











每個應用程式都從一個構想開始。這個構想需要資料儲存,而資料儲存則需要一份藍圖。這份藍圖就是實體-關係圖(ERD)。它是決定系統如何理解資訊的基礎文件。然而,一間小棚屋的藍圖無法適用於摩天大樓。同樣地,為原型設計的資料庫結構,往往無法承受生產環境的流量壓力與複雜的商業邏輯。
理解ERD的演進對技術負責人、資料庫管理員與軟體架構師至關重要。這涉及在彈性與完整性之間取得平衡。隨著使用者群體擴大,你的資料需求也會改變。你不能永遠維持最初的模型。必須加以調整。本指南探討資料模型的生命周期,從第一行程式碼到企業級架構。
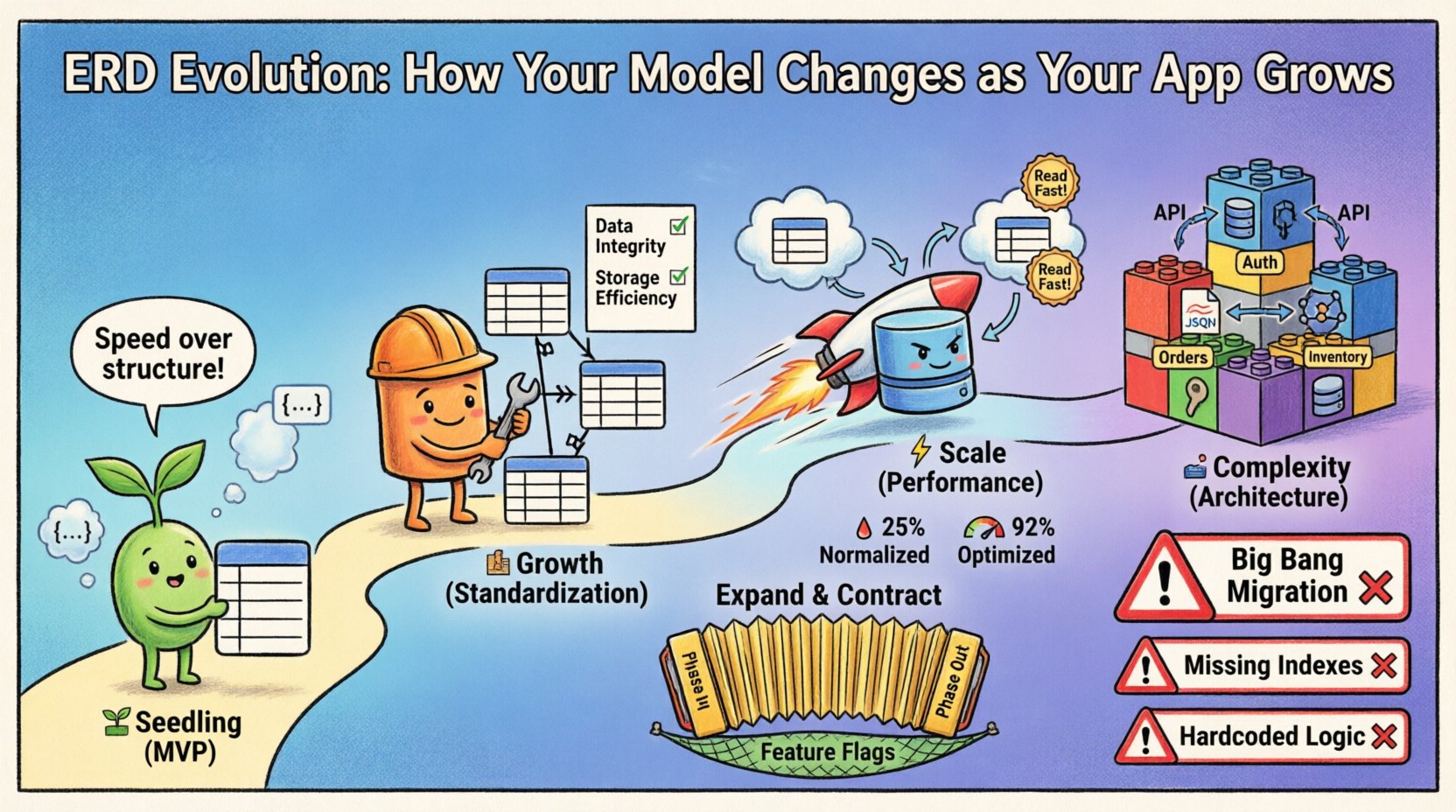
第一階段:幼苗期(MVP) 🌱
起初,速度是首要指標。目標是以最少的阻力驗證核心假設。在此階段,ERD通常具有高度流動性,反映的是當下的需求,而非長期預測。
- 重點:功能優先於結構。
- 結構:平面結構相當常見。關係通常會去規範化,以降低連接的複雜度。
- 限制:外鍵可能較為鬆散或被省略,以支援快速迭代。
- 變更:資料結構的修改可能每週發生,有時甚至每天一次。
在此階段,你可能會看到緊密耦合的實體。例如,一個 User資料表可能包含一個JSON格式的個人設定資料,而不是獨立的 Profile資料表。這可以減少對連接的需求,加快儀表板的讀取操作。然而,這會產生技術負債。隨著應用程式成熟,查詢這些嵌套資料會變得越來越慢,也更難維護。
早期模型的關鍵特徵
- 最少的外鍵約束。
- 彈性的欄位類型(例如,全部使用VARCHAR)。
- 單一資料庫實例。
- 應用程式物件與資料庫表格之間的直接對應。
第二階段:成長期(標準化) 🏗️
當產品獲得市場認可後,最初的彈性反而成為負擔。資料重複會導致不一致。如果使用者在一個地方更新了電子郵件,卻未在另一處更新,系統的信任度就會受損。這正是規範化應被優先考慮的階段。
現在為什麼要進行規範化?
