











W złożonym świecie inżynierii backendu dane są fundamentem, na którym budowane są aplikacje. Choć pisanie kodu do manipulowania danymi to podstawowa odpowiedzialność, zrozumienie samej struktury danych jest równie istotne. Diagram relacji encji (ERD) pełni rolę projektu tego układu. Jest to język wizualny, który przekazuje sposób przechowywania, łączenia i pobierania informacji. Dla programisty backendowego umiejętność płynnego czytania ERD to nie tylko przydatna umiejętność, ale podstawowe wymaganie do projektowania solidnych, skalowalnych i utrzymywalnych systemów.
Wiele programistów od razu przystępuje do pisania zapytań, nie w pełni zrozumiewając architektury schematu. Często prowadzi to do problemów z wydajnością, naruszeń integralności danych oraz trudnych zadań refaktoryzacji w przyszłości. Opanowanie sztuki interpretacji ERD daje Ci zdolność przewidywania, jak dane przepływają przez Twoją aplikację, oraz jak zmiany w jednym obszarze mogą się rozprzestrzenić na całą bazę danych. Ten przewodnik szczegółowo omawia mechanizmy czytania ERD, skupiając się na praktycznym zastosowaniu, a nie abstrakcyjnej teorii.
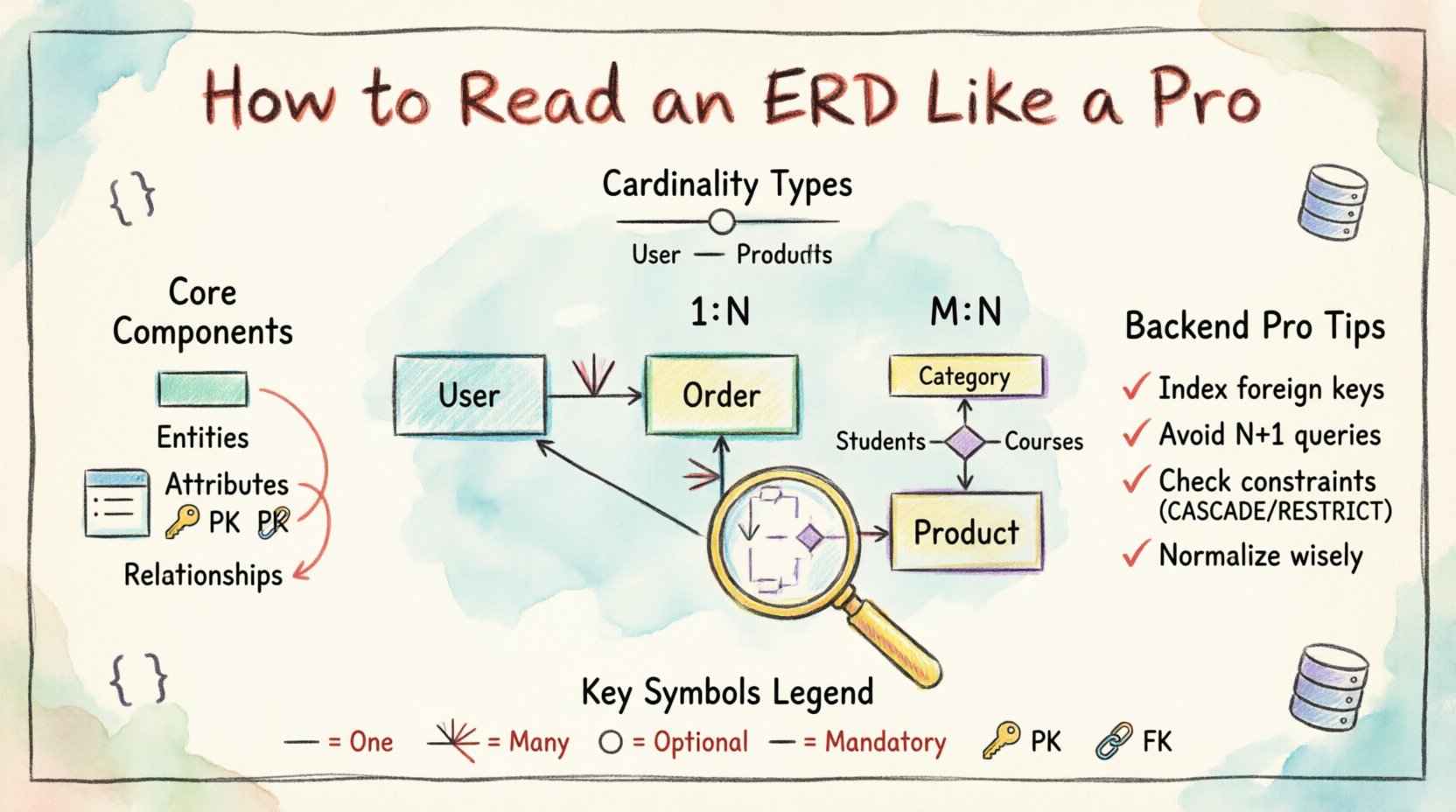
Zrozumienie podstawowych elementów diagramu ERD 🧱
Zanim przejdziesz do analizy połączeń, musisz zrozumieć poszczególne symbole tworzące diagram. Diagram ERD składa się z kilku różnych elementów, z których każdy reprezentuje konkretny aspekt modelu danych. Szybkie rozpoznanie tych elementów pozwala Ci analizować złożone schematy bez utraty orientacji w liniach.
1. Encje (Tabele)
Najbardziej wyraźnym elementem diagramu ERD jest encja. W kontekście bazy danych relacyjnych encja odpowiada bezpośrednio tabeli. Reprezentuje ona wyraźny obiekt lub pojęcie, o którym przechowywane są dane. Gdy widzisz prostokąt oznaczony nazwą taką jakKlient lub Zamówienie, patrzysz na tabelę.
