











Każda aplikacja zaczyna się od pomysłu. Ten pomysł wymaga przechowywania danych, a przechowywanie danych wymaga projektu. Ten projekt to Diagram Związków Encji (ERD). Jest to podstawowy dokument, który określa, jak system rozumie informacje. Jednak projekt małego szopu nie nadaje się do wieżowca. Podobnie schemat bazy danych stworzony dla prototypu często zawodzi pod ciężarem ruchu produkcyjnego i skomplikowanej logiki biznesowej.
Zrozumienie ewolucji ERD jest kluczowe dla liderów technicznych, administratorów baz danych i architektów oprogramowania. Dotyczy to zarządzania napięciem między elastycznością a integralnością. Gdy liczba użytkowników rośnie, zmieniają się wymagania dotyczące danych. Nie możesz po prostu utrzymywać początkowego modelu przez całe życie. Musisz go dostosować. Ten przewodnik omawia cykl życia modelu danych, od pierwszego wiersza kodu po architekturę o skali przedsiębiorstwa.
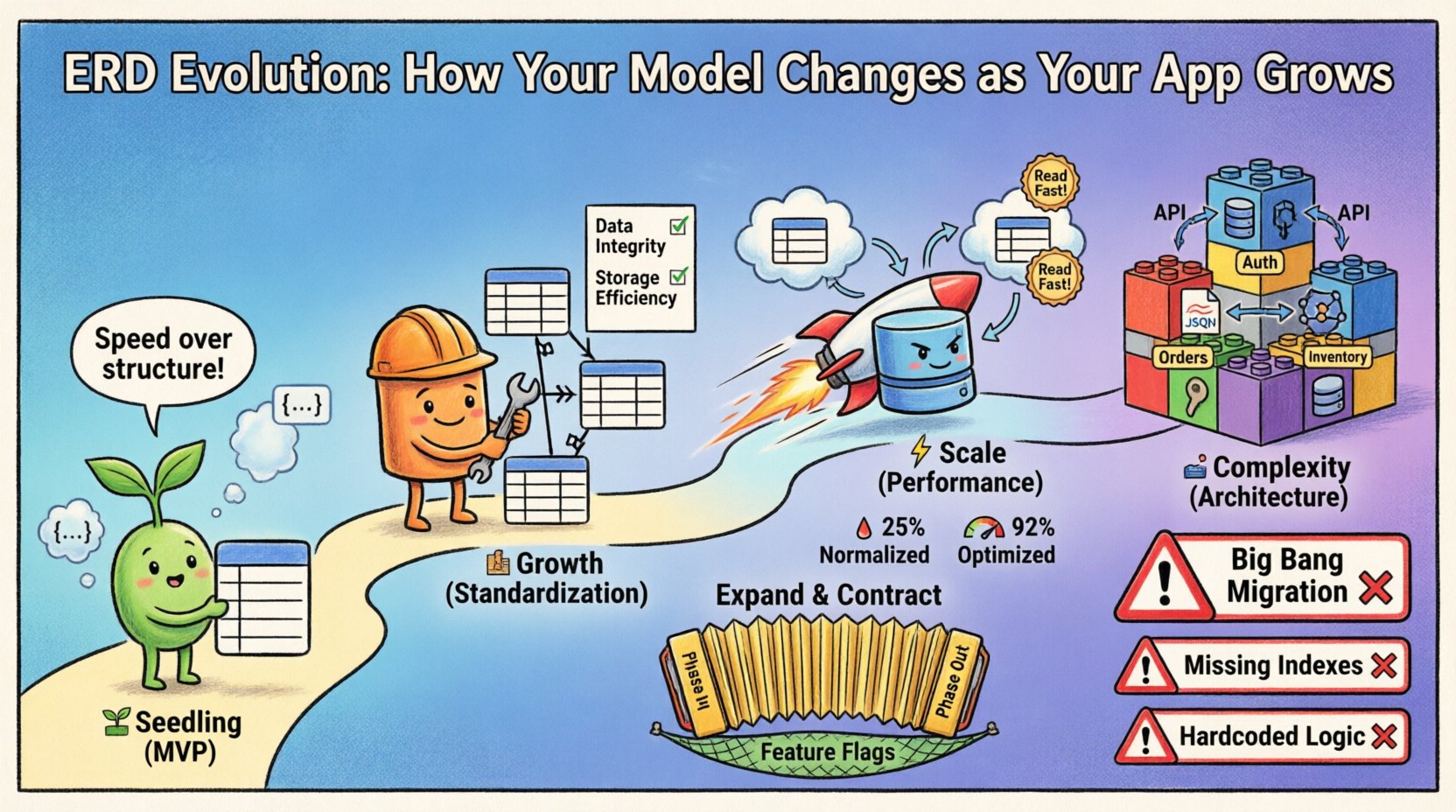
Faza 1: Etap młodego pączka (MVP) 🌱
Na początku priorytetem jest szybkość. Celem jest weryfikacja podstawowego założenia z minimalnym oporem. Na tym etapie ERD jest często płynny, odzwierciedlając potrzeby natychmiastowe, a nie długoterminowe przewidywania.
