











Building a system that can handle millions of users requires more than just powerful hardware or efficient code. The foundation lies in the data structure itself. An Entity Relationship Diagram (ERD) is not merely a documentation artifact; it is the blueprint for your application’s longevity. When architects design for growth, they anticipate the future load, the complexity of relationships, and the necessity of data integrity. A well-constructed schema prevents technical debt from accumulating before the first commit is even made.
This guide explores how to approach Entity Relationship Diagram design specifically for scalable environments. We will cover the theoretical underpinnings, practical trade-offs, and structural patterns that support high-throughput systems without compromising consistency.
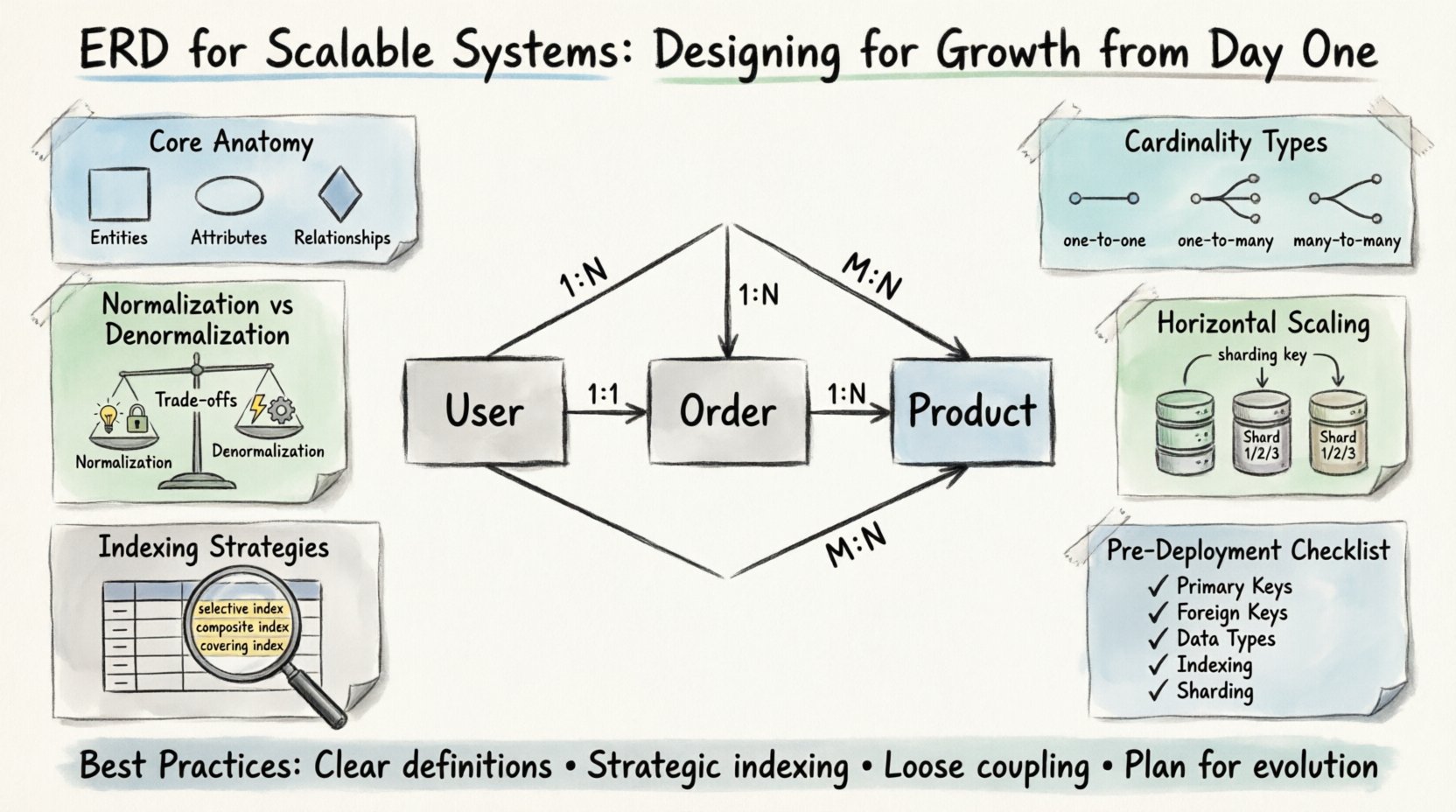
🧩 The Core Anatomy of a Scalable ERD
Before considering scale, one must understand the fundamental building blocks. Every diagram consists of entities, attributes, and relationships. In a scalable context, these elements must be defined with precision to avoid bottlenecks later.
