











Projetar modelos de dados em uma arquitetura de microserviços exige uma mudança fundamental na forma de pensar em comparação com aplicativos monolíticos. Em um sistema tradicional, um único Diagrama de Relacionamento de Entidades (ERD) geralmente cobre todo o banco de dados. Em um ambiente distribuído, essa visão única se fragmenta em múltios esquemas independentes. O desafio está em manter a coerência sem acoplar os serviços entre si. Este guia explora como estruturar modelos de dados de forma eficaz, garantindo escalabilidade e resiliência, ao mesmo tempo em que evita os problemas comuns da gestão distribuída de dados.
Quando os serviços compartilham dados diretamente, eles herdam as dependências mútuas. Esse acoplamento rígido leva a sistemas frágeis, em que uma alteração em uma área quebra outra. O objetivo é criar fronteiras que permitam que as equipes implantem de forma independente. Alcançar isso exige planejamento cuidadoso de relacionamentos, modelos de consistência e padrões de integração.
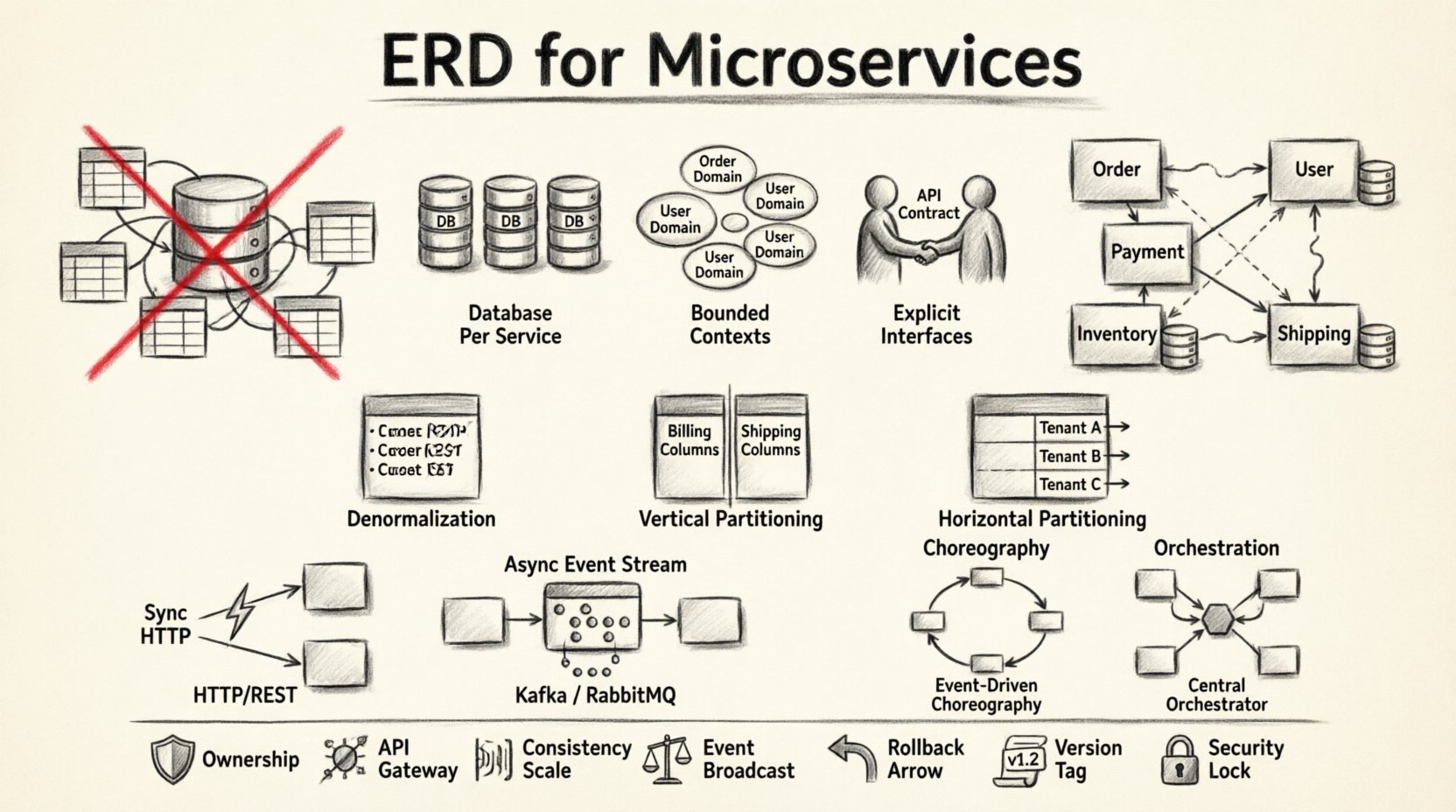
🧱 Por que os ERDs Tradicionais Falham em Sistemas Distribuídos
Um ERD padrão assume uma autoridade central. Ele mapeia tabelas, colunas e chaves estrangeiras dentro de uma única fronteira transacional. Os microserviços rejeitam essa centralização. Quando você aplica uma mentalidade de ERD monolítica a um sistema distribuído, corre o risco de criar um monólito distribuído. Isso acontece quando os serviços dependem de tabelas de banco de dados compartilhadas em vez de APIs definidas.
Os seguintes problemas geralmente surgem ao ignorar esses princípios:
- Acoplamento de Implantação:Alterações em uma tabela compartilhada exigem implantações simultâneas em múltiplos serviços.
- Fronteiras de Transação:Transações ACID abrangem múltiplos serviços, aumentando a latência e os pontos de falha.
- Bloqueio de Esquema:Blocos de banco de dados em um serviço podem travar solicitações em outro serviço.
- Problemas de Visibilidade:Nenhuma equipe única detém o estado global dos dados, levando a silos de dados.
