









Die Gestaltung einer robusten Datenarchitektur erfordert mehr als nur das Zeichnen von Kästchen und Linien. Es erfordert ein tiefes Verständnis dafür, wie Informationen durch eine Organisation fließen und wie dieser Fluss durch Regeln gesteuert wird. Ein Entitäts-Beziehungs-Diagramm (ERD) dient als struktureller Bauplan, während die Geschäftlogik das Verhalten des Systems bestimmt. Wenn diese beiden Elemente auseinanderdriften, resultiert dies oft in einem zerbrechlichen System, das Schwierigkeiten hat, sich den realen Anforderungen anzupassen. Dieser Leitfaden untersucht die entscheidende Schnittstelle zwischen Datenmodellierung und Geschäftsregeln und bietet Strategien, um sicherzustellen, dass Ihr Schema Ihre Anforderungen effektiv unterstützt.
Die Herausforderung besteht darin, abstrakte Konzepte – wie beispielsweise „Ein Benutzer kann nicht mehr bestellen, als er auf Lager hat“ – in konkrete Datenbankstrukturen zu übersetzen. Wenn das Modell die Regeln nicht widerspiegelt, leidet die Datenintegrität. Sind die Regeln zu streng, stirbt die Geschäftsfähigkeit. Wir müssen ein Gleichgewicht finden, das Konsistenz bewahrt, ohne die Operation zu behindern. Betrachten wir nun die Kernkomponenten und wie sie ausgerichtet werden können.
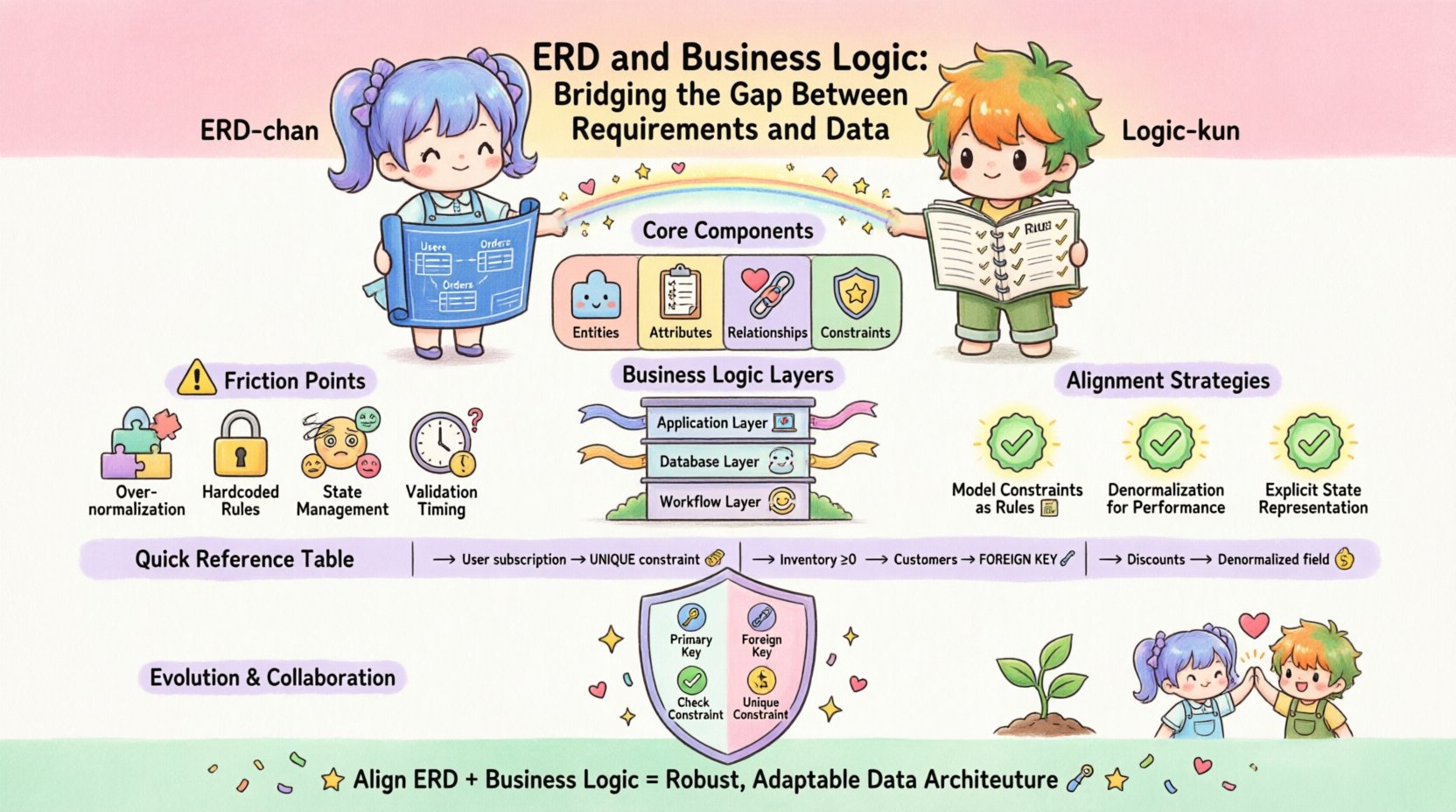
Verständnis der Kernkomponenten 🏗️
Um die Kluft zu überbrücken, müssen wir zunächst definieren, mit was wir arbeiten. Beide Seiten der Gleichung weisen unterschiedliche Eigenschaften auf, die beeinflussen, wie sie miteinander interagieren.
