











Todo aplicativo começa com uma ideia. Essa ideia exige armazenamento de dados, e esse armazenamento exige uma planta. Essa planta é o Diagrama Entidade-Relacionamento (ERD). É o documento fundamental que determina como o seu sistema entende as informações. No entanto, uma planta para uma pequena cabana não serve para um arranha-céu. Da mesma forma, um esquema de banco de dados projetado para um protótipo frequentemente falha sob o peso do tráfego de produção e da lógica de negócios complexa.
Compreender a evolução do ERD é essencial para líderes técnicos, administradores de banco de dados e arquitetos de software. Envolve navegar pela tensão entre flexibilidade e integridade. À medida que sua base de usuários cresce, suas necessidades de dados mudam. Você não pode simplesmente manter o modelo inicial para sempre. Deve adaptá-lo. Este guia explora o ciclo de vida de um modelo de dados, desde a primeira linha de código até arquiteturas em escala empresarial.
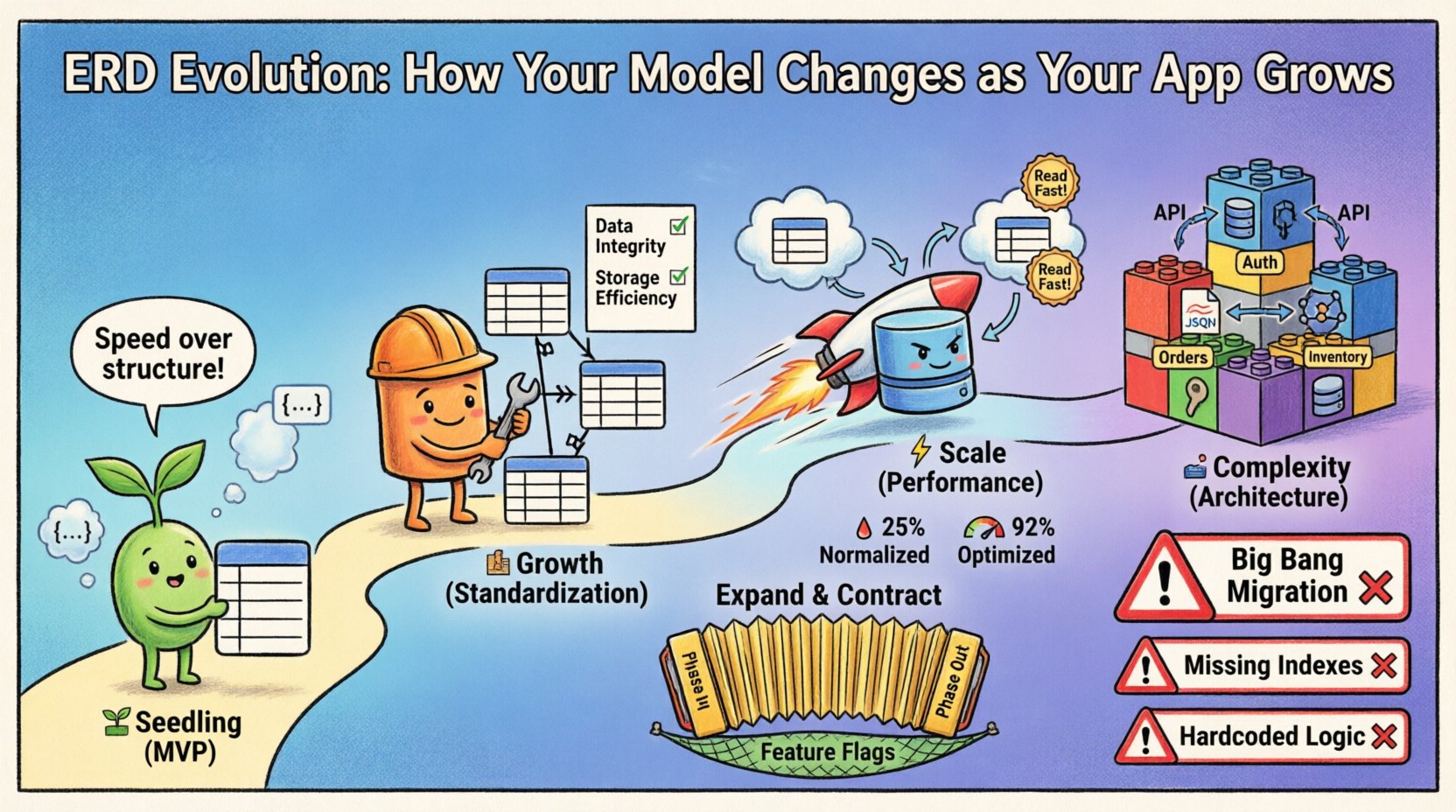
Fase 1: Estágio de Muda (MVP) 🌱
No início, a velocidade é a métrica principal. O objetivo é validar a hipótese central com o mínimo de atrito possível. Nesta fase, o ERD é frequentemente fluido, refletindo necessidades imediatas em vez de previsões de longo prazo.
