











在微服務架構中設計資料模型,與單體應用程式相比,需要根本性的思維轉變。在傳統系統中,單一的實體關係圖(ERD)通常涵蓋整個資料庫。在分散式環境中,這種單一視圖會分裂成多個獨立的資料結構。挑戰在於維持一致性,同時又不將服務緊密耦合。本指南探討如何有效設計資料模型,確保可擴展性和韌性,同時避免分散式資料管理常見的陷阱。
當服務直接共享資料時,它們會繼承彼此的依賴關係。這種緊密耦合會導致系統脆弱,一個區域的變更會導致另一個區域失效。目標是建立邊界,讓團隊能夠獨立部署。達成此目標需要仔細規劃關係、一致性模型和整合模式。
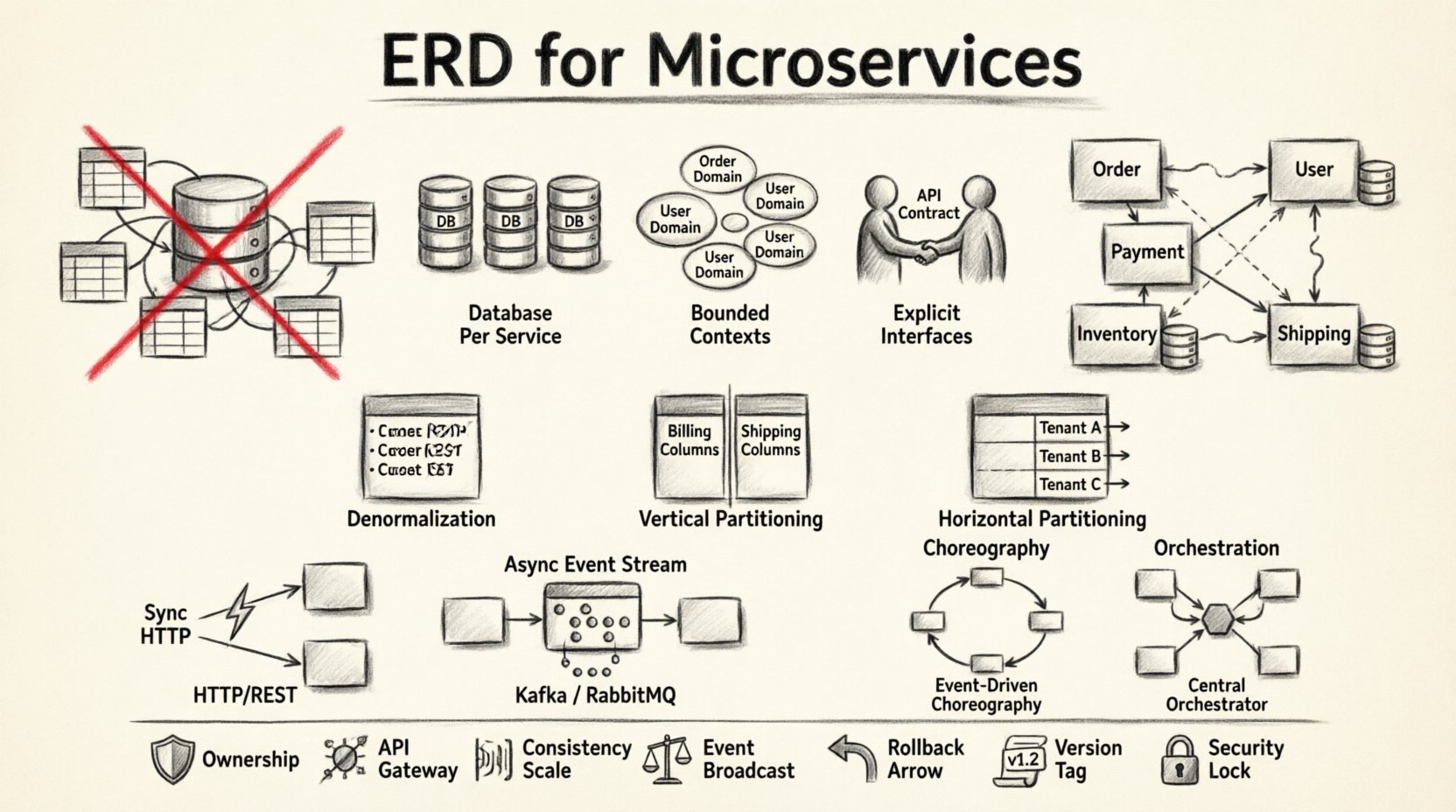
🧱 為何傳統ERD在分散式系統中會失效
標準的ERD假設存在一個中央權威。它在單一交易邊界內映射表格、欄位和外鍵。微服務拒絕這種中心化。當你將單體ERD的思維應用於分散式系統時,可能會導致建立分散式單體。這發生在服務依賴共享資料庫表格,而非明確定義的API時。
忽略這些原則時,通常會出現以下問題:
- 部署耦合:對共享表格的變更,需要在多個服務中同時進行部署。
- 交易邊界:ACID交易跨越多個服務,增加延遲和失敗點。
- 結構鎖定:一個服務中的資料庫鎖定,可能導致另一個服務的請求停滯。
- 可見性問題:沒有單一團隊掌握全局資料狀態,導致資料孤島。
與單一圖表不同,你需要一組服務特定的資料結構,透過明確定義的介面進行溝通。這種方法優先考慮自主性,而非即時一致性。
🧬 分散式資料模型的核心原則
為了維持秩序,你必須遵守特定的架構原則。這些指南幫助團隊在資料所有權和存取模式方面做出決策。
1. 每個服務擁有自己的資料庫
每個微服務應擁有其資料儲存空間。這確保了服務的內部結構對其他服務不可見。如果服務A需要來自服務B的資料,必須透過API請求,而非直接查詢資料庫。這種隔離保護了每個領域的完整性。
- 服務自行管理其結構的演進。
- 團隊可以根據自身需求選擇最適合的資料庫技術(多語言持久化)。
- 一個資料庫的失敗不會導致整個應用程式崩潰。
2. 有界上下文
資料必須與業務能力對齊。在領域驅動設計中,有界上下文定義了模型的語義邊界。兩個服務可能使用「客戶」這個詞,但這些上下文中的資料內容不同。一個可能儲存聯絡資訊,另一個則儲存財務紀錄。將它們合併到單一ERD中會造成混淆與技術負債。
3. 明確的介面
由於服務無法直接看見彼此的資料,API 成為資料合約。API 回應的結構定義了資料對消費者的真實狀態。這使內部儲存實作與外部使用分離。
📐 獨立性導向的結構設計模式
為微服務設計結構時,需採用特定模式來處理原本由外鍵處理的關係。你無法依賴資料庫層級的約束來強制跨服務的關係。