Das Entitäts-Beziehungs-Diagramm (ERD)
Ein ERD stellt die statische Struktur der Daten dar. Er definiert Entitäten (Tabellen), Attribute (Spalten) und Beziehungen (Fremdschlüssel). Sein primäres Ziel ist Normalisierung und Integrität. Er beantwortet die Frage: „Welche Daten müssen wir speichern?“ Zu den zentralen Aspekten gehören:
- Entitäten: Die grundlegenden Objekte des Systems, beispielsweise Kunde, Bestellung, oder Produkt.
- Attribute: Die Eigenschaften, die die Entitäten beschreiben, wie beispielsweise E-Mail, Preis, oder Status.
- Beziehungen: Wie Entitäten miteinander verbunden sind, typischerweise definiert durch Primärschlüssel und Fremdschlüssel. Diese legen die Kardinalität (eins-zu-eins, eins-zu-viele) fest.
- Einschränkungen: Regeln, die auf Datenbankebene durchgesetzt werden, wie beispielsweise
NICHT NULL,EINDEUTIG, oderÜBERPRÜFEN.
Obwohl leistungsstark, ist ein ERD oft passiv. Er speichert Daten, verarbeitet sie aber nicht von Natur aus. Er ist das Gefäß, nicht der Treiber.
Geschäftslogik
Die Geschäftslogik stellt die aktiven Regeln dar, die steuern, wie Daten erstellt, geändert und genutzt werden. Sie beantwortet die Frage: „Was dürfen wir mit diesen Daten tun?“ Diese Logik kann in verschiedenen Schichten existieren:
- Anwendungsschicht:Code im Backend oder Frontend, der Eingaben validiert, bevor sie die Datenbank erreichen.
- Datenbankschicht:Gespeicherte Prozeduren, Trigger und Einschränkungen, die Regeln direkt innerhalb der Speicherengine durchsetzen.
- Workflowschicht:Die Abfolge von Ereignissen, die erforderlich sind, um eine Aufgabe abzuschließen, beispielsweise Genehmigungsketten oder Statuswechsel.
Wenn die Geschäftslogik zu weit von der Datenstruktur getrennt ist, treten Diskrepanzen auf. Zum Beispiel, wenn die Anwendung die Eingabe einer negativen Menge zulässt, die Datenbankbeschränkung dies aber verhindert, ist die Benutzererfahrung gestört. Umgekehrt, wenn die Datenbank negative Mengen zulässt, die Anwendung sie aber blockiert, ist die Logik dupliziert und fehleranfällig.
Die Reibungspunkte: Warum die Kluft entsteht 📉
Entwickler und Datenbankarchitekten sprechen oft eine andere Sprache. Das technische Team konzentriert sich auf Leistung und Integrität, während die Geschäftsebene auf Funktionalität und Benutzererfahrung fokussiert ist. Diese Diskrepanz führt zu mehreren häufigen Reibungspunkten.
- Über-Normalisierung:Eine strikte Einhaltung der Normalisierungsregeln kann komplexe Geschäftsabfragen erschweren. Ein stark normalisierter Schema erfordert viele Joins, um Daten für eine bestimmte Geschäftsregel abzurufen, was die Anwendungslogik verlangsamt.