- Foco: Funcionalidade sobre estrutura.
- Estrutura: Esquemas planos são comuns. As relações são frequentemente desnormalizadas para reduzir a complexidade das junções.
- Restrições: Chaves estrangeiras podem ser soltas ou omitidas para permitir iterações rápidas.
- Mudanças: Modificações no esquema ocorrem semanalmente, às vezes diariamente.
Durante esta fase, você pode ver entidades fortemente acopladas. Por exemplo, uma Usuáriotabela pode conter um blob JSON de configurações de perfil em vez de uma tabela separada de Perfiltabela. Isso reduz a necessidade de junções, acelerando as operações de leitura para o painel. No entanto, isso gera dívida técnica. À medida que o aplicativo amadurece, consultar esses dados aninhados torna-se mais lento e difícil de manter.
Características Principais dos Modelos Iniciais
- Restrições mínimas de chaves estrangeiras.
- Tipos de coluna flexíveis (por exemplo, usar VARCHAR para tudo).
- Instância única de banco de dados.
- Mapeamento direto entre objetos do aplicativo e tabelas do banco de dados.
Fase 2: Estágio de Crescimento (Padronização) 🏗️
Assim que o produto ganha tração, a flexibilidade inicial torna-se um ônus. A duplicação de dados leva a inconsistências. Se um usuário atualiza seu endereço de e-mail em um lugar, mas não em outro, o sistema perde a confiança. É nesta fase que a normalização assume precedência.
Por que normalizar agora?
- Integridade dos dados: Garantir a integridade referencial evita registros órfãos.
- Eficiência de armazenamento: Remover dados redundantes economiza espaço em disco.
- Manutenibilidade: Atualizar um único registro em uma tabela normalizada atualiza-o em todos os lugares logicamente.
- Previsibilidade de Consultas: Estruturas padronizadas tornam a escrita de consultas menos propensa a erros.
Durante esta transição, você deve refatorar o ERD. Uma tabela de usuário plana pode ser dividida em Usuários e Detalhes do Usuário. Isso introduz relacionamentos. Você deve definir se esses são um para um, um para muitos ou muitos para muitos.
Lista de Verificação da Transição
- Identifique todos os campos duplicados entre as tabelas.
- Defina chaves primárias para todas as entidades.
- Implemente restrições de chave estrangeira para garantir relacionamentos.
- Revise as consultas existentes quanto aos impactos de desempenho das novas junções.
- Planeje a compatibilidade reversa durante a migração.
Fase 3: Estágio de Escala (Desempenho) ⚡
Quando existem milhões de registros, a estrutura normalizada pode se tornar um gargalo. As junções são computacionalmente custosas em grande escala. É aqui que o modelo evolui novamente, muitas vezes se afastando da normalização rígida em direção à desnormalização estratégica para desempenho.
Desnormalização Estratégica
Isso não é uma regressão para a fase do MVP. É uma decisão calculada. Você duplica intencionalmente dados para evitar junções caras em tabelas grandes.
- Cargas de Trabalho com Leitura Intensa: Se o seu aplicativo é principalmente de leitura, o armazenamento em cache de dados no esquema reduz a carga no banco de dados.
