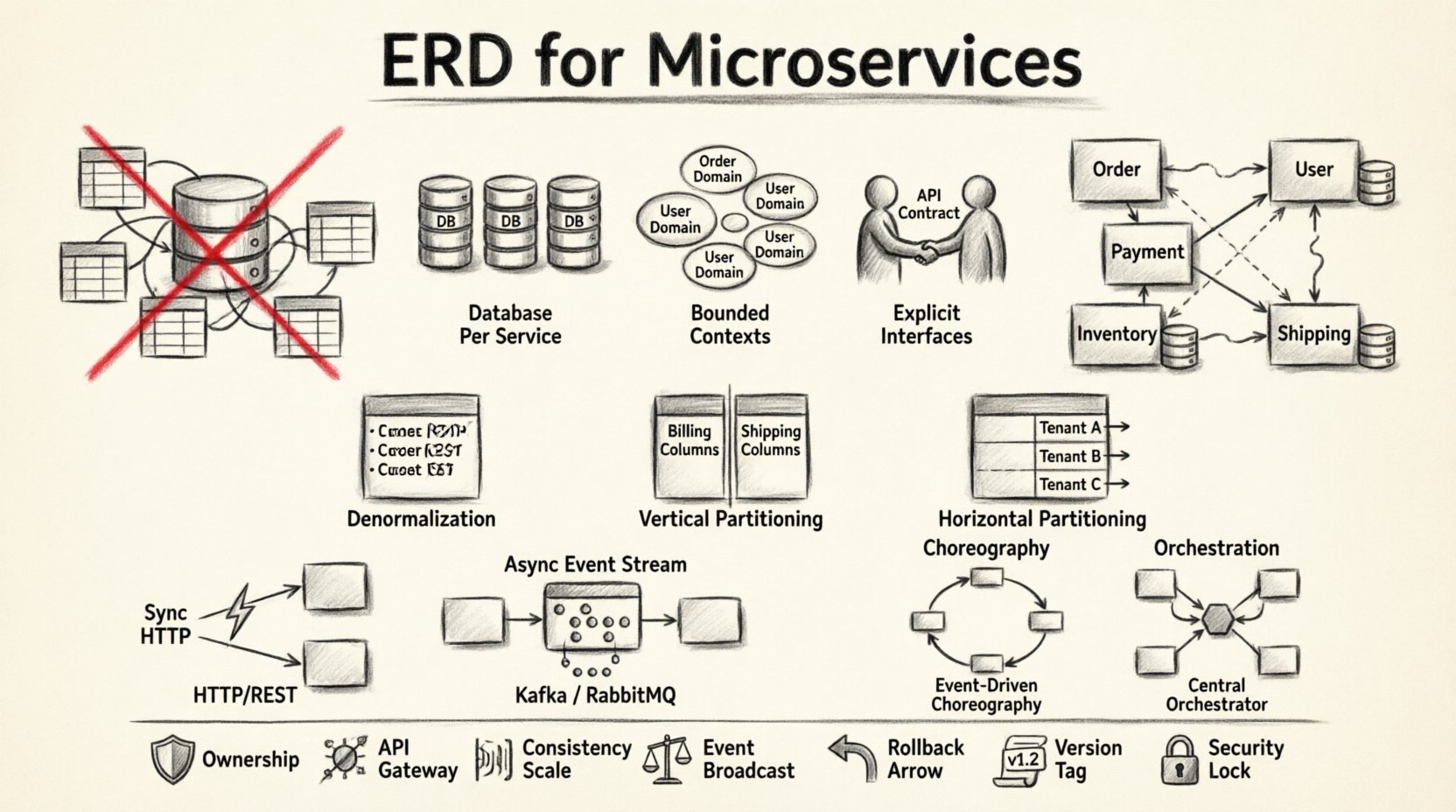
🧱 Dlaczego tradycyjne ERD zawierają się w systemach rozproszonych
Standardowy ERD zakłada centralną władzę. Mapuje tabele, kolumny i klucze obce w ramach jednego granicy transakcyjnej. Mikroserwisy odrzucają tę centralizację. Gdy stosuje się myślenie monolityczne ERD w systemie rozproszonym, istnieje ryzyko stworzenia rozproszonego monolitu. Zdarza się to, gdy usługi opierają się na współdzielonych tabelach baz danych zamiast zdefiniowanych interfejsów API.
