











Tworzenie systemu, który może obsługiwać miliony użytkowników, wymaga więcej niż tylko potężnego sprzętu czy efektywnego kodu. Podstawą jest struktura danych sama w sobie. Diagram relacji encji (ERD) nie jest po prostu dokumentem; jest szkicem przetrwania Twojej aplikacji. Kiedy architekci projektują system z myślą o wzroście, przewidują przyszły obciążenie, złożoność relacji oraz konieczność integralności danych. Poprawnie skonstruowana schemat zapobiega akumulowaniu długu technicznego już przed pierwszym commitem.
Ten przewodnik omawia podejście do projektowania diagramów relacji encji specjalnie dla środowisk skalowalnych. Omówimy podstawy teoretyczne, praktyczne kompromisy oraz wzorce strukturalne wspierające systemy o wysokim przepływie danych bez utraty spójności.
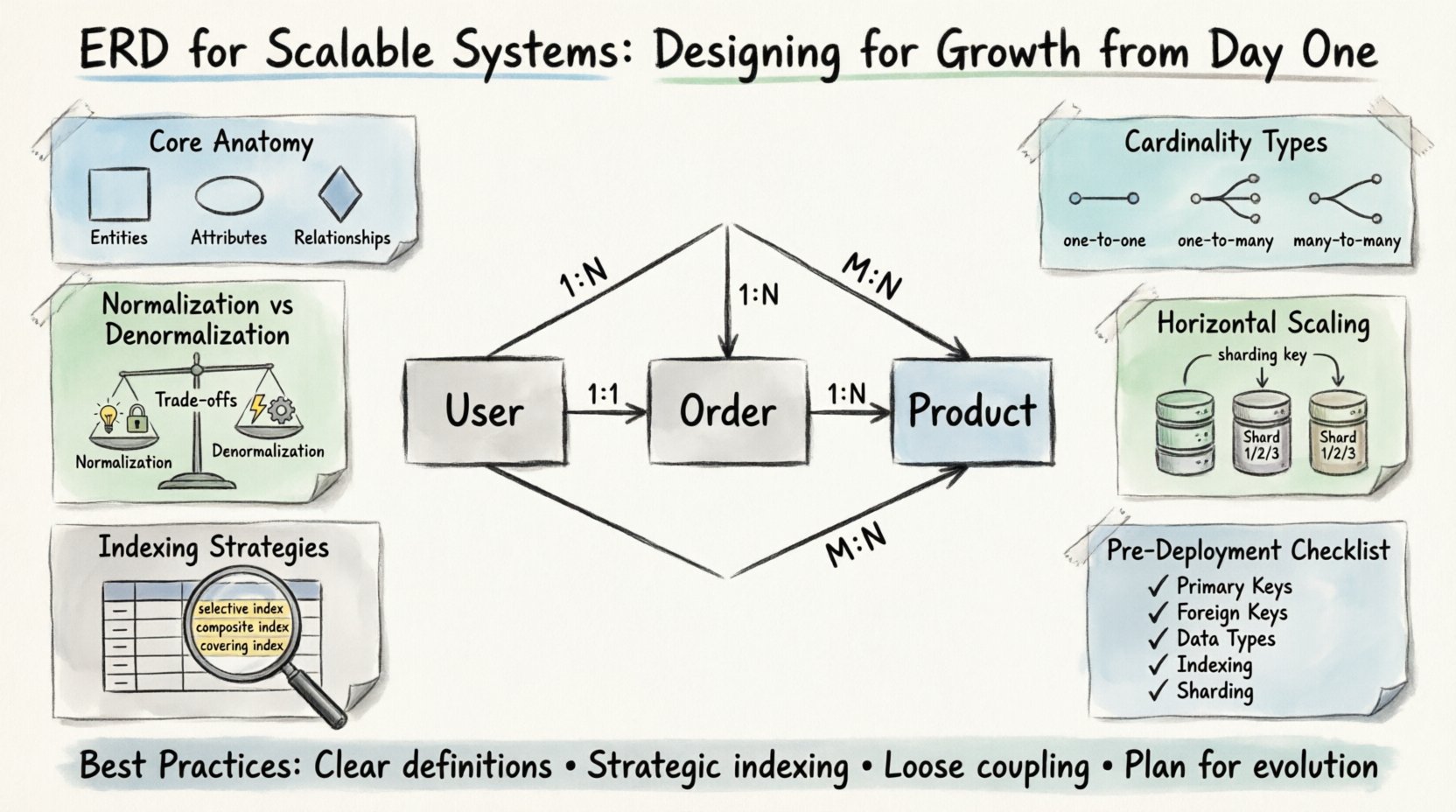
🧩 Podstawowa anatomia skalowalnego ERD
Zanim rozważysz skalowalność, musisz zrozumieć podstawowe elementy budowlane. Każdy diagram składa się z encji, atrybutów i relacji. W kontekście skalowalnym te elementy muszą być precyzyjnie zdefiniowane, aby uniknąć wąskich gardeł w przyszłości.
