











Construir um sistema capaz de lidar com milhões de usuários exige mais do que hardware potente ou código eficiente. A base está na própria estrutura de dados. Um Diagrama de Relacionamento de Entidades (ERD) não é meramente um artefato de documentação; é o projeto arquitetônico para a longevidade da sua aplicação. Quando arquitetos projetam para crescimento, antecipam a carga futura, a complexidade das relações e a necessidade de integridade dos dados. Um esquema bem construído evita que a dívida técnica se acumule antes mesmo do primeiro commit ser feito.
Este guia explora como abordar o design de Diagramas de Relacionamento de Entidades especificamente para ambientes escaláveis. Cobriremos os fundamentos teóricos, os trade-offs práticos e os padrões estruturais que suportam sistemas de alta taxa de transferência sem comprometer a consistência.
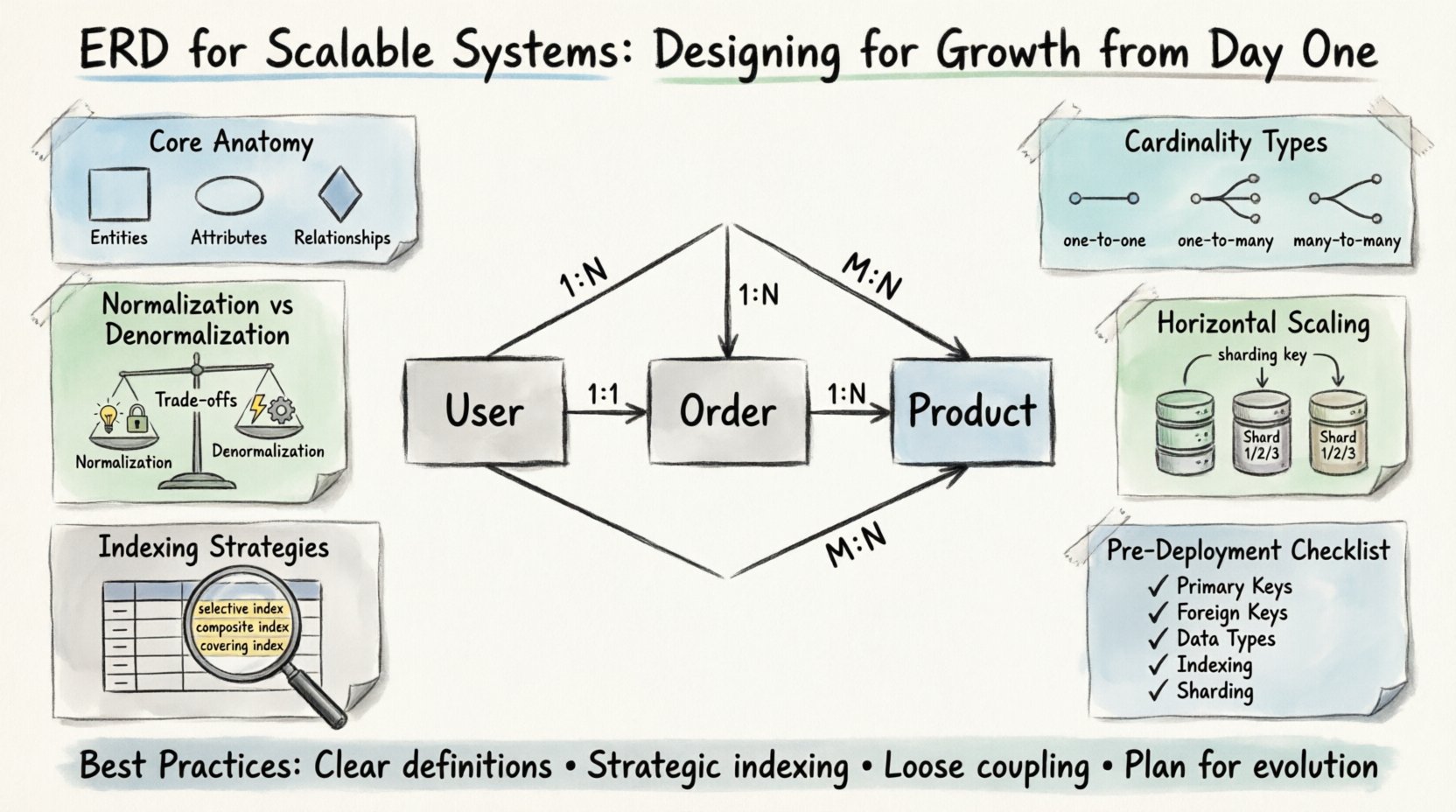
🧩 A Anatomia Central de um ERD Escalável
Antes de considerar escalabilidade, é necessário entender os blocos fundamentais. Todo diagrama consiste em entidades, atributos e relacionamentos. Em um contexto escalável, esses elementos devem ser definidos com precisão para evitar gargalos futuros.
