








Projetar um modelo de dados robusto não é meramente um exercício acadêmico; é a base sobre a qual repousa a estabilidade da aplicação. Um Diagrama de Relacionamento de Entidades (ERD) serve como o projeto arquitetônico de como as informações são armazenadas, vinculadas e recuperadas em um ambiente de produção. Quando os sistemas escalam, o custo de uma má modelagem torna-se exponencial. Este guia examina uma implementação prática de um ERD em uma arquitetura backend complexa, com foco na integridade dos dados, escalabilidade e manutenibilidade.
Muitas vezes, os desenvolvedores focam na lógica da aplicação, tratando o banco de dados como uma preocupação secundária. No entanto, o esquema define os limites do que o sistema pode fazer de forma eficiente. Ao analisar um cenário do mundo real, podemos compreender as trade-offs envolvidas na normalização de dados, no tratamento de relacionamentos e na garantia da integridade referencial, sem depender de fornecedores específicos de software.
📋 O Cenário Empresarial
Considere uma plataforma de serviços multi-locatária projetada para gerenciar projetos colaborativos. O sistema exige uma isolamento rigoroso entre diferentes organizações clientes, ao mesmo tempo em que permite flexibilidade interna dentro dessas organizações. Os requisitos principais incluem:
- Multi-locatária:Os dados devem ser segregados por organização para garantir a segurança.
- Fluxos de Trabalho Complexos:As tarefas devem ser atribuídas, rastreadas e vinculadas a projetos específicos.
- Trilhas de Auditoria:Toda alteração significativa em um registro deve ser registrada para fins de conformidade.
- Escalabilidade:O esquema deve suportar milhões de registros sem degradar o desempenho das consultas.
O desafio está em traduzir essas regras de negócios em uma estrutura relacional que evite anomalias de dados. Um erro comum é criar estruturas excessivamente normalizadas que exigem joins excessivos, ou estruturas excessivamente denormalizadas que levam à redundância de dados e anomalias de atualização.
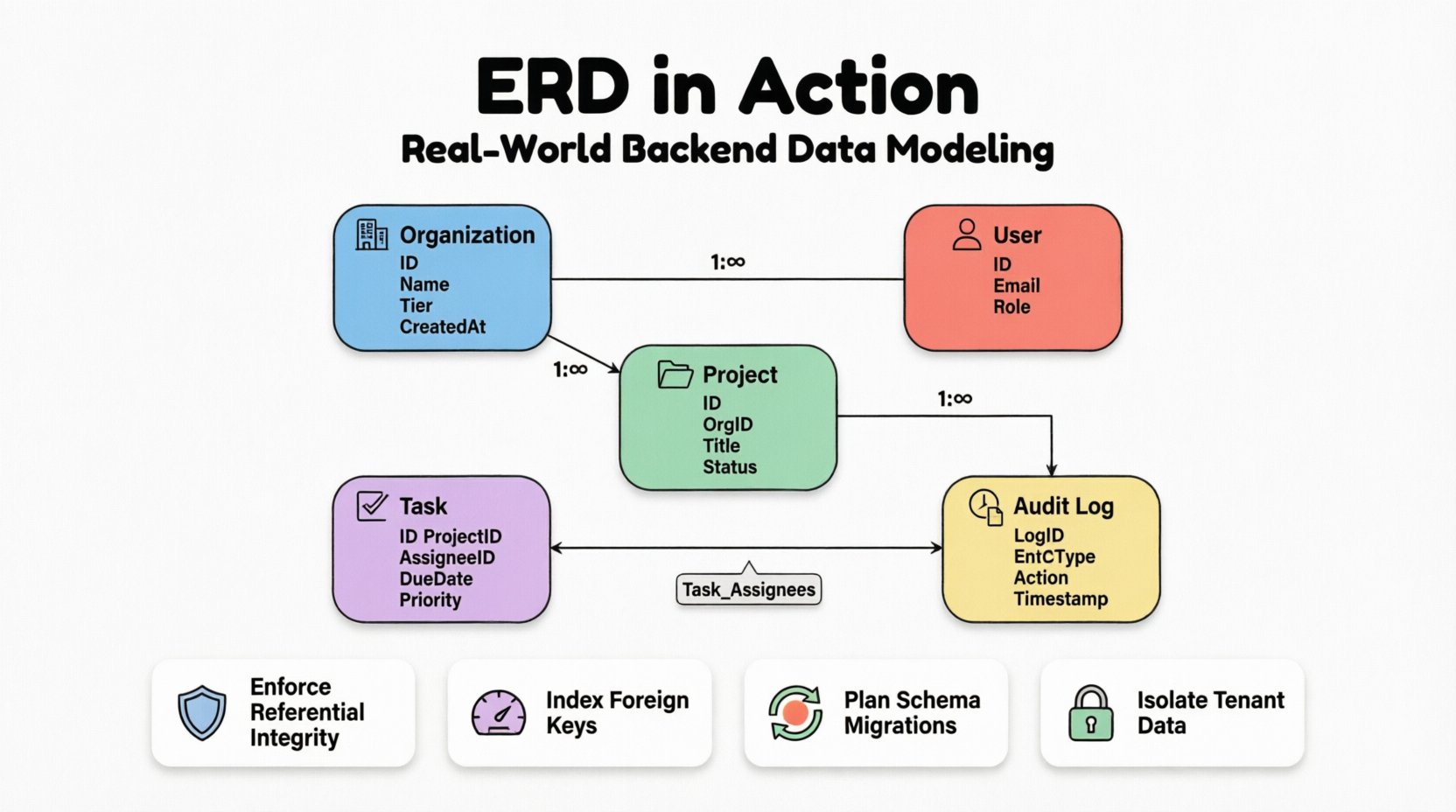
