











La modélisation des données est souvent considérée comme un exercice statique consistant à définir des relations et des entités. Toutefois, un diagramme Entité-Relation (ERD) n’est pas simplement un plan de stockage ; il détermine directement l’efficacité avec laquelle un moteur de base de données récupère et manipule les informations. Chaque ligne tracée, chaque relation définie et chaque type de données choisi a des répercussions sur le plan d’exécution de vos requêtes. Comprendre les mécanismes derrière la conception du schéma permet de concevoir des systèmes qui évoluent de manière fluide sous charge.
Ce guide explore la relation technique entre les structures ERD et la performance des requêtes. Nous allons aller au-delà des définitions basiques pour examiner comment des décisions spécifiques de modélisation influencent les opérations d’E/S, l’utilisation du CPU et les mécanismes de verrouillage dans un environnement relationnel.
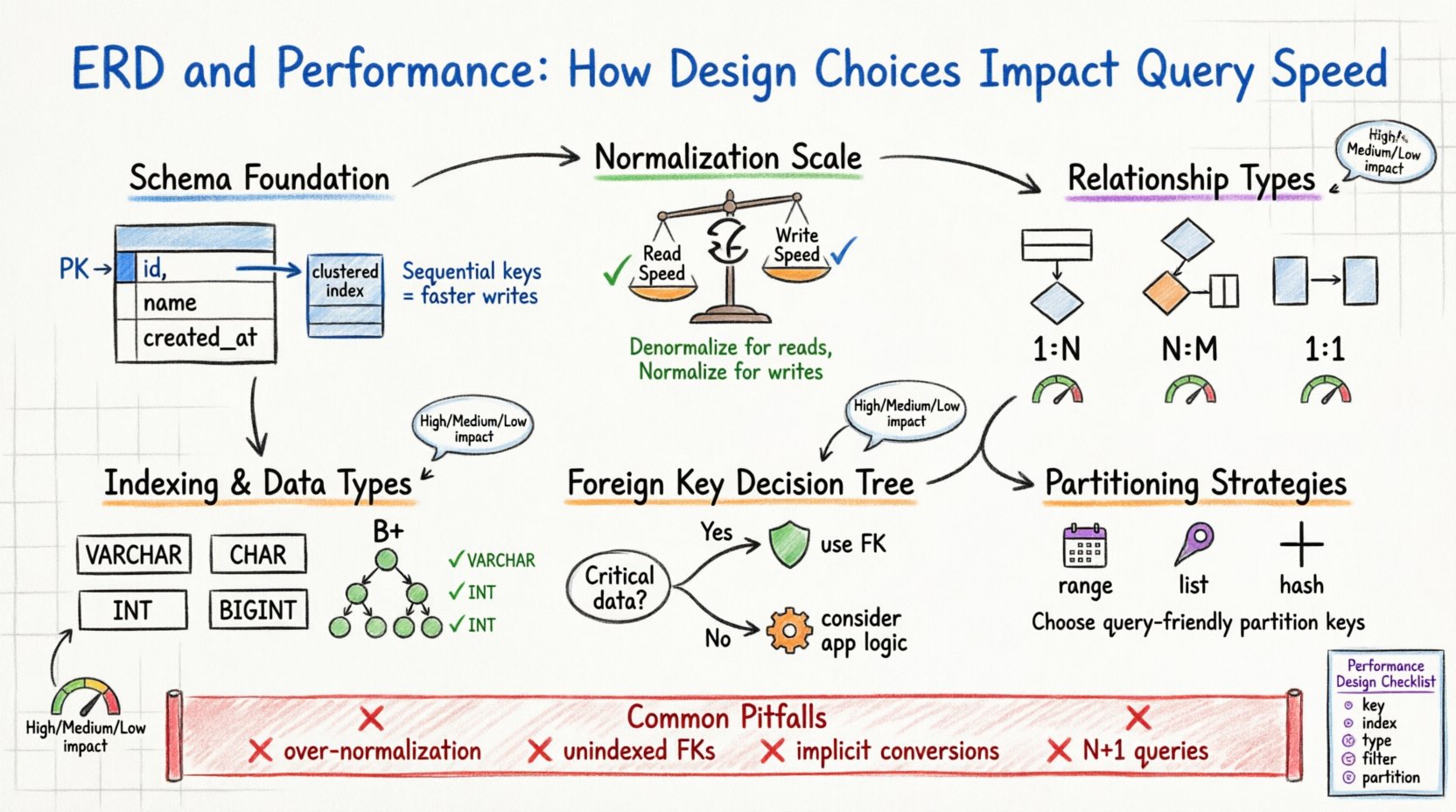
1. La fondation : structure du schéma et stockage physique 🏗️
La conception logique que vous créez dans votre ERD se traduit finalement en fichiers physiques sur un disque. Le moteur de base de données doit mapper ces entités logiques en pages, blocs et lignes. Lorsque le schéma est optimisé, le moteur minimise le nombre de lectures disque nécessaires pour satisfaire une requête. Lorsqu’il ne l’est pas, le moteur peut être obligé d’effectuer des analyses complètes de table, des opérations coûteuses.