Poniższe problemy zwykle pojawiają się, gdy ignoruje się te zasady:
- Zależność wdrażania:Zmiany w współdzielonej tabeli wymagają jednoczesnego wdrażania w wielu usługach.
- Granice transakcji:Transakcje ACID obejmują wiele usług, zwiększając opóźnienia i punkty awarii.
- Zamrożenie schematu:Blokady bazy danych w jednej usłudze mogą zatrzymać żądania w innej usłudze.
- Problemy z widocznością:Żaden zespół nie zarządza globalnym stanem danych, co prowadzi do izolowanych zbiorów danych.
Zamiast pojedynczego diagramu potrzebujesz zbioru schematów specyficznych dla usług, które komunikują się poprzez dobrze zdefiniowane interfejsy. Ten podejście priorytetowo uznaje autonomię nad natychmiastową spójnością.
🧬 Podstawowe zasady modelowania danych rozproszonych
Aby zachować porządek, należy przestrzegać określonych zasad architektonicznych. Te wytyczne pomagają zespołom podejmować decyzje dotyczące własności danych i wzorców dostępu.
1. Baza danych na usługę
Każdy mikroserwis powinien zarządzać własnym magazynem danych. Zapewnia to, że wewnętrzny schemat usługi nie jest widoczny dla innych. Jeśli usługa A potrzebuje danych z usługi B, musi je żądać poprzez interfejs API, a nie bezpośrednio z bazy danych. Ta izolacja chroni integralność każdego obszaru.
- Usługi zarządzają własnym rozwojem schematu.
- Zespoły mogą wybierać najlepszą technologię bazy danych zgodnie z ich konkretnymi potrzebami (polyglot persistence).
- Awaria jednej bazy danych nie powoduje awarii całej aplikacji.
2. Zasady ograniczonego kontekstu
Dane muszą być zgodne z możliwościami biznesowymi. W projektowaniu opartym na domenie, zasada ograniczonego kontekstu definiuje granice semantyczne modelu. Dwie usługi mogą używać terminu „Klient”, ale dane w tych kontekstach się różnią. Jedna może przechowywać dane kontaktowe, a druga historię finansową. Połączenie ich w jednym ERD powoduje zamieszanie i dług techniczny.
3. Jawne interfejsy
Ponieważ usługi nie mogą bezpośrednio widzieć danych drugiej usługi, interfejs API staje się kontraktem danych. Schemat odpowiedzi interfejsu API definiuje rzeczywistość danych dla odbiorcy. To rozdziela implementację wewnętrznego przechowywania danych od zewnętrznej ich konsumpcji.
📐 Wzorce projektowania schematów dla niezależności
Projektowanie schematów dla mikroserwisów obejmuje konkretne wzorce do obsługi relacji, które tradycyjnie byłyby zarządzane przez klucze obce. Nie można polegać na ograniczeniach na poziomie bazy danych w celu zapewnienia relacji między usługami.
Denumeryzacja
W monolicie normalizacja zmniejsza nadmiarowość. W mikroserwisach często preferuje się denormalizację. Przechowywanie danych powtórzonych zmniejsza potrzebę wywołań zdalnych. Na przykład usługa Zamówień może przechowywać imię i adres Klienta w rekordzie zamówienia. Pozwala to uniknąć synchronicznego wyszukiwania w usłudze Użytkownika przy każdym wyświetleniu zamówienia.
- Zysk:Szybsza wydajność odczytu i mniejsza liczba skoków sieciowych.
- Ryzyko:Niespójność danych, jeśli dane źródłowe ulegną zmianie. Musisz obsługiwać aktualizacje za pomocą zdarzeń.
Pionowe partycjonowanie
Podziel duże tabele na mniejsze, skupione zestawy. Jeśli tabela zawiera zarówno dane rozliczeniowe, jak i adresy wysyłki, rozdziel te aspekty. Dane rozliczeniowe mogą należeć do usługi płatności, a adresy wysyłki do usługi logistycznej. Zmniejsza to obszar zmian i poprawia bezpieczeństwo, ograniczając dostęp.