- Skupienie:Funkcjonalność nad strukturą.
- Struktura:Płaskie schematy są powszechne. Relacje często są zdekomponowane, aby zmniejszyć złożoność połączeń.
- Ograniczenia:Klucze obce mogą być luźne lub pominięte, aby umożliwić szybką iterację.
- Zmiany:Modyfikacje schematu odbywają się tygodniowo, czasem codziennie.
W tym etapie możesz zobaczyć encje, które są silnie powiązane. Na przykład tabela User może zawierać obiekt JSON z ustawieniami profilu zamiast osobnej tabeli Profile tabeli. To zmniejsza potrzebę łączenia, przyspieszając operacje odczytu dla pulpitu. Jednak to tworzy dług techniczny. Gdy aplikacja dojrzewa, zapytania do tej zagnieżdżonej danych stają się wolniejsze i trudniejsze do utrzymania.
Kluczowe cechy modeli wczesnych etapów
- Minimalne ograniczenia kluczy obcych.
- Elastyczne typy kolumn (np. używanie VARCHAR dla wszystkiego).
- Jeden egzemplarz bazy danych.
- Bezpośrednie mapowanie między obiektami aplikacji a tabelami bazy danych.
Faza 2: Etap wzrostu (standardyzacja) 🏗️
Gdy produkt zyskuje uznanie, pierwotna elastyczność staje się obciążeniem. Duplikacja danych prowadzi do niezgodności. Jeśli użytkownik aktualizuje swój adres e-mail w jednym miejscu, ale nie w drugim, system traci zaufanie. To etap, w którym priorytetem jest normalizacja.
Dlaczego teraz znormalizować?
- Integralność danych: Wzmacnianie integralności referencyjnej zapobiega powstawaniu zaniedbanych rekordów.
- Efektywność przechowywania: Usuwanie nadmiarowych danych oszczędza miejsce na dysku.
- Utrzymywalność:Aktualizacja pojedynczego rekordu w tabeli znormalizowanej aktualizuje go wszędzie logicznie.
- Przewidywalność zapytań:Standardowe struktury sprawiają, że pisanie zapytań jest mniej podatne na błędy.
W trakcie tej zmiany musisz przepisać ERD. Płaska tabela użytkowników może zostać podzielona naUżytkownicy i DaneUżytkownika. Wprowadza to relacje. Musisz określić, czy są to relacje jeden do jednego, jeden do wielu, czy wiele do wielu.
Lista kontrolna przejścia
- Zidentyfikuj wszystkie powtarzające się pola między tabelami.
- Zdefiniuj klucze podstawowe dla wszystkich encji.
- Zaimplementuj ograniczenia kluczy obcych, aby zapewnić relacje.
- Przejrzyj istniejące zapytania pod kątem wpływu nowych połączeń na wydajność.
- Zaplanuj kompatybilność wsteczną podczas migracji.
Faza 3: Etap skalowania (wydajność) ⚡
Gdy istnieją miliony rekordów, znormalizowana struktura może stać się węzłem zawieszenia. Połączenia są kosztowne obliczeniowo w skali. To właśnie w tym momencie model ponownie się rozwija, często odchylając się od ściśle znormalizowanej struktury w kierunku strategicznej denormalizacji dla poprawy wydajności.
Strategiczna denormalizacja
To nie jest cofnięcie do fazy MVP. To świadome decyzje. Zamiernie duplikujesz dane, aby uniknąć kosztownych połączeń na dużych tabelach.
- Obciążenia o ciężkim obciążeniu odczytu: Jeśli Twoja aplikacja głównie odczytuje dane, buforowanie danych w schemacie zmniejsza obciążenie bazy danych.
- Tabele raportowe: Dane wstępnie podsumowane dla pulpitu pomagają uniknąć obliczania sum w czasie rzeczywistym.