- Encje: Odnoszą się do podstawowych obiektów Twojej dziedziny biznesowej. Przykłady to Użytkownicy, Zamówienia i Produkty. W systemach o dużym tempie wzrostu encje powinny być wystarczająco szczegółowe, aby umożliwić niezależne skalowanie, ale jednocześnie wystarczająco spójne, aby zachować logiczne granice.
- Atrybuty: To właściwości opisujące encje. Typy danych są tutaj kluczowe. Wybór poprawnego typu wpływa na wydajność przechowywania i wykonywania zapytań. Na przykład użycie specjalnego typu całkowitego dla identyfikatorów jest lepsze niż ciągi znaków podczas indeksowania.
- Relacje: Określają sposób działania encji. Liczba wystąpień (cardinality) to najważniejszy aspekt do zdefiniowania na wstępie. Nieprawidłowe rozumienie relacji jeden do wielu jako wiele do wielu może prowadzić do niepotrzebnych połączeń i poważnego spowolnienia wydajności.
📐 Zrozumienie liczby wystąpień i ograniczeń
Liczba wystąpień określa liczbę wystąpień jednej encji, które mogą lub muszą być powiązane z wystąpieniami innej encji. W systemach skalowalnych wybór liczby wystąpień często decyduje o tym, jak dane są partycjonowane.
- Jeden do jednego (1:1): Rzadko stosowane w celu optymalizacji wydajności. Często oznacza podział dużej encji w celu zmniejszenia zawieszeń. Używaj tylko wtedy, gdy wzorce dostępu do danych są ściśle różne.
- Jeden do wielu (1:N): Najczęstsza relacja. Użytkownik ma wiele zamówień. Ta struktura wspiera skuteczne indeksowanie po stronie klucza obcego, umożliwiając szybkie pobieranie powiązanych rekordów.
- Wiele do wielu (M:N): Wymaga tabeli pośredniej. Choć elastyczne, mogą stać się wąskimi garzłami wydajności wraz ze wzrostem objętości danych. Rozważ denormalizację lub widoki materiałizowane, jeśli częstotliwość odczytu jest wysoka.
Podczas definiowania ograniczeń należy rozważyć koszt ich stosowania. W systemach rozproszonych wymuszanie ścisłych ograniczeń kluczy obcych między shardami może wprowadzać opóźnienia. W takich przypadkach może być konieczne weryfikowanie na poziomie aplikacji, aby zachować wydajność systemu i jednocześnie zapewnić integralność danych.
⚖️ Normalizacja wobec kompromisów wydajności
Normalizacja zmniejsza nadmiarowość i poprawia integralność danych. Jednak systemy o wysokiej wydajności często wymagają odstąpienia od ścisłych zasad normalizacji. Zrozumienie warstw pomaga podejmować świadome decyzje.
- Pierwsza postać normalna (1NF): Wartości atomowe. Zapewnia, że każda komórka zawiera jedną wartość. To nie jest kwestia do negocjacji dla integralności relacyjnej.
- Druga postać normalna (2NF): Brak częściowej zależności. Wszystkie atrybuty niekluczowe muszą zależeć od całego klucza głównego. Użyteczne do zmniejszania anomalii aktualizacji.
- Trzecia postać normalna (3NF): Brak zależności przechodniej. Atrybuty niekluczowe nie mogą zależeć od innych atrybutów niekluczowych. To standardowy cel dla większości systemów transakcyjnych.
Choć 3NF jest idealna pod kątem spójności, często wymaga skomplikowanych połączeń. W systemach o dużym obciążeniu odczytu łączenie wielu tabel może obciążyć silnik bazy danych. Denormalizacja polega na powielaniu danych w celu zmniejszenia potrzeby łączenia. Zwiększa to złożoność zapisu, ale znacznie przyspiesza odczyt.
