











设计数据库更多在于理解关系,而不是敲代码。在编写任何脚本之前,必须建立一个视觉基础。这个基础就是实体-关系图(通常称为ERD)。跳过这一步,相当于在没有蓝图的情况下建造摩天大楼。结构或许能支撑一段时间,但随着数据的增长,问题就会暴露出来。🧱
本指南将带你走过数据库架构的初始阶段。它聚焦于创建稳健模式所需的概念模型和逻辑模型。无论你是在管理客户记录、库存,还是复杂的事务数据,这些原则都是一致的。我们将探讨实体、属性、关系和基数,而无需依赖特定工具或专有软件。目标是构建一个可扩展、高效且易于维护的系统。🚀
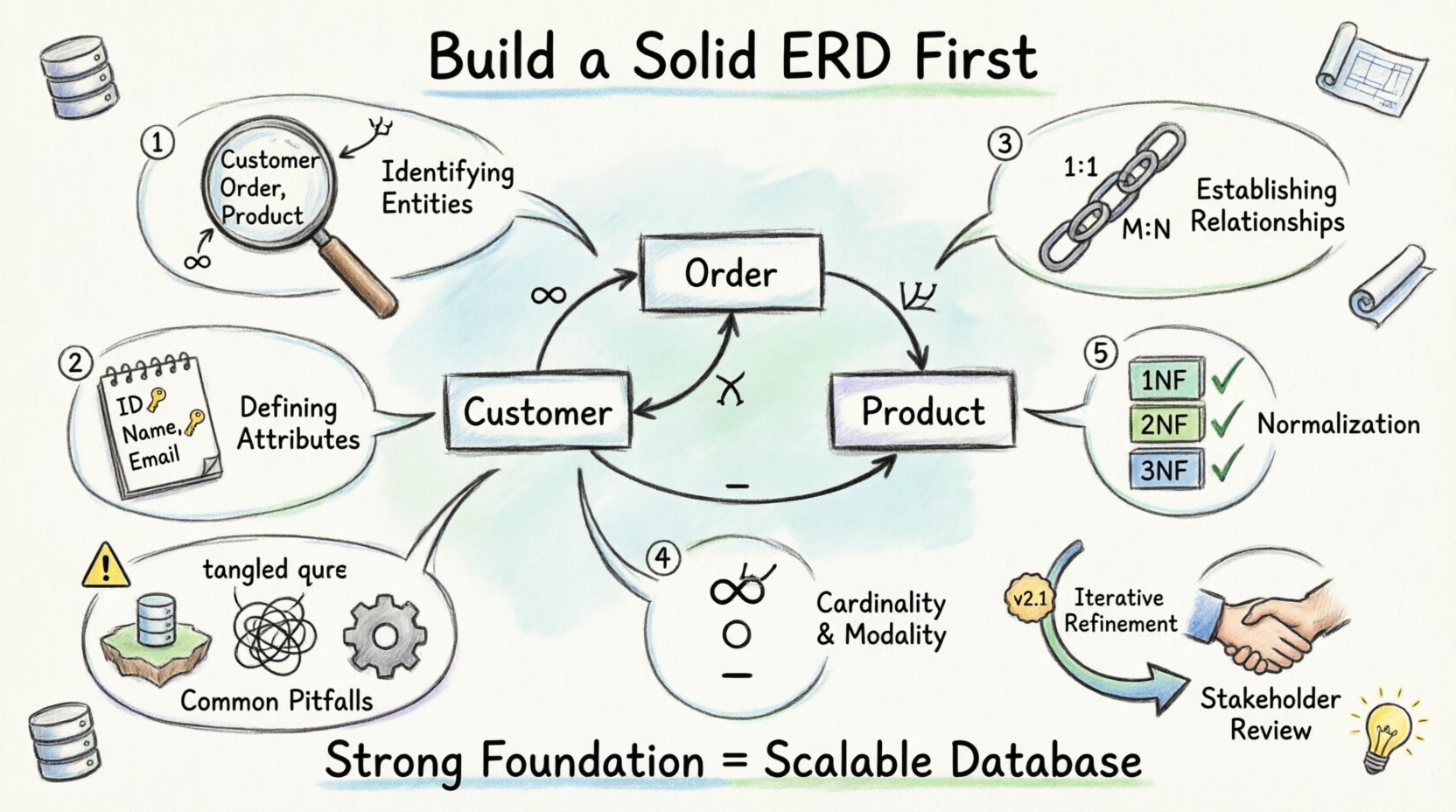
理解实体-关系图 📐
ERD是系统内数据结构的视觉化表示。它描绘出需要存储的“事物”(实体)以及它们之间的相互作用。可以将其视为数据库引擎的地图。它并不定义数据在磁盘上的物理存储方式,而是定义数据在应用程序中的逻辑组织方式。
为什么从这里开始?🤔
从一个稳固的图表开始可以避免多种常见问题:
- 数据冗余:在多个位置存储相同信息会导致数据不一致。
- 完整性错误:关系被明确界定,从而防止出现孤立记录。
- 可扩展性:逻辑模型可以在业务增长时进行调整,而无需完全重建。
- 沟通:利益相关者可以在开发开始前审查结构,确保需求得到满足。
如果没有ERD,开发人员常常只能猜测关系。这会导致后期出现复杂的连接操作和性能瓶颈。一个定义清晰的图表将成为整个项目团队的唯一可信依据。🤝
第一步:识别实体 🏢
任何数据库的基本构建单元都是实体。实体代表一个独立的对象、概念或人,其数据被收集。在图表的语境中,这些就是你在需求中识别出的名词。
现实世界实体与逻辑实体
在分析业务流程时,必须区分物理对象和逻辑概念。例如,“产品”是一个逻辑实体。仓库中的某个具体“小部件”是一个物理实例。数据库存储的是逻辑实体,通过唯一标识符来追踪实例。
识别候选实体
为了找出实体,需审查业务规则和功能需求。请寻找:
- 名词:在需求文档中扫描大写的名词。
- 核心功能:执行了哪些操作?谁参与其中?
- 监管需求:为了合规,必须保留哪些数据?
常见的例子包括:
- 客户: 谁在购买或互动?
- 订单: 交易记录。
- 产品: 正在销售的商品。
- 员工: 谁在管理这个系统?
- 位置: 货物发送到哪里?
实体命名规范
一致性是可读性的关键。在整个图表中使用单数、复数或一致的命名标准。除非是行业标准,否则避免使用缩写。例如,使用“Customer”而不是“Cust”。