- Partycjonowanie: Podział tabel według daty lub regionu wymaga specjalnego projektowania schematu, aby umożliwić skuteczne zapytania.
Porównanie: Znormalizowane vs. Optymalizowane
| Funkcja | Znormalizowane (Faza 2) | Optymalizowane (Faza 3) |
|---|---|---|
| Integralność | Wysoka (wymuszona przez DB) | Zarządzane przez logikę aplikacji |
| Prędkość zapisu | Szybko | Wolniej (aktualizuje wiele tabel) |
| Prędkość odczytu | Wolniej (wymaga łączeń) | Szybko (jedno wyszukanie) |
| Przechowywanie | Efektywne | Mniej efektywne (nadmiarowość) |
Faza 4: Etap złożoności (architektura) 🏛️
Na poziomie przedsiębiorstwa pojedynczy model bazy danych często jest niewystarczający. System może zostać podzielony na mikroserwisy lub wykorzystać poliglotową persystencję. ERD już nie przedstawia pojedynczego diagramu fizycznego, lecz zbiór modeli, które komunikują się ze sobą.
Mikroserwisy i własność danych
W architekturze monolitycznej tabela Zamówienia jest współużywana przez usługi rozliczeniowe, wysyłkowe i powiadamiające. W systemie rozproszonym każda usługa posiada własne dane. Wymaga to zmiany podejścia do modelowania relacji.
- Spójność ostateczna: Nie możesz polegać na transakcjach ACID między usługami. ERD musi uwzględniać synchronizację stanu.
- Umowy interfejsu API: Relacje są często definiowane przez odpowiedzi interfejsu API, a nie kluczami obcymi.
- Synchronizacja danych: Potrzebne są narzędzia do utrzymania spójności danych między różnymi magazynami (np. SQL dla zamówień, NoSQL dla dzienników).
Poliglotowa persystencja
Różne dane wymagają różnych silników przechowywania. ERD ewoluuje, aby uwzględniać koncepcje nierełacyjne.
- Dane grafowe: Dla sieci społecznościowych lub silników rekomendacji model grafowy zastępuje tabele relacyjne.
- Magazyny dokumentów: Dla elastycznego treści, takich jak katalogi produktów, dokumenty JSON zastępują sztywne kolumny.
- Magazyny par klucz-wartość: W celu zarządzania sesjami i buforowania zamiast złożonych wierszy stosuje się proste pary klucz-wartość.
Techniczny przegląd: Poziomy normalizacji 🔬
Aby skutecznie rozwijać swój model, musisz zrozumieć zasady, które stosujesz lub łamiesz. Normalizacja to proces organizowania danych w celu zmniejszenia nadmiarowości.
Pierwsza postać normalna (1NF)
- Wartości atomowe: Każda kolumna zawiera tylko jedną wartość.
- Brak powtarzających się grup: Nie możesz mieć kolumn takich jak
kolor1,kolor2,kolor3. - Unikalne identyfikatory: Każdy wiersz musi być jednoznacznie identyfikowalny.
Druga postać normalna (2NF)
- Muszą znajdować się w 1NF.
- Wszystkie atrybuty niekluczowe muszą być całkowicie zależne od klucza głównego.
- Usuwa częściowe zależności (np. przenoszenie informacji o dostawcy do osobnej tabeli, jeśli zależy tylko od ID dostawcy, a nie od ID zamówienia).
Trzecia postać normalna (3NF)
- Muszą znajdować się w 2NF.
- Usuwane są zależności przechodnie.
- Kolumna nie może zależeć od innej kolumny niekluczowej (np.
Miastozależy odStan, a nie tylkoKod pocztowy). PrzenieśMiastoiStandoLokalizacjatabela.
Typowe pułapki w ewolucji modelu ERD ⚠️
Nawet doświadczone zespoły popełniają błędy podczas refaktoryzacji modeli. Rozpoznawanie tych wzorców pomaga uniknąć kosztownych przestojów.
1. Migracja typu „Big Bang”
Próba zmiany całego schematu w jednym wdrożeniu. To niesie wysokie ryzyko. Jeśli skrypt migracji nie powiedzie się, system będzie uszkodzony.
- Rozwiązanie: Używaj migracji inkrementalnych. Dodaj kolumny, wypełnij dane, zmień logikę, a następnie usuń stare kolumny.
2. Ignorowanie skutków indeksowania
Zmiana relacji zmienia wzorce zapytań. Nowa relacja klucza obcego może wymagać nowego indeksu, aby działać skutecznie.
- Rozwiązanie: Przeanalizuj dzienniki wolnych zapytań przed i po zmianach schematu.
