


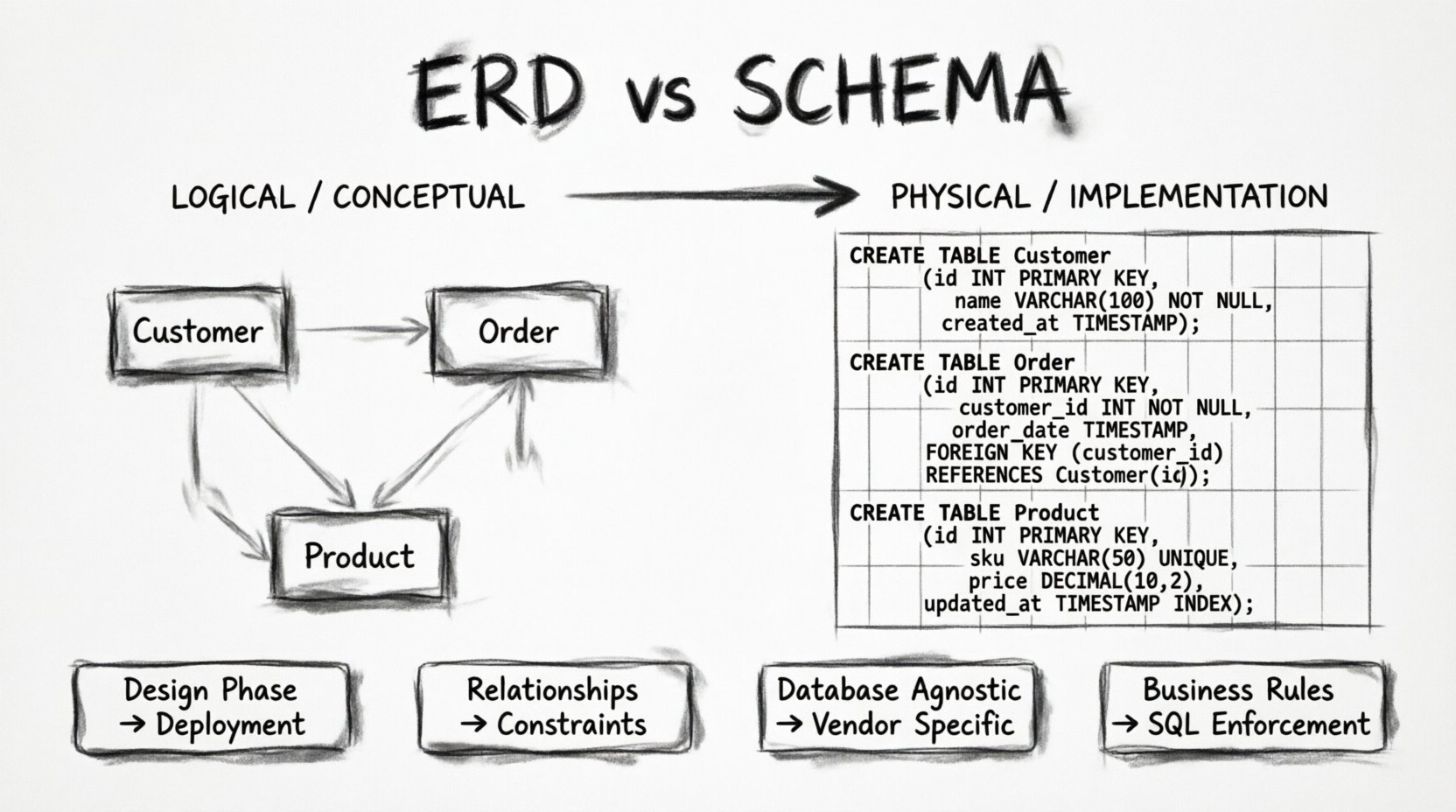
La conception des bases de données est le pilier de toute application logicielle robuste. Pourtant, même les ingénieurs expérimentés hésitent parfois à expliquer la distinction entre les plans visuels et la mise en œuvre physique. La confusion réside généralement entre le diagramme Entité-Relation (ERD) et le schéma de base de données. Bien que ces termes soient souvent utilisés de façon interchangeable dans les conversations informelles, ils représentent des niveaux distincts du processus d’architecture des données. Comprendre cette nuance n’est pas seulement une question académique ; elle détermine la manière dont les données circulent, comment les contraintes sont appliquées, et comment le système évolue au fil du temps.