🔍 Entidades e Atributos Principais
A base de qualquer ERD é a definição de entidades. Neste estudo de caso, identificamos cinco entidades principais. Cada entidade representa um conceito distinto que deve ser persistido no banco de dados. Os atributos associados a essas entidades definem o nível de granularidade dos dados armazenados.
1. Entidade Organização
Esta é a raiz da hierarquia. Todos os outros registros são vinculados a esta entidade para garantir o isolamento do locatário.
- ID da Organização: Identificador único.
- Nome da Organização: Rótulo legível pelo ser humano.
- Nível de Assinatura: Determina o acesso a recursos.
- Criado em:Marca de tempo para auditoria.
2. Entidade Usuário
Os usuários pertencem a organizações, mas podem ser membros de múltiplos projetos. Os detalhes de autenticação são separados dos dados de negócios para seguir as melhores práticas de segurança.
- ID do Usuário: Identificador único.
- E-mail: Usado para autenticação e contato.
- Hash da Senha: Armazenamento seguro para credenciais.
- Função: Define permissões (Administrador, Membro, Visualizador).
3. Entidade Projeto
Projetos são os contêineres para itens de trabalho. Eles são de propriedade de uma organização, mas trabalhados por usuários.
- ID do Projeto: Identificador único.
- ID da Organização: Chave estrangeira que faz ligação com o locatário pai.
- Título: Nome curto para o projeto.
- Status: Ativo, Arquivado ou Excluído.
4. Entidade Tarefa
A unidade central de trabalho. Essa entidade exige as relações mais complexas, pois liga usuários, projetos e registros.
- ID da Tarefa: Identificador único.
- ID do Projeto: Chave estrangeira.
- ID do Responsável: Chave estrangeira para Usuário.
- Data de Vencimento: Restrição temporal.
- Prioridade: Valor enumerado.
5. Entidade de Registro de Auditoria
Registra todas as alterações feitas em entidades críticas. Isso garante rastreabilidade.
- ID do Registro: Identificador único.
- Tipo de Entidade: Qual tabela foi afetada.
- ID do Registro: Qual linha foi afetada.
- Ação: Criar, Atualizar, Excluir.
- Realizado Por: ID do Usuário.
- Horário: Horário da ação.