Em vez de um único diagrama, você precisa de uma coleção de esquemas específicos para cada serviço que se comuniquem por meio de interfaces bem definidas. Essa abordagem prioriza a autonomia sobre a consistência imediata.
🧬 Princípios Fundamentais da Modelagem de Dados Distribuídos
Para manter a ordem, você deve seguir princípios arquitetônicos específicos. Essas diretrizes ajudam as equipes a tomar decisões sobre propriedade de dados e padrões de acesso.
1. Banco de Dados por Serviço
Cada microserviço deve possuir seu próprio armazenamento de dados. Isso garante que o esquema interno de um serviço não seja visível para os outros. Se o Serviço A precisar de dados do Serviço B, ele deve solicitá-los por meio de uma API, e não consultar o banco de dados diretamente. Essa isolamento protege a integridade de cada domínio.
- Os serviços gerenciam sua própria evolução de esquema.
- As equipes podem escolher a melhor tecnologia de banco de dados para suas necessidades específicas (persistência poliglota).
- Falha em um banco de dados não causa o colapso de todo o aplicativo.
2. Contextos Delimitados
Os dados devem estar alinhados com as capacidades de negócios. No design orientado a domínio, um Contexto Delimitado define a fronteira semântica de um modelo. Dois serviços podem usar o termo “Cliente”, mas os dados dentro desses contextos diferem. Um pode armazenar detalhes de contato, enquanto o outro armazena histórico financeiro. Mesclar esses contextos em um único ERD cria confusão e dívida técnica.
3. Interfaces Explícitas
Como os serviços não conseguem ver diretamente os dados uns dos outros, a API torna-se o contrato de dados. O esquema da resposta da API define a realidade dos dados para o consumidor. Isso desacopla a implementação interna de armazenamento da utilização externa.
📐 Padrões de Projeto de Esquema para Independência
Projetar esquemas para microserviços envolve padrões específicos para lidar com relacionamentos que tradicionalmente seriam tratados por chaves estrangeiras. Você não pode confiar em restrições de nível de banco de dados para impor relacionamentos entre serviços.
