











O modelamento de dados é frequentemente visto como um exercício estático na definição de relacionamentos e entidades. No entanto, um Diagrama de Relacionamento de Entidades (ERD) não é meramente um projeto para armazenamento; é um determinante direto de quão eficientemente um motor de banco de dados recupera e manipula informações. Cada linha desenhada, cada relacionamento definido e cada tipo de dado selecionado reverbera no plano de execução das suas consultas. Compreender os mecanismos por trás do design do esquema permite a criação de sistemas que escalonam de forma suave sob carga.
Este guia explora a relação técnica entre estruturas de ERD e o desempenho de consultas. Avançaremos além das definições básicas para examinar como decisões específicas de modelagem influenciam operações de E/S, uso de CPU e mecanismos de bloqueio em um ambiente relacional.
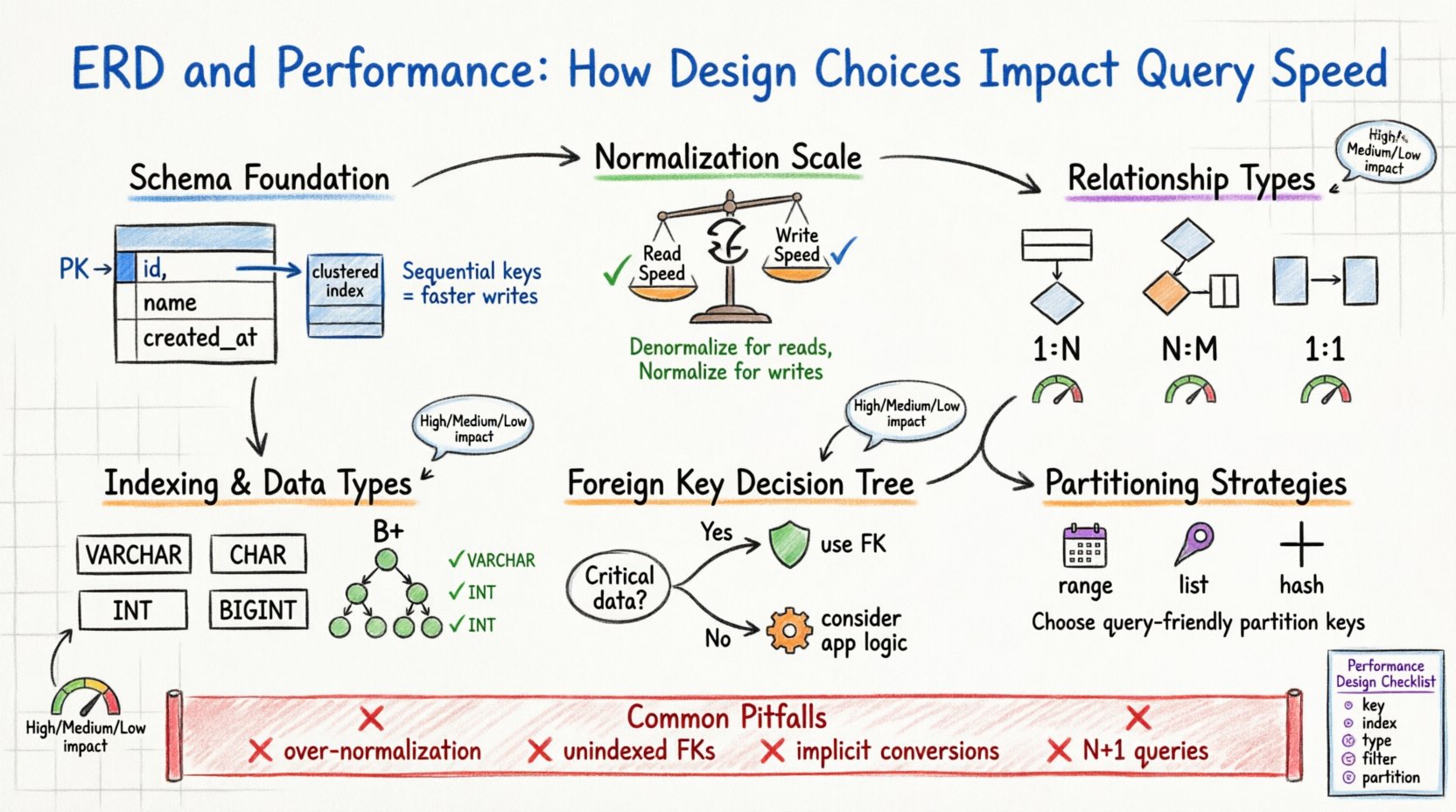
1. A Fundação: Estrutura do Esquema e Armazenamento Físico 🏗️
O design lógico que você cria no seu ERD eventualmente se traduz em arquivos físicos em um disco. O motor do banco de dados deve mapear essas entidades lógicas para páginas, blocos e linhas. Quando o esquema é otimizado, o motor minimiza o número de leituras de disco necessárias para atender a uma solicitação. Quando não é, o motor pode ser forçado a realizar varreduras completas de tabelas, operações que são custosas.
