











Every application starts with an idea. That idea requires data storage, and that storage requires a blueprint. This blueprint is the Entity-Relationship Diagram (ERD). It is the foundational document that dictates how your system understands information. However, a blueprint for a small shed does not work for a skyscraper. Similarly, a database schema designed for a prototype often fails under the weight of production traffic and complex business logic.
Understanding ERD evolution is critical for technical leads, database administrators, and software architects. It involves navigating the tension between flexibility and integrity. As your user base expands, your data requirements shift. You cannot simply keep the initial model forever. You must adapt it. This guide explores the lifecycle of a data model, from the first line of code to enterprise-scale architecture.
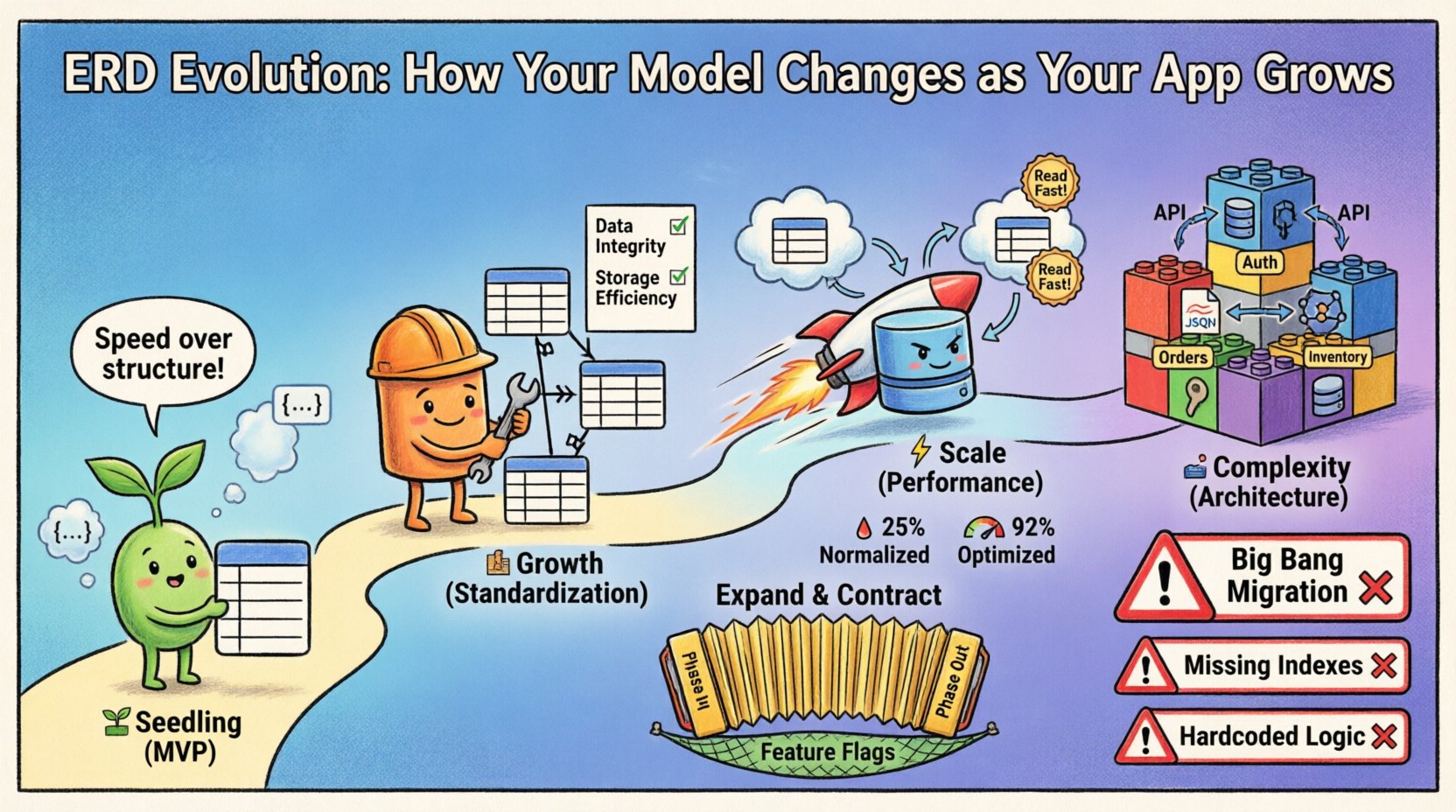
Phase 1: The Seedling Stage (MVP) 🌱
In the beginning, speed is the primary metric. The goal is to validate the core hypothesis with minimal friction. At this stage, the ERD is often fluid, reflecting immediate needs rather than long-term predictions.
