











Designing data models in a microservices architecture requires a fundamental shift in thinking compared to monolithic applications. In a traditional system, a single Entity Relationship Diagram (ERD) often covers the entire database. In a distributed environment, that singular view fractures into multiple, independent schemas. The challenge lies in maintaining coherence without coupling services together. This guide explores how to structure data models effectively, ensuring scalability and resilience while avoiding the common pitfalls of distributed data management.
When services share data directly, they inherit each other’s dependencies. This tight coupling leads to brittle systems where a change in one area breaks another. The goal is to create boundaries that allow teams to deploy independently. Achieving this requires careful planning of relationships, consistency models, and integration patterns.
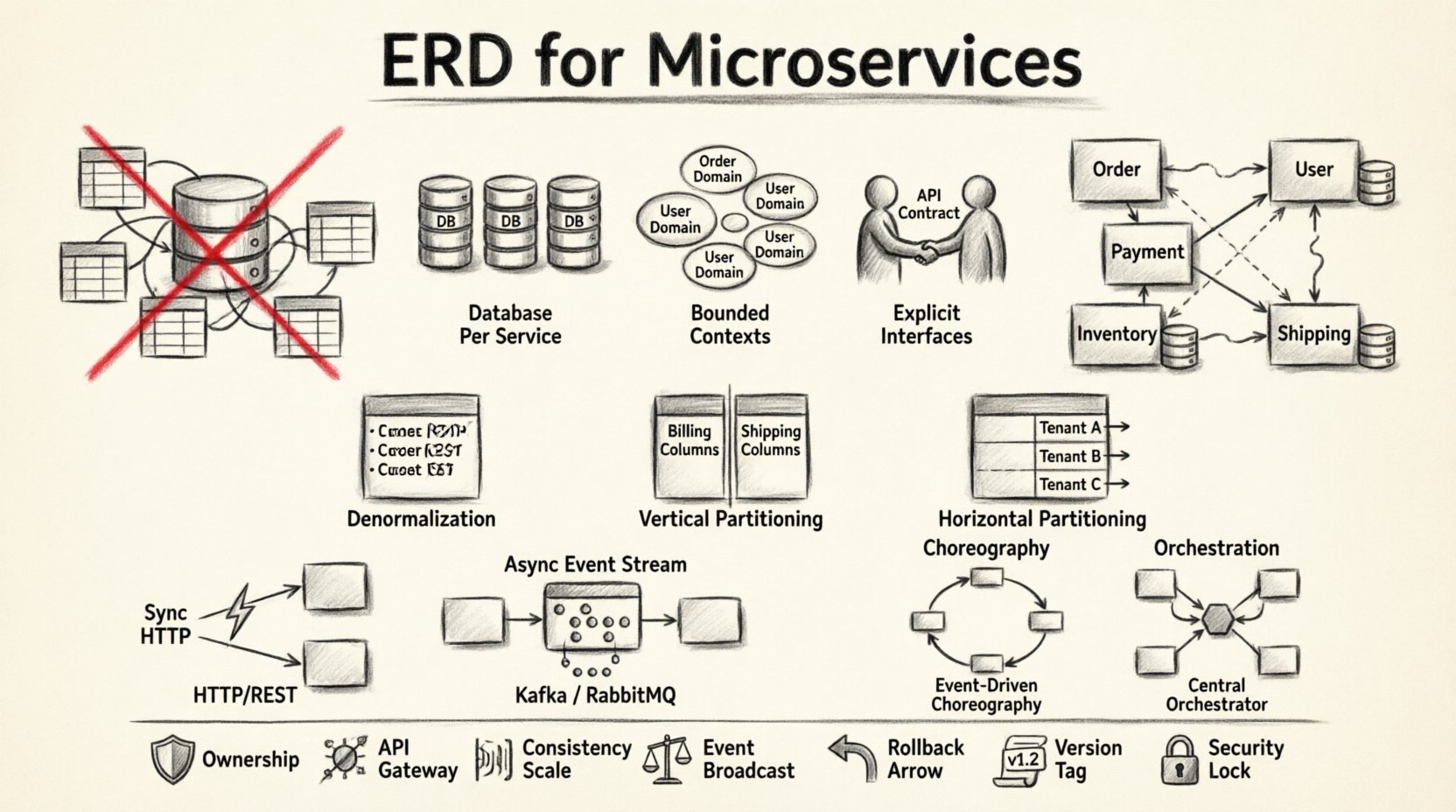
🧱 Why Traditional ERDs Break in Distributed Systems
A standard ERD assumes a central authority. It maps tables, columns, and foreign keys within a single transactional boundary. Microservices reject this centralization. When you apply a monolithic ERD mindset to a distributed system, you risk creating a distributed monolith. This happens when services rely on shared database tables rather than defined APIs.