Considere a chave primária. Ela serve como identificador único para uma linha. Em muitos motores de armazenamento, a chave primária define a ordem física dos dados no disco (Índice Agrupado). Escolher uma chave primária sequencial e curta garante que os dados sejam armazenados de forma contígua. Isso reduz a fragmentação e permite varreduras de intervalo mais rápidas. Por outro lado, uma chave primária aleatória e longa pode causar divisões de página durante inserções, prejudicando o desempenho de gravação e aumentando a sobrecarga de armazenamento.
Principais Considerações para Chaves Primárias
- Sequencialidade:Inteiros autoincrementais são geralmente preferidos para cargas de trabalho intensivas em gravação.
- Tamanho:Chaves menores reduzem o tamanho dos índices secundários, pois são armazenadas como ponteiros nesses índices.
- Estabilidade:As chaves primárias não devem mudar. Atualizar uma chave primária geralmente exige atualizar todas as chaves estrangeiras associadas.
2. Normalização versus Trade-offs de Desempenho ⚖️
A normalização é o processo de organizar dados para reduzir redundâncias e melhorar a integridade. Embora tradicionalmente associada à qualidade dos dados, ela tem efeitos profundos sobre o desempenho. Um esquema altamente normalizado (por exemplo, Terceira Forma Normal) frequentemente exige mais junções para reconstruir dados, enquanto um esquema denormalizado reduz as junções, mas aumenta o armazenamento e a complexidade de atualização.
A decisão de normalizar ou denormalizar é um equilíbrio entre velocidade de leitura e velocidade de gravação. Em um ambiente com alta carga de leitura, a denormalização pode reduzir significativamente o tempo de consulta ao evitar junções complexas. Em um ambiente com alta carga de gravação, a normalização reduz o número de linhas que precisam ser atualizadas em várias tabelas.
Análise de Impacto da Normalização
| Aspecto | Altamente Normalizado | Denormalizado |
|---|---|---|
| Desempenho de Leitura | Mais Baixo (Requer Junções) | Mais Alto (Acesso a uma Única Tabela) |
| Desempenho de Gravação | Mais Alto (Menos Redundância) | Mais Baixo (Atualização de Múltiplas Cópias) |
| Integridade dos Dados | Alta (Fonte Única de Verdade) | Mais Baixa (Risco de Inconsistência) |
| Uso de Armazenamento | Menor | Maior |
3. Chaves Estrangeiras e Custo de Integridade 🔗
Chaves estrangeiras garantem a integridade referencial. Elas garantem que um valor em uma tabela corresponda a um valor em outra. Embora isso evite registros órfãos, introduz um custo de tempo de execução. Quando você insere, atualiza ou exclui uma linha, o banco de dados deve verificar a restrição de chave estrangeira.
Essa verificação não é gratuita. O motor precisa localizar a linha referenciada e verificar sua existência. Se a tabela referenciada for grande e não tiver um índice na coluna da chave estrangeira, a verificação se torna uma varredura completa da tabela. Além disso, excluir um registro pai exige que o motor verifique todos os registros filhos para garantir que não restem referências, potencialmente bloqueando muitas linhas.
Quando usar chaves estrangeiras
- Integridade Crítica de Dados: Se a correção dos dados for fundamental (por exemplo, transações financeiras), use chaves estrangeiras.