- Focus: Functionality over structure.
- Structure: Flat schemas are common. Relationships are often denormalized to reduce join complexity.
- Constraints: Foreign keys may be loose or omitted to allow rapid iteration.
- Changes: Schema modifications happen weekly, sometimes daily.
During this phase, you might see entities that are tightly coupled. For example, a User table might contain a JSON blob of profile settings instead of a separate Profile table. This reduces the need for joins, speeding up read operations for the dashboard. However, this creates technical debt. As the application matures, querying that nested data becomes slower and harder to maintain.
Key Characteristics of Early-Stage Models
- Minimal foreign key constraints.
- Flexible column types (e.g., using VARCHAR for everything).
- Single database instance.
- Direct mapping between application objects and database tables.
Phase 2: The Growth Stage (Standardization) 🏗️
Once the product gains traction, the initial flexibility becomes a liability. Data duplication leads to inconsistencies. If a user updates their email address in one place but not another, the system breaks trust. This is the phase where normalization takes precedence.
Why Normalize Now?
- Data Integrity: Enforcing referential integrity prevents orphaned records.
- Storage Efficiency: Removing redundant data saves disk space.
- Maintainability: Updating a single record in a normalized table updates it everywhere logically.
- Query Predictability: Standardized structures make writing queries less error-prone.
During this transition, you must refactor the ERD. A flat user table might be split into Users and UserDetails. This introduces relationships. You must define whether these are one-to-one, one-to-many, or many-to-many.
Transition Checklist
- Identify all duplicated fields across tables.
- Define primary keys for all entities.
- Implement foreign key constraints to enforce relationships.
- Review existing queries for performance impacts of new joins.
- Plan for backward compatibility during the migration.
Phase 3: The Scale Stage (Performance) ⚡
When millions of records exist, the normalized structure can become a bottleneck. Joins are computationally expensive at scale. This is where the model evolves again, often moving away from strict normalization towards strategic denormalization for performance.
Strategic Denormalization
This is not a regression to the MVP phase. It is a calculated decision. You intentionally duplicate data to avoid expensive joins on large tables.
- Read-Heavy Workloads: If your app is mostly read, caching data in the schema reduces database load.
- Reporting Tables: Pre-aggregated data for dashboards avoids calculating sums on the fly.
- Partitioning: Splitting tables by date or region requires specific schema design to allow efficient querying.
Comparison: Normalized vs. Optimized
| Feature | Normalized (Phase 2) | Optimized (Phase 3) |
|---|---|---|
| Integrity | High (Enforced by DB) | Managed by Application Logic |
| Write Speed | Fast | Slower (Updates multiple tables) |
| Read Speed | Slower (Requires Joins) | Fast (Single Lookup) |
| Storage | Efficient | Less Efficient (Redundancy) |
Phase 4: The Complexity Stage (Architecture) 🏛️
At the enterprise level, a single database model is often insufficient. The system may split into microservices or utilize polyglot persistence. The ERD no longer represents a single physical diagram but a collection of models that communicate.
Microservices and Data Ownership
In a monolithic architecture, the Orders table is shared by the billing, shipping, and notification services. In a distributed system, each service owns its data. This requires a shift in how you model relationships.
- Eventual Consistency: You cannot rely on ACID transactions across services. The ERD must account for state synchronization.
- API Contracts: Relationships are often defined by API responses rather than foreign keys.
- Data Synchronization: Tools are needed to keep data consistent across different stores (e.g., SQL for orders, NoSQL for logs).
Polyglot Persistence
Different data requires different storage engines. The ERD evolves to include non-relational concepts.
- Graph Data: For social networks or recommendation engines, a graph model replaces relational tables.
- Document Stores: For flexible content like product catalogs, JSON documents replace rigid columns.