- Entities: These represent the core objects of your business domain. Examples include Users, Orders, and Products. In high-growth systems, entities should be granular enough to allow independent scaling but cohesive enough to maintain logical boundaries.
- Attributes: These are the properties describing the entities. Data types are critical here. Choosing the correct type affects storage efficiency and query performance. For instance, using a dedicated integer type for IDs is superior to strings for indexing purposes.
- Relationships: These define how entities interact. Cardinality is the most important aspect to define early. Misinterpreting a one-to-many relationship as many-to-many can lead to unnecessary joins and severe performance degradation.
📐 Understanding Cardinality and Constraints
Cardinality dictates the number of instances of one entity that can or must relate to instances of another. In scalable systems, the choice of cardinality often determines how data is partitioned.
- One-to-One (1:1): Rarely used for performance optimization. Often implies splitting a large entity to reduce locking contention. Use only when data access patterns are strictly distinct.
- One-to-Many (1:N): The most common relationship. A User has many Orders. This structure supports efficient indexing on the foreign key side, allowing fast retrieval of related records.
- Many-to-Many (M:N): Requires a junction table. While flexible, these can become performance bottlenecks as the volume of data grows. Consider denormalization or materialized views if read frequency is high.
When defining constraints, consider the overhead of enforcement. In distributed systems, enforcing strict foreign key constraints across shards can introduce latency. In such cases, application-level validation may be necessary to maintain system throughput while preserving data integrity.
⚖️ Normalization vs. Performance Trade-offs
Normalization reduces redundancy and improves data integrity. However, high-performance systems often require a deviation from strict normalization rules. Understanding the layers helps in making informed decisions.
- First Normal Form (1NF): Atomic values. Ensures each cell contains a single value. This is non-negotiable for relational integrity.
- Second Normal Form (2NF): No partial dependency. All non-key attributes must depend on the whole primary key. Useful for reducing update anomalies.
- Third Normal Form (3NF): No transitive dependency. Non-key attributes must not depend on other non-key attributes. This is the standard target for most transactional systems.
While 3NF is ideal for consistency, it often requires complex joins. In read-heavy systems, joining multiple tables can strain the database engine. Denormalization involves duplicating data to reduce the need for joins. This increases write complexity but significantly speeds up reads.
📊 Normalization vs. Denormalization Comparison
| Feature | Normalized (3NF) | Denormalized |
|---|---|---|
| Data Integrity | High (Single Source of Truth) | Lower (Requires Sync Logic) |
| Write Performance | Faster (Less Data Written) | Slower (Redundant Writes) |
| Read Performance | Slower (Requires Joins) | Faster (Direct Access) |
| Storage Usage | Efficient | Higher (Redundancy) |
| Use Case | Transactional Systems (OLTP) | Reporting & Analytics (OLAP) |
🚀 Designing for Horizontal Scaling
As data volume grows, a single database node becomes a bottleneck. Horizontal scaling involves adding more nodes to distribute the load. Your ERD must support this architecture from the start.
- Sharding Keys: Identify a column that allows data to be split evenly across shards. This column should be present in every query that accesses the data. If a query requires scanning all shards, performance will suffer.
- Foreign Keys Across Shards: Joining tables that reside on different shards is computationally expensive. Minimize cross-shard relationships in the design phase. If a relationship is necessary, consider caching the reference data.
- Global IDs: Use unique identifiers that do not rely on auto-incrementing counters, as these can cause contention. UUIDs or distributed ID generators are preferred.
When modeling for sharding, consider the distribution of data. Hotspots occur when one shard receives significantly more traffic than others. Analyze access patterns to ensure the sharding key aligns with the most frequent query filters.