Denormalização
Em um monólito, a normalização reduz a redundância. Nos microserviços, a denormalização é frequentemente preferida. Armazenar dados duplicados reduz a necessidade de chamadas remotas. Por exemplo, um Serviço de Pedidos pode armazenar o nome e o endereço do cliente dentro do registro do pedido. Isso evita uma consulta síncrona ao Serviço de Usuário toda vez que um pedido é exibido.
- Benefício:Desempenho de leitura mais rápido e menos saltos de rede.
- Risco:Inconsistência de dados se os dados de origem forem alterados. Você deve lidar com atualizações por meio de eventos.
Particionamento Vertical
Divida tabelas grandes em conjuntos menores e focados. Se uma tabela contém informações de faturamento e endereços de entrega, separe essas preocupações. Os dados de faturamento podem pertencer a um Serviço de Pagamentos, enquanto os endereços de entrega pertencem a um Serviço de Logística. Isso reduz a área de superfície para mudanças e melhora a segurança limitando o acesso.
Particionamento Horizontal
Divida os dados com base no ID do cliente ou na região geográfica. Isso é útil para escalar serviços específicos sem afetar os outros. Permite que você repita serviços para regiões com alto tráfego, mantendo os demais leves.
| Padrão | Melhor Caso de Uso | Consideração Principal |
|---|---|---|
| Denormalização | Cargas de trabalho com leituras intensivas | Requer lógica de sincronização |
| Particionamento Vertical | Domínios distintos | Fronteiras de API claras |
| Particionamento Horizontal | Alta escala / Multi-inquilinato | Complexidade da lógica de roteamento |
🔄 Gerenciamento de Relacionamentos e Consistência
A parte mais difícil do modelamento de dados em microserviços é manter a consistência sem transações distribuídas. Você precisa escolher entre consistência forte e consistência eventual.
Comunicação Síncrona
Os serviços podem se chamar diretamente por meio de HTTP ou gRPC. Isso fornece consistência forte para operações imediatas. No entanto, introduz latência e cria uma cadeia de dependências. Se o Serviço A chamar o Serviço B, e o Serviço B estiver fora do ar, o Serviço A falhará.
Comunicação Assíncrona
Os serviços se comunicam por meio de filas de mensagens ou fluxos de eventos. Isso desacopla o tempo das operações. O Serviço A publica um evento, e o Serviço B o consome posteriormente. Isso suporta consistência eventual.
- Prós:Resiliência, escalabilidade e acoplamento fraco.
- Contras:Os dados são temporariamente inconsistentes. Depurar exige rastreamento em múltiplos logs.
🗓️ O Padrão Saga para Integridade de Dados
Uma saga é uma sequência de transações locais. Cada transação atualiza o banco de dados local e publica um evento para acionar a próxima etapa. Se uma etapa falhar, a saga executa transações compensatórias para desfazer alterações anteriores.
Coreografia versus Orquestração
Sagas podem ser implementadas de duas formas:
- Coreografia:Os serviços escutam eventos e decidem o que fazer em seguida. Não há um controlador central. Isso é flexível, mas mais difícil de visualizar.
- Orquestração:Um coordenador central informa aos serviços o que fazer. Isso oferece melhor visibilidade e controle sobre o fluxo de trabalho, mas introduz um ponto único de falha.
Ao modelar ERDs para sagas, você deve levar em conta as mudanças de estado. Cada serviço envolvido em uma saga precisa armazenar seu estado para lidar com rollback. Isso significa que seu esquema deve suportar estados transacionais, e não apenas dados finais.
📝 Gerenciamento da Evolução de Esquemas
A evolução de esquemas é inevitável. Os campos mudam, os tipos se alteram e as restrições são flexibilizadas. Em um sistema distribuído, você não pode alterar um esquema de banco de dados enquanto outros serviços dependem dele. Você deve planejar a versão.
Compatibilidade com Versões Anteriores
Sempre mantenha compatibilidade com versões anteriores. Ao adicionar um novo campo, não remova o antigo imediatamente. Permita que os consumidores façam a migração gradualmente. Se for necessário mudar o nome de um campo, crie um apelido para o nome antigo durante o período de transição.
