











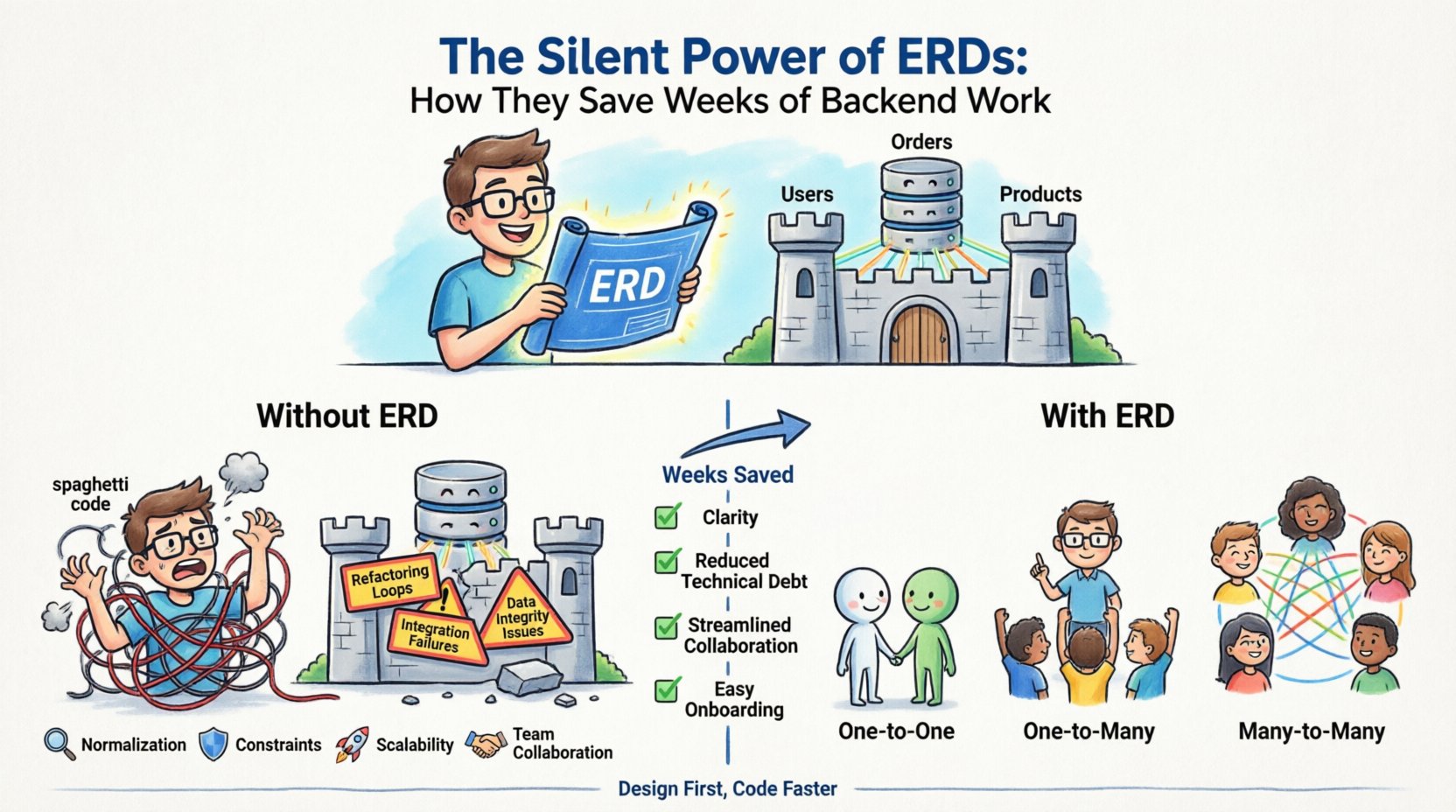
Rozwój backendu często przypomina budowę domu bez projektu. Zaczynasz kłaść cegły, dodawać okna i montować ściany na podstawie intuicji. Czasem działa. Często nie. Po kilku tygodniach okazuje się, że musisz demontować ściany, by dopasować drzwi, które zapomniano zaplanować. Tak wygląda codzienność programowania bez solidnego Diagram relacji encji (ERD). ERD to cichy architekt Twojej infrastruktury danych, działający w tle, by zapobiegać kosztownym awariom strukturalnym. Gdy poświęcasz czas na projektowanie modelu danych przed napisaniem jednej linii kodu, zdobywasz jasność, zmniejszasz dług techniczny i ułatwiasz współpracę między zespołami.