- Rozwiązanie: Zaprojektuj tworzenie indeksów w godziny poza szczytem obciążenia.
3. Tworzenie stałe ograniczenia w logice aplikacji
Niektóre zespoły preferują weryfikację danych w kodzie zamiast w bazie danych. Może to prowadzić do uszkodzenia danych, jeśli wiele usług zapisuje do tej samej bazy.
- Rozwiązanie: Zachowaj ograniczenia na poziomie bazy danych (NOT NULL, ograniczenia CHECK), nawet jeśli aplikacja jest rozproszona.
Strategie migracji 🔄
Gdy musisz ewoluować model ERD, potrzebujesz strategii, która minimalizuje przestoje i utratę danych.
Wzorzec rozszerzania i zwężania
To złoty standard bezpiecznej ewolucji schematu.
- Dodaj: Dodaj nową kolumnę lub tabelę do schematu. Nie zmieniaj jeszcze istniejącej logiki.
- Zapisz: Zaktualizuj aplikację tak, aby zapisywała zarówno do starej, jak i do nowej struktury.
- Odczytaj: Zaktualizuj aplikację tak, aby odczytywała z nowej struktury.
- Wypełnij: Uruchom zadanie w tle, aby wypełnić nową strukturę danymi z poprzedniej wersji.
- Umowa: Po weryfikacji usuń stare kolumny i logikę.
Flagi funkcji
Użyj flag funkcji, aby przełączać się między starym a nowym schematem. Dzięki temu możesz natychmiast wrócić do poprzedniej wersji, jeśli pojawią się problemy, bez wdrażania skryptu cofnięcia zmian.
Dokumentacja i wersjonowanie 📝
ERD to nie jednorazowy produkt końcowy. Jest to dokument dynamiczny. W miarę ewolucji modelu dokumentacja musi się aktualizować.
Kontrola wersji dla schematów
- Traktuj pliki schematów (skrypty SQL) jak kod. Przechowuj je w systemie kontroli wersji.
- Używaj narzędzi migracji, aby śledzić zmiany w czasie.
- Oznacz wersje wydania wersjami schematu (np.
v1.2.0-schema).
Spójność wizualna
- Ujednolit zasady nazewnictwa (np. snake_case w porównaniu do camelCase).
- Upewnij się, że nazwy tabel odzwierciedlają dziedzinę (np.
klientzamiastt1). - Zachowaj komentarze w schemacie w celu zaprezentowania kontekstu logiki biznesowej.
Zabezpieczenie modelu na przyszłość 🚀
Nie możesz przewidzieć przyszłości, ale możesz zapewnić elastyczność. Choć nadmierna inżynieria jest zła, projektowanie z myślą o zmianach jest mądre.
Wzorce projektowe rozszerzalne
- EAV (Obiekt-Atrybut-Wartość): Użyteczne dla danych o dużej zmienności, choć kosztem wydajności zapytań.
- Kolumny JSON: Nowoczesne bazy danych obsługują typy JSON. Pozwala to przechowywać elastyczne atrybuty bez zmiany struktury tabeli.
- Systemy etykietowania: Użyj relacji wiele do wielu dla metadanych zamiast tworzyć stałe atrybuty.
Monitorowanie i audyt
- Śledź zmiany schematu. Kto zmienił co i kiedy?
- Monitoruj trendy wzrostu danych. Jeśli tabela rośnie o 50% miesięcznie, zaplanuj podział zanim spowolni.
- Skonfiguruj alerty dla naruszeń ograniczeń.
Wnioski dotyczące elastyczności 🔄
Ewolucja diagramu ER to odbicie dojrzałości aplikacji. Przechodzi od elastyczności do integralności, a następnie do wydajności. Każda faza niesie nowe wyzwania. Kluczem jest przewidywanie tych zmian i zarządzanie nimi świadomie.
Nie ma jednego „idealnego” modelu. Istnieje tylko model, który pasuje do Twoich obecnych ograniczeń i trajektorii rozwoju. Zrozumienie kompromisów między normalizacją, denormalizacją i wzorcami architektonicznymi pozwala zapewnić, że warstwa danych wspiera Twoją firmę przez lata.
- Zacznij prosto, ale planuj strukturę.
- Normalizuj dla integralności, denormalizuj dla szybkości.
- Dokumentuj każdą zmianę.
- Testuj migracje skrupulatnie.
Twoje dane to Twoja najcenniejsza资产. Traktuj model, który je przechowuje, z tą opieką, jakiej zasługuje.