- Tabelas de Relatórios: Dados pré-agregados para painéis evitam o cálculo de somas em tempo real.
- Particionamento: Dividir tabelas por data ou região exige um design específico de esquema para permitir consultas eficientes.
Comparação: Normalizado vs. Otimizado
| Funcionalidade | Normalizado (Fase 2) | Otimizado (Fase 3) |
|---|---|---|
| Integridade | Alto (Imposto pelo BD) | Gerenciado pela Lógica da Aplicação |
| Velocidade de Escrita | Rápido | Mais lento (Atualiza várias tabelas) |
| Velocidade de Leitura | Mais lento (Requer Joins) | Rápido (Consulta Única) |
| Armazenamento | Eficiente | Menos Eficiente (Redundância) |
Fase 4: O Estágio da Complexidade (Arquitetura) 🏛️
No nível empresarial, um único modelo de banco de dados muitas vezes é insuficiente. O sistema pode se dividir em microserviços ou utilizar persistência poliglota. O MER já não representa um único diagrama físico, mas uma coleção de modelos que se comunicam.
Microserviços e Propriedade de Dados
Em uma arquitetura monolítica, a Pedidostabela é compartilhada pelos serviços de faturamento, envio e notificação. Em um sistema distribuído, cada serviço possui seus próprios dados. Isso exige uma mudança na forma como você modela as relações.
- Consistência Eventual: Você não pode confiar em transações ACID entre serviços. O MER deve levar em conta a sincronização de estado.
- Contratos de API: As relações são frequentemente definidas pelas respostas da API em vez de chaves estrangeiras.
- Sincronização de Dados: Ferramentas são necessárias para manter os dados consistentes entre diferentes armazenamentos (por exemplo, SQL para pedidos, NoSQL para logs).
Persistência Poliglota
Dados diferentes exigem motores de armazenamento diferentes. O MER evolui para incluir conceitos não relacionais.
- Dados em Grafos: Para redes sociais ou motores de recomendação, um modelo em grafos substitui as tabelas relacionais.
- Bancos de Documentos: Para conteúdo flexível, como catálogos de produtos, documentos JSON substituem colunas rígidas.
- Bancos de Chave-Valor: Para gerenciamento de sessão e armazenamento em cache, pares simples chave-valor substituem linhas complexas.
Análise Técnica Aprofundada: Níveis de Normalização 🔬
Para evoluir seu modelo de forma eficaz, você precisa entender as regras que está seguindo ou violando. A normalização é o processo de organizar dados para reduzir a redundância.
Primeira Forma Normal (1NF)
- Valores atômicos: Cada coluna contém apenas um valor.
- Sem grupos repetidos: Você não pode ter colunas como
cor1,cor2,cor3. - Identificadores únicos: Cada linha deve ser identificável de forma única.
Segunda Forma Normal (2NF)
- Deve estar na 1NF.
- Todos os atributos não-chave devem depender totalmente da chave primária.
- Remove dependências parciais (por exemplo, mover informações do fornecedor para uma tabela separada se ela depender apenas do ID do fornecedor, e não do ID do pedido).
Terceira Forma Normal (3NF)
- Deve estar na 2NF.
- As dependências transitivas são removidas.
- Uma coluna não pode depender de outra coluna não-chave (por exemplo,
Cidadedepende deEstado, e não apenasCEP). MovaCidadeeEstadopara umLocalizaçãotabela.
Armadilhas Comuns na Evolução do ERD ⚠️
Mesmo equipes experientes cometem erros ao refatorar modelos. Reconhecer esses padrões ajuda a evitar paradas caras.
1. A Migração do “Big Bang”
Tentar mudar todo o esquema em uma única implantação. Isso apresenta alto risco. Se o script de migração falhar, o sistema ficará inoperante.
- Solução: Use migrações incrementais. Adicione colunas, preencha os dados, altere a lógica e, em seguida, remova as colunas antigas.
2. Ignorar as Implicações do Indexamento
Mudar relacionamentos altera os padrões de consulta. Um novo relacionamento de chave estrangeira pode exigir um novo índice para funcionar bem.
