











O desenvolvimento de backend muitas vezes parece construir uma casa sem um projeto. Você começa colocando tijolos, adicionando janelas e estruturando paredes com base na intuição. Às vezes, funciona. Muitas vezes, não funciona. Semanas depois, você se vê desmontando paredes para acomodar uma porta que esqueceu de planejar. Essa é a realidade de programar sem um sólidoDiagrama de Relacionamento de Entidades (ERD). O ERD é o arquiteto silencioso da sua infraestrutura de dados, atuando nas sombras para prevenir falhas estruturais custosas. Quando você investe tempo em projetar seu modelo de dados antes de escrever uma única linha de código, você ganha clareza, reduz a dívida técnica e facilita a colaboração entre equipes.
Este guia explora o impacto tangível dos ERDs nos fluxos de trabalho do backend. Vamos analisar a mecânica da modelagem de dados, os custos ocultos de pular o planejamento e as vantagens estratégicas de um esquema bem documentado. Ao entender esses princípios, você pode passar da programação reativa para uma arquitetura proativa.
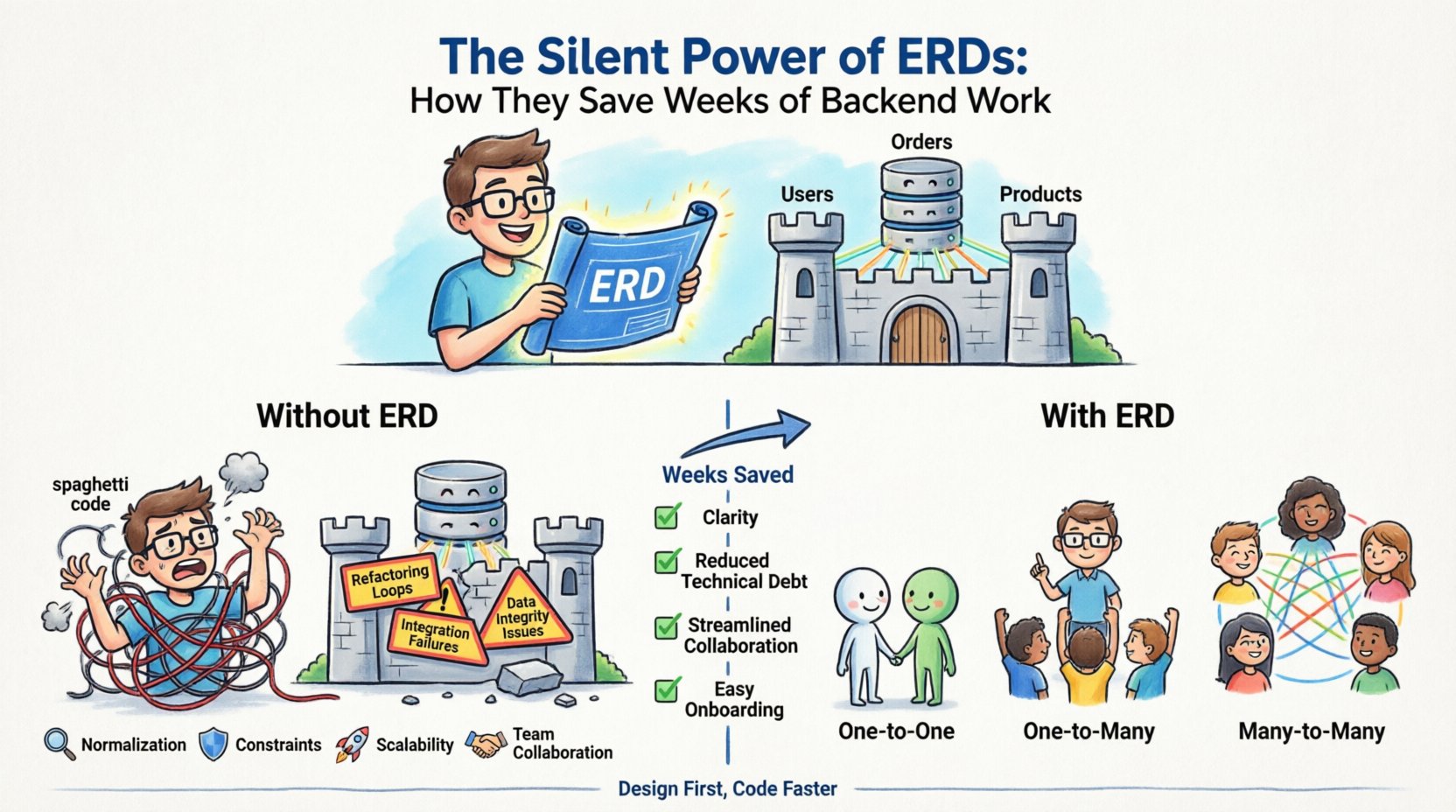
O que exatamente é um ERD? 📐
Um Diagrama de Relacionamento de Entidades é uma representação visual da estrutura lógica de um banco de dados. Ele mostra como diferentes partes de dados se relacionam entre si. Pense nele como um mapa para a memória da sua aplicação. Sem esse mapa, os desenvolvedores navegam à cega, correndo o risco de colisões entre pontos de dados que deveriam permanecer separados.
Em sua essência, um ERD consiste em três componentes principais:
- Entidades: Elas representam os objetos ou conceitos que você está rastreando. Em um banco de dados, essas se traduzem em tabelas. Exemplos incluemUsuários, Pedidos, ouProdutos.
- Atributos: São as propriedades específicas de uma entidade. Elas se tornam as colunas dentro das suas tabelas. Para uma entidadeUsuário entidade, os atributos podem incluiremail, hash_senha, ecriado_em.
- Relacionamentos: Eles definem como as entidades interagem. Eles determinam a cardinalidade e a conectividade entre as tabelas, como umUsuário tendo muitosPedidos.