Estratégias de Versão
- Versão no URI:Inclua números de versão na rota da API.
- Versão por Cabeçalho:Use cabeçalhos personalizados para especificar a versão esperada do esquema.
- Negociação de Conteúdo:Use cabeçalhos HTTP padrão para solicitar tipos de mídia específicos.
A documentação deve ser mantida em sincronia com o código. Testes automatizados devem verificar se o contrato da API corresponde ao esquema. Isso evita que mudanças quebradas cheguem à produção.
🛡️ Armadilhas Comuns para Evitar
Mesmo com um plano sólido, as equipes frequentemente tropeçam em questões específicas. O conhecimento dessas armadilhas ajuda na criação de um sistema robusto.
1. A Armadilha do Banco de Dados Compartilhado
Não compartilhe tabelas entre serviços. Isso cria um acoplamento oculto. Se o serviço de Pagamento ler a tabela do serviço de Pedidos, ele saberá demais sobre a estrutura interna. Isso leva a um acoplamento rígido e conflitos de implantação.
2. Sobrenormalização
Tentar normalizar dados entre serviços leva a junções excessivas e chamadas de rede. Aceite alguma redundância. É melhor ter dados duplicados do que um sistema lento e acoplado.
3. Ignorar Idempotência
Chamadas de rede falham. Mensagens são duplicadas. Seu esquema e a lógica da API devem lidar com solicitações duplicadas sem causar erros. Projete seus pontos finais para serem idempotentes, para que repetir uma solicitação não crie registros duplicados.
4. Falta de Observabilidade
Quando os dados são distribuídos, você não pode consultar um único banco de dados para rastrear uma transação. Você precisa de rastreamento distribuído e registro centralizado. Seu esquema deve incluir IDs de correlação para rastrear solicitações entre os limites dos serviços.
📋 Lista de Verificação de Governança
Antes de implantar um novo serviço, revise a seguinte lista de verificação para garantir que seu modelo de dados seja sólido.
- Propriedade: Há um único serviço responsável por esses dados?
- Interface: Os dados são expostos apenas por meio de uma API?
- Consistência: O modelo de consistência está documentado (Fortemente consistente vs. Eventual)?
- Eventos: As mudanças de estado são publicadas como eventos para outros serviços?
- Compensação: Há um mecanismo de rollback para transações falhas?
- Versionamento: O esquema é versionado para lidar com mudanças futuras?
- Segurança: Os dados sensíveis são criptografados em repouso e em trânsito?
🔍 Visualizando a Arquitetura
Embora você não possa desenhar um único ERD para todo o sistema, pode criar um mapa de alto nível. Esse mapa mostra os serviços e seus limites de dados, e não colunas específicas.
- Desenhe caixas para cada serviço.
- Rotule o domínio de dados dentro da caixa (por exemplo, “Dados do Perfil do Usuário”).
- Desenhe setas para chamadas de API indicando o fluxo de dados.
- Indique os fluxos de eventos separadamente dos fluxos de solicitação/resposta.
Essa ajuda visual ajuda os interessados a entenderem o fluxo de informações sem se perderem em detalhes técnicos do esquema. Serve como ferramenta de comunicação para arquitetos e analistas de negócios.
🚀 Conclusão
Projetar ERDs para microsserviços não se trata de desenhar linhas entre tabelas. Trata-se de definir limites entre capacidades de negócios. Ao adotar o banco de dados por serviço, aceitar a consistência eventual e gerenciar rigorosamente as APIs, você pode construir sistemas escaláveis. O caos dos dados distribuídos é gerenciável com disciplina e contratos claros. Foque na autonomia, minimize acoplamento e garanta que cada serviço detenha completamente seus dados.
Lembre-se de que o modelagem de dados é um processo iterativo. À medida que os serviços crescem, seu esquema precisará evoluir. Revise regularmente sua arquitetura com base nessas práticas para manter um sistema saudável e resiliente.