- Wizualny wskaźnik:Zazwyczaj prostokąt lub pudełko zawierające nazwę.
- Funkcja:Grupuje powiązane atrybuty danych.
- Skutki dla backendu:Każda encja zwykle odpowiada klasie lub modelowi w Twoim kodzie.
Podczas czytania encji zwróć uwagę na tekst wewnątrz. Czasem zawiera on wyraźnie wymienione atrybuty (kolumny). Inne razy jest to abstrakcyjne przedstawienie, gdzie szczegóły są przechowywane w osobnym pliku dokumentacji. W każdym przypadku nazwa encji mówi Ci, o jakim rzeczonym elemencie systemu mowa.
2. Atrybuty (Kolumny)
Atrybuty definiują właściwości encji. Jeśli encja to tabela, atrybuty to kolumny w tej tabeli. Opisują one konkretne punkty danych wymagane dla każdego rekordu.
- Klucz główny:Często podkreślony lub oznaczony ikoną klucza. Unikalnie identyfikuje każdy wiersz.
- Klucz obcy:Często oznaczony linią łączącą z inną encją. Ustanawia relację.
- Typy danych:Choć nie zawsze są one pokazywane wizualnie, doświadczony czytelnik wnioskuje o typ danych na podstawie kontekstu (np. pole o nazwieemail_addressoznacza ciąg znaków, created_atoznacza znacznik czasu).
Zrozumienie atrybutów jest kluczowe dla pisania wydajnych zapytań. Jeśli atrybut nie jest indeksowany, jego wyszukiwanie spowoduje pełne skanowanie tabeli. Jeśli jest kluczem obcym, określa operacje łączenia.
3. Relacje (linie)
Relacje określają, jak encje wzajemnie na siebie oddziałują. Te linie łączą dwie encje i opisują liczność (ile). Jest to najważniejsza część odczytywania diagramu ERD pod kątem logiki backendowej, ponieważ decyduje o tym, jak dane są powiązane między tabelami.
- Kierunek:Linie często mają strzałki lub symbole na końcach, aby pokazać kierunek.
- Liczność:Określa, czy relacja jest jedno-do-jednego, jedno-do-wielu lub wiele-do-wielu.