Dans ce guide, nous analyserons les constructions théoriques de la modélisation des données face aux réalités pratiques des systèmes de gestion de bases de données. Nous explorerons la manière dont les concepts abstraits se transforment en structures concrètes, les implications de cette transformation, et pourquoi maintenir une séparation mentale claire entre les deux est essentielle pour la maintenabilité à long terme. Que vous conceviez un nouveau système ou que vous refactoriez un système existant, la clarté ici évite les dettes techniques coûteuses.
Qu’est-ce qu’un ERD exactement ? 📐
Le diagramme Entité-Relation est une représentation conceptuelle ou logique des données. Il sert de pont de communication entre les parties prenantes métier, les analystes et les développeurs. Son objectif principal est de visualiser la manière dont les éléments de données sont liés les uns aux autres, sans s’attarder aux détails spécifiques d’un moteur de base de données particulier.
Au cœur de tout ERD, on retrouve trois composants fondamentaux :
- Entités : Elles représentent des objets ou des concepts du monde réel. Dans un système de vente au détail, une entité pourrait être Client, Produit, ou Commande. Les entités sont les noms de votre univers de données.
- Attributs : Ce sont les propriétés ou caractéristiques qui décrivent une entité. Pour un Client, les attributs pourraient inclure Prénom, Adresse e-mail, ou Date d’inscription. Les attributs définissent les données que nous devons stocker concernant l’entité.
- Relations : Cela définit la manière dont les entités interagissent. Un client peut-il passer de nombreuses commandes ? Un produit peut-il appartenir à plusieurs catégories ? Les relations sont les verbes qui relient les noms.
La beauté d’un ERD réside dans son abstraction. Il ne se soucie pas que les données vivent finalement dans PostgreSQL, MySQL ou un magasin de documents NoSQL. Il se préoccupe de l’intégrité des informations et du flux logique. Les styles de notation varient, le style Crow’s Foot étant une norme courante pour représenter la cardinalité (un-à-un, un-à-plusieurs, plusieurs-à-plusieurs). Ce langage visuel permet aux équipes de valider la logique du modèle de données avant qu’une seule ligne de code ne soit écrite.
Lors de la création d’un ERD, l’accent est mis sur la normalisation. Cela consiste à organiser les données afin de réduire la redondance et d’améliorer l’intégrité des données. Nous examinons comment décomposer de grandes tables en tables plus petites et interconnectées, afin de garantir qu’une mise à jour d’une information à un endroit se répercute partout où cela est pertinent. L’ERD est la carte du territoire ; elle montre les routes et les repères, mais pas le matériau exact du revêtement.
Définir le schéma de base de données 🏗️
Si l’ERD est la carte, le schéma est le territoire lui-même. Le schéma de base de données est la structure physique de la base de données. Il s’agit de l’ensemble concret de définitions qui indique au système de gestion de base de données (SGBD) exactement comment stocker les données. Alors que l’ERD parle en concepts, le schéma parle en types de données, contraintes et moteurs de stockage.
Un schéma définit les spécificités techniques suivantes :
- Tables : L’entité ERD devient une table physique. Le schéma spécifie le nom de la table, qui doit souvent respecter des conventions de nommage strictes (par exemple, snake_case).
- Types de données : Un attribut tel que Âge devient un
INTouSMALLINT. Un Email devient unVARCHARavec une limite de longueur spécifique. Un Timestamp devientTIMESTAMP AVEC ZONE HORAIRE. Ces choix ont une incidence sur l’espace de stockage et les performances des requêtes. - Contraintes : C’est ici que la logique de l’ERD est appliquée. Les clés primaires (PK) garantissent l’unicité. Les clés étrangères (FK) assurent l’intégrité référentielle entre les tables.