Pensez à la clé primaire. Elle sert d’identifiant unique pour une ligne. Dans de nombreux moteurs de stockage, la clé primaire définit l’ordre physique des données sur le disque (index clusterisé). Choisir une clé primaire séquentielle et courte garantit que les données sont stockées de manière contiguë. Cela réduit la fragmentation et permet des balayages par plage plus rapides. À l’inverse, une clé primaire aléatoire et longue peut provoquer des séparations de pages lors des insertions, ce qui dégrade les performances d’écriture et augmente la surcharge de stockage.
Principaux éléments à considérer pour les clés primaires
- Séquentialité :Les entiers auto-incrémentés sont généralement préférés pour les charges de travail intensives en écriture.
- Taille :Les clés plus petites réduisent la taille des index secondaires, car elles sont stockées comme des pointeurs dans ces index.
- Stabilité :Les clés primaires ne doivent pas changer. La mise à jour d’une clé primaire exige souvent la mise à jour de toutes les clés étrangères associées.
2. Normalisation vs. compromis performance ⚖️
La normalisation est le processus d’organisation des données afin de réduire la redondance et d’améliorer l’intégrité. Bien qu’elle soit traditionnellement associée à la qualité des données, elle a des effets profonds sur les performances. Un schéma fortement normalisé (par exemple, Troisième Forme Normale) nécessite souvent plus de jointures pour reconstruire les données, tandis qu’un schéma dénormalisé réduit les jointures mais augmente le stockage et la complexité des mises à jour.
Le choix entre normaliser ou dénormaliser représente un équilibre entre la vitesse de lecture et la vitesse d’écriture. Dans un environnement intensif en lectures, la dénormalisation peut réduire considérablement le temps de requête en évitant les jointures complexes. Dans un environnement intensif en écritures, la normalisation réduit le nombre de lignes à mettre à jour sur plusieurs tables.
Analyse des impacts de la normalisation
| Aspect | Très normalisé | Dénormalisé |
|---|---|---|
| Performance en lecture | Plus faible (nécessite des jointures) | Plus élevé (accès à une seule table) |
| Performance en écriture | Plus élevé (moins de redondance) | Plus faible (mise à jour de plusieurs copies) |
| Intégrité des données | Élevée (source unique de vérité) | Plus faible (risque d’incohérence) |
| Utilisation du stockage | Inférieur | Supérieur |
3. Clés étrangères et surcharge d’intégrité 🔗
Les clés étrangères assurent l’intégrité référentielle. Elles garantissent qu’une valeur dans une table correspond à une valeur dans une autre. Bien que cela empêche les enregistrements orphelins, cela introduit une surcharge au moment de l’exécution. Lorsque vous insérez, mettez à jour ou supprimez une ligne, la base de données doit vérifier la contrainte de clé étrangère.
Cette vérification n’est pas gratuite. Le moteur doit localiser la ligne référencée et vérifier son existence. Si la table référencée est grande et ne dispose pas d’un index sur la colonne de clé étrangère, la vérification devient un balayage complet de la table. En outre, la suppression d’un enregistrement parent oblige le moteur à vérifier tous les enregistrements enfants pour s’assurer qu’aucune référence ne reste, ce qui peut verrouiller de nombreuses lignes.
Quand utiliser les clés étrangères
- Intégrité critique des données : Si la correction des données est primordiale (par exemple, les transactions financières), utilisez les clés étrangères.
- Logique de l’application : Si la logique de l’application est complexe, déléguer l’intégrité à la base de données simplifie le code.
- Petits jeux de données : La surcharge est négligeable sur les petites tables.