The following issues typically arise when ignoring these principles:
- Deployment Coupling: Changes to a shared table require simultaneous deployments across multiple services.
- Transaction Boundaries: ACID transactions span multiple services, increasing latency and failure points.
- Schema Locking: Database locks in one service can stall requests in another service.
- Visibility Issues: No single team owns the global data state, leading to data silos.
Instead of a single diagram, you need a collection of service-specific schemas that communicate through well-defined interfaces. This approach prioritizes autonomy over immediate consistency.
🧬 Core Principles of Distributed Data Modeling
To maintain order, you must adhere to specific architectural principles. These guidelines help teams make decisions regarding data ownership and access patterns.
1. Database Per Service
Each microservice should own its data store. This ensures that the internal schema of a service is not visible to others. If Service A needs data from Service B, it must request it via an API, not query the database directly. This isolation protects the integrity of each domain.
- Services manage their own schema evolution.
- Teams can choose the best database technology for their specific needs (polyglot persistence).
- Failure in one database does not crash the entire application.
2. Bounded Contexts
Data must align with business capabilities. In domain-driven design, a Bounded Context defines the semantic boundary of a model. Two services might use the term “Customer,” but the data within those contexts differs. One might store contact details, while the other stores financial history. Merging these into a single ERD creates confusion and technical debt.
3. Explicit Interfaces
Since services cannot see each other’s data directly, the API becomes the data contract. The schema of the API response defines the reality of the data for the consumer. This decouples the internal storage implementation from the external consumption.
📐 Schema Design Patterns for Independence
Designing schemas for microservices involves specific patterns to handle relationships that would traditionally be handled by foreign keys. You cannot rely on database-level constraints to enforce relationships across services.
Denormalization
In a monolith, normalization reduces redundancy. In microservices, denormalization is often preferred. Storing duplicate data reduces the need for remote calls. For example, an Order Service might store the Customer Name and Address within the Order record. This avoids a synchronous lookup to the User Service every time an order is displayed.
- Benefit: Faster read performance and fewer network hops.
- Risk: Data inconsistency if the source data changes. You must handle updates via events.
Vertical Partitioning
Split large tables into smaller, focused sets. If a table contains both billing information and shipping addresses, separate these concerns. Billing data might belong to a Payments Service, while shipping addresses belong to a Logistics Service. This reduces the surface area for change and improves security by limiting access.
Horizontal Partitioning
Split data based on tenant ID or geographic region. This is useful for scaling specific services without affecting others. It allows you to replicate services for high-traffic regions while keeping others lightweight.
| Pattern | Best Use Case | Key Consideration |
|---|---|---|
| Denormalization | Read-heavy workloads | Requires synchronization logic |
| Vertical Partitioning | Distinct domains | Clear API boundaries |
| Horizontal Partitioning | High scale / Multi-tenancy | Routing logic complexity |
🔄 Handling Relationships and Consistency
The most difficult part of microservices data modeling is maintaining consistency without distributed transactions. You need to choose between Strong Consistency and Eventual Consistency.
Synchronous Communication
Services can call each other directly via HTTP or gRPC. This provides strong consistency for immediate operations. However, it introduces latency and creates a dependency chain. If Service A calls Service B, and Service B is down, Service A fails.