🔗 Modelagem de Relacionamentos e Cardinalidade
Relacionamentos definem como as entidades interagem. Em um sistema de produção, esses relacionamentos são enforceados por chaves estrangeiras. A cardinalidade (um-para-um, um-para-muitos, muitos-para-muitos) determina como os dados são consultados e atualizados.
Organização para Usuário
Este é um Um-para-Muitos relacionamento. Uma organização pode ter muitos usuários, mas um registro de usuário está vinculado a uma única organização para fins de isolamento de dados. Para evitar vazamento de dados entre locatários, o organization_id é uma chave estrangeira obrigatória na tabela de Usuários.
Organização para Projeto
Semelhantemente, este é um Um-para-Muitos relacionamento. Projetos não podem existir sem uma organização pai. Se uma organização for excluída, o comportamento em cascata deve ser cuidadosamente considerado. Neste caso, optamos por excluir projetos de forma suave em vez de excluí-los permanentemente, para preservar o contexto histórico.
Projeto para Tarefa
Outro Um-para-Muitos relacionamento. Um projeto contém múltiplas tarefas, e uma tarefa pertence a exatamente um projeto. Este é um link estrutural padrão.
Usuário para Tarefa (Atribuição)
Este é o relacionamento mais crítico. Um usuário pode ser atribuído a múltiplas tarefas, e uma tarefa pode ser atribuída a múltiplos usuários (trabalho colaborativo). Isso exige um Muitos para Muitos relação.
Para implementar isso, introduzimos uma tabela de junção, frequentemente chamada de entidade associativa. Essa tabela divide a relação muitos para muitos em duas relações um para muitos.
| Nome da Tabela | Propósito | Chaves |
|---|---|---|
| Tarefa_Atribuidos | Linka Usuários a Tarefas | ID_Tarefa, ID_Usuário |
| Organização_Inquilinos | Linka Organizações a Usuários | ID_Organização, ID_Usuário |
Usar uma tabela de junção nos permite armazenar metadados adicionais. Por exemplo, na tabela Tarefa_Atribuidos tabela, podemos armazenar o papel que o usuário teve nessa tarefa específica (por exemplo, Líder, Colaborador), o que difere do seu papel global de usuário.
⚖️ Restrições e Integridade de Dados
A validação em nível de aplicativo não é suficiente. As restrições do banco de dados atuam como a última linha de defesa contra a corrupção de dados. Em um ambiente de produção, as restrições devem ser definidas no nível do esquema.
Integridade Referencial
Chaves estrangeiras garantem que um registro em uma tabela filha não possa referenciar um pai inexistente. Por exemplo, uma tarefa não pode ser atribuída a um usuário que não existe no sistema.
No entanto, os comportamentos ON DELETE e ON UPDATE são decisões críticas:
- CASCADE: Se um pai for excluído, todos os filhos serão excluídos. Use isso para dados órfãos que não têm sentido sem o pai (por exemplo, comentários em um post excluído).
- RESTRICT: Impede a exclusão se filhos existirem. Use isso para prevenir perda acidental de dados (por exemplo, excluir uma organização que possui registros ativos de cobrança).
- SET NULL: Se o pai for excluído, a coluna de chave estrangeira na tabela filha torna-se NULL. Use isso quando a relação é opcional.
Restrições de Verificação
O SQL padrão suporta restrições de verificação para impor regras específicas do domínio. Exemplos incluem:
- Data de Vencimento: O
due_datecoluna deve ser maior que acreated_atcoluna. - Prioridade: O
prioritycoluna deve corresponder a uma lista específica de valores permitidos (por exemplo, Baixa, Média, Alta). - Valor: Campos financeiros devem ser não negativos.
Restrições Únicas
Garanta a unicidade dos dados quando necessário. Por exemplo, um endereço de e-mail deve ser único em todo o sistema, ou dentro de uma organização específica, dependendo do modelo de usuário. Uma restrição única composta pode garantir que um usuário seja atribuído a um projeto específico apenas uma vez (evitando atribuições duplicadas).