📊 Porównanie normalizacji i denormalizacji
| Funkcja | Normalizowana (3NF) | Nienormalizowana |
|---|---|---|
| Integralność danych | Wysoka (jedyna prawdziwa źródłowa) | Niższa (wymaga logiki synchronizacji) |
| Wydajność zapisu | Szybsza (mniej danych zapisywanych) | Wolniejsza (nadmiarowe zapisy) |
| Wydajność odczytu | Wolniejsza (wymaga łączeń) | Szybsza ( bezpośredni dostęp) |
| Użycie pamięci | Efektywne | Wyższe (nadmiarowość) |
| Przypadek użycia | Systemy transakcyjne (OLTP) | Raportowanie i analizy (OLAP) |
🚀 Projektowanie z myślą o skalowaniu poziomym
Wraz ze wzrostem objętości danych pojedynczy węzeł bazy danych staje się węzłem rozległym. Skalowanie poziome polega na dodawaniu większej liczby węzłów w celu rozłożenia obciążenia. Twój ERD musi wspierać tę architekturę od samego początku.
- Klucze fragmentacji: Zidentyfikuj kolumnę, która pozwala na równomierne podział danych między fragmenty. Ta kolumna powinna występować we wszystkich zapytaniach dostępu do danych. Jeśli zapytanie wymaga skanowania wszystkich fragmentów, wydajność będzie pogarszać się.
- Klucze obce między fragmentami: Łączenie tabel znajdujących się na różnych fragmentach jest kosztowne obliczeniowo. Minimalizuj relacje między fragmentami na etapie projektowania. Jeśli relacja jest konieczna, rozważ buforowanie danych referencyjnych.
- Globalne identyfikatory: Używaj unikalnych identyfikatorów, które nie opierają się na licznikach automatycznych, ponieważ mogą one powodować zawieszenie. Zalecane są UUID lub generatory identyfikatorów rozproszonych.
Podczas modelowania dla fragmentacji rozważ rozkład danych. Zjawisko „gorących punktów” występuje, gdy jeden fragment otrzymuje znacznie więcej ruchu niż inne. Analizuj wzorce dostępu, aby upewnić się, że klucz fragmentacji odpowiada najczęściej używanym filtrów zapytań.
📑 Strategie indeksowania dla dużych zestawów danych
Indeksy są niezbędne dla wydajności zapytań, ale wiążą się z kosztem. Każdy indeks zużywa pamięć i spowalnia operacje zapisu. Strategiczny podejście do indeksowania jest kluczowe.
- Wybierane indeksy: Twórz indeksy na kolumnach, które znacząco filtrowują dane. Kolumna o niskiej liczbie unikalnych wartości (np. płeć) często nie jest dobrym kandydatem na indeks główny.
- Indeksy złożone: Łącz wiele kolumn w kolejności odpowiadającej wzorców zapytań. Stosuje się zasade prefiksu z lewej strony, co oznacza, że pierwsza kolumna w indeksie musi pasować do zapytania, aby indeks mógł być skutecznie wykorzystany.
- Indeksy pokrywające: Włącz wszystkie kolumny wymagane przez zapytanie bezpośrednio w indeksie. Pozwala to bazie danych spełnić zapytanie bez dostępu do danych tabeli, co nazywane jest operacją „pokrywania”.
- Indeksy częściowe: Indeksuj tylko podzbiór wierszy tabeli. Jest to przydatne w przypadku usunięć miękkich lub określonych flag stanu, co zmniejsza rozmiar struktury indeksu.
Regularnie przeglądaj plany wykonania zapytań. Indeks, który wydaje się dobry na papierze, może zostać zignorowany przez optymalizator zapytań, jeśli statystyki są przestarzałe. Regularne utrzymanie zapewnia, że silnik bazy danych podejmuje optymalne decyzje.
🔄 Ewolucja i migracje schematu
Systemy nie są statyczne. Wymagania się zmieniają, a model danych musi ewoluować. Przejście z wersji A do wersji B bez przestojów to kluczowa umiejętność.
- Zmiany dodawane: Dodanie kolumny lub tabeli jest zazwyczaj bezpieczne. Nie niszczy istniejących zapytań. Jest to preferowany sposób wprowadzania nowych funkcji.
- Operacje zmiany nazwy: Zmiana nazwy kolumny jest ryzykowna. Wymaga aktualizacji kodu aplikacji. Zaprojektuj okres deprecjacji, w którym wspierane będą zarówno stare, jak i nowe nazwy.
- Dodawanie ograniczeń: Dodanie ograniczenia (np. NOT NULL) do istniejących danych może się nie powieść, jeśli dane już istnieją. Najpierw zwaliduj dane, a następnie dodaj ograniczenie w osobnym kroku.
