








Concevoir un modèle de données robuste n’est pas simplement un exercice académique ; c’est la fondation sur laquelle repose la stabilité de l’application. Un diagramme d’entités et de relations (ERD) sert de plan directeur pour la manière dont les informations sont stockées, liées et récupérées dans un environnement de production. Lorsque les systèmes évoluent, le coût d’un mauvais modèle devient exponentiel. Ce guide examine une mise en œuvre concrète d’un ERD au sein d’une architecture backend complexe, en mettant l’accent sur l’intégrité des données, la scalabilité et la maintenabilité.
Trop souvent, les développeurs se concentrent sur la logique de l’application tout en traitant la base de données comme une préoccupation secondaire. Or, le schéma détermine les limites de ce que le système peut faire efficacement. En analysant un scénario du monde réel, nous pouvons comprendre les compromis liés à la normalisation des données, à la gestion des relations et à la garantie de l’intégrité référentielle sans dépendre de fournisseurs logiciels spécifiques.
📋 Le scénario métier
Prenons une plateforme de services multi-locataires conçue pour gérer des projets collaboratifs. Le système exige une isolation stricte entre les différentes organisations clientes tout en permettant une flexibilité interne au sein de ces organisations. Les exigences fondamentales incluent :
- Multi-locataire :Les données doivent être séparées par organisation afin d’assurer la sécurité.
- Flux de travail complexes :Les tâches doivent être attribuées, suivies et liées à des projets spécifiques.
- Traçabilité des audits :Tout changement important apporté à un enregistrement doit être journalisé pour assurer la conformité.
- Évolutivité :Le schéma doit supporter des millions d’enregistrements sans dégrader les performances des requêtes.
Le défi réside dans la traduction de ces règles métiers en une structure relationnelle qui prévient les anomalies de données. Une erreur courante consiste à créer des structures trop normalisées nécessitant des jointures excessives, ou des structures trop dénormalisées entraînant une redondance des données et des anomalies de mise à jour.
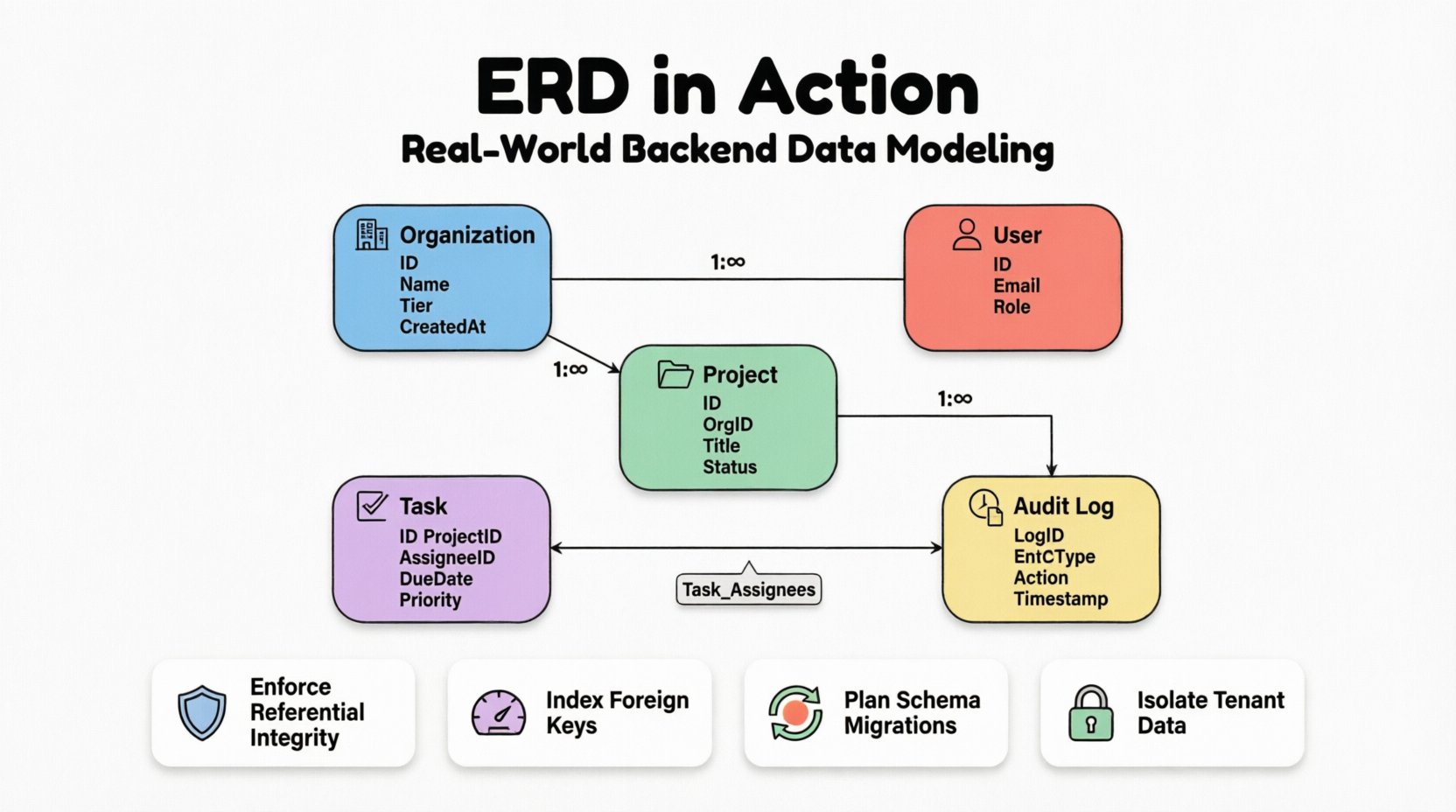
🔍 Entités et attributs principaux