- Entidades: Elas representam os objetos centrais do seu domínio de negócios. Exemplos incluem Usuários, Pedidos e Produtos. Em sistemas de alto crescimento, as entidades devem ser granulares o suficiente para permitir escalabilidade independente, mas coesas o suficiente para manter limites lógicos.
- Atributos: São as propriedades que descrevem as entidades. Os tipos de dados são cruciais aqui. Escolher o tipo correto afeta a eficiência de armazenamento e o desempenho das consultas. Por exemplo, usar um tipo inteiro dedicado para IDs é superior a strings para fins de indexação.
- Relacionamentos: Eles definem como as entidades interagem. A cardinalidade é o aspecto mais importante a ser definido cedo. Interpretar incorretamente um relacionamento um-para-muitos como muitos-para-muitos pode levar a junções desnecessárias e uma degradação severa do desempenho.
📐 Compreendendo Cardinalidade e Restrições
A cardinalidade determina o número de instâncias de uma entidade que podem ou devem se relacionar com instâncias de outra. Em sistemas escaláveis, a escolha da cardinalidade frequentemente determina como os dados são particionados.
- Um-para-um (1:1): Raramente usado para otimização de desempenho. Muitas vezes implica dividir uma entidade grande para reduzir a contenção de bloqueios. Use apenas quando os padrões de acesso a dados forem estritamente distintos.
- Um-para-muitos (1:N): O relacionamento mais comum. Um Usuário tem muitos Pedidos. Essa estrutura suporta indexação eficiente no lado da chave estrangeira, permitindo recuperação rápida de registros relacionados.
- Muitos-para-muitos (M:N): Requer uma tabela de junção. Embora flexível, esses relacionamentos podem se tornar gargalos de desempenho à medida que o volume de dados cresce. Considere a desnormalização ou visualizações materializadas se a frequência de leitura for alta.
Ao definir restrições, considere a sobrecarga de execução. Em sistemas distribuídos, forçar restrições de chave estrangeira rígidas entre shards pode introduzir latência. Nesses casos, a validação em nível de aplicação pode ser necessária para manter a taxa de throughput do sistema, preservando ao mesmo tempo a integridade dos dados.
⚖️ Normalização vs. Trade-offs de Desempenho
A normalização reduz a redundância e melhora a integridade dos dados. No entanto, sistemas de alto desempenho frequentemente exigem uma desvio das regras rígidas de normalização. Compreender as camadas ajuda a tomar decisões informadas.
- Primeira Forma Normal (1NF): Valores atômicos. Garante que cada célula contenha um único valor. Isso é irredutível para a integridade relacional.
- Segunda Forma Normal (2NF): Sem dependência parcial. Todos os atributos não-chave devem depender da chave primária inteira. Útil para reduzir anomalias de atualização.
- Terceira Forma Normal (3NF): Sem dependência transitiva. Atributos não-chave não devem depender de outros atributos não-chave. Este é o objetivo padrão para a maioria dos sistemas transacionais.
Embora o 3NF seja ideal para consistência, frequentemente exige junções complexas. Em sistemas com alta carga de leitura, unir múltiplas tabelas pode sobrecarregar o motor do banco de dados. A desnormalização envolve a duplicação de dados para reduzir a necessidade de junções. Isso aumenta a complexidade das gravações, mas acelera significativamente as leituras.
