











データベース正規化はシステム設計における重要なプロセスであり、データが効率的に整理され、重複を減らし、整合性を高めるように保証します。従来、原始的な概念から第三正規形(3NF)へスキーマを移行するには、大きな手作業と深い理論的知識が必要でした。しかし、Visual Paradigm AI DB Modelerは正規化を自動化されたワークフローに統合することで、このアプローチを革命的に変革しました。このガイドでは、このツールを活用して最適化されたデータベース構造をスムーズに達成する方法を探ります。
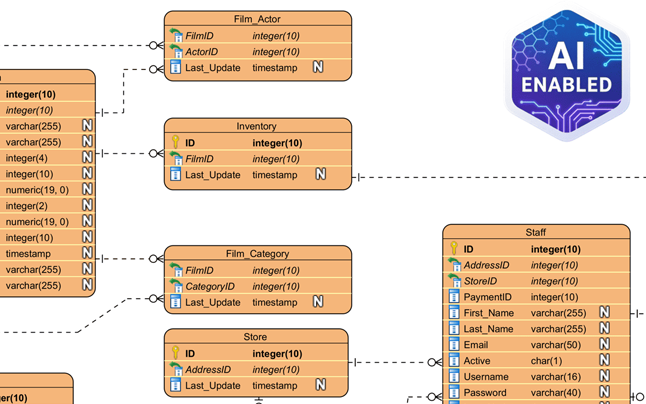
主要な概念
AI DB Modelerを効果的に使用するには、ツールの論理を支える基盤となる定義を理解することが不可欠です。AIは、アーキテクチャ成熟度の3つの主要な段階に注目しています。
1. 第一正規形(1NF)
正規化の基盤となる段階です。1NFは、テーブル構造がフラットで原子的であることを保証します。この状態では、各テーブルセルには単一の値が含まれるリストやデータの集合ではなく、単一の値です。さらに、テーブル内のすべてのレコードが一意であることを義務付け、最も基本的なレベルで重複行を排除します。
2. 第二正規形(2NF)
1NFの厳格なルールに基づき、第二正規形は列間の関係に注目します。これには、すべての非キー属性が主キーに対して完全に関数的かつ依存していることが求められます。この段階では、部分的依存を排除します。これは、複合主キーを持つテーブルで、ある列がキーの一部にのみ依存する場合に頻繁に発生します。
3. 第三正規形(3NF)
これは、大多数のプロダクショングレードのリレーショナルデータベースの標準的な目標です。3NFは、すべての属性が主キーにのみ依存していることを確実にします。特に、推移的依存(列Aが列Bに依存し、列Bが主キーに依存する状態)を特定して排除します。3NFを達成することで、高いアーキテクチャ成熟度が得られ、データの重複を最小限に抑え、更新異常を防ぐことができます。
ガイドライン:自動化された正規化ワークフロー
Visual Paradigm AI DB Modelerは、正規化を特に自動化された7段階ワークフローのステップ5に組み込んでいます。このプロセスをスムーズに進めるために、これらのガイドラインに従い、AIの提案の利点を最大限に活かしてください。
ステップ1:AIワークフローの開始
まず、初期のプロジェクト要件や原始的なスキーマのアイデアをAI DB Modelerに入力してください。ツールはエンティティ発見と関係マッピング初期のステップを進んで、最適化フェーズに到達するまで進んでください。
ステップ2:1NF変換の分析
ワークフローがステップ5に達すると、AIは実質的に「データベースアーキテクト」の役割を引き継ぎます。まず、あなたのエンティティが1NF基準を満たしているかを確認します。AIが複雑なフィールドを原子的な値に分解する様子に注目してください。たとえば、「住所」を一つのフィールドとして持っていた場合、AIはそれを「通り名」「市区町村」「郵便番号」に分割することを提案するかもしれません。これにより原子性が確保されます。
ステップ3:2NFおよび3NFの最適化の確認
このツールはルールを繰り返し適用して1NFから3NFへと段階的に進みます。この段階では、AIが依存関係を正しく処理するためにテーブルを再構成する様子を観察できます:
- 完全な主キーに依存しない非キー属性を特定し、それらを別々のテーブルに移動します(2NF)。
- 他の非キー属性に依存する属性を検出し、それらを分離して推移的依存関係を排除します(3NF)。
ステップ4:教育的根拠の確認
Visual Paradigm AI DB Modelerの最も強力な特徴の一つはその透明性です。スキーマを変更する際、AIは教育的根拠を提供します。このテキストを飛ばさないでください。AIはすべての構造的変更の背後にある理由を説明し、特定の最適化がデータの重複を排除する、またはデータの整合性を確保することについて詳しく説明します。これらの根拠を読むことは、AIがデータのビジネス文脈を理解していることを確認するために不可欠です。
ステップ5:SQLプレイグラウンドで検証
AIがスキーマが3NFに到達したと主張した後は、すぐにSQLをエクスポートしないでください。組み込みのインタラクティブSQLプレイグラウンドを使用してください。このツールは新しいスキーマに現実的なサンプルデータを投入します。
テストクエリを実行してパフォーマンスと論理を検証してください。このステップにより、正規化プロセスが特定の使用ケースにおいてデータの取得を過度に複雑にしないことを確認できます。その後、デプロイ.