Le pilier de tout ERD est la définition des entités. Dans cette étude de cas, nous identifions cinq entités principales. Chaque entité représente un concept distinct qui doit être persisté dans la base de données. Les attributs associés à ces entités définissent le niveau de granularité des données stockées.
1. Entité Organisation
C’est la racine de la hiérarchie. Tous les autres enregistrements sont liés à cette entité afin de garantir l’isolation des locataires.
- ID de l’organisation :Identifiant unique.
- Nom de l’organisation :Étiquette lisible par l’humain.
- Niveau d’abonnement : Détermine l’accès aux fonctionnalités.
- Créé le :Horodatage pour l’audit.
2. Entité Utilisateur
Les utilisateurs appartiennent à des organisations, mais peuvent être membres de plusieurs projets. Les détails d’authentification sont séparés des données métier afin de respecter les meilleures pratiques de sécurité.
- ID utilisateur :Identifiant unique.
- Courriel : Utilisé pour l’authentification et le contact.
- Hachage du mot de passe :Stockage sécurisé des identifiants.
- Rôle : Définit les autorisations (Administrateur, Membre, Visualisateur).
3. Entité Projet
Les projets sont les conteneurs des éléments de travail. Ils sont détenus par une organisation mais traités par des utilisateurs.
- ID du projet :Identifiant unique.
- ID de l’organisation :Clé étrangère liée au locataire parent.
- Titre :Nom abrégé du projet.
- Statut :Actif, archivé ou supprimé.
4. Entité Tâche
L’unité fondamentale du travail. Cette entité nécessite les relations les plus complexes car elle lie les utilisateurs, les projets et les journaux.
- ID de la tâche :Identifiant unique.
- ID du projet :Clé étrangère.
- ID du destinataire :Clé étrangère vers l’utilisateur.
- Date d’échéance :Contrainte temporelle.
- Priorité :Valeur énumérée.
5. Entité Journal d’audit
Enregistre chaque modification apportée aux entités critiques. Cela garantit la traçabilité.
- ID du journal : Identifiant unique.
- Type d’entité : Quelle table a été affectée.
- ID de l’enregistrement : Quelle ligne a été affectée.
- Action : Créer, mettre à jour, supprimer.
- Effectué par : ID utilisateur.
- Horodatage : Heure de l’action.
🔗 Modélisation des relations et de la cardinalité
Les relations définissent la manière dont les entités interagissent. Dans un système de production, ces relations sont assurées par des clés étrangères. La cardinalité (un à un, un à plusieurs, plusieurs à plusieurs) détermine la manière dont les données sont interrogées et mises à jour.