Poziome partycjonowanie
Podziel dane na podstawie identyfikatora klienta lub regionu geograficznego. Jest to przydatne do skalowania określonych usług bez wpływu na inne. Pozwala na replikację usług dla obszarów o dużym ruchu, jednocześnie utrzymując inne lekkie.
| Wzorzec | Najlepsze zastosowanie | Kluczowa kwestia |
|---|---|---|
| Denumeryzacja | Obciążenia odczytu | Wymaga logiki synchronizacji |
| Pionowe partycjonowanie | Odrębne domeny | Jasne granice interfejsu API |
| Poziome partycjonowanie | Wysoka skala / Wieloklientowość | Złożoność logiki routingu |
🔄 Obsługa relacji i spójności
Najtrudniejszą częścią modelowania danych w mikrousługach jest utrzymanie spójności bez transakcji rozproszonych. Musisz wybrać między silną spójnością a spójnością ostateczną.
Komunikacja synchroniczna
Usługi mogą wywoływać się nawzajem bezpośrednio przez HTTP lub gRPC. Zapewnia to silną spójność dla operacji natychmiastowych. Jednak wprowadza opóźnienia i tworzy łańcuch zależności. Jeśli usługa A wywołuje usługę B, a usługa B jest niedostępna, usługa A kończy się niepowodzeniem.
Komunikacja asynchroniczna
Usługi komunikują się za pomocą kolejek komunikatów lub strumieni zdarzeń. Odrzuca synchronizację czasową operacji. Usługa A publikuje zdarzenie, a usługa B przetwarza je później. Wspiera to spójność ostateczną.
- Zalety:Wytrzymałość, skalowalność i luźne sprzężenie.
- Wady:Dane są tymczasowo niespójne. Debugowanie wymaga śledzenia przez wiele dzienników.
🗓️ Wzorzec Saga dla integralności danych
Saga to ciąg lokalnych transakcji. Każda transakcja aktualizuje lokalną bazę danych i publikuje zdarzenie, które uruchamia następny krok. Jeśli krok nie powiedzie się, saga wykonuje transakcje kompensacyjne w celu cofnięcia poprzednich zmian.
Choreografia w porównaniu do orchestry
Sagi można zaimplementować na dwa sposoby:
- Choreografia: Usługi nasłuchują zdarzeń i decydują, co zrobić dalej. Nie ma centralnego kontrolera. Jest to elastyczne, ale trudniejsze do wizualizacji.
- Orchestry: Centralny koordynator informuje usługi, co mają zrobić. Zapewnia lepszą widoczność i kontrolę nad przepływem pracy, ale wprowadza punkt jednego awarii.
Podczas modelowania diagramów ERD dla sag należy uwzględnić zmiany stanu. Każda usługa uczestnicząca w sago musi przechowywać swój stan w celu obsługi cofnięć. Oznacza to, że schemat musi obsługiwać stany transakcyjne, a nie tylko końcowe dane.
📝 Zarządzanie ewolucją schematu
Ewolucja schematu jest nieunikniona. Pola ulegają zmianie, typy się zmieniają, a ograniczenia się rozluźniają. W systemie rozproszonym nie możesz zmieniać schematu bazy danych, gdy inne usługi na nim zależą. Musisz zaplanować wersjonowanie.
Zgodność wsteczna
Zawsze utrzymuj zgodność wsteczną. Gdy dodajesz nowe pole, nie usuwaj starego od razu. Pozwól konsumentom na stopniowe przeniesienie. Jeśli musisz zmienić nazwę pola, zaliasz stare imię na nowe w okresie przejściowym.
Strategie wersjonowania
- Wersjonowanie URI: Włączaj numery wersji w ścieżce interfejsu API.
- Wersjonowanie nagłówków: Używaj niestandardowych nagłówków, aby określić oczekiwaną wersję schematu.
- Negocjacja treści: Używaj standardowych nagłówków HTTP, aby żądać określonych typów mediów.