| 方面 | 建议 | 示例 |
|---|---|---|
| 案例 | PascalCase 或 snake_case | CustomerRecord 或 customer_record |
| 单复数 | 表名使用单数 | 使用Customer,而不是Customers |
| 清晰性 | 避免使用通用名称 | 使用Invoice,而不是Document |
步骤 2:定义属性 📝
一旦确定了实体,您就必须定义存储在它们身上的信息。这些细节被称为属性。属性描述了实体的特征。
属性的类型
根据其角色和行为,属性可分为几个类别:
- 描述性属性: 基本事实,如姓名、地址或电话号码。
- 关键属性: 唯一标识符。每个实体至少需要一个键来与其他实体区分开来。
- 复合属性: 可以进一步划分为更小部分的数据(例如,地址可拆分为街道、城市、邮编)。
- 派生属性: 从其他数据计算得出的值(例如,年龄由出生日期推导得出)。
- 多值属性: 可以容纳多个值的字段(例如,单个人的多个电话号码)。
主键:锚点 🔑
主键(PK)是最关键的属性。它必须在表中的每条记录中都唯一。它确保没有两行是相同的。主键通常由系统自动生成,例如自增整数或UUID。
选择键时的考虑因素:
- 稳定性: 值不应随时间改变。使用姓名有风险;使用ID更安全。
- 唯一性: 不允许重复。
- 非空性: 没有键,记录就无法存在。
步骤3:建立关系 🔗
实体很少孤立存在。客户下订单。员工参与项目。这些连接就是关系。定义关系正是ERD真正强大之处。
关系的类型
有三种标准的基数用于描述实体之间的交互方式:
- 一对一(1:1): 实体A的一个实例与实体B的一个实例相关联。
- 一对多(1:N): 实体A的一个实例与实体B的多个实例相关联。
- 多对多(M:N):实体A的多个实例与实体B的多个实例相关联。
处理多对多关系
在关系模型中,直接的多对多关系在物理上不被支持。必须使用关联实体(也称为桥接表或连接表)来解决。这个新实体将M:N关系分解为两个一对多关系。
例如,一个学生可以选修多门课程,而一门课程也可以有多个学生。与其直接连接,不如创建一个注册实体。该表包含学生ID和课程ID,以及该注册的任何特定数据(如成绩)。
步骤4:基数和模态 🔢
基数定义了关系的数量。模态定义了可选性(关系是强制的还是可选的)。这些细节确保了数据完整性。
基数表示法
视觉符号有助于开发人员理解约束。常用的符号包括:
- 一个:一条直线或短横线(-)。