Ten przewodnik bada rzeczywisty wpływ ERD na przepływy pracy backendu. Przeanalizujemy mechanizmy modelowania danych, ukryte koszty pomijania projektowania oraz strategiczne zalety dobrze dokumentowanego schematu. Zrozumienie tych zasad pozwoli Ci przejść od reaktywnej programowania do proaktywnej architektury.
Czym dokładnie jest ERD? 📐
Diagram relacji encji to wizualne przedstawienie struktury logicznej bazy danych. Pokazuje, jak różne fragmenty danych są ze sobą powiązane. Można go porównać do mapy pamięci Twojej aplikacji. Bez tej mapy programiści poruszają się na oślep, ryzykując kolizje między punktami danych, które powinny pozostać oddzielone.
W esencji ERD składa się z trzech głównych elementów:
- Encje: Odnoszą się do obiektów lub pojęć, które śledzisz. W bazie danych odpowiadają im tabele. Przykłady to Użytkownicy, Zamówienia, lub Produkty.
- Atrybuty: To konkretne właściwości encji. Stają się kolumnami w Twoich tabelach. Dla encji Użytkownik encji atrybuty mogą obejmować email, hash_hasła, oraz utworzono_w.
- Związki: Określają, jak encje ze sobą współdziałają. Wyznaczają liczność i połączenia między tabelami, takie jak Użytkownik mający wiele Zamówienia.
Choć koncepcja wydaje się prosta, złożoność pojawia się w momencie zarządzania skalą. Prosty blog może wymagać tylko kilku tabel. System przedsiębiorstwa wymaga dziesiątek, a nawet setek połączonych ze sobą encji. Diagram ERD działa jako jedyny źródło prawdy dla wszystkich tych interakcji.
Ukryte koszty pomijania projektowania 💸
Wiele zespołów programistycznych spieszy się z kodowaniem, by spełnić terminy. Przypuszczają, że później można przepisać bazę danych. To niebezpieczne założenie. Zmiana schematu bazy danych jest znacznie bardziej kosztowna niż zmiana logiki aplikacji. Gdy dane są już zapisane, zmiana ich struktury wymaga skryptów migracji, potencjalnego czasu przestoju oraz ostrożnego obsługi istniejących rekordów.
Zastanów się nad poniższymi scenariuszami, w których brak diagramu ERD powoduje trudności:
- Pętle przepisywania: Budujesz funkcjonalność, uświadamiasz sobie, że struktura danych jej nie wspiera, i musisz przepisać zapytania. Ten cykl powtarza się, zużywając tygodnie czasu sprintu.
- Niepowodzenia integracji: Gdy zespoły frontendu i backendu pracują bez wspólnego określenia schematu, interfejsy API często przestają działać. Backend wysyła jedną strukturę; frontend oczekuje innej.
- Problemy z integralnością danych: Bez zdefiniowanych ograniczeń do systemu wpływa nieprawidłowa data. Musisz ręcznie czyścić zanieczyszczone rekordy lub naprawiać niezgodne stany.
- Opóźnienia w onboardowaniu: Nowi programiści mają trudności z zrozumieniem systemu. Spędzają dni czytając kod zamiast tworzyć funkcjonalności, ponieważ przepływ danych nie jest dokumentowany.
Do momentu, gdy zauważysz problem, koszt się zwiększył. „Naprawa” wymaga teraz nie tylko zmian kodu, ale także migracji danych, testów i weryfikacji wdrożenia.
Mapowanie relacji jak profesjonalista 🔗
Zrozumienie, jak dane są ze sobą powiązane, to serce projektowania diagramu ERD. Relacje decydują o tym, jak są pisane zapytania oraz jak optymalizowana jest wydajność. Musisz jasno zdefiniować trzy podstawowe typy relacji.