- 資料完整性:強制執行參考完整性,可防止孤立記錄的產生。
- 儲存效率:移除重複資料可節省磁碟空間。
- 可維護性:在規範化的資料表中更新單一記錄,會在邏輯上於所有地方更新該記錄。
- 查詢可預測性:標準化的結構使撰寫查詢時更不容易出錯。
在此轉換期間,您必須重構實體關係圖(ERD)。一個平面的使用者資料表可能會被拆分為使用者 和 使用者詳細資料。這會引入關係。您必須明確定義這些關係是一對一、一對多,還是多對多。
轉換清單
- 識別所有跨資料表的重複欄位。
- 為所有實體定義主鍵。
- 實作外鍵約束以強制執行關係。
- 檢視現有查詢,評估新連接對效能的影響。
- 在遷移期間規劃向後相容性。
第三階段:擴展階段(效能)⚡
當存在數百萬筆記錄時,規範化結構可能成為瓶頸。在規模擴大時,連接運算成本高昂。此時模型會再次演進,通常會從嚴格的規範化轉向策略性去規範化以提升效能。
策略性去規範化
這並非回歸到MVP階段。而是一項經過計算的決策。您會刻意重複資料,以避免在大型資料表上進行成本高昂的連接運算。
- 以讀取為主的工作負載: 如果您的應用程式主要以讀取為主,將資料快取在結構中可降低資料庫負載。
- 報表資料表: 為儀表板預先聚合的資料可避免即時計算總和。
- 分割: 按日期或地區分割資料表,需要特定的結構設計,以確保查詢效率。
對比:規範化 vs. 優化
| 功能 | 規範化(第二階段) | 優化(第三階段) |
|---|---|---|
| 完整性 | 高(由資料庫強制執行) | 由應用程式邏輯管理 |
| 寫入速度 | 快速 | 較慢(更新多個資料表) |
| 讀取速度 | 較慢(需要連接) | 快速(單一查詢) |
| 儲存空間 | 高效 | 效率較低(冗餘) |
第四階段:複雜性階段(架構) 🏛️
在企業級別,單一資料庫模型通常不夠用。系統可能拆分成微服務,或使用多語言持久化。ERD不再代表單一的物理圖示,而是一組相互溝通的模型集合。
微服務與資料所有權
在單體架構中,訂單資料表由計費、運送和通知服務共用。在分散式系統中,每個服務擁有其資料。這需要改變你建模關係的方式。
- 最終一致性:你無法依賴跨服務的ACID交易。ERD必須考慮狀態同步。
- API合約:關係通常由API回應定義,而非外鍵。
- 資料同步:需要工具來維持不同資料儲存空間之間的資料一致性(例如,訂單使用SQL,日誌使用NoSQL)。
多語言持久化
不同的資料需要不同的儲存引擎。ERD演進為包含非關聯性概念。
- 圖形資料:對於社交網路或推薦引擎,圖形模型取代關聯式資料表。
- 文件儲存:對於彈性內容,如產品目錄,JSON文件取代僵硬的欄位。
- 鍵值儲存: 用於會話管理和快取,簡單的鍵值對取代了複雜的資料列。
技術深入探討:資料庫規範化層級 🔬
為了有效發展你的模型,你必須理解你正在遵循或違反的規則。規範化是組織資料以減少冗餘的過程。
第一範式 (1NF)
- 原子值:每個欄位僅包含一個值。
- 無重複群組:你不能有類似以下的欄位
color1,color2,color3. - 唯一識別符:每一列都必須能被唯一識別。
第二範式 (2NF)
- 必須符合 1NF。
- 所有非鍵屬性都必須完全依賴於主鍵。
- 消除部分依賴(例如,若供應商資訊僅依賴於供應商 ID 而非訂單 ID,則將其移至獨立的資料表)。
第三範式 (3NF)
- 必須符合 2NF。
- 消除傳遞依賴。