🚀 Desempenho e Estratégia de Indexação
Um esquema bem projetado é inútil se as consultas forem lentas. A indexação é o mecanismo que permite ao banco de dados encontrar dados rapidamente. No entanto, os índices têm um custo em termos de desempenho de gravação e armazenamento.
Identificação de Padrões de Consulta
Antes de criar índices, analise as operações de leitura mais comuns. Em nosso estudo de caso, consultas típicas incluem:
- Encontre todas as tarefas atribuídas a um usuário específico.
- Encontre todos os projetos dentro de uma organização.
- Recupere os registros de auditoria para uma ID de entidade específica.
Posicionamento de Índices
Chaves estrangeiras são os candidatos mais comuns para indexação. Se uma consulta filtra frequentemente por organization_id, um índice nessa coluna é obrigatório. Sem ele, o banco de dados realiza uma varredura completa da tabela, o que degrada rapidamente à medida que os dados crescem.
Índices compostos são úteis para consultas que filtram em múltiplas colunas. Por exemplo, se o sistema pesquisar frequentemente tarefas por project_id E status, um índice composto em (project_id, status) é mais eficiente do que dois índices separados.
Índices Parciais
Em cenários onde apenas um subconjunto de dados é frequentemente consultado, os índices parciais economizam espaço. Por exemplo, se o sistema consulta apenas por ativo tarefas, um índice que inclui apenas linhas onde status = 'Ativo' pode ser significativamente menor e mais rápido de percorrer do que um índice em toda a tabela.
🛠️ Manutenção e Evolução do Esquema
Requisitos de software mudam. O esquema do banco de dados não é exceção. Mover da versão A para a versão B exige planejamento cuidadoso para evitar tempo de inatividade e perda de dados. Esse processo é frequentemente gerenciado por scripts de migração.
Adicionando Colunas
Adicionar uma nova coluna é geralmente seguro. Se a coluna permitir valores nulos, as linhas existentes não são afetadas. Se a coluna exigir um valor padrão, certifique-se de que o padrão seja aplicável a todos os dados existentes para evitar violações de restrição.
Removendo Colunas
Excluir uma coluna é arriscado. É melhor marcar a coluna como obsoleta primeiro. Isso permite que os desenvolvedores removam as referências à coluna no código do aplicativo antes de removê-la fisicamente do banco de dados. Esse abordagem em duas fases evita erros no aplicativo durante a janela de implantação.
Renomeando Colunas
Renomear colunas raramente é suportado em versões antigas do banco de dados sem soluções complexas. É geralmente melhor adicionar uma nova coluna com o nome desejado, migrar os dados e depois remover a coluna antiga. Isso garante que o esquema permaneça compatível com versões anteriores durante a transição.
🚧 Armadilhas Comuns no Design de ERD
Mesmo arquitetos experientes cometem erros. Compreender armadilhas comuns ajuda a evitá-las na fase de design.
- Sobrenormalização:Dividir os dados em muitas tabelas pequenas torna as consultas complexas e lentas. Equilibre a normalização com as necessidades de desempenho das consultas.
- Subnormalização:Armazenar os mesmos dados em múltiplos locais (por exemplo, repetir nomes de usuários em cada registro de tarefa) leva a anomalias de atualização. Se um usuário mudar seu nome, você deve atualizar cada entrada de registro.
- Dependências Circulares:Criar relacionamentos de chave estrangeira circulares pode levar a bloqueios durante inserção ou exclusão. Certifique-se de que o gráfico de dependência seja um Grafo Direcionado Acíclico (DAG).
- Ignorando Exclusões Suaves: Excluir registros permanentemente remove o histórico. Implemente uma coluna de timestamp
deleted_atpara manter os registros visíveis para auditoria, enquanto os esconde das visualizações padrão. - Tipos de Dados Implícitos: Usar tipos genéricos como
VARCHAR(255)para tudo desperdiça espaço. UseINTpara IDs,BOOLEANpara flags e restrições de comprimento específicas para strings quando apropriado.