Poniższa tabela przedstawia różnice między tymi typami relacji:
| Typ relacji | Definicja | Przykładowy scenariusz | Uwaga implementacyjna |
|---|---|---|---|
| Jeden do jednego (1:1) | Pojedynczy rekord w tabeli A jest powiązany z dokładnie jednym rekordem w tabeli B. | Profil użytkownika powiązany z tabelą ustawień użytkownika. | Często realizowane przez umieszczenie klucza podstawowego B w A. |
| Jeden do wielu (1:N) | Pojedynczy rekord w tabeli A jest powiązany z wieloma rekordami w tabeli B. | Kategoria zawierająca wiele produktów. | Standardowe umieszczenie klucza obcego w tabeli „wielu”. |
| Wiele do wielu (M:N) | Wiele rekordów w tabeli A powiązanych jest z wieloma rekordami w tabeli B. | Studenci zapisani na wiele kursów. | Wymaga tabeli pośredniej do rozwiązania połączenia. |
Ignorowanie tych różnic prowadzi do nieefektywnych zapytań. Na przykład przechowywanie listy identyfikatorów produktów w jednym kolumnie dla kategorii narusza zasady normalizacji. Zmusza Cię to do analizy ciągów znaków zamiast korzystania z łączeń, co spowalnia wydajność wraz ze wzrostem danych.
Normalizacja: utrzymywanie danych czystych 🧹
Normalizacja to proces organizowania danych w celu zmniejszenia nadmiarowości i poprawy integralności. Choć nowoczesne systemy czasem odchylają się od ściślej znormalizowanej struktury dla poprawy wydajności, zrozumienie zasad nadal jest niezbędne.
Standardowe formy normalizacji obejmują:
- Pierwsza forma normalna (1NF):Gwarantuje atomowość. Każda kolumna zawiera tylko jedną wartość. Brak list lub tablic w jednym polu.
- Druga forma normalna (2NF):Opiera się na 1NF. Wymaga, aby wszystkie atrybuty niekluczowe były całkowicie zależne od klucza głównego. Brak częściowych zależności.
- Trzecia forma normalna (3NF):Opiera się na 2NF. Wymaga, aby atrybuty niekluczowe zależały wyłącznie od klucza głównego, a nie od innych atrybutów niekluczowych.
Dlaczego to ma znaczenie? Rozważ tabelę Zamówienie tabelę. Jeśli przechowujesz Imię i nazwisko klienta w każdym wierszu zamówienia, tworzysz nadmiarowość. Jeśli klient zmieni swoje imię, musisz zaktualizować tysiące wierszy. Jeśli przeoczyłeś jeden, dane stają się niezgodne. Przenosząc Imię i nazwisko klienta do tabeli Klienci i łącząc poprzez identyfikator, zapewnicasz jednoznaczną źródłową prawdę.
Jednak normalizacja nie jest rozwiązaniem na wszystkie przypadki. Nadmierna normalizacja może prowadzić do skomplikowanych łączeń, które pogarszają wydajność. Celem jest równowaga. Musisz zrozumieć kompromisy między efektywnością przechowywania danych a szybkością zapytań.
Typowe pułapki w projektowaniu schematu 🚧
Nawet doświadczeni programiści popełniają błędy podczas projektowania ERD. Rozpoznanie tych typowych pułapek może zaoszczędzić Ci dużego stresu w przyszłości.
- Zależności cykliczne: Encja A potrzebuje encji B, a encja B potrzebuje encji A. Powoduje to zamknięcie w pętli podczas inicjalizacji i utrudnia pisanie skryptów migracji.
- Brakujące ograniczenia: Niezdefiniowanie kluczy obcych, ograniczeń unikalności lub ograniczeń sprawdzających pozwala nieprawidłowym danym na przejście między przerwami. Baza danych powinna wymuszać zasady, a nie kod aplikacji.
- Wartości zakodowane w kodzie:Przechowywanie kodów stanu, takich jak „aktywny” lub „nieaktywny”, jako liczb całkowitych bez tabeli odnośników sprawia, że system jest kruchy. Jeśli chcesz dodać „wstrzymanie”, musisz zmienić logikę wszędzie.
- Ignorowanie miękkich usuwań:Trwałe usuwanie danych usuwa historię. Projektowanie z myślą o miękkich usunięciach (oznaczanie rekordu jako usuniętego zamiast jego usunięcia) zachowuje śledzenie zmian.
- Zbyt skomplikowane projektowanie:Projektowanie dla przypadku użycia, który jeszcze nie istnieje. Projektuj zgodnie z obecnymi wymaganiami, ale upewnij się, że schemat jest wystarczająco elastyczny, aby radzić sobie z rozsądnym wzrostem.
Każda z tych pułapek dodaje warstwy złożoności do Twojego kodu. Diagram ERD pomaga Ci wizualizować te problemy, zanim zostaną one wbudowane w produkcji.
Od diagramu do wdrożenia 🚀
Po finalizacji diagramu ERD następnym krokiem jest jego przekształcenie w kod. Ten proces, często nazywany migracją schematu, wymaga dyscypliny.