反規範化
在單體系統中,規範化可減少冗餘。但在微服務中,反規範化通常更受青睞。儲存重複資料可減少遠端呼叫的需求。例如,訂單服務可能在訂單記錄中儲存客戶姓名和地址。這可避免每次顯示訂單時都需同步查詢使用者服務。
- 優勢:更快的讀取效能以及更少的網路跳躍次數。
- 風險:如果來源資料變更,可能會導致資料不一致。您必須透過事件來處理更新。
垂直分割
將大型資料表拆分成較小且專注的集合。如果一個資料表同時包含帳單資訊與寄送地址,應將這些概念分離。帳單資料可能屬於付款服務,而寄送地址則屬於物流服務。這能減少變更的影響範圍,並透過限制存取來提升安全性。
水平分割
根據租戶ID或地理區域來分割資料。這對於在不影響其他服務的情況下擴展特定服務非常有用。您可以針對高流量區域複製服務,同時保持其他服務輕量。
| 模式 | 最佳使用情境 | 關鍵考量 |
|---|---|---|
| 去規範化 | 讀取密集型工作負載 | 需要同步邏輯 |
| 垂直分割 | 明確的領域 | 明確的API邊界 |
| 水平分割 | 高擴展性/多租戶 | 路由邏輯複雜度 |
🔄 處理關係與一致性
微服務資料模型中最困難的部分是在沒有分散式交易的情況下維持一致性。您必須在強一致性與最終一致性之間做出選擇。
同步通訊
服務可以透過HTTP或gRPC直接互相呼叫。這能為即時操作提供強一致性。然而,這會引入延遲並形成依賴鏈。如果服務A呼叫服務B,而服務B當機,服務A也會失敗。
非同步通訊
服務透過訊息佇列或事件串流進行通訊。這能解耦操作的時序。服務A發佈事件,服務B稍後再消費該事件。這支援最終一致性。
- 優點:彈性、可擴展性與鬆散耦合。
- 缺點:資料會暫時不一致。除錯需要跨多個日誌追蹤。
🗓️ 資料完整性中的Saga模式
Saga是一系列本地交易。每個交易都會更新本地資料庫並發佈事件以觸發下一步。如果某一步失敗,Saga會執行補償交易來撤銷先前的變更。
編排 vs. 編排
Saga可以透過兩種方式實現:
- 編排:服務會監聽事件並決定下一步該做什麼。沒有中央控制器。這種方式彈性高,但較難視覺化。
- 編排:由中央協調者告知服務該做什麼。這能提供更好的工作流程可見性與控制,但會引入單點故障。
在為Saga建立ERD模型時,必須考慮狀態變更。參與Saga的每個服務都需儲存其狀態以處理回滾。這表示你的資料結構必須支援交易狀態,而不僅僅是最終資料。
📝 資料結構演進的管理
資料結構演進是不可避免的。欄位會變更,類型會轉移,約束會放寬。在分散式系統中,當其他服務依賴該資料庫結構時,無法隨意修改。你必須規劃版本控制。
向後相容性
永遠維持向後相容性。新增欄位時,不要立即移除舊欄位。讓使用者有時間逐步遷移。若必須變更欄位名稱,請在過渡期間將舊名稱別名指向新名稱。