NOT NULLLes contraintes garantissent que les champs obligatoires sont remplis. Les contraintes uniques empêchent les entrées en double. - Index : Bien qu’ils soient souvent omis dans les ERD de haut niveau, le schéma détermine où les index sont créés. Les index accélèrent les opérations de lecture mais ralentissent les écritures. Le schéma dicte l’optimisation physique de la base de données.
Le schéma est également responsable de la sécurité et du contrôle d’accès. Il définit qui peut lire ou écrire dans des tables spécifiques. Il gère les transactions, en garantissant que les modifications des données sont atomiques. Lorsqu’un développeur écrit une instruction CREATE TABLE , ils définissent le schéma. Il s’agit du niveau d’implémentation avec lequel le code de l’application interagit directement.
Différences clés en un coup d’œil 📊
Pour clarifier la distinction, il est utile de comparer les différences côte à côte. L’ERD est abstrait et orienté conception, tandis que le schéma est concret et orienté implémentation.
| Fonctionnalité | MCD (Diagramme Entité-Relation) | Schéma de base de données |
|---|---|---|
| Nature | Modèle logique / conceptuel | Modèle physique |
| Focus | Relations et flux de données | Stockage et application |
| Notation | Boîtes, lignes, symboles en forme de bec de corbeau | Instructions SQL, scripts DDL |
| Dépendance | Indépendant de la base de données | Spécifique à la base de données (fournisseur) |
| Contraintes | Implicites (règles métiers) | Explicites (PK, FK, Check) |
| Étape | Phase de conception | Phase de développement / déploiement |
Ce tableau met en évidence que, bien qu’ils soient liés, ils fonctionnent à des étapes différentes du cycle de vie du logiciel. Confondre les deux conduit souvent les développeurs à imposer des contraintes physiques à un modèle logique avant qu’il ne soit pleinement validé.
Le processus de traduction : du schéma au code 🔄
Le passage du MCD au schéma n’est pas toujours une correspondance directe 1:1. C’est au niveau de cette couche de traduction que de nombreux projets rencontrent des difficultés. Le modèle logique suppose des conditions idéales, mais le modèle physique doit faire face aux contraintes de performance, aux systèmes hérités et aux fonctionnalités spécifiques du moteur.
Normalisation vs. Performance
Un MCD est généralement normalisé jusqu’à la Troisième Forme Normale (3FN). Cela minimise la duplication des données. Toutefois, lors de la traduction vers un schéma pour une application à fort trafic, les développeurs dénormalisent souvent. Cela signifie dupliquer intentionnellement des données afin de réduire le nombre de jointures nécessaires lors d’une requête. Par exemple, stocker le Nom du client directement dans la table Commande table, même si cela viole les règles strictes de normalisation, peut considérablement accélérer les requêtes de reporting. Le MCD pourrait montrer une relation, mais le schéma pourrait stocker les données de manière redondante pour gagner en vitesse.
Spécificités des types de données
Un MCD indique simplement qu’un champ est un Date. Le schéma doit choisir entre DATE, DATETIME, ou TIMESTAMP. Il doit décider des jeux de caractères (UTF8, ASCII) et des règles de comparaison. Ces décisions influencent la manière dont l’application gère l’internationalisation et le tri. Un MCD générique ne peut pas capturer ces nuances.
Gestion des relations Many-to-Many
Dans un MCD, une relation Many-to-Many est représentée par une ligne avec deux crocs. Dans le schéma physique, cela ne peut pas exister directement. Il doit être résolu en deux relations One-to-Many via une table de jonction (ou table pont). Le schéma doit définir la clé primaire de cette table de jonction, qui peut être une clé composite ou une clé artificielle (UUID). Ce changement structurel est invisible dans le diagramme de haut niveau, mais il est crucial dans la structure de la base de données.
Pourquoi la distinction est importante pour les développeurs 🛠️
Comprendre l’écart entre ces deux concepts n’est pas seulement une question théorique ; cela a un impact sur le travail quotidien. Lorsqu’un bug survient dans l’intégrité des données, savoir si le problème provient de la conception logique ou de la mise en œuvre physique est la première étape vers sa résolution.