Quand éviter les clés étrangères
- Haute capacité d’écriture : Supprimer les contraintes peut réduire les conflits de verrouillage.
- Analytique à grande échelle : Dans les entrepôts de données, les performances l’emportent souvent sur une intégrité stricte.
- Niveaux architecturaux : Dans les microservices, maintenir des clés étrangères au-delà des frontières des services est souvent impraticable.
4. Stratégies d’indexation et types de colonnes 📑
Un MCD définit les types de données pour chaque colonne. Le choix entre VARCHAR et CHAR, ou entre INT et BIGINT, influence la manière dont les données sont stockées et indexées. Les types de données plus petits consomment moins de mémoire et d’espace disque, permettant ainsi de stocker davantage de données dans le pool de tampon (RAM).
Lorsqu’une requête filtre sur une colonne, le moteur de base de données s’appuie sur les index pour trouver rapidement les lignes. Si la conception du schéma ne correspond pas aux modèles de requêtes, les index deviennent inutiles. Par exemple, créer un index sur une colonne rarement utilisée dans des clauses WHERE est une perte de ressources.
Optimisation des types de colonnes
- Longueur fixe vs. longueur variable : Utilisez CHAR pour les données de longueur fixe (par exemple, les codes pays) afin de réduire la fragmentation. Utilisez VARCHAR pour les données de longueur variable.
- Plages d’entiers : N’utilisez pas BIGINT si INT suffit. Les entiers plus petits permettent d’insérer plus de lignes par page.
- Représentation booléenne : Utilisez les types TINYINT(1) ou BOOLEAN plutôt que de stocker des chaînes ‘Oui’/’Non’.
5. Implications de la cardinalité des relations 📊
La cardinalité des relations (un à un, un à plusieurs, plusieurs à plusieurs) détermine la manière dont les données sont liées. Chaque type de relation présente des caractéristiques de performance différentes.
Un à plusieurs (1:N)
Il s’agit de la relation la plus courante. Une table parente contient un enregistrement, tandis qu’une table enfant en contient plusieurs. Les performances dépendent fortement de l’index sur la colonne clé étrangère dans la table enfant. Sans cet index, trouver tous les enfants d’un parent nécessite un balayage complet de la table enfant.
Plusieurs à plusieurs (N:M)
Cela nécessite une table de jonction (entité associative). Cela ajoute une couche supplémentaire d’indirection. Les requêtes impliquant des relations N:M nécessitent généralement trois jointures : Table A, Table de jonction, Table B. Cette complexité augmente l’utilisation du CPU et les besoins en mémoire.
Un à un (1:1)
Souvent utilisé pour diviser une grande table en groupes logiques. Cela peut améliorer les performances si seule une sous-ensemble de colonnes est fréquemment interrogée. Toutefois, cela ajoute le coût d’une jointure pour récupérer l’enregistrement complet.
6. Considérations sur le partitionnement et le fractionnement 🗃️
À mesure que les données augmentent, une seule table peut devenir trop grande pour être gérée efficacement. Le partitionnement permet de diviser une grande table en morceaux plus petits et plus faciles à gérer, selon une clé (par exemple, une date). La conception du schéma ERD doit anticiper cela.
Si vous concevez un schéma pour un système qui sera éventuellement fractionné (réparti sur plusieurs serveurs), la clé de partitionnement doit être choisie avec soin. Cette clé doit être utilisée fréquemment dans les requêtes afin que le moteur puisse acheminer les demandes vers le bon shard. Choisir une clé qui n’est pas utilisée dans les requêtes oblige le système à agréger les données de tous les shards, ce qui est lent.
Stratégies de partitionnement
- Partitionnement par plage : Division par plages de dates ou d’ID. Adapté aux données de séries temporelles.
- Partitionnement par liste : Division par des valeurs spécifiques (par exemple, codes régions).
- Partitionnement par hachage : Répartit les données de manière équilibrée pour éviter les points de surcharge.
7. Pièges courants dans la conception 🚫
Même les architectes expérimentés peuvent introduire des goulets d’étranglement de performance à travers leurs choix de conception. Reconnaître ces modèles tôt évite des refontes coûteuses plus tard.
- Sur-normalisation :Diviser les données en trop nombreuses petites tables augmente la complexité des jointures et réduit l’efficacité du cache.