📊 Comparação entre Normalização e Desnormalização
| Recursos | Normalizado (3FN) | Denormalizado |
|---|---|---|
| Integridade dos Dados | Alta (Fonte Única de Verdade) | Menor (Requer Lógica de Sincronização) |
| Desempenho de Escrita | Mais Rápido (Menos Dados Escritos) | Mais Lento (Escritas Redundantes) |
| Desempenho de Leitura | Mais Lento (Requer Joins) | Mais Rápido (Acesso Direto) |
| Uso de Armazenamento | Eficiente | Maior (Redundância) |
| Caso de Uso | Sistemas Transacionais (OLTP) | Relatórios e Análise (OLAP) |
🚀 Projetando para Escalonamento Horizontal
À medida que o volume de dados cresce, um único nó de banco de dados torna-se um gargalo. O escalonamento horizontal envolve adicionar mais nós para distribuir a carga. Seu ERD deve suportar essa arquitetura desde o início.
- Chaves de Shard: Identifique uma coluna que permita dividir os dados de forma equilibrada entre os shards. Essa coluna deve estar presente em todas as consultas que acessam os dados. Se uma consulta exigir a varredura de todos os shards, o desempenho será afetado.
- Chaves Estrangeiras entre Shards: Unir tabelas que residem em diferentes shards é computacionalmente custoso. Minimize relacionamentos entre shards na fase de design. Se um relacionamento for necessário, considere armazenar em cache os dados de referência.
- IDs Globais: Use identificadores únicos que não dependam de contadores autoincrementais, pois esses podem causar contenção. UUIDs ou geradores de IDs distribuídos são preferidos.
Ao modelar para sharding, considere a distribuição dos dados. Hotspots ocorrem quando um shard recebe significativamente mais tráfego do que os outros. Analise os padrões de acesso para garantir que a chave de sharding esteja alinhada com os filtros de consulta mais frequentes.
📑 Estratégias de Indexação para Grandes Conjuntos de Dados
Índices são essenciais para o desempenho de consultas, mas têm um custo. Cada índice consome armazenamento e reduz o desempenho das operações de escrita. Uma abordagem estratégica para indexação é vital.
- Índices Seletivos: Crie índices em colunas que filtram dados significativamente. Uma coluna com baixa cardinalidade (por exemplo, sexo) geralmente é um mau candidato para um índice primário.
- Índices Compostos: Combine múltiplas colunas na ordem que corresponde aos padrões de consulta. A regra do prefixo mais à esquerda se aplica, ou seja, a primeira coluna no índice deve corresponder à consulta para que o índice seja usado efetivamente.
- Índices Cobertores: Inclua todas as colunas necessárias por uma consulta diretamente no índice. Isso permite que o banco de dados atenda à consulta sem acessar os dados da tabela, conhecido como uma operação de “cobertura”.
- Índices Parciais: Índice apenas um subconjunto das linhas da tabela. Isso é útil para exclusões suaves ou bandeiras de status específicas, reduzindo o tamanho da estrutura do índice.
Revise regularmente os planos de execução de consultas. Um índice que parece bom em teoria pode ser ignorado pelo otimizador de consultas se as estatísticas estiverem desatualizadas. Manutenção regular garante que o motor do banco de dados tome decisões ótimas.
🔄 Evolução e Migrações de Esquema
Sistemas não são estáticos. Os requisitos mudam, e o modelo de dados deve evoluir. Mover de uma versão A para a versão B sem tempo de inatividade é uma habilidade crítica.
- Mudanças Aditivas:Adicionar uma coluna ou tabela geralmente é seguro. Não quebra consultas existentes. Este é o método preferido para introduzir novos recursos.
- Operações de Renomeação:Renomear uma coluna é arriscado. Exige atualização do código da aplicação. Planeje um período de descontinuação em que ambos os nomes antigo e novo sejam suportados.