Débogage de l’intégrité des données
Si vous rencontrez une situation où les données sont dupliquées de manière inattendue, vous devez vous demander : le MCD est-il défectueux, ou une contrainte du schéma manque-t-elle ? Un Foreign Key manquant dans le schéma permet des enregistrements orphelins que la logique du MCD considérait comme impossibles. À l’inverse, si le MCD est trop rigide et ne tient pas compte des suppressions douces, le schéma pourrait imposer des suppressions définitives qui rompent la logique métier. Séparer les préoccupations permet de localiser la source de l’erreur.
Contrôle de version et collaboration
Lors de la gestion d’une base de données, le contrôle de version est essentiel. Toutefois, les MCD et les schémas évoluent différemment. Le MCD change lorsque les exigences métiers évoluent. Le schéma change lorsque la base de données nécessite une optimisation ou lorsqu’on applique des migrations. Les maintenir synchronisés est un défi. Si le schéma change sans mettre à jour le MCD, la documentation devient obsolète. Si le MCD change sans script de migration, la base de données reste en désaccord avec la conception.
Intégration des nouveaux membres d’équipe
Les nouveaux développeurs ont souvent du mal à comprendre la structure de la base de données. Le montrer un MCD leur fournit le contexte de la manière dont le système fonctionne de façon conceptuelle. Le montrer le schéma leur fournit le contexte de la manière dont le système fonctionne de façon technique. Une intégration efficace nécessite les deux. Le MCD répond à « Qu’est-ce que cela signifie ? » et le schéma répond à « Comment puis-je y accéder ? ».
Péchés courants dans la modélisation des données 🚧
Malgré les définitions claires, de nombreuses équipes tombent dans des pièges en traitant le MCD et le schéma comme identiques.
- Sauter le MCD :Passer directement à l’écriture de scripts SQL de schéma conduit souvent à un endettement structurel. Sans modèle visuel, les relations sont souvent oubliées ou implémentées de manière incohérente.
- Ignorer les contraintes :Se fier uniquement au code de l’application pour appliquer des règles (comme des emails uniques) plutôt que des contraintes de base de données (index UNIQUE) est risqué. Le schéma doit être la dernière ligne de défense pour l’intégrité des données.
- Sur-conception : Créer un MCD trop détaillé avec tous les attributs possibles avant que les exigences ne soient claires. Cela conduit à un schéma difficile à migrer ultérieurement.
- Désynchronisation des outils : Utiliser un outil de conception qui ne prend pas en charge la génération de code, ou utiliser un outil de base de données qui ne prend pas en charge l’ingénierie inverse. Cela crée un écart manuel où les modifications sont apportées dans un endroit mais pas dans l’autre.
- Supposer l’équivalence : Croire qu’un MCD parfait garantit une base de données parfaite. Le schéma est soumis à des limitations matérielles, à des modèles de requêtes et à des problèmes de concurrence que le MCD ne peut pas anticiper.
Maintenir la synchronisation au fil du temps 🔄
À mesure qu’une application grandit, la base de données évolue. Des fonctionnalités sont ajoutées, et d’autres sont abandonnées. Maintenir le lien entre le MCD et le schéma devient de plus en plus difficile au fil du temps. Cela est souvent appelédérive du schéma.
Pour y remédier, les équipes doivent adopter un flux de travail strict :
- Concevoir d’abord : Mettre toujours à jour le MCD avant d’écrire les scripts de migration.
- Automatiser la génération : Utiliser des outils capables de générer du SQL DDL à partir du MCD. Cela garantit que le schéma correspond à la conception.
- Ingénierie inverse : Exécuter périodiquement des outils d’ingénierie inverse sur la base de données en production pour mettre à jour le MCD. Cela permet de détecter les modifications apportées par des requêtes SQL directes qui contournent le processus de conception.
- Documentation : Veiller à ce que le MCD soit stocké dans le même dépôt que les scripts de migration du schéma. Cela crée une source unique de vérité.
Cette discipline empêche la base de données de devenir une boîte noire. Lorsque le MCD et le schéma sont synchronisés, le système reste transparent et gérable.