- Opcjonalność:Czasem oznaczana przez linie pełne w porównaniu do przerywanych, pokazując, czy relacja jest obowiązkowa czy opcjonalna.
Dekodowanie liczności i relacji 🔗
Liczność to serce diagramu ERD. Określa ograniczenia i logikę relacji w bazie danych. Nieprawidłowe rozumienie liczności może prowadzić do duplikacji danych lub do utraconych rekordów. Przeanalizujmy trzy główne typy relacji, z którymi się spotkasz.
1. Jedno-do-jednego (1:1)
Relacja ta istnieje, gdy pojedynczy rekord w tabeli A jest powiązany dokładnie z jednym rekordem w tabeli B, i odwrotnie.
- Przypadek użycia:Dzielenie dużych tabel pod kątem bezpieczeństwa lub wydajności. Na przykład, tabela Użytkownik profil może być rozdzielony od tabeli Użytkownik_Ustawienia tabeli.
- Realizacja:Klucz obcy w jednej tabeli odnosi się do klucza głównego w drugiej, często z ograniczeniem unikalności.
- Wpływ na backend:Łączenia są zwykle niezbędne do pobrania pełnych danych, ale logika jest prosta.
2. Jedno-do-wielu (1:N)
To najpowszechniejsza relacja w bazach danych relacyjnych. Jeden rekord w tabeli A może być powiązany z wieloma rekordami w tabeli B, ale każdy rekord w tabeli B jest powiązany tylko z jednym rekordem w tabeli A.
- Przypadek użycia:Tabela Kategoriazawierająca wiele Produktów.
- Realizacja: Klucz obcy znajduje się w tabeli strony „Wiele” (Products), odnoszącej się do strony „Jedno” (Category).
- Wpływ na backend: Podczas pobierania kategorii często ładujesz listę produktów. Podczas pobierania produktu ładujesz jedną kategorię.
3. Wiele do wielu (M:N)
Taka relacja występuje, gdy rekordy w tabeli A mogą być powiązane z wieloma rekordami w tabeli B, a rekordy w tabeli B mogą być powiązane z wieloma rekordami w tabeli A.
- Przykład użycia: Studenci zapisujący się na wiele Klas, a klasy mające wielu uczniów.
- Realizacja: Nie może być bezpośrednio przedstawiona za pomocą jednego klucza obcego. Wymaga tabeli pośredniej (lub mostowej), aby rozwiązać relację na dwie relacje jeden do wielu.
- Wpływ na backend: Zapytania często obejmują trzy tabele. Musisz jawnie obsłużyć tabelę pośrednią w kodzie, aby zarządzać powiązaniami.
Tabela: Podsumowanie liczby relacji
| Typ relacji | Przykładowy scenariusz | Strategia implementacji | Złożoność zapytania |
|---|---|---|---|
| Jeden do jednego (1:1) | Użytkownik & Profil | Unikalny klucz obcy | Niska (jedno połączenie) |
| Jeden do wielu (1:N) | Autor & Książki | Klucz obcy po stronie Wiele | Średnia (połączenie listy) |
| Wiele do wielu (M:N) | Studenci & Kursy | Tabela pośrednia | Wysoka (połączenie trzech tabel) |
Style notacji i symbole 📐
Choć koncepcje pozostają spójne, notacja wizualna może się różnić w zależności od osoby, która stworzyła schemat. Znajomość powszechnych stylów zapewnia, że nie przegapisz subtelnych szczegółów.
Notacja kłykci (Crow’s Foot)
Jest szeroko stosowana w nowoczesnych narzędziach projektowania baz danych. Używa określonych symboli na końcu linii relacji, aby oznaczać liczność.
- Linia pojedyncza: Oznacza „Jeden”.
- Kłykcie (trzy gałęzie): Oznacza „Wiele”.
- Koło: Oznacza „Opcjonalny” (Zero).
- Pionowa kreska: Oznacza „Obowiązkowy” (Jeden).
Na przykład linia z pojedynczą kreską z jednej strony i kłykciem z drugiej oznacza relację „Jeden do wielu”, gdzie strona „Jeden” jest obowiązkowa.