ヒントとテクニック
これらのベストプラクティスAI DB Modelerを使用する際には。
- 構文よりも文脈を確認する:AIは正規化ルールの適用において優れていますが、特定のビジネスドメインの特徴を把握しているとは限りません。常に「教育的根拠」をビジネスロジックと照合してください。AIがアプリケーションの読み取りパフォーマンスに悪影響を及ぼすような方法でテーブルを分割している場合、わずかに非正規化を行う必要があるかもしれません。
- サンプルデータを使用する:SQLプレイグラウンドで生成されたサンプルデータは単なる飾りではありません。null値が新しく正規化された外部キーでどのように処理されるかといったエッジケースを確認するために使用してください。
- プロンプトを繰り返し調整する:ステップ1~4での初期スキーマ生成が漠然としている場合、ステップ5での正規化の効果は低下します。AIが堅固な概念モデルからスタートできるように、初期のプロンプトは具体的に記述してください。
-
DBModeler AIによるスキーマ設計の包括的レビュー:DBModeler AIが自動化と知能によってデータベーススキーマ設計をどのように変革するかを詳細に分析したものです。
-
DBModeler AI:インテリジェントなデータベースモデリングツール:Visual ParadigmでAI駆動の自動データベースモデリングおよびスキーマ生成ツールにアクセスできます。
-
DBModeler AI:7ステップのワークフローを持つAI駆動のデータベース設計ツール。ドメインモデル、ER図、正規化されたスキーマ、完全な設計レポートを生成できます。ブラウザ上でライブのデータベースプレイグラウンドを起動し、即座にクエリをテストできます。
-
AIテキスト分析 – テキストを自動的に視覚的モデルに変換:AIを活用してテキストドキュメントを分析し、UML、BPMN、ERDなどの図を自動生成することで、モデリングとドキュメント作成を迅速化します。
-
Visual Paradigm ERDツール – オンラインでエンティティ関係図を作成:直感的なドラッグアンドドロップ機能を活用して、ユーザーが簡単にデータベーススキーマを設計・可視化できる強力なウェブベースのERDツールです。
-
ERDツールによるデータベース設計 – Visual Paradigmガイド:データモデリングとスキーマ設計のベストプラクティスを活用して、堅牢でスケーラブルなデータベースを設計するための包括的なガイドです。
-
エンティティ関係図(ERD)とは何か? – Visual Paradigmガイド:ERDの詳細な説明、その構成要素、およびデータベース設計とデータモデリングにおける重要性について。
-
無料ERDツール – Visual Paradigmでオンラインでデータベースを設計:インストールやサブスクリプションなしで、無料でオンラインでプロフェッショナルなエンティティ関係図を作成できるERDツールにアクセスできます。
-
Visual Paradigm ERDでエンティティを描く方法:Visual ParadigmのERDツールでエンティティを作成・カスタマイズするためのステップバイステップのユーザーガイド。正確なデータベースモデリングに役立ちます。
-
ERDでリレーショナルデータベースをモデリングする方法 – Visual Paradigmチュートリアル:コンセプトから実装まで、ERDを使ってリレーショナルデータベースをモデリングする方法を実践的に紹介するチュートリアル。