Impact sur les performances des requêtes et l’optimisation ⚡
Le schéma dicte les performances plus que le MCD. Alors que le MCD montre les relations, le schéma détermine la manière dont le moteur de base de données accède aux données. Un MCD pourrait montrer une jointure logique entreUtilisateurs et Articles. Le schéma détermine si un index existe sur le champID_Utilisateur dans la tableArticles table.
Sans indexage approprié dans le schéma, une requête simple peut déclencher un balayage complet de la table. Il s’agit d’une contrainte physique. Le MCD ne peut pas vous montrer le plan d’exécution. Les développeurs doivent consulter le schéma pour comprendre pourquoi une requête est lente. Ils doivent analyser les index, la stratégie de partitionnement et les types de données.
En outre, le schéma gère les mécanismes de verrouillage. Si plusieurs utilisateurs mettent à jour le même enregistrement, le niveau d’isolement et la stratégie de verrouillage du schéma déterminent s’ils se bloquent mutuellement. Le MCD reste muet sur la concurrence. Il s’agit d’une distinction cruciale pour les systèmes à fort volume.
Comblant le fossé avec les meilleures pratiques 🏆
Pour garantir que les deux modèles remplissent efficacement leur rôle, envisagez d’adopter ces normes :
- Utilisez des conventions de nommage standard : Assurez-vous que les noms de table dans le schéma correspondent aux noms d’entité dans le MCD. La cohérence réduit la charge cognitive.
- Documentez les contraintes explicitement : Dans le MCD, annotez les relations avec la cardinalité. Dans le schéma, annotez les colonnes avec leurs contraintes. Rendez les règles visibles dans les deux endroits.
- Revoyez régulièrement : Programmez des revues trimestrielles du MCD par rapport au schéma de production. Recherchez les écarts et les anomalies.
- Séparez les préoccupations : Traitez le MCD comme un artefact métier et le schéma comme un artefact technique. N’incorporez pas la logique métier dans les définitions du schéma physique.
- Prévoyez la migration : Lorsque le MCD change, le schéma doit être modifié via un script de migration. Ne modifiez jamais directement le schéma en production sans script versionné.
L’élément humain de la modélisation des données 👥
En fin de compte, ces modèles sont conçus pour les humains, et non seulement pour les machines. Le MCD est destiné à la communication. Il permet à un chef de produit de comprendre la structure des données sans connaître SQL. Le schéma est destiné à la machine. Il permet à l’application de récupérer les données de manière efficace.
Lorsque les développeurs comprennent cette distinction entre humain et machine, ils peuvent concevoir de meilleurs systèmes. Ils savent quand simplifier le MCD pour les parties prenantes et quand détailler le schéma pour le moteur de base de données. Cette dualité est l’essence de l’architecture des bases de données.
En respectant la frontière entre le diagramme logique et l’implémentation physique, les équipes évitent les pièges courants de la corruption des données et des goulets d’étranglement de performance. Le MCD fournit la vision ; le schéma fournit la réalité. Les deux sont nécessaires à un système réussi.
Réflexions finales sur l’architecture des données 🧠
La distinction entre un diagramme Entité-Relation et un schéma de base de données est un pilier fondamental du génie logiciel. Elle représente la transition de la pensée à l’action, de l’idée à l’exécution. Alors que le MCD capte les relations et la logique qui pilotent l’entreprise, le schéma capte les contraintes et les structures qui pilotent l’application.
Maîtriser la relation entre ces deux modèles ne consiste pas à mémoriser des définitions. C’est comprendre le cycle de vie des données. C’est savoir qu’un changement dans le diagramme exige un changement dans le code, et qu’un changement dans le code doit être reflété dans le diagramme. Ce cycle garantit que le système reste cohérent, fiable et évolutif.
Au fur et à mesure que vous avancez dans votre parcours de développement, gardez ces deux modèles distincts. Utilisez le MCD pour planifier et communiquer. Utilisez le schéma pour construire et imposer. Lorsque vous les alignez, vous construisez des systèmes capables de résister à l’épreuve du temps et des changements.
Souvenez-vous, l’objectif n’est pas seulement de stocker des données, mais de les stocker de manière cohérente. Cette cohérence provient de la clarté logique du MCD et de la rigueur structurelle du schéma. Ensemble, ils forment la fondation de votre architecture des données.