Notacja Chen
Mniej powszechna w rozwoju aplikacji, ale często używana w kontekstach akademickich lub architektonicznych najwyższego poziomu. Zamiast linii używa rombów do oznaczania relacji.
- Obiekty:Prostokąty.
- Relacje:Rombów.
- Atrybuty:Owali.
Przy czytaniu notacji Chen skup się na kształcie rombu. Etikiety liczności (1, N, M) umieszcza się na liniach łączących romb z obiektami.
Klucze i ograniczenia: Zasady gry 🔑
Schemat ERD nie dotyczy tylko połączeń; dotyczy zasad. Ograniczenia zapewniają integralność danych. Jako developer backendu musisz wiedzieć, które ograniczenia są realizowane przez bazę danych, a które należy obsłużyć w logice aplikacji.
Klucze główne (PK)
Każda tabela powinna mieć klucz główny. Ta wartość jednoznacznie identyfikuje każdy wiersz. Przy czytaniu schematu ERD szukaj atrybutu podkreślonego.
- Klucze zastępcze:Automatycznie zwiększane liczby całkowite (np. ID), które nie mają znaczenia biznesowego.
- Klucze naturalne:Identyfikatory biznesowe (np. Email, SKU), które są unikalne z natury.
Dlaczego to ma znaczenie:Klucze obce odnoszą się do kluczy głównych. Jeśli zmienisz strategię klucza głównego (np. UUID w porównaniu do liczby całkowitej), musisz zaktualizować wszystkie zależne klucze obce oraz potencjalnie przebudować warstwy pamięci podręcznej aplikacji.
Klucze obce (FK)
Klucz obcy to pole (lub zbiór pól) w jednej tabeli, które odnosi się do klucza głównego w innej tabeli. Zapewnia integralność referencyjną.
- PO USUNIĘCIU KASKADOWYM: Jeśli rekord nadrzędny zostanie usunięty, rekordy potomne są automatycznie usuwane.
- PO USUNIĘCIU ZABLOKOWANYM: Zapobiega usunięciu rekordu nadrzędnego, jeśli istnieją rekordy potomne.
- PO USUNIĘCIU USTAW NA NULL: Ustawia kolumnę klucza obcego na NULL, jeśli rekord nadrzędny zostanie usunięty.
Zrozumienie tych zachowań jest kluczowe podczas tworzenia punktów końcowych usuwania. Usunięcie kaskadowe może mieć niepożądane skutki uboczne, jeśli graf relacji jest złożony.
Normalizacja i struktura danych 🧹
Podczas analizy diagramu ER należy również ocenić poziom normalizacji. Normalizacja zmniejsza nadmiarowość danych i poprawia integralność. Jednak nie zawsze jest ścisłym wymaganiem pod kątem wydajności.
Pierwsza postać normalna (1NF)
Wszystkie kolumny muszą zawierać wartości atomowe. Nie ma list ani tablic w jednym polu. Jeśli widzisz kolumnę o nazwietagi zawierającą„tag1, tag2, tag3”, schemat narusza 1NF.
Druga postać normalna (2NF)
Muszą być w 1NF, a wszystkie atrybuty niekluczowe muszą być całkowicie zależne od klucza głównego. Często oznacza to przeniesienie atrybutów zależnych tylko od części klucza złożonego do osobnej tabeli.
Trzecia postać normalna (3NF)
Muszą być w 2NF i nie może istnieć zależność przechodnia. JeśliAokreślaB, aBokreślaC, następnie A określa C. W 3NF, C nie powinno istnieć w tej samej tabeli co B.
Denormalizacja w praktyce
Choć normalizacja jest teoretycznym ideałem, w programowaniu zaplecza często wymagana jest denormalizacja dla wydajności. Możesz zobaczyć powtarzające się dane na diagramie ERD zaprojektowanym pod kątem szybkości.
- Odczyt vs. Zapis: Normalizowane schematy są lepsze dla zapisu; denormalizowane schematy są lepsze dla odczytu.
- Buforowanie: Czasem dane są powielane, aby zmniejszyć liczbę operacji JOIN w wysokoprzepustowych punktach końcowych.