- Hartkodierte Regeln:Die Einbettung von Geschäftsregeln direkt in den Anwendungscode macht sie für die Datenebene unsichtbar. Wenn sich das Datenbankschema ändert, könnte die Anwendung stillschweigend fehlschlagen oder inkonsistente Daten zurückgeben.
- Zustandsverwaltung:ERDs kämpfen oft mit komplexen Zustandsmaschinen (z. B. Auftragsstatus wie „Ausstehend“, „Versandt“, „Rückerstattet“). Die Darstellung dieser als einfache Spalten kann zu verwaisten Zuständen führen, wenn die Logik nicht durchgesetzt wird.
- Zeitpunkt der Validierung:Entscheiden, ob die Validierung vor oder nach der Speicherung erfolgt, ist entscheidend. Frühe Validierung reduziert die Last, aber späte Validierung stellt sicher, dass die aktuellsten Daten verwendet werden.
Wenn diese Punkte ignoriert werden, wird das System zu einem Durcheinander aus Workarounds. Entwickler fügen temporäre Lösungen hinzu, um Beschränkungen zu umgehen, was zu technischem Schulden führt. Die Daten werden unzuverlässig, und die Geschäftslogik wird brüchig.
Strategien zur Ausrichtung 🤝
Die Brücke über diese Kluft erfordert bewusstes Design. Wir müssen das Schema als ein lebendiges Dokument betrachten, das sich mit den Geschäftsanforderungen entwickelt. Hier sind bewährte Strategien, um die Datenmodellierung mit der Logik auszurichten.
1. Modellieren Sie Einschränkungen als Geschäftsregeln
Jede Geschäftsregel, die ungültige Daten verhindert, sollte eine entsprechende Datenbankbeschränkung haben. Verlassen Sie sich nicht ausschließlich auf Anwendungscode. Dadurch wird sichergestellt, dass die Regeln unabhängig davon gelten, woher die Daten stammen – API, Skript oder direkter Import.
- Eindeutigkeit:Wenn ein Benutzername eindeutig sein muss, setzen Sie dies auf Spaltenebene durch. Prüfen Sie ihn nicht zuerst in der Anwendung, da Race-Conditions auftreten können.
- Bereichsüberprüfungen: Wenn ein Rabatt 100 % nicht überschreiten darf, verwenden Sie eine
CHECKEinschränkung. Dies verhindert versehentliche Datenbeschädigung durch Massenupdates. - Referenzielle Integrität: Verwenden Sie Fremdschlüssel, um sicherzustellen, dass eine Bestellung immer einem gültigen Kunden zugeordnet ist. Wenn ein Kunde gelöscht wird, entscheiden Sie basierend auf den geschäftlichen Anforderungen, ob die Bestellung erhalten bleibt (weiche Löschung) oder entfernt wird (Kaskadenlöschung).
2. Denormalisierung zur Leistungssteigerung der Logik
Während Normalisierung gut für die Speicherung ist, ist sie nicht immer gut für die Logik. Komplexe Geschäftsregeln erfordern oft die Aggregation von Daten aus mehreren Quellen. Wenn die Logik leseschwer ist, erwägen Sie die Denormalisierung bestimmter Attribute.
- Gecachte Gesamtbeträge: Anstatt die Zeilenpositionen jedes Mal zu summieren, wenn ein Gesamtbetrag benötigt wird, speichern Sie den Gesamtbetrag in der Bestellungstabelle. Aktualisieren Sie dieses Feld jedes Mal, wenn sich eine Zeilenposition ändert.
- Status-Flags: Wenn der Benutzerstatus den Zugriff bestimmt, speichern Sie ihn in einer Spalte statt über eine Historientabelle zu verknüpfen. Dies beschleunigt die Logik, die Berechtigungen überprüft.
Dieser Ansatz tauscht Speicherplatz gegen Abfragegeschwindigkeit und logische Einfachheit ein. Er muss sorgfältig verwaltet werden, um Dateninkonsistenzen zu vermeiden.
3. Explizite Zustandsdarstellung
Für Workflows sollte die Datenbank den Zustand explizit widerspiegeln. Verwenden Sie eine spezielle Status-Spalte mit einem eingeschränkten Wertesatz. Vermeiden Sie die Verwendung von Freitextfeldern für den Zustand.
- Aufgezählte Werte: Definieren Sie die zulässigen Status klar. Dadurch wird Berichterstattung und Logik einfacher.