- Ignorer la sélectivité :Indexer des colonnes à faible sélectivité (par exemple, sexe ou indicateurs d’état) donne souvent de mauvaises performances, car l’optimiseur peut ignorer l’index et scanner la table de toute façon.
- Conversions implicites :Concevoir une colonne comme chaîne de caractères alors que des valeurs numériques sont attendues oblige le moteur à convertir les types lors des requêtes, empêchant ainsi l’utilisation de l’index.
- Schémas de requêtes N+1 :Concevoir des relations qui encouragent à récupérer les données en boucles plutôt que par des jointures par lots peut surcharger le serveur.
8. Préparation à l’avenir et évolution 🛡️
Les bases de données évoluent. Les exigences changent, et de nouvelles fonctionnalités sont ajoutées. Un schéma performant aujourd’hui peut devenir un goulet d’étranglement demain s’il manque de flexibilité. Le schéma ERD doit pouvoir accomoder la croissance sans nécessiter une refonte complète.
Pensez à ajouter des colonnes susceptibles d’être utilisées pour le filtrage à l’avenir. Bien que cela augmente légèrement la taille des lignes, cela évite le coût de la modification de la structure de la table plus tard, opération coûteuse sur de grandes quantités de données. En outre, tenez compte de l’impact de l’ajout de nouveaux index. Chaque index consomme des ressources d’écriture. Concevez le schéma pour minimiser le nombre d’index nécessaires.
Liste de contrôle de conception pour les performances
- Les clés primaires sont-elles courtes et séquentielles ?
- Les clés étrangères sont-elles indexées ?
- Les types de données sont-ils les plus petits types valides possibles ?
- Les filtres fréquents sont-ils couverts par des index ?
- Le niveau de normalisation est-il adapté à la charge de travail ?
- Avez-vous envisagé la partition des grandes tables ?
- Y a-t-il des colonnes stockant des JSON ou du texte complexes qui pourraient être structurés ?
9. Le rôle du plan d’exécution 📋
En fin de compte, le moteur de base de données décide comment exécuter une requête en fonction du schéma et des statistiques. Le MCD influence les statistiques que le moteur collecte. Par exemple, une colonne avec une distribution de valeurs distinctes sera traitée différemment d’une colonne avec des données biaisées. Comprendre le fonctionnement du plan d’exécution vous aide à interpréter pourquoi une requête est lente.
Si une requête effectue un balayage complet de la table, cela indique souvent un index manquant ou une conception qui ne permet pas un filtrage efficace. Si elle effectue de nombreux boucles imbriquées, cela suggère des jointures complexes pouvant être simplifiées. En alignant le MCD avec les modèles d’accès attendus, vous guidez le moteur vers des plans d’exécution optimaux.
10. Équilibrer l’intégrité et la vitesse ⚖️
Il n’existe pas de schéma parfait. Chaque choix de conception implique un compromis. L’objectif n’est pas d’éliminer les problèmes de performance, mais de les gérer de manière stratégique. Dans certains cas, accepter un petit risque d’incohérence des données (via des vérifications au niveau de l’application plutôt que des contraintes de base de données) est un compromis valable pour atteindre un débit d’écriture extrême.
Revoyez régulièrement votre MCD par rapport aux journaux de requêtes réels. Identifiez les requêtes les plus lentes et remontez-les jusqu’au schéma. Cette boucle de rétroaction garantit que votre conception évolue en harmonie avec les besoins de votre application.
Résumé des domaines d’impact 📝
| Élément de conception | Impact sur les performances | Recommandation |
|---|---|---|
| Type de clé primaire | Élevé (stockage et indexation) | Utilisez de manière cohérente des entiers ou des UUID. |
| Clés étrangères | Moyen (surcharge d’écriture) | Indexez les colonnes FK ; supprimez-les si l’intégrité est gérée ailleurs. |
| Normalisation | Élevé (complexité des jointures) | Dénormalisez les tables fortement lues. |
| Types de données | Moyen (utilisation de la mémoire) | Utilisez le type le plus spécifique disponible. |
| Cardinalité | Élevé (coût de jointure) | Optimisez les tables de jonction pour les relations N:M. |
En traitant le diagramme d’entités et de relations comme un artefact de performance plutôt que simplement comme une carte logique, vous pouvez construire des systèmes robustes, évolutifs et efficaces. Les décisions que vous prenez aujourd’hui détermineront le comportement de votre application pendant de nombreuses années à venir.