Embora o conceito pareça simples, a complexidade surge ao lidar com escalabilidade. Um blog simples pode precisar apenas de algumas tabelas. Um sistema empresarial exige dezenas, se não centenas, de entidades interconectadas. O diagrama ER atua como a única fonte de verdade para todas essas interações.
O Custo Oculto de Pular o Design 💸
Muitas equipes de desenvolvimento correm para codificar para cumprir prazos. Elas assumem que podem refatorar o banco de dados posteriormente. Essa é uma suposição perigosa. Alterar um esquema de banco de dados é significativamente mais caro do que alterar a lógica da aplicação. Uma vez que os dados são gravados, alterar sua estrutura exige scripts de migração, possível tempo de inatividade e manipulação cuidadosa dos registros existentes.
Considere os seguintes cenários em que a ausência de um diagrama ER causa atritos:
- Loops de Refatoração:Você constrói um recurso, percebe que a estrutura de dados não o suporta e precisa reescrever as consultas. Esse ciclo se repete, consumindo semanas do tempo de sprint.
- Falhas de Integração:Quando as equipes de frontend e backend trabalham sem uma definição de esquema compartilhada, as APIs frequentemente falham. O backend envia uma estrutura; o frontend espera outra.
- Problemas de Integridade de Dados:Sem restrições definidas, dados inválidos entram no sistema. Você acaba limpando registros órfãos ou corrigindo estados inconsistentes manualmente.
- Atrasos na Integração:Desenvolvedores novos têm dificuldade para entender o sistema. Eles gastam dias lendo código em vez de construir recursos, porque o fluxo de dados não está documentado.
No momento em que você percebe o problema, o custo já se acumulou. A “correção” agora exige não apenas alterações no código, mas também migração de dados, testes e verificação de implantação.
Mapeando Relacionamentos Como um Profissional 🔗
Compreender como os dados se conectam é o coração do design de diagramas ER. As relações determinam como as consultas são escritas e como o desempenho é otimizado. Existem três tipos principais de relações que você deve definir claramente.