- Lógica do Aplicativo: Se a lógica do aplicativo for complexa, transferir a integridade para o banco de dados simplifica o código.
- Pequenos Conjuntos de Dados: O custo é desprezível em tabelas pequenas.
Quando evitar chaves estrangeiras
- Alto throughput de escrita: Remover restrições pode reduzir a contenção de bloqueios.
- Análise em Grande Escala: Em data warehousing, o desempenho frequentemente prevalece sobre a integridade rígida.
- Camadas Arquitetônicas: Em microserviços, manter chaves estrangeiras entre limites de serviços é frequentemente impraticável.
4. Estratégias de Indexação e Tipos de Coluna 📑
Um ERD define os tipos de dados para cada coluna. A escolha entre VARCHAR e CHAR, ou entre INT e BIGINT, afeta como os dados são armazenados e indexados. Tipos de dados menores consomem menos memória e espaço em disco, permitindo que mais dados cabem no pool de buffer (RAM).
Quando uma consulta filtra uma coluna, o motor do banco de dados depende dos índices para encontrar linhas rapidamente. Se o design do esquema não estiver alinhado com os padrões de consulta, os índices tornam-se inúteis. Por exemplo, criar um índice em uma coluna que raramente é usada em cláusulas WHERE é um desperdício de recursos.
Otimização de Tipos de Coluna
- Fixo vs. Comprimento Variável: Use CHAR para dados de comprimento fixo (por exemplo, códigos de país) para reduzir a fragmentação. Use VARCHAR para dados de comprimento variável.
- Faixas Inteiras: Não use BIGINT se INT for suficiente. Inteiros menores cabem mais linhas por página.
- Representação Booleana: Use tipos TINYINT(1) ou BOOLEAN em vez de armazenar strings ‘Sim’/’Não’.
5. Implicações da Cardinalidade de Relacionamentos 📊
A cardinalidade das relações (um para um, um para muitos, muitos para muitos) determina como os dados são vinculados. Cada tipo de relação possui características de desempenho diferentes.
Um para Muitos (1:N)
Esta é a relação mais comum. Uma tabela pai contém um registro, e a tabela filha contém muitos. O desempenho depende fortemente do índice na coluna de chave estrangeira na tabela filha. Sem esse índice, encontrar todos os filhos de um pai exige a varredura completa da tabela filha.
Muitos para Muitos (N:M)
Isso exige uma tabela de junção (entidade associativa). Isso adiciona uma camada extra de indireção. Consultas que envolvem relações N:M geralmente exigem três junções: Tabela A, Tabela de Junção, Tabela B. Essa complexidade aumenta o uso de CPU e os requisitos de memória.
Um para Um (1:1)
Freqüentemente usado para dividir uma tabela grande em grupos lógicos. Isso pode melhorar o desempenho se apenas um subconjunto de colunas for frequentemente consultado. No entanto, adiciona o custo de uma junção para recuperar o registro completo.
6. Considerações sobre Particionamento e Sharding 🗃️
À medida que os dados crescem, uma única tabela pode se tornar muito grande para ser gerenciada de forma eficiente. O particionamento permite dividir uma tabela grande em partes menores e mais gerenciáveis com base em uma chave (por exemplo, data). O design do ERD deve antecipar isso.
Se você projetar um esquema para um sistema que será eventualmente particionado (dividido entre múltiplos servidores), a chave de particionamento deve ser escolhida com cuidado. A chave deve ser usada com frequência nas consultas para permitir que o motor direcione as solicitações para o shard correto. Escolher uma chave que não seja usada nas consultas força o sistema a agrupar dados de todos os shards, o que é lento.
Estratégias de Particionamento
- Particionamento por Faixa: Dividir por faixas de data ou ID. Bom para dados em série temporal.
- Particionamento por Lista: Dividir por valores específicos (por exemplo, códigos de região).
- Particionamento por Hash: Distribui os dados de forma uniforme para evitar pontos quentes.
7. Armadilhas Comuns no Projeto 🚫
Mesmo arquitetos experientes podem introduzir gargalos de desempenho por meio de escolhas de projeto. Reconhecer esses padrões cedo evita refatorações custosas no futuro.
- Sobrenormalização:Dividir os dados em muitas tabelas pequenas aumenta a complexidade das junções e reduz a eficiência do cache.