Organisation vers Utilisateur
Il s’agit d’une Un à plusieurs relation. Une organisation peut avoir plusieurs utilisateurs, mais un enregistrement utilisateur est lié à une seule organisation à des fins d’isolement des données. Pour éviter toute fuite de données entre les locataires, la organization_id est une clé étrangère obligatoire dans la table Utilisateur.
Organisation vers Projet
De manière similaire, il s’agit d’une Un à plusieurs relation. Les projets ne peuvent exister sans organisation parente. Si une organisation est supprimée, le comportement en cascade doit être soigneusement examiné. Dans ce cas, nous choisissons de supprimer de manière douce les projets plutôt que de les supprimer définitivement, afin de préserver le contexte historique.
Projet vers Tâche
Une autre Un à plusieurs relation. Un projet contient plusieurs tâches, et une tâche appartient à exactement un projet. Il s’agit d’un lien structurel standard.
Utilisateur vers Tâche (affectation)
Il s’agit de la relation la plus critique. Un utilisateur peut être affecté à plusieurs tâches, et une tâche peut être affectée à plusieurs utilisateurs (travail collaboratif). Cela nécessite une Nombreux-à-nombreux relation.
Pour implémenter cela, nous introduisons une table de jonction, souvent appelée entité associative. Cette table divise la relation nombreuses-à-nombreuses en deux relations un-à-plusieurs.
| Nom de la table | Objectif | Clés |
|---|---|---|
| Tâche_Assignataires | Lien entre les utilisateurs et les tâches | ID_Tâche, ID_Utilisateur |
| Organisation_Locataires | Lien entre les organisations et les utilisateurs | ID_Organisation, ID_Utilisateur |
L’utilisation d’une table de jonction nous permet de stocker des métadonnées supplémentaires. Par exemple, dans la table Tâche_Assignataires table, nous pourrions stocker le rôle que l’utilisateur avait sur cette tâche spécifique (par exemple, Responsable, Contributrice), ce qui diffère de leur rôle utilisateur global.
⚖️ Contraintes et intégrité des données
La validation au niveau de l’application n’est pas suffisante. Les contraintes de base de données agissent comme la dernière ligne de défense contre la corruption des données. Dans un environnement de production, les contraintes doivent être définies au niveau du schéma.
Intégrité référentielle
Les clés étrangères garantissent qu’un enregistrement dans une table enfant ne peut pas référencer un parent inexistant. Par exemple, une tâche ne peut pas être attribuée à un utilisateur qui n’existe pas dans le système.
Cependant, les comportements SUR SUPPRESSION et SUR MISE À JOUR sont des décisions critiques :
- CASCADE : Si un parent est supprimé, tous les enfants sont supprimés. Utilisez cela pour les données orphelines qui n’ont aucun sens sans le parent (par exemple, les commentaires sur un post supprimé).
- RESTREINDRE : Empêche la suppression si des enfants existent. Utilisez cela pour éviter la perte accidentelle de données (par exemple, supprimer une organisation qui possède des enregistrements de facturation actifs).
- METTRE À NULL : Si le parent est supprimé, la colonne clé étrangère dans l’enfant devient NULL. Utilisez cela lorsque la relation est facultative.
Contraintes de vérification
SQL standard prend en charge les contraintes de vérification pour appliquer des règles spécifiques au domaine. Des exemples incluent :
- Date d’échéance : La
due_datecolonne doit être supérieure à lacreated_atcolonne. - Priorité : La
prioritycolonne doit correspondre à une liste spécifique de valeurs autorisées (par exemple, Faible, Moyen, Élevé). - Montant :Les champs financiers doivent être non négatifs.
Contraintes d’unicité
Assurez l’unicité des données là où cela est requis. Par exemple, une adresse e-mail doit être unique dans l’ensemble du système, ou au sein d’une organisation spécifique, selon le modèle d’utilisateur. Une contrainte d’unicité composite peut garantir qu’un utilisateur n’est affecté qu’une seule fois à un projet spécifique (empêchant les affectations en double).
🚀 Performances et stratégie d’indexation
Un schéma bien conçu est inutile si les requêtes sont lentes. L’indexation est le mécanisme qui permet à la base de données de trouver rapidement les données. Toutefois, les index ont un coût en termes de performance des écritures et d’espace de stockage.