- Key-Value Stores: For session management and caching, simple key-value pairs replace complex rows.
Technical Deep Dive: Normalization Levels 🔬
To evolve your model effectively, you must understand the rules you are following or breaking. Normalization is the process of organizing data to reduce redundancy.
First Normal Form (1NF)
- Atomic values: Each column contains only one value.
- No repeating groups: You cannot have columns like
color1,color2,color3. - Unique identifiers: Every row must be uniquely identifiable.
Second Normal Form (2NF)
- Must be in 1NF.
- All non-key attributes must be fully dependent on the primary key.
- Removes partial dependencies (e.g., moving vendor info to a separate table if it depends only on Vendor ID, not Order ID).
Third Normal Form (3NF)
- Must be in 2NF.
- Transitive dependencies are removed.
- A column cannot depend on another non-key column (e.g.,
Citydepends onState, not justZip Code). MoveCityandStateto aLocationtable.
Common Pitfalls in ERD Evolution ⚠️
Even experienced teams make mistakes when refactoring models. Recognizing these patterns helps avoid costly downtime.
1. The “Big Bang” Migration
Attempting to change the entire schema in one deployment. This carries high risk. If the migration script fails, the system is broken.
- Solution: Use incremental migrations. Add columns, populate data, switch logic, then remove old columns.
2. Ignoring Indexing Implications
Changing relationships changes query patterns. A new foreign key relationship might require a new index to perform well.
- Solution: Analyze slow query logs before and after schema changes.
- Solution: Plan index creation during off-peak hours.
3. Hardcoding Constraints in Application Logic
Some teams prefer to validate data in the code rather than the database. This leads to data corruption if multiple services write to the same store.
- Solution: Keep constraints in the database layer (NOT NULL, CHECK constraints) even if the app is distributed.
Migration Strategies 🔄
When you must evolve the ERD, you need a strategy that minimizes downtime and data loss.
Expand and Contract Pattern
This is the gold standard for safe schema evolution.
- Add: Add the new column or table to the schema. Do not change existing logic yet.
- Write: Update the application to write to both the old and new structures.
- Read: Update the application to read from the new structure.
- Backfill: Run a background job to populate the new structure with old data.
- Contract: Once verified, remove the old columns and logic.
Feature Flags
Use feature flags to toggle between the old schema and the new schema. This allows you to revert immediately if issues arise without deploying a rollback script.
Documentation and Versioning 📝
An ERD is not a one-time deliverable. It is a living document. As the model evolves, the documentation must keep pace.
Version Control for Schemas
- Treat schema files (SQL scripts) as code. Store them in your version control system.
- Use migration tools to track changes over time.
- Tag releases with schema versions (e.g.,
v1.2.0-schema).
Visual Consistency
- Standardize naming conventions (e.g., snake_case vs camelCase).
- Ensure table names reflect the domain (e.g.,
customerinstead oft1). - Keep comments in the schema for business logic context.
Future Proofing Your Model 🚀
You cannot predict the future, but you can build flexibility. While over-engineering is bad, designing for change is smart.
Extensible Design Patterns
- EAV (Entity-Attribute-Value): Useful for highly variable data, though it sacrifices query performance.
- JSON Columns: Modern databases support JSON types. This allows you to store flexible attributes without altering the table structure.
- Tagging Systems: Use a many-to-many relationship for metadata rather than hard-coding specific attributes.
Monitoring and Auditing
- Track schema changes. Who changed what and when?
- Monitor data growth trends. If a table grows 50% per month, plan for partitioning before it slows down.
- Set up alerts for constraint violations.
Conclusion on Adaptability 🔄
The evolution of an ERD is a reflection of the application’s maturity. It moves from flexibility to integrity, and then to performance. Each phase presents new challenges. The key is to anticipate these changes and manage them deliberately.
There is no single “perfect” model. There is only the model that fits your current constraints and growth trajectory. By understanding the trade-offs between normalization, denormalization, and architectural patterns, you can ensure your data layer supports your business for years to come.
- Start simple, but plan for structure.
- Normalize for integrity, denormalize for speed.
- Document every change.
- Test migrations rigorously.
Your data is your most valuable asset. Treat the model that holds it with the care it deserves.