Postępuj zgodnie z tymi krokami, aby zapewnić płynny przejście:
- Kontrola wersji:Traktuj schemat bazy danych jak kod aplikacji. Każda zmiana powinna być plikiem migracji przechowywanym w twoim repozytorium.
- Zgodność wsteczna: Przy dodawaniu kolumny najpierw zrób ją nullowalną. Wypełnij istniejące dane, a następnie na kolejnej migracji zastosuj ograniczenie. To zapobiega przestojom.
- Testowanie migracji: Uruchamiaj skrypty migracji w środowisku testowym identycznym z produkcyjnym. Sprawdź, czy nie ma spadków wydajności.
- Planowanie cofnięcia: Zawsze musisz mieć możliwość cofnięcia migracji, jeśli się nie powiedzie. Przegrane dane są nieakceptowalne.
Narzędzia automatyzacji mogą pomóc w generowaniu SQL z diagramów ERD, ale recenzja ręczna jest kluczowa. Automatyczne generatory często pomijają subtelności logiki biznesowej, które zauważyłby człowiek.
Współpraca i komunikacja 🤝
Diagram ERD nie jest tylko dla administratorów baz danych. Służy jako narzędzie komunikacji dla całego zespołu. Menedżerowie produktu, deweloperzy frontendu i inżynierowie testów jakościowych wszystko zyskują z rozumienia struktury danych.
Gdy stakeholderzy przeglądarką diagram ERD, mogą wczesnie zidentyfikować potencjalne problemy:
- Możliwość zrealizowania funkcji: Czy baza danych może wspierać żądaną funkcję? Jeśli nie, jakie zmiany są potrzebne?
- Oczekiwania co do wydajności: Czy projekt pozwala na skuteczne zapytania w dużym zakresie?
- Wymagania dotyczące bezpieczeństwa: Czy wrażliwe pola zostały zidentyfikowane i zabezpieczone? Czy kontrola dostępu jest możliwa na poziomie danych?
To wspólne zrozumienie zmniejsza napięcie podczas planowania sprintów. Zamiast zgadywać, jak przepływa dane, zespół dyskutuje na podstawie wizualnego modelu. Zgody są rozwiązywane odwołując się do diagramu, a nie do opinii.
Rozważania dotyczące skalowalności 📈
W miarę jak Twoja aplikacja rośnie, model danych musi się rozwijać. Diagram relacji encji pomaga Ci przewidywać te zmiany. Umożliwia Ci wizualizację tego, jak dodanie nowej encji wpływa na istniejące relacje.
Kluczowe czynniki skalowalności do rozważenia podczas projektowania:
- Strategia indeksowania: Zidentyfikuj kolumny, które będą często wykonywane w zapytaniach. Zaprojektuj indeksy na tych polach, aby przyspieszyć pobieranie danych.
- Partycjonowanie: Czy pewne tabele będą rosły zbyt dużym tempem? Zaprojektuj partycjonowanie poziome, jeśli to konieczne.
- Podział odczytu/zapisu: Czy projekt wspiera osobne repliki do odczytu i zapisu? Upewnij się, że klucze obce nie komplikują replikacji.
- Warstwy buforowania: Jak model danych oddziałuje z systemami buforowania? Dane niezmienne są łatwiejsze do buforowania niż często zmieniające się dane.
Myślenie o skalowalności na wczesnym etapie zapobiega potrzebie całkowitej przebudowy później. Łatwiej dodać nową tabelę niż przenieść dane z jednego serwera na drugi.
Ostateczne rozważania nad architekturą danych 🧠
Wkład w stworzenie szczegółowego ERD przynosi zyski przez cały cykl życia projektu. Przekształca modelowanie danych z reaktywnej roboty w strategiczne zasoby. Wizualizując relacje, stosując ograniczenia i planując rozwój, budujesz systemy wytrzymałe i łatwe w utrzymaniu.
Nie traktuj bazy danych jako pochodzenia. Jest to fundament Twojej aplikacji. Inwestuj w fazę projektowania, a w dłuższej perspektywie oszczędzisz tygodnie pracy nad backendem. Cichą moc ERD stanowi jego zdolność do zapobiegania problemom jeszcze przed ich wystąpieniem.
Zacznij mapować swoje dane już dziś. Jasność, którą uzyskasz, będzie różnicą między chaotycznym kodem a zoptymalizowanym systemem.