Asynchronous Communication
Services communicate via message queues or event streams. This decouples the timing of operations. Service A publishes an event, and Service B consumes it later. This supports eventual consistency.
- Pros: Resilience, scalability, and loose coupling.
- Cons: Data is temporarily inconsistent. Debugging requires tracing across multiple logs.
🗓️ The Saga Pattern for Data Integrity
A saga is a sequence of local transactions. Each transaction updates the local database and publishes an event to trigger the next step. If a step fails, the saga executes compensating transactions to undo previous changes.
Choreography vs. Orchestration
Sagas can be implemented in two ways:
- Choreography: Services listen for events and decide what to do next. There is no central controller. This is flexible but harder to visualize.
- Orchestration: A central coordinator tells services what to do. This provides better visibility and control over the workflow but introduces a single point of failure.
When modeling ERDs for sagas, you must account for state changes. Every service involved in a saga needs to store its state to handle rollbacks. This means your schema must support transactional states, not just final data.
📝 Managing Schema Evolution
Schema evolution is inevitable. Fields change, types shift, and constraints relax. In a distributed system, you cannot alter a database schema while other services depend on it. You must plan for versioning.
Backward Compatibility
Always maintain backward compatibility. When adding a new field, do not remove the old one immediately. Allow consumers to migrate gradually. If you must change a field name, alias the old name to the new one during a transition period.
Versioning Strategies
- URI Versioning: Include version numbers in the API path.
- Header Versioning: Use custom headers to specify the expected schema version.
- Content Negotiation: Use standard HTTP headers to request specific media types.
Documentation must be kept in sync with the code. Automated tests should verify that the API contract matches the schema. This prevents breaking changes from reaching production.
🛡️ Common Pitfalls to Avoid
Even with a solid plan, teams often stumble on specific issues. Awareness of these pitfalls helps in designing a robust system.
1. The Shared Database Trap
Do not share tables between services. It creates a hidden coupling. If the Payment Service reads the Order Service’s table, it knows too much about the internal structure. This leads to tight coupling and deployment conflicts.
2. Over-Normalization
Trying to normalize data across services leads to excessive joins and network calls. Accept some redundancy. It is better to have duplicate data than to have a slow, coupled system.
3. Ignoring Idempotency
Network calls fail. Messages get duplicated. Your schema and API logic must handle duplicate requests without causing errors. Design your endpoints to be idempotent so that retrying a request does not create duplicate records.
4. Lack of Observability
When data is distributed, you cannot query a single database to trace a transaction. You need distributed tracing and centralized logging. Your schema should include correlation IDs to track requests across service boundaries.
📋 Governance Checklist
Before deploying a new service, review the following checklist to ensure your data model is sound.
- Ownership: Is there a single service responsible for this data?
- Interface: Is the data exposed only via an API?
- Consistency: Is the consistency model documented (Strong vs. Eventual)?
- Events: Are state changes published as events for other services?
- Compensation: Is there a rollback mechanism for failed transactions?
- Versioning: Is the schema versioned to handle future changes?
- Security: Is sensitive data encrypted at rest and in transit?
🔍 Visualizing the Architecture
While you cannot draw a single ERD for the whole system, you can create a high-level map. This map shows services and their data boundaries, not specific columns.
- Draw boxes for each service.
- Label the data domain within the box (e.g., “User Profile Data”).
- Draw arrows for API calls indicating data flow.
- Indicate event streams separately from request/response flows.
This visual aid helps stakeholders understand the flow of information without getting bogged down in technical schema details. It serves as a communication tool for architects and business analysts.
🚀 Conclusion
Designing ERDs for microservices is not about drawing lines between tables. It is about defining boundaries between business capabilities. By embracing database per service, accepting eventual consistency, and rigorously managing APIs, you can build systems that scale. The chaos of distributed data is manageable with discipline and clear contracts. Focus on autonomy, minimize coupling, and ensure every service owns its data completely.
Remember that data modeling is an iterative process. As services grow, your schema will need to evolve. Regularly review your architecture against these principles to maintain a healthy, resilient system.