Gdy widzisz nadmiarowe dane na diagramie ERD, zastanów się dlaczego. Czy to błąd projektowy, czy celowa strategia optymalizacji?
Czytanie do optymalizacji zaplecza 🚀
Czytanie diagramu ERD to nie tylko zrozumienie przechowywania danych; to przewidywanie wydajności. Dobrze przeczytany schemat pozwala pisać zapytania wykorzystujące indeksy skutecznie.
Identyfikowanie możliwości indeksowania
Szukaj atrybutów, które często są używane w filtrach wyszukiwania lub operacjach sortowania. Powinny one być indeksowane.
- Kolumny wyszukiwania: Atrybuty używane w klauzulach WHERE.
- Kolumny łączenia: Klucze obce powinny być indeksowane prawie zawsze, aby przyspieszyć operacje JOIN.
- Kolumny sortowania: Atrybuty używane w klauzulach ORDER BY.
Unikanie zapytań N+1
Diagram ERD ujawnia strukturę relacji. Jeśli masz relację jeden do wielu, pobieranie rodzica, a następnie pętla pobierająca dzieci pojedynczo, tworzy problem zapytań N+1.
- Rozwiązanie: Użyj ładowania zgodnego (eager loading) lub jawnych JOIN-ów opartych na ścieżce relacji zdefiniowanej na diagramie ERD.
- Ostrzeżenie:Złożone relacje wiele do wielu mogą łatwo prowadzić do problemów z wydajnością, jeśli tabela pośrednicząca nie jest indeksowana na obu kolumnach kluczy obcych.
Typowe pułapki w projektowaniu schematu ⚠️
Nawet doświadczeni architekci popełniają błędy. Przy czytaniu diagramu ERD szukaj oznak złego projektowania, które mogą spowodować problemy w przyszłości.
1. Zależności cykliczne
Gdy encja A zależy od encji B, a encja B zależy od encji A, tworzysz zależność cykliczną. Może to prowadzić do zakleszczeń podczas zatwierdzania transakcji lub skomplikowanej logiki inicjalizacji.
2. Nierównowaga liczności
Czasem relacja wiele do wielu jest niepoprawnie modelowana jako jedna do wielu w obu kierunkach, co prowadzi do duplikacji danych lub utraty informacji.
3. Brak metadanych
Diagram ERD bez znaczników czasu (created_at, updated_at) utrudnia audyt i debugowanie. Systemy backendowe często wymagają tej informacji do miękkich usuwań lub wersjonowania.
4. Nadmierna normalizacja
Zbyt wiele tabel może sprawiać, że proste zapytania wymagają nadmiernych połączeń, spowalniając aplikację. Szukaj tabel, które można logicznie połączyć, jeśli mają ten sam cykl życia.
Zastosowanie praktyczne: od diagramu do kodu 💻
Po zrozumieniu diagramu ERD następnym krokiem jest przekształcenie go w logikę aplikacji. Ten proces polega na mapowaniu modelu wizualnego na kod aplikacji.
1. Mapowanie modelu
Każda encja staje się klasą lub modelem w Twoim kodzie. Atrybuty stają się właściwościami. Relacje stają się powiązaniami lub metodami.
- Jeden do jednego: Właściwość pojedynczego obiektu.
- Jeden do wielu: Właściwość kolekcji lub listy.
- Wiele do wielu: Kolekcja powiązanych modeli poprzez most.
2. Projektowanie interfejsu API
Diagram ERD określa strukturę Twojego interfejsu API. Normalizowany schemat często prowadzi do zagnieżdżonych odpowiedzi JSON lub oddzielnych punktów końcowych dla powiązanych zasobów. Na przykład, punkt końcowy /orders może zawierać strukturę zagnieżdżoną /order-items zagnieżdżoną strukturę.
3. Logika walidacji
Ograniczenia w diagramie ERD (takie jak NOT NULL) powinny być odbite w walidacji na poziomie aplikacji. Jeśli baza danych pozwala na wartość NULL, ale logika biznesowa wymaga wartości, aplikacja musi zapewnić przestrzeganie tego reguły przed wysłaniem danych do bazy danych.