- Solução: Analise os logs de consultas lentas antes e depois das mudanças no esquema.
- Solução: Planeje a criação de índices durante horários de baixa carga.
3. Codificação Fixa de Restrições na Lógica do Aplicativo
Algumas equipes preferem validar dados no código em vez do banco de dados. Isso leva à corrupção de dados se múltiplos serviços escreverem no mesmo armazenamento.
- Solução: Mantenha as restrições na camada do banco de dados (NOT NULL, restrições CHECK), mesmo que o aplicativo seja distribuído.
Estratégias de Migração 🔄
Quando você precisar evoluir o ERD, precisa de uma estratégia que minimize tempo de inatividade e perda de dados.
Padrão de Expansão e Contratação
Este é o padrão ouro para evolução segura do esquema.
- Adicionar: Adicione a nova coluna ou tabela ao esquema. Não altere a lógica existente ainda.
- Gravar: Atualize o aplicativo para gravar tanto na estrutura antiga quanto na nova.
- Ler: Atualize o aplicativo para ler a partir da nova estrutura.
- Preenchimento de Retorno: Execute um trabalho em segundo plano para preencher a nova estrutura com os dados antigos.
- Contrato: Uma vez verificado, remova as colunas e a lógica antigas.
Bandeiras de Recursos
Use bandeiras de recurso para alternar entre o esquema antigo e o novo. Isso permite que você reverta imediatamente se surgirem problemas, sem precisar implantar um script de rollback.
Documentação e Versionamento 📝
Um ERD não é um produto entregue apenas uma vez. É um documento vivo. À medida que o modelo evolui, a documentação deve acompanhar esse ritmo.
Controle de Versão para Esquemas
- Trate os arquivos de esquema (scripts SQL) como código. Armazene-os no seu sistema de controle de versão.
- Use ferramentas de migração para rastrear mudanças ao longo do tempo.
- Marque as versões com versões de esquema (por exemplo,
v1.2.0-esquema).
Consistência Visual
- Padronize convenções de nomeação (por exemplo, snake_case vs camelCase).
- Garanta que os nomes das tabelas reflitam o domínio (por exemplo,
clienteem vez det1). - Mantenha comentários no esquema para contexto de lógica de negócios.
Preparando Seu Modelo para o Futuro 🚀
Você não consegue prever o futuro, mas pode construir flexibilidade. Embora o superdimensionamento seja ruim, projetar para mudanças é inteligente.
Padrões de Design Extensíveis
- EAV (Entidade-Atributo-Valor): Útil para dados altamente variáveis, embora sacrifique o desempenho de consultas.
- Colunas JSON: Bancos de dados modernos suportam tipos JSON. Isso permite armazenar atributos flexíveis sem alterar a estrutura da tabela.
- Sistemas de Etiquetagem: Use uma relação muitos para muitos para metadados em vez de codificar atributos específicos.
Monitoramento e Auditoria
- Rastreie as alterações no esquema. Quem alterou o que e quando?
- Monitore tendências de crescimento de dados. Se uma tabela crescer 50% por mês, planeje a partição antes que ela comece a desacelerar.
- Configure alertas para violações de restrições.
Conclusão sobre Adaptabilidade 🔄
A evolução de um ERD é um reflexo da maturidade da aplicação. Ela passa da flexibilidade para a integridade, e depois para o desempenho. Cada fase apresenta novos desafios. A chave é antecipar essas mudanças e gerenciá-las de forma deliberada.
Não existe um único modelo ‘perfeito’. Existe apenas o modelo que se adapta às suas restrições atuais e à trajetória de crescimento. Ao compreender os trade-offs entre normalização, denormalização e padrões arquitetônicos, você pode garantir que sua camada de dados suporte seu negócio por muitos anos.
- Comece simples, mas planeje para a estrutura.
- Normalizar para integridade, denormalizar para velocidade.
- Documente todas as alterações.
- Teste as migrações com rigor.
Seus dados são seu ativo mais valioso. Trate o modelo que os contém com o cuidado que merece.