- Zgodność wsteczna: Upewnij się, że nowe wersje schematu nie naruszają istniejących klientów. Używaj flag funkcji, aby włączać nową logikę tylko wtedy, gdy schemat jest gotowy.
🚫 Powszechne pułapki do uniknięcia
Nawet doświadczeni projektanci napotykają problemy. Wczesne rozpoznanie tych wzorców może zaoszczędzić znaczną ilość czasu inżynierskiego.
- Zbyt silne sprzężenie: Tworzenie relacji, które wymuszają ścisłą synchronizację między niepowiązanymi jednostkami. Zachowaj luźne sprzężenie modułów, aby umożliwić niezależne wdrażanie.
- Zbyt skomplikowane projektowanie: Projektowanie dla scenariuszy, które mogą się nigdy nie wydarzyć. Skup się na 80% przypadków użycia, które generują 90% ruchu. Prostota ułatwia utrzymanie.
- Ignorowanie miękkich usuwań: Twarda usunięcie usuwa dane na stałe. W celu śledzenia zmian lub odtworzenia danych użyj flagi stanu (np. is_deleted), zamiast fizycznego usunięcia.
- Problemy z zapytaniami N+1: Nieprzewidywanie sposobu pobierania danych. Zaprojektuj ładowanie zgodne z zapytaniem lub pobieranie partiami na poziomie dostępu do danych, aby uniknąć nadmiernych wywołań do bazy danych.
✅ Lista kontrolna projektu przed wdrożeniem
Zanim zakończysz projektowanie schematu, przejdź przez tę listę weryfikacji, aby upewnić się, że jest gotowy do skalowania.
- ☐ Klucze główne: Czy wszystkie tabele są wyposażone w unikalny, indeksowany klucz główny?
- ☐ Klucze obce: Czy relacje są poprawnie zdefiniowane? Czy liczba elementów jest dokładna?
- ☐ Typy danych: Czy do identyfikatorów i kwot używane są typy numeryczne? Czy typy dat są standaryzowane?
- ☐ Możliwość wartości NULL: Czy pola wymagane są oznaczone jako NOT NULL?
- ☐ Indeksowanie: Czy kolumny używane w zapytaniach o wysokim obciążeniu są indeksowane?
- ☐ Rozdzielanie danych (sharding): Czy istnieje wykonalny klucz rozdzielania danych, jeśli przewiduje się skalowanie poziome?
- ☐ Ograniczenia: Czy ograniczenia są niezbędne dla logiki biznesowej, czy mogą być obsługiwane na poziomie warstwy aplikacji?
- ☐ Dokumentacja: Czy ERD została zaktualizowana w celu odzwierciedlenia ostatecznej implementacji?
🛡️ Integralność danych w rozproszonych środowiskach
W rozproszonym środowisku trudniej zapewnić właściwości ACID (atomowość, spójność, izolacja, trwałość) między węzłami. Zrozumienie skutków dla Twojego ERD jest kluczowe.
- Spójność ostateczna: Przyjmij, że dane mogą być tymczasowo niezgodne między replikami. Projektuj aplikację tak, aby mogła sprawnie obsługiwać ten stan.
- Idempotentność: Upewnij się, że operacje mogą być ponawiane bez skutków ubocznych. Jest to kluczowe w przypadku błędów sieciowych, gdy zapis może się powieść, ale potwierdzenie zostanie utracone.
- Rozwiązywanie konfliktów: Zdefiniuj sposób obsługi jednoczesnych aktualizacji tego samego rekordu. Zegary czasu lub zegary wektorowe mogą pomóc określić najnowszą wersję.
Włączając te rozważania do diagramu relacji encji, tworzysz system, który nie tylko działa dziś, ale jest również wystarczająco wytrzymały na jutro. Koszt zmiany schematu w środowisku produkcyjnym jest wykładniczo wyższy niż poprawne zaprojektowanie go od początku.
🔍 Podsumowanie najlepszych praktyk
Podsumowując, sukces w skalowaniu opiera się na dyscyplinowanym podejściu do modelowania danych. Skup się na jasnych definicjach, odpowiedniej normalizacji i strategicznym indeksowaniu. Unikaj skrótów, które naruszają integralność danych. Regularnie przeglądarkuj swoje diagramy w miarę rozwoju systemu. Statyczny ERD to obciążenie; żywy model to aktyw.
Inwestuj czas w fazie projektowania. Zwróci się to w niższych kosztach utrzymania i wyższej niezawodności systemu. Twoi użytkownicy nigdy nie zobaczą diagramu, ale poczują wydajność systemu, który on obsługuje.