Utrzymanie integralności schematu w czasie 🔧
ERD nie jest statyczny. W miarę rozwoju aplikacji zmienia się schemat. Twoja zdolność do odczytywania ERD pomaga skutecznie zarządzać migracjami.
1. Obsługa migracji
Gdy dodajesz nową tabelę lub relację, od razu aktualizuj ERD. Zapewnia to, że Twój zespół ma aktualny obraz systemu. Migracje powinny być wersjonowane i testowane względem bieżącej struktury schematu.
2. Refaktoryzacja
Refaktoryzacja często wiąże się z dzieleniem tabel lub ich łączeniem. Zrozumienie linii relacji pomaga określić, które dane należy przemieścić, a które klucze obce należy zaktualizować.
3. Dokumentacja
ERD to dokument żywy. Jeśli schemat nie odpowiada bazie danych, jest bezużyteczny. Regularne audyty zapewniają, że reprezentacja wizualna odpowiada rzeczywistości fizycznej.
Zaawansowane koncepcje: relacje rekurencyjne 🔁
Czasem jednostka jest związana sama z sobą. Nazywa się to relacja rekurencyjna.
- Przykład: Jednostka Employee jednostka, w której jeden pracownik jest szefem innych.
- Realizacja: Klucz obcy w tej samej tabeli wskazuje na klucz główny tej samej tabeli.
- Logika backendu:Wymaga zapytań rekurencyjnych lub algorytmów przeszukiwania, aby znaleźć wszystkich podwładnych lub pełną hierarchię.
Rozpoznawanie tego wzorca na ERD jest kluczowe do tworzenia funkcji takich jak wykresy organizacyjne lub komentarze wątkowe.
Podsumowanie najważniejszych wniosków 📝
Opanowanie ERD to ciągły proces obserwacji i ćwiczeń. Wymaga cierpliwości, by śledzić każdą linię i zrozumieć konsekwencje każdego symbolu. Skupiając się na składnikach, relacjach i ograniczeniach, budujesz model umysłowy, który prowadzi Twoją pracę.
- Znajdź swoje symbole:Rozróżnij jednostki, atrybuty i relacje.
- Zrozum związek liczności:Wiedz, jaka jest różnica między 1:1, 1:N i M:N.
- Sprawdź ograniczenia:Szukaj kluczy i reguł nullowalności.
- Zastanów się nad wydajnością:Używaj ERD do planowania indeksowania i optymalizacji zapytań.
- Trzymaj go aktualnym: Upewnij się, że schemat odzwierciedla aktualny stan bazy danych.
Kiedy kontynuujesz swoją drogę jako deweloper backendu, niech ERD będzie twoim kompasem. Daje on kontekst potrzebny do podejmowania świadomych decyzji dotyczących architektury danych, zapewniając, że systemy, które budujesz, są nie tylko funkcjonalne, ale także wytrzymałe i wydajne.
Ostateczne rozważania na temat biegłości w zakresie schematów 🎓
Umiejętność skutecznego czytania ERD dzieli koderów od inżynierów. Przesuwa uwagę z prostego uruchamiania kodu na zrozumienie, jak dane zachowują się pod obciążeniem, jak są trwale przechowywane oraz jak są powiązane z innymi danymi. Ta umiejętność zmniejsza czas debugowania, poprawia współpracę z zespołami danych i prowadzi do lepszej architektury systemu.
Poświęć czas na analizę schematów w swoich projektach. Zadawaj pytania dotyczące przyczyn wyboru określonych relacji. Wyzwania projektowanie, gdy zauważysz nieefektywności. W ten sposób przyczyniasz się do zdrowiejszego ekosystemu danych i bardziej stabilnej aplikacji.
Pamiętaj, że baza danych jest źródłem prawdy. Traktuj ERD jak mapę do tej prawdy. Dzięki praktyce czytanie tych schematów stanie się naturalne, pozwalając Ci bezpiecznie i precyzyjnie poruszać się po skomplikowanych przestrzeniach danych.