- Übergangstabellen: Für komplexe Workflows verwenden Sie eine Verbindungstabelle, um die Historie zu verfolgen. Dadurch können Sie den Logikpfad rekonstruieren, der zum aktuellen Zustand geführt hat.
Zuordnung der Logik zur Schemastruktur: Eine praktische Tabelle 📊
Um zu visualisieren, wie abstrakte Regeln in konkrete Strukturen übersetzt werden, verweisen Sie auf die untenstehende Zuordnung. Diese Tabelle zeigt gemeinsame geschäftliche Anforderungen und ihre entsprechenden Datenmodellierungs-Muster auf.
| Geschäftsanforderung | Logische Implikation | Schema-Implementierung |
|---|---|---|
| Ein Benutzer kann nur eine aktive Abonnement haben | Eindeutigkeitsbeschränkung für den aktiven Zustand | EINDEUTIG (Benutzer-ID, Status) wo Status = ‘aktiv’ |
| Der Bestand kann nicht unter null gehen | Validierung beim Schreiben | ÜBERPRÜFUNG (Menge >= 0) oder Trigger-Logik |
| Bestellungen müssen bestehenden Kunden zugeordnet sein | Referenzielle Integrität | FREMDSCHLÜSSEL (customer_id) VERWEIST AUF Customers(id) |
| Rabatte werden pro Artikel berechnet | Entnormalisierter Speicher | Speichern rabattierter_Preis im OrderItem, Aktualisierung bei Änderung |
| Protokolle müssen fünf Jahre lang aufbewahrt werden | Lebenszyklus-Management | erstellt_am Spalte + Hintergrundaufgabe zur Archivierung |
| Rollen bestimmen den Zugriff auf Funktionen | Assoziations-Mapping | Zwischentabelle RollenBerechtigungen Verknüpfung von Benutzern mit Funktionen |
Diese Zuordnung stellt sicher, dass jede Regel in dem Datenmodell einen Platz hat. Sie verhindert die Situation, in der Logik nur im Code existiert und die Daten dadurch verwundbar sind.
Validierung und Einschränkungen: Die Sicherheitsnetz 🛡️
Einschränkungen sind die erste Verteidigungslinie für die Datenintegrität. Sie werden vom Datenbank-Engine durchgesetzt, was sie schneller und zuverlässiger als Überprüfungen auf Anwendungsebene macht. Sie sollten jedoch nicht die einzigeEbene sein.
Arten von Einschränkungen
- Primärschlüssel: Stellen sicher, dass jedes Datensatz eindeutig identifizierbar ist. Dies ist für alle Beziehungen grundlegend.
- Fremdschlüssel: Pflegen Sie Beziehungen zwischen Tabellen. Sie verhindern verwaiste Datensätze.
- Überprüfungsbeschränkungen: Definieren Sie spezifische Bedingungen für Spaltenwerte. Nützlich für Bereiche, Formate oder Logik wie
preis > 0. - Eindeutigkeitsbeschränkungen: Verhindern Sie doppelte Daten. Unverzichtbar für E-Mails, Benutzernamen oder SKUs.
Trigger und gespeicherte Prozeduren
Manchmal reicht eine Beschränkung nicht aus. Komplexe Logik, wie das Aktualisieren eines Kontostands über mehrere Tabellen hinweg bei einer Transaktion, erfordert Trigger. Obwohl sie leistungsstark sind, sollten Trigger sparsam eingesetzt werden. Sie können Logik vor Entwicklern verbergen und die Fehlersuche erschweren.
- Anwendungsfall:Automatisches Archivieren alter Datensätze.
- Anwendungsfall:Berechnung abgeleiteter Felder vor dem Einfügen.
- Warnung:Vermeiden Sie Geschäftslogik, die besser in der Anwendungsschicht liegt. Trigger sollten sich auf Datenintegrität konzentrieren, nicht auf benutzergerechte Abläufe.
Entwicklung und Refaktorisierung 🔄
Geschäftsregeln ändern sich. Ein Unternehmen könnte mit dem Verkauf von Abonnements beginnen und später zu Einmalzahlungen wechseln. Das Datenmodell muss in der Lage sein, sich zu entwickeln, ohne bestehende Logik zu brechen.