Identification des modèles de requêtes
Avant de créer des index, analysez les opérations de lecture les plus fréquentes. Dans notre étude de cas, les requêtes typiques incluent :
- Trouver toutes les tâches attribuées à un utilisateur spécifique.
- Trouver tous les projets au sein d’une organisation.
- Récupérer les journaux d’audit pour un ID d’entité spécifique.
Placement des index
Les clés étrangères sont les candidats les plus courants pour l’indexation. Si une requête filtre fréquemment par organization_id, un index sur cette colonne est obligatoire. Sans celui-ci, la base de données effectue un balayage complet de la table, ce qui se dégrade rapidement avec la croissance des données.
Les index composés sont utiles pour les requêtes qui filtrent sur plusieurs colonnes. Par exemple, si le système recherche fréquemment des tâches par project_id ET statut, un index composite sur (project_id, statut) est plus efficace qu’index séparés.
Index partiels
Dans les scénarios où seul un sous-ensemble de données est fréquemment interrogé, les index partiels économisent de l’espace. Par exemple, si le système ne requête que des actif tâches, un index qui ne comprend que les lignes où statut = 'Actif' peut être considérablement plus petit et plus rapide à parcourir qu’un index sur toute la table.
🛠️ Maintenance et évolution du schéma
Les exigences logicielles évoluent. Le schéma de base de données n’est pas une exception. Passer de la version A à la version B nécessite une planification soigneuse pour éviter les temps d’arrêt et la perte de données. Ce processus est souvent géré à l’aide de scripts de migration.
Ajout de colonnes
L’ajout d’une nouvelle colonne est généralement sans risque. Si la colonne accepte les valeurs NULL, les lignes existantes ne sont pas affectées. Si la colonne nécessite une valeur par défaut, assurez-vous que cette valeur par défaut s’applique à toutes les données existantes afin d’éviter des violations de contraintes.
Suppression de colonnes
Supprimer une colonne est risqué. Il est préférable de marquer d’abord la colonne comme obsolète. Cela permet aux développeurs de supprimer les références à la colonne dans le code de l’application avant de la supprimer physiquement de la base de données. Cette approche en deux phases évite les erreurs d’application pendant la fenêtre de déploiement.
Renommage de colonnes
Le renommage de colonnes est rarement pris en charge dans les anciennes versions de base de données sans solutions complexes. Il est souvent préférable d’ajouter une nouvelle colonne avec le nom souhaité, de migrer les données, puis de supprimer l’ancienne colonne. Cela garantit que le schéma reste compatible avec les versions antérieures pendant la transition.
🚧 Pièges courants dans la conception des modèles entité-relation
Même les architectes expérimentés commettent des erreurs. Comprendre les pièges courants aide à les éviter pendant la phase de conception.
- Sur-normalisation : Diviser les données en trop nombreuses petites tables rend les requêtes complexes et lentes. Équilibrez la normalisation avec les besoins de performance des requêtes.
- Sous-normalisation : Stocker les mêmes données à plusieurs endroits (par exemple, répéter les noms d’utilisateurs dans chaque journal de tâche) entraîne des anomalies de mise à jour. Si un utilisateur change son nom, vous devez mettre à jour chaque entrée du journal.
- Dépendances circulaires : Créer des relations de clés étrangères circulaires peut entraîner des blocages pendant l’insertion ou la suppression. Assurez-vous que le graphe de dépendance est un graphe acyclique orienté (DAG).
- Ignorer les suppressions douces : Supprimer définitivement les enregistrements supprime l’historique. Mettez en place une colonne horodatée
supprimé_lepour conserver les enregistrements visibles pour les audits tout en les cachant des vues standard. - Types de données implicites : Utiliser des types génériques comme
VARCHAR(255)pour tout cela gaspille de l’espace. UtilisezENTIERpour les identifiants,BOOLEANpour les drapeaux, et des contraintes de longueur spécifiques pour les chaînes de caractères lorsque cela est pertinent.