A tabela abaixo descreve as diferenças entre esses tipos de relação:
| Tipo de Relação | Definição | Cenário de Exemplo | Observação de Implementação |
|---|---|---|---|
| Um para Um (1:1) | Um único registro na Tabela A está relacionado a exatamente um registro na Tabela B. | Um perfil de usuário vinculado a uma tabela de configurações de usuário. | Geralmente implementado colocando a chave primária de B em A. |
| Um para Muitos (1:N) | Um único registro na Tabela A está relacionado a múltiplos registros na Tabela B. | Uma Categoria contendo múltiplos Produtos. | Posicionamento padrão da chave estrangeira na tabela do lado “muitos”. |
| Muitos para Muitos (M:N) | Vários registros na Tabela A estão relacionados a vários registros na Tabela B. | Alunos matriculados em múltiplos Cursos. | Requer uma tabela de junção para resolver a ligação. |
Ignorar essas distinções leva a consultas ineficientes. Por exemplo, armazenar uma lista de IDs de produtos em uma única coluna para uma categoria viola os princípios de normalização. Isso obriga você a analisar strings em vez de usar junções, reduzindo o desempenho à medida que os dados crescem.
Normalização: Mantendo os Dados Limpos 🧹
A normalização é o processo de organizar os dados para reduzir a redundância e melhorar a integridade. Embora sistemas modernos às vezes desviem-se da normalização rígida para melhorar o desempenho, compreender os princípios permanece essencial.
As formas padrão de normalização incluem:
- Primeira Forma Normal (1FN): Garante atomicidade. Cada coluna contém apenas um valor. Nenhuma lista ou array em uma única célula.
- Segunda Forma Normal (2FN): Baseia-se na 1FN. Exige que todos os atributos não-chave dependam totalmente da chave primária. Nenhuma dependência parcial.
- Terceira Forma Normal (3FN): Baseia-se na 2FN. Exige que os atributos não-chave dependam apenas da chave primária, e não de outros atributos não-chave.
Por que isso importa? Considere uma Ordem tabela. Se você armazenar o Nome do Cliente em cada linha de ordem, você cria redundância. Se o cliente mudar o nome, você precisará atualizar milhares de linhas. Se esquecer de uma, seus dados ficarão inconsistentes. Ao mover o Nome do Cliente para uma Clientes tabela e vincular por ID, você garante uma única fonte de verdade.
No entanto, a normalização não é uma solução mágica. A sobre-normalização pode levar a junções complexas que prejudicam o desempenho. O objetivo é o equilíbrio. Você deve entender as trade-offs entre eficiência de armazenamento e velocidade de consulta.
Armadilhas Comuns no Design de Esquemas 🚧
Mesmo desenvolvedores experientes cometem erros ao projetar ERDs. Reconhecer essas armadilhas comuns pode poupar-lhe grandes problemas no futuro.
- Dependências Circulares: A entidade A precisa da entidade B, e a entidade B precisa da entidade A. Isso cria um bloqueio (deadlock) na inicialização e torna difícil escrever scripts de migração.
- Restrições Ausentes: Falhar em definir chaves estrangeiras, restrições únicas ou restrições de verificação permite que dados inválidos passem despercebidos. O banco de dados deve impor regras, e não o código da aplicação.
- Valores Codificados:Armazenar códigos de status como “ativo” ou “inativo” como inteiros sem uma tabela de referência torna o sistema frágil. Se precisar adicionar “suspenso”, você precisa alterar a lógica em todos os lugares.
- Ignorando Exclusões Suaves:Excluir dados permanentemente remove o histórico. Projetar para exclusões suaves (marcar um registro como excluído em vez de removê-lo) preserva os rastros de auditoria.
- Engenharia Excessiva:Projetar para um caso de uso que ainda não existe. Construa com base nas necessidades atuais, mas certifique-se de que o esquema seja flexível o suficiente para lidar com crescimentos razoáveis.
Cada um desses perigos adiciona camadas de complexidade ao seu código. Um ERD ajuda você a visualizar esses problemas antes que eles se tornem incorporados à produção.