Versionsverwaltung des Schemas
Änderungen am ERD sollten versioniert werden. Verwenden Sie Migrations-Skripte zur Verwaltung von Übergängen. Dadurch können Sie bei einer unerwarteten Störung der Geschäftslogik rückgängig machen.
- Rückwärtskompatibilität: Wenn Sie eine Spalte hinzufügen, machen Sie sie zunächst nullable. Dadurch kann die alte Logik weiterlaufen, während die neue Logik bereitgestellt wird.
- Veraltung: Löschen Sie Spalten nicht sofort. Kennzeichnen Sie sie als veraltet und behalten Sie sie für eine gewisse Zeit, um alte Integrationen zu unterstützen.
- Dokumentation: Halten Sie die Schemadokumentation mit dem Code synchron. Ein Kommentar im ERD sollte die Geschäftsregel hinter einer Spalte erklären.
Refaktorisierung für Logik
Wenn die Anforderungen wachsen, kann das ursprüngliche ERD zu einer Engstelle werden. Sie müssen möglicherweise Tabellen aufteilen oder zusammenführen. Dies ist eine erhebliche Aufgabe, die sorgfältige Planung erfordert.
- Identifizieren Sie die Logik: Bestimmen Sie, welche Geschäftsregeln Leistungs- oder Integritätsprobleme verursachen.
- Planen Sie den Umzug:Erstellen Sie ein Skript, um Daten in die neue Struktur zu verschieben, während die Konsistenz gewahrt bleibt.
- Testen Sie gründlich:Führen Sie die neue Logik anhand historischer Daten aus, um sicherzustellen, dass sie wie erwartet funktioniert.
Zusammenarbeit und Dokumentation 📝
Die technische Ausrichtung ist nur die Hälfte des Kampfes. Die andere Hälfte ist die Kommunikation. Das Datenbank-Schema ist ein Vertrag zwischen der Datenebene und der Anwendungsebene. Jeder Beteiligte muss ihn verstehen.
Geteiltes Vokabular
Stellen Sie sicher, dass die Begriffe in der Datenbank mit der geschäftlichen Terminologie übereinstimmen. Wenn das Geschäft es als „Kunde“ bezeichnet, nennen Sie die Tabelle nicht „Kunde“. Wenn das Geschäft ein Feld „Status“ nennt, nennen Sie es nicht „Flag“. Konsistenz verringert die kognitive Belastung.
Visuelle Dokumentation
ERDs sind visuell, können aber dicht sein. Ergänzen Sie sie mit Diagrammen, die den Datenfluss neben der Struktur zeigen. Markieren Sie, wo die Geschäftslogik mit den Daten interagiert.
- Datensatzverzeichnis:Pflegen Sie ein Dokument, das den Zweck jeder Tabelle und jedes Feldes erklärt.
- Logik-Flussdiagramme:Zeichnen Sie auf, wie Daten von der Eingabe zur Speicherung gelangen, und notieren Sie, wo die Validierung stattfindet.
- Beschränkungslisten:Führen Sie eine Liste aller Regeln, die von der Datenbank durchgesetzt werden, für eine einfache Referenz während der Entwicklung.
Abschließende Gedanken zur Datenintegrität 🎯
Die Beziehung zwischen einem ERD und der Geschäftslogik ist symbiotisch. Der ERD liefert die Grundlage, und die Geschäftslogik gibt den Zweck vor. Wenn sie nicht ausgerichtet sind, kann das System keinen Wert liefern. Wenn sie ausgerichtet sind, wird das System zu einer zuverlässigen Maschine für das Geschäft.
Erfolg entsteht daraus, die Datenbank als Partner bei der Durchsetzung der Logik zu betrachten, nicht nur als Speicherplatz. Durch die Implementierung von Beschränkungen, die explizite Verwaltung des Zustands und die Pflege klarer Dokumentation schaffen Sie ein System, das sowohl robust als auch anpassungsfähig ist. Das Ziel besteht nicht darin, jede zukünftige Anforderung vorherzusagen, sondern eine Struktur zu bauen, die Veränderungen ohne Zusammenbruch bewältigen kann.
Beginnen Sie mit den Regeln. Definieren Sie, welche Daten gültig sind, bevor Sie definieren, wie sie gespeichert werden. Lassen Sie die Geschäftslogik die Schema-Struktur leiten und lassen Sie das Schema die Logik schützen. Diese Ausrichtung ist der Eckpfeiler einer nachhaltigen Datenarchitektur. 🚀