- Ignorar a Seletividade:Indexar colunas com baixa seletividade (por exemplo, gênero ou bandeiras de status) frequentemente resulta em um desempenho ruim, pois o otimizador pode ignorar o índice e varrer a tabela de qualquer forma.
- Conversões Implícitas:Projetar uma coluna como string quando valores numéricos são esperados força o motor a converter tipos durante as consultas, impedindo o uso do índice.
- Padrões de Consultas N+1:Projetar relações que incentivem a busca de dados em loops em vez de junções em lote pode sobrecarregar o servidor.
8. Preparação para o Futuro e Evolução 🛡️
Bancos de dados evoluem. Requisitos mudam e novos recursos são adicionados. Um esquema que é eficiente hoje pode se tornar um gargalo amanhã se não tiver flexibilidade. O ERD deve acomodar o crescimento sem exigir uma reescrita completa.
Considere adicionar colunas que provavelmente serão usadas para filtragem no futuro. Embora isso aumente ligeiramente o tamanho da linha, evita o custo de alterar a estrutura da tabela posteriormente, o que pode ser uma operação cara em conjuntos de dados grandes. Além disso, considere o impacto de adicionar novos índices. Cada índice consome recursos de gravação. Projete o esquema para minimizar o número de índices necessários.
Lista de verificação de design para desempenho
- As chaves primárias são curtas e sequenciais?
- As chaves estrangeiras estão indexadas?
- Os tipos de dados são os menores tipos válidos possíveis?
- Os filtros frequentes são cobertos por índices?
- O nível de normalização é adequado para a carga de trabalho?
- Você considerou a partição para tabelas grandes?
- Há alguma coluna armazenando JSON ou texto complexo que poderia ser estruturado?
9. O Papel do Plano de Execução 📋
Em última análise, o motor do banco de dados decide como executar uma consulta com base no esquema e nas estatísticas. O ERD influencia as estatísticas coletadas pelo motor. Por exemplo, uma coluna com uma distribuição de valores distintos será tratada de forma diferente de uma com dados enviesados. Compreender como funciona o plano de execução ajuda você a interpretar por que uma consulta é lenta.
Se uma consulta realiza uma varredura completa da tabela, isso geralmente indica a ausência de um índice ou um design que não suporta filtragem eficiente. Se ela realiza muitos loops aninhados, isso sugere junções complexas que poderiam ser simplificadas. Alinhando o ERD com os padrões de acesso esperados, você orienta o motor para planos de execução ótimos.
10. Equilibrando Integridade e Velocidade ⚖️
Não existe um esquema perfeito. Cada escolha de design envolve uma compensação. O objetivo não é eliminar problemas de desempenho, mas gerenciá-los de forma estratégica. Em alguns casos, aceitar um pequeno risco de inconsistência de dados (por meio de verificações em nível de aplicação em vez de restrições do banco de dados) é uma compensação válida para um throughput extremo de gravação.
Revise regularmente seu ERD com base nos logs de consultas reais. Identifique as consultas mais lentas e rastreie-as de volta ao esquema. Esse ciclo de feedback garante que seu design evolua em sincronia com as necessidades da sua aplicação.
Resumo das Áreas de Impacto 📝
| Elemento de Design | Impacto no Desempenho | Recomendação |
|---|---|---|
| Tipo de Chave Primária | Alto (Armazenamento e Indexação) | Use inteiros ou UUIDs de forma consistente. |
| Chaves Estrangeiras | Médio (Carga de Escrita) | Indexe as colunas FK; remova se a integridade for tratada em outro lugar. |
| Normalização | Alto (Complexidade de Junções) | Desnormalize tabelas com leitura intensiva. |
| Tipos de Dados | Médio (Uso de Memória) | Use o tipo mais específico disponível. |
| Cardinalidade | Alto (Custo de Junção) | Otimize as tabelas de junção para relacionamentos N:M. |
Ao tratar o Diagrama de Relacionamento de Entidades como um artefato de desempenho, e não apenas como um mapa lógico, você pode construir sistemas que são robustos, escalonáveis e eficientes. As decisões que você tomar agora determinarão o comportamento de sua aplicação nos próximos anos.