📑 Indexing Strategies for Large Datasets
Indexes are essential for query performance, but they come with a cost. Every index consumes storage and slows down write operations. A strategic approach to indexing is vital.
- Selective Indexes: Create indexes on columns that filter data significantly. A column with low cardinality (e.g., gender) is often a poor candidate for a primary index.
- Composite Indexes: Combine multiple columns in an order that matches query patterns. The leftmost prefix rule applies, meaning the first column in the index must match the query for the index to be used effectively.
- Covering Indexes: Include all columns required by a query in the index itself. This allows the database to satisfy the query without accessing the table data, known as a “covering” operation.
- Partial Indexes: Index only a subset of the table rows. This is useful for soft deletes or specific status flags, reducing the size of the index structure.
Review query execution plans regularly. An index that looks good on paper might be ignored by the query optimizer if statistics are outdated. Regular maintenance ensures the database engine makes optimal decisions.
🔄 Evolution and Schema Migrations
Systems are not static. Requirements change, and the data model must evolve. Moving from version A to version B without downtime is a critical skill.
- Additive Changes: Adding a column or table is generally safe. It does not break existing queries. This is the preferred method for introducing new features.
- Rename Operations: Renaming a column is risky. It requires updating application code. Plan for a deprecation period where both old and new names are supported.
- Constraint Addition: Adding a constraint (like NOT NULL) to existing data can fail if data exists. Validate data first, then add the constraint in a separate step.
- Backward Compatibility: Ensure that new schema versions do not break existing clients. Use feature flags to toggle new logic only when the schema is ready.
🚫 Common Pitfalls to Avoid
Even experienced designers encounter issues. Recognizing these patterns early can save significant engineering time.
- Tight Coupling: Creating relationships that force strict synchronization between unrelated entities. Keep modules loosely coupled to allow independent deployment.
- Over-Engineering: Designing for scenarios that may never happen. Focus on the 80% of use cases that drive 90% of the traffic. Simplicity aids maintainability.
- Ignoring Soft Deletes: Hard deletes remove data permanently. For audit trails or recovery, use a status flag (e.g., is_deleted) instead of physical removal.
- N+1 Query Issues: Failing to anticipate how data will be fetched. Plan for eager loading or batch fetching in the data access layer to avoid excessive database round trips.
✅ Pre-Deployment Design Checklist
Before finalizing the schema, run through this verification list to ensure readiness for scale.
- ☐ Primary Keys: Are all tables equipped with a unique, indexed primary key?
- ☐ Foreign Keys: Are relationships defined correctly? Is the cardinality accurate?
- ☐ Data Types: Are numeric types used for IDs and amounts? Are date types standardized?
- ☐ Nullability: Are required fields marked as NOT NULL?
- ☐ Indexing: Are high-traffic query columns indexed?
- ☐ Sharding: Is there a viable sharding key if horizontal scaling is anticipated?
- ☐ Constraints: Are constraints necessary for business logic, or can they be handled in the application layer?
- ☐ Documentation: Is the ERD updated to reflect the final implementation?
🛡️ Data Integrity in Distributed Environments
In a distributed setup, ACID properties (Atomicity, Consistency, Isolation, Durability) are harder to guarantee across nodes. Understanding the implications for your ERD is crucial.
- Eventual Consistency: Accept that data may be temporarily inconsistent across replicas. Design your application to handle this state gracefully.
- Idempotency: Ensure that operations can be retried without side effects. This is vital for network failures where a write might succeed but the acknowledgment is lost.
- Conflict Resolution: Define how to handle simultaneous updates to the same record. Timestamps or vector clocks can help determine the latest version.
By embedding these considerations into your Entity Relationship Diagram, you create a system that is not only functional today but robust enough for tomorrow. The cost of changing a schema in production is exponentially higher than designing it correctly initially.
🔍 Summary of Best Practices
To recap, successful scaling relies on a disciplined approach to data modeling. Focus on clear definitions, appropriate normalization, and strategic indexing. Avoid shortcuts that compromise data integrity. Regularly review your diagrams as the system evolves. A static ERD is a liability; a living model is an asset.
Invest the time in the design phase. It will pay dividends in reduced maintenance costs and higher system reliability. Your users will never see the diagram, but they will feel the performance of the system it supports.