- 欄位不能依賴於另一個非鍵欄位(例如,
City依賴於State,而不僅僅是Zip Code)。將City和State到一個位置表。
ERD演進中的常見陷阱 ⚠️
即使經驗豐富的團隊在重構模型時也會犯錯。識別這些模式有助於避免高昂的停機成本。
1. 「大爆炸」遷移
試圖在一次部署中更改整個架構。這具有很高的風險。如果遷移腳本失敗,系統將無法運作。
- 解決方案: 使用逐步遷移。新增欄位,填入資料,切換邏輯,然後移除舊的欄位。
2. 忽略索引影響
更改關係會改變查詢模式。新的外鍵關係可能需要新增索引才能良好運作。
- 解決方案: 在架構變更前後分析慢查詢日誌。
- 解決方案: 在非高峰時段規劃索引建立。
3. 在應用程式邏輯中硬編碼約束
有些團隊偏好在程式碼中驗證資料,而非資料庫中。如果多個服務寫入同一個儲存位置,將導致資料損壞。
- 解決方案: 即使應用程式是分散式的,也應將約束保留在資料庫層(NOT NULL、CHECK 約束)。
遷移策略 🔄
當你必須演進ERD時,需要一種能最小化停機時間和資料損失的策略。
擴展與收縮模式
這是安全架構演進的黃金標準。
- 新增: 將新的欄位或表格加入架構中。目前不要更改現有的邏輯。
- 寫入: 更新應用程式,使其同時寫入舊結構和新結構。
- 讀取: 更新應用程式,使其從新結構讀取。
- 補填: 執行背景工作,以舊資料填入新結構。
- 合約: 確認無誤後,移除舊的欄位與邏輯。
功能旗標
使用功能旗標在舊資料結構與新資料結構之間切換。若出現問題,可立即回退,無需部署還原腳本。
文件與版本控制 📝
ERD 不是一次性的交付成果,而是一份持續更新的文件。隨著模型的演進,文件也必須同步更新。
資料結構的版本控制
- 將資料結構檔案(SQL 指令碼)視為程式碼,儲存在您的版本控制系統中。
- 使用遷移工具追蹤時間上的變更。
- 以資料結構版本標記發行版本(例如,
v1.2.0-schema).
視覺一致性
- 統一命名慣例(例如,snake_case 與 camelCase)。
- 確保資料表名稱反映領域語意(例如,
customer而非t1). - 在資料結構中保留註解,以提供商業邏輯的上下文。
為您的模型做好未來準備 🚀
你無法預測未來,但可以建立彈性。雖然過度設計不好,但為變更而設計則是明智之舉。
可擴展的設計模式
- EAV(實體-屬性-值): 適用於高度變動的資料,但會犧牲查詢效能。
- JSON 欄位: 現代資料庫支援 JSON 類型。這讓您可以在不變更資料表結構的情況下,儲存彈性的屬性。
- 標籤系統: 使用多對多關係來處理元資料,而非硬編碼特定屬性。
監控與審計
- 追蹤結構變更。誰在何時更改了什麼?
- 監控資料增長趨勢。如果一個資料表每月增長 50%,請在它變慢之前規劃分割。
- 為約束違規設定警示。
適應力的結論 🔄
ERD 的演變反映了應用程式的成熟度。它從彈性過渡到完整性,再進展到效能。每個階段都會帶來新的挑戰。關鍵在於預見這些變動並有意識地加以管理。
並不存在單一的「完美」模型。只有符合你當前限制與成長軌跡的模型才是最佳選擇。透過理解正規化、反正規化與架構模式之間的權衡,你可以確保你的資料層能長期支援你的業務發展。
- 從簡單開始,但要為結構做好規劃。
- 正規化以確保完整性,反正規化以提升速度。
- 記錄每一次變更。
- 嚴格測試遷移過程。
你的資料是你最有價值的資產。請以應有的謹慎對待儲存它的模型。