✅ Melhores Práticas para ERDs de Produção
Para garantir a longevidade e a saúde do sistema, siga estas diretrizes:
- Documente Relacionamentos: O próprio ERD é documentação. Certifique-se de mantê-lo atualizado com o esquema real. Ferramentas automatizadas podem gerar diagramas a partir do banco de dados para verificar a precisão.
- Padronize Convenções de Nomeação: Use
snake_casepara tabelas e colunas. Prefixe chaves estrangeiras com o nome da relação (por exemplo,organization_idem vez de apenasorg_id) para clareza. - Use UUIDs em vez de Auto-Incremento: Para sistemas distribuídos, UUIDs evitam problemas de colisão ao mesclar bancos de dados. Para sistemas de instância única, inteiros com auto-incremento são mais compactos e mais rápidos.
- Planeje para o Crescimento: Projete levando em conta o particionamento. Se uma tabela for esperada para crescer até bilhões de linhas, considere como ela será dividida entre shards ou partições com base no
organization_id. - Revise Padrões de Acesso: Revise regularmente os logs de consultas lentas para identificar índices ausentes ou junções ineficientes.
🔄 O Ciclo de Vida de um Esquema
Um ERD não é um documento estático. Ele evolui com o produto. O ciclo de vida geralmente segue estas etapas:
- Fase de Design: Elaboração do modelo inicial com base nos requisitos.
- Fase de Implementação: Criando scripts de migração para construir o esquema.
- Fase de Validação: Executando testes de carga para verificar suposições de desempenho.
- Fase de Iteração: Adicionando novos campos ou relacionamentos conforme os recursos são adicionados.
- Fase de Otimização: Aperfeiçoando índices e restrições com base em dados de produção.
Durante a fase de otimização, você pode descobrir que as suposições iniciais sobre cardinalidade estavam erradas. Por exemplo, você pode descobrir que uma Um-Para-Muitosrelação na verdade era uma Muitos-Para-Muitosna prática, exigindo uma alteração no esquema para uma tabela de junção. Isso destaca a importância da flexibilidade no design.
🛡️ Considerações de Segurança no Design de Esquema
A segurança de dados está profundamente entrelaçada com o design de esquema. Políticas de segurança em nível de linha (RLS) muitas vezes dependem da estrutura do diagrama ER para funcionar corretamente. Se o organization_idnão for adequadamente indexado e aplicado, um usuário da Organização A pode acidentalmente consultar dados da Organização B.
Além disso, dados sensíveis devem ser separados. Se o sistema manipula informações de pagamento, esses dados deveriam idealmente residir em um esquema ou tabela separada com controles de acesso mais rígidos, em vez de serem misturados com metadados gerais de usuários. Isso limita o alcance do dano em caso de violação.
📝 Resumo das Decisões de Design
A tabela a seguir resume as decisões principais tomadas neste estudo de caso e a justificativa por trás delas.
| Decisão | Opção A | Opção B (Selecionada) | Justificativa |
|---|---|---|---|
| Multi-inquilinato | Bancos de dados separados | Banco de dados compartilhado, esquema compartilhado | Redução da sobrecarga operacional; mais fácil de gerenciar análises entre inquilinos. |
| Exclusão de Organizações | Exclusão Rígida | Exclusão Suave | Preserva os registros históricos de auditoria e evita perda de dados para conformidade. |
| Atribuições de Tarefas | Coluna Única | Tabela de Junção | Permite múltiplos atribuídos e rastreia papéis específicos por atribuição. |
| Chaves Primárias | Auto-Incremento | UUIDs | Suporta arquitetura distribuída futura e mesclagem de dados mais fácil. |
Construir um backend de produção exige mais do que apenas escrever código. Exige um entendimento profundo de como os dados fluem e como são estruturados. Um ERD é o mapa que orienta essa jornada. Ao seguir esses princípios, você garante que o sistema permaneça estável, seguro e escalável à medida que o negócio cresce.
Lembre-se, o objetivo não é criar o diagrama mais complexo possível, mas aquele que melhor atende às necessidades do aplicativo, ao mesmo tempo em que minimiza a dívida técnica. A revisão contínua e a adaptação são fundamentais para manter um ecossistema de dados saudável.