版本控制策略
- URI版本控制:在API路徑中包含版本號碼。
- 標頭版本控制:使用自訂標頭來指定預期的資料結構版本。
- 內容協商:使用標準HTTP標頭來請求特定的媒體類型。
文件必須與程式碼保持同步。自動化測試應驗證API合約是否與資料結構相符。這可防止破壞性變更進入生產環境。
🛡️ 應避免的常見陷阱
即使有穩固的計畫,團隊仍經常在特定問題上跌倒。了解這些陷阱有助於設計出穩健的系統。
1. 共用資料庫的陷阱
不要在服務之間共用資料表。這會造成隱藏的耦合。如果付款服務讀取訂單服務的資料表,就過度了解內部結構。這會導致緊密耦合與部署衝突。
2. 過度規範化
試圖在服務之間規範化資料,會導致過多的連接與網路呼叫。接受一定程度的重複資料。擁有重複資料,總比擁有一個緩慢且緊密耦合的系統要好。
3. 忽略冪等性
網路呼叫會失敗。訊息可能重複。你的資料結構與API邏輯必須能處理重複請求而不產生錯誤。設計端點時應具冪等性,使重試請求不會產生重複記錄。
4. 缺乏可觀測性
當資料分散時,你無法查詢單一資料庫來追蹤交易。你需要分散式追蹤和集中式記錄。你的資料結構應包含關聯識別碼,以跨服務邊界追蹤請求。
📋 治理檢查清單
在部署新服務之前,請審查以下檢查清單,以確保你的資料模型穩健。
- 所有權:是否有單一服務對此資料負責?
- 介面:資料是否僅透過 API 暴露?
- 一致性:一致性模型是否已文件化(強一致性 vs. 最終一致性)?
- 事件:狀態變更是否以事件形式發布給其他服務?
- 補償:是否有失敗交易的回滾機制?
- 版本控制:資料結構是否已版本化以應對未來的變更?
- 安全性:敏感資料是否在靜態和傳輸中均已加密?
🔍 可視化架構
雖然你無法為整個系統繪製單一的ERD,但你可以建立一個高階地圖。此地圖顯示服務及其資料邊界,而非具體欄位。
- 為每個服務繪製方框。
- 在方框內標示資料領域(例如:「使用者個人資料」)。
- 繪製箭頭表示API呼叫,以顯示資料流動。
- 將事件串流與請求/回應流程分開標示。
此視覺輔助工具幫助利益相關者理解資訊流動,而不會陷入技術性資料結構細節。它作為架構師與業務分析師之間的溝通工具。
🚀 結論
為微服務設計ERD,並非僅僅在表格之間畫線。而是定義業務能力之間的邊界。透過採用每個服務對應一個資料庫、接受最終一致性,並嚴格管理API,你就能建構可擴展的系統。透過紀律與明確的合約,分散式資料的混亂是可以管理的。專注於自主性,最小化耦合,並確保每個服務完全擁有其資料。
請記住,資料模型設計是一個迭代的過程。隨著服務的成長,你的資料結構將需要演進。定期根據這些原則審查你的架構,以維持一個健康且具韌性的系統。