- Adição de Restrições:Adicionar uma restrição (como NOT NULL) a dados existentes pode falhar se os dados já existirem. Valide os dados primeiro, depois adicione a restrição em um passo separado.
- Compatibilidade com Versões Anteriores:Garanta que as novas versões do esquema não quebrem clientes existentes. Use bandeiras de recurso para alternar a nova lógica apenas quando o esquema estiver pronto.
🚫 Armadilhas Comuns a Evitar
Mesmo designers experientes enfrentam problemas. Reconhecer esses padrões cedo pode poupar um tempo significativo de engenharia.
- Acoplamento Estreito:Criar relacionamentos que forçam uma sincronização rígida entre entidades não relacionadas. Mantenha os módulos fracamente acoplados para permitir implantações independentes.
- Engenharia Excessiva:Projetar para cenários que podem nunca acontecer. Foque nos 80% dos casos de uso que geram 90% do tráfego. A simplicidade auxilia na manutenção.
- Ignorar Exclusões Suaves:Exclusões rígidas removem dados permanentemente. Para rastreamento de auditoria ou recuperação, use uma bandeira de status (por exemplo, is_deleted) em vez da remoção física.
- Problemas de Consultas N+1:Falhar em antecipar como os dados serão buscados. Planeje o carregamento preguiçoso ou a busca em lote na camada de acesso a dados para evitar viagens excessivas ao banco de dados.
✅ Lista de Verificação de Design Antes da Implantação
Antes de finalizar o esquema, percorra esta lista de verificação para garantir a prontidão para escala.
- ☐ Chaves Primárias:Todas as tabelas possuem uma chave primária exclusiva e indexada?
- ☐ Chaves Estrangeiras:As relações estão definidas corretamente? A cardinalidade está correta?
- ☐ Tipos de Dados:Os tipos numéricos são usados para IDs e valores? Os tipos de data são padronizados?
- ☐ Permitir Valores Nulos:Os campos obrigatórios estão marcados como NOT NULL?
- ☐ Indexação:As colunas com consultas de alto tráfego estão indexadas?
- ☐ Sharding:Existe uma chave de sharding viável caso seja prevista a escalabilidade horizontal?
- ☐ Restrições:As restrições são necessárias para a lógica de negócios, ou podem ser tratadas na camada de aplicação?
- ☐ Documentação:O diagrama ERD foi atualizado para refletir a implementação final?
🛡️ Integridade de Dados em Ambientes Distribuídos
Em uma configuração distribuída, é mais difícil garantir as propriedades ACID (Atomicidade, Consistência, Isolamento, Durabilidade) entre nós. Compreender as implicações para o seu ERD é crucial.
- Consistência Eventual:Aceite que os dados podem ser temporariamente inconsistentes entre réplicas. Projete sua aplicação para lidar com esse estado de forma elegante.
- Idempotência:Garanta que operações possam ser repetidas sem efeitos colaterais. Isso é vital para falhas de rede em que uma gravação pode ter sucesso, mas o reconhecimento é perdido.
- Resolução de Conflitos: Defina como lidar com atualizações simultâneas no mesmo registro. Marcações de tempo ou relógios vetoriais podem ajudar a determinar a versão mais recente.
Ao incorporar essas considerações ao seu Diagrama de Relacionamento de Entidades, você cria um sistema que não é apenas funcional hoje, mas robusto o suficiente para o amanhã. O custo de alterar um esquema em produção é exponencialmente maior do que projetá-lo corretamente desde o início.
🔍 Resumo das Melhores Práticas
Para recapitular, a escalabilidade bem-sucedida depende de uma abordagem disciplinada para modelagem de dados. Foque em definições claras, normalização adequada e indexação estratégica. Evite atalhos que comprometam a integridade dos dados. Revise regularmente seus diagramas à medida que o sistema evolui. Um ERD estático é uma desvantagem; um modelo vivo é um ativo.
Invista tempo na fase de design. Isso trará dividendos em custos reduzidos de manutenção e maior confiabilidade do sistema. Seus usuários nunca verão o diagrama, mas sentirão o desempenho do sistema que ele sustenta.