Do Diagrama para a Implementação 🚀
Uma vez que o ERD é finalizado, o próximo passo é traduzi-lo em código. Esse processo, frequentemente chamado de migração de esquema, exige disciplina.
Siga estas etapas para garantir uma transição suave:
- Controle de Versão:Trate o esquema do banco de dados como código de aplicação. Todas as alterações devem ser arquivos de migração armazenados no seu repositório.
- Compatibilidade com Versões Anteriores: Ao adicionar uma coluna, torne-a nula primeiro. Preencha os dados existentes, depois aplique a restrição em uma migração subsequente. Isso evita tempo de inatividade.
- Testando Migrações: Execute scripts de migração em um ambiente de homologação idêntico ao de produção. Verifique regressões de desempenho.
- Planos de Retorno: Sempre tenha uma forma de desfazer uma migração caso ela falhe. Perda de dados é inaceitável.
Ferramentas de automação podem ajudar na geração de SQL a partir de ERDs, mas a revisão manual é crucial. Geradores automatizados frequentemente ignoram nuances da lógica de negócios que um arquiteto humano identificaria.
Colaboração e Comunicação 🤝
Um ERD não é apenas para administradores de banco de dados. Serve como ferramenta de comunicação para toda a equipe. Gerentes de produto, desenvolvedores front-end e engenheiros de QA todos se beneficiam ao entender a estrutura de dados.
Quando os interessados revisam o ERD, podem identificar problemas potenciais cedo:
- Viabilidade da Funcionalidade: O banco de dados pode suportar a funcionalidade solicitada? Caso contrário, quais alterações são necessárias?
- Expectativas de Desempenho: O projeto permite consultas eficientes em grande escala?
- Requisitos de Segurança: Os campos sensíveis foram identificados e protegidos? O controle de acesso é viável ao nível dos dados?
Esse entendimento compartilhado reduz a fricção durante o planejamento de sprint. Em vez de adivinhar como os dados fluem, a equipe discute com base em um modelo visual. As divergências são resolvidas com base no diagrama, e não na opinião.
Considerações de Escalabilidade 📈
À medida que seu aplicativo cresce, seu modelo de dados deve evoluir. Um ERD ajuda você a antecipar essas mudanças. Ele permite que você visualize como a adição de uma nova entidade afeta as relações existentes.
Fatores-chave de escalabilidade a considerar durante o design:
- Estratégia de Indexação:Identifique quais colunas serão consultadas com frequência. Planeje índices nessas colunas para acelerar a recuperação.
- Particionamento:Algumas tabelas podem crescer demais? Planeje o particionamento horizontal se necessário.
- Divisão de Leitura/Escrita:O design suporta réplicas separadas para leitura e escrita? Certifique-se de que chaves estrangeiras não complicam a replicação.
- Camadas de Cache:Como o modelo de dados interage com sistemas de cache? Dados imutáveis são mais fáceis de armazenar em cache do que dados que mudam com frequência.
Pensar na escala desde cedo evita a necessidade de uma reescrita completa posteriormente. É mais fácil adicionar uma nova tabela do que mover dados de um servidor para outro.
Pensamentos Finais sobre Arquitetura de Dados 🧠
O esforço gasto na criação de um ERD detalhado traz benefícios ao longo de todo o ciclo de vida de um projeto. Ele transforma o modelamento de dados de uma tarefa reativa em um ativo estratégico. Ao visualizar relacionamentos, aplicar restrições e planejar o crescimento, você constrói sistemas robustos e sustentáveis.
Não trate o banco de dados como uma depois-pensada. Ele é a base do seu aplicativo. Invista na fase de design, e você economizará semanas de trabalho no backend a longo prazo. O poder silencioso do ERD reside na sua capacidade de prevenir problemas antes que eles sequer ocorram.
Comece a mapear seus dados hoje. A clareza que você ganhará será a diferença entre uma base de código caótica e um sistema otimizado.