Dokumentacja musi być zsynchronizowana z kodem. Testy automatyczne powinny potwierdzać, że kontrakt interfejsu API odpowiada schematowi. To zapobiega wprowadzaniu zmian, które mogą naruszyć działanie w środowisku produkcyjnym.
🛡️ Najczęstsze pułapki do uniknięcia
Nawet przy solidnym planie zespoły często napotykają konkretne problemy. Znajomość tych pułapek pomaga w projektowaniu odpornego systemu.
1. Pułapka współdzielonej bazy danych
Nie dziel tabel między usługami. Powoduje to ukrytą zależność. Jeśli usługa płatności odczytuje tabelę usługi zamówień, wie zbyt dużo o strukturze wewnętrznej. To prowadzi do silnej zależności i konfliktów wdrażania.
2. Nadmierna normalizacja
Próba normalizacji danych między usługami prowadzi do nadmiernych połączeń i wywołań sieciowych. Zaakceptuj pewną nadmiarowość. Lepiej mieć powielone dane niż system wolny i silnie skojarzony.
3. Ignorowanie idempotentności
Wywołania sieciowe mogą się nie powieść. Wiadomości mogą się powielać. Twój schemat i logika interfejsu API muszą obsługiwać powtarzające się żądania bez powodowania błędów. Projektuj swoje punkty końcowe jako idempotentne, aby ponowne wysyłanie żądania nie tworzyło powielonych rekordów.
4. Brak obserwacji
Gdy dane są rozproszone, nie możesz wykonać zapytania do pojedynczej bazy danych w celu śledzenia transakcji. Potrzebujesz rozproszonego śledzenia i centralizowanego rejestrowania. Twój schemat powinien zawierać identyfikatory korelacji w celu śledzenia żądań przez granice usług.
📋 Lista kontrolna zarządzania
Zanim wdrożysz nową usługę, przejrzyj poniższą listę kontrolną, aby upewnić się, że twój model danych jest poprawny.
- Właściciel:Czy istnieje jedna usługa odpowiedzialna za te dane?
- Interfejs:Czy dane są udostępniane wyłącznie za pośrednictwem interfejsu API?
- Spójność:Czy model spójności jest zapisany (Silna vs. Ostateczna)?
- Zdarzenia:Czy zmiany stanu są publikowane jako zdarzenia dla innych usług?
- Kompensacja:Czy istnieje mechanizm cofnięcia dla nieudanych transakcji?
- Wersjonowanie:Czy schemat jest wersjonowany w celu obsługi przyszłych zmian?
- Bezpieczeństwo:Czy poufne dane są szyfrowane w spoczynku i w trakcie przesyłania?
🔍 Wizualizacja architektury
Choć nie możesz narysować jednego ERD dla całego systemu, możesz stworzyć mapę najwyższego poziomu. Ta mapa pokazuje usługi i ich granice danych, a nie konkretne kolumny.
- Narysuj prostokąty dla każdej usługi.
- Oznacz domenę danych wewnątrz prostokąta (np. „Dane profilu użytkownika”).
- Narysuj strzałki dla wywołań interfejsu API wskazujące kierunek przepływu danych.
- Wskazuj strumienie zdarzeń osobno od przepływów żądanie/odpowiedź.
To wizualne wspomaganie pomaga stakeholderom zrozumieć przepływ informacji bez zagłębiania się w szczegółowe aspekty schematu technicznego. Służy jako narzędzie komunikacji dla architektów i analityków biznesowych.
🚀 Wnioski
Projektowanie ERD dla mikroserwisów nie polega na rysowaniu linii między tabelami. Polega na definiowaniu granic między możliwościami biznesowymi. Przyjmując bazę danych na usługę, akceptując spójność ostateczną i ściśle zarządzając interfejsami API, możesz budować systemy, które skalują się. Chaos danych rozproszonych można kontrolować dzięki dyscyplinie i jasnym umowom. Skup się na autonomiczności, minimalizuj zależności i upewnij się, że każda usługa całkowicie zarządza własnymi danymi.
Pamiętaj, że modelowanie danych to proces iteracyjny. Gdy usługi rosną, twój schemat będzie musiał się rozwijać. Regularnie przeglądarkuj architekturę pod kątem tych zasad, aby utrzymać zdrowy i odporny system.