✅ Meilleures pratiques pour les modèles ER de production
Pour assurer la pérennité et la santé du système, respectez ces directives :
- Documentez les relations : Le modèle ER est en lui-même une documentation. Assurez-vous qu’il est mis à jour en accord avec le schéma réel. Des outils automatisés peuvent générer des diagrammes à partir de la base de données pour vérifier leur exactitude.
- Standardisez les conventions de nommage : Utilisez
snake_casepour les tables et les colonnes. Précisez les clés étrangères avec le nom de la relation (par exemple,organization_idau lieu de simplementorg_id) pour plus de clarté. - Utilisez les UUID au lieu des auto-incréments : Pour les systèmes distribués, les UUID évitent les conflits lors de la fusion de bases de données. Pour les systèmes à instance unique, les entiers auto-incrémentés sont plus compacts et plus rapides.
- Prévoyez la croissance : Concevez en tenant compte du partitionnement. Si une table est censée atteindre des milliards de lignes, envisagez comment elle sera divisée entre des shards ou des partitions en fonction de la
organization_id. - Revoyez les modèles d’accès : Revoyez régulièrement les journaux des requêtes lentes pour identifier les index manquants ou les jointures inefficaces.
🔄 Le cycle de vie d’un schéma
Un modèle ER n’est pas un document statique. Il évolue avec le produit. Le cycle de vie suit généralement ces étapes :
- Phase de conception : Rédaction du modèle initial basé sur les exigences.
- Phase d’implémentation : Création de scripts de migration pour construire le schéma.
- Phase de validation : Exécution de tests de charge pour vérifier les hypothèses de performance.
- Phase d’itération : Ajout de nouveaux champs ou relations au fur et à mesure de l’ajout de fonctionnalités.
- Phase d’optimisation : Affinement des index et des contraintes basés sur les données de production.
Pendant la phase d’optimisation, vous pourriez découvrir que les hypothèses initiales sur la cardinalité étaient erronées. Par exemple, vous pourriez constater qu’une Une-to-Plusieurs relation était en réalité une Plusieurs-to-Plusieurs en pratique, ce qui nécessite un changement de schéma vers une table de jonction. Cela met en évidence l’importance de la flexibilité dans la conception.
🛡️ Considérations de sécurité dans la conception du schéma
La sécurité des données est étroitement liée à la conception du schéma. Les politiques de sécurité au niveau des lignes (RLS) dépendent souvent de la structure du MCD pour fonctionner correctement. Si le id_organisation n’est pas correctement indexé et appliqué, un utilisateur provenant de l’organisation A pourrait accidentellement interroger les données de l’organisation B.
En outre, les données sensibles doivent être séparées. Si le système gère des informations de paiement, ces données devraient idéalement résider dans un schéma ou une table distincte avec des contrôles d’accès plus stricts, plutôt que d’être mélangées aux métadonnées utilisateur générales. Cela limite le rayon d’effet en cas de violation.
📝 Résumé des décisions de conception
Le tableau suivant résume les principales décisions prises dans cette étude de cas ainsi que les raisons qui les ont motivées.
| Décision | Option A | Option B (choisie) | Raisonnement |
|---|---|---|---|
| Multi-locataire | Bases de données séparées | Base de données partagée, schéma partagé | Réduction de la charge opérationnelle ; gestion plus facile des analyses translocataires. |
| Suppression des organisations | Suppression définitive | Suppression douce | Préserve les journaux d’audit historiques et empêche la perte de données pour respecter les exigences réglementaires. |
| Affectations de tâches | Colonne unique | Table de jonction | Permet plusieurs assignataires et suit les rôles spécifiques par affectation. |
| Clés primaires | Auto-incrémentation | UUID | Supporte une architecture distribuée future et facilite la fusion des données. |
Construire un backend de production exige plus que la simple rédaction de code. Il exige une compréhension approfondie du flux des données et de leur structure. Un MCD est la carte qui guide ce parcours. En suivant ces principes, vous assurez que le système reste stable, sécurisé et évolutif au fur et à mesure de la croissance de l’entreprise.
Souvenez-vous, l’objectif n’est pas de créer le diagramme le plus complexe possible, mais celui qui répond le mieux aux besoins de l’application tout en minimisant la dette technique. Une revue et une adaptation continues sont essentielles pour maintenir un écosystème de données sain.