- 多个:乌鸦爪符号(∞)或三个分叉。
- 可选:一个圆圈(○),表示允许为零。
- 强制:一条实线,表示至少需要一个。
参与约束
理解参与情况对于应用逻辑至关重要。考虑以下场景:
- 完全参与:每个客户必须有一个订单。(强制)
- 部分参与:一个订单可能有一个配送地址。(可选)
错误的模态会导致数据库错误。如果系统要求强制关系,但数据库允许空值,当数据缺失时,应用逻辑将失效。
步骤 5:规范化上下文 🔄
虽然ERD是一个逻辑模型,但它必须符合规范化原则。规范化可以减少冗余并提高数据完整性。它涉及将属性组织到表中,以最小化依赖关系。
第一范式(1NF)
确保值是原子的。字段不应包含项目列表。例如,不要在“爱好”字段中存储“阅读、徒步、编程”,而应创建一个独立的“爱好”表。
第二范式(2NF)
消除部分依赖。所有非键属性必须依赖于整个主键,而不仅仅是其中一部分。这通常适用于表具有复合键的情况。
第三范式(3NF)
消除传递依赖。非键属性不应依赖于其他非键属性。例如,在“员工”表中,如果根据“办公室ID”存储“城市”,则应将“办公室ID”和“城市”分离到一个“办公室”表中。
ERD有助于可视化这些依赖关系。如果你发现属性以暗示重复的方式分组,那么在编写SQL之前需要调整ERD。⚙️
常见的陷阱,应避免 ⚠️
即使是经验丰富的设计师在初期阶段也会犯错。及早识别这些陷阱可以节省大量开发时间。
| 陷阱 | 后果 | 解决方案 |
|---|---|---|
| 遗漏关系 | 数据变成孤立的岛屿 | 审查所有连接的需求 |
| 过度规范化 | 查询变得过于复杂 | 在数据完整性与读取性能之间取得平衡 |
| 忽略数据类型 | 存储效率低下和错误 | 尽早定义类型(日期、数字、文本) |
| 硬编码值 | 系统变得僵化 | 对静态数据使用查找表 |
| 弱键 | 难以追踪记录 | 确保键是唯一且稳定的 |
文档和审查 📄
ERD 不是一次性完成的绘图。它是一个随着项目不断演进的动态文档。初始设计完成后,必须进行审查。
利益相关者验证
将图表展示给业务分析师和领域专家。他们可以发现开发人员可能忽略的缺失业务规则。例如,“退款在30天后不得处理”这一规则可能不会出现在技术图表中,但却对逻辑至关重要。
技术可行性
与数据库管理员一起审查设计。他们可以评估所提出的模式在预期数据量下的性能表现。他们可能会根据定义的关系,建议索引策略或分区方案。
迭代过程 🔄
数据库设计很少是线性的。新需求不断出现,业务流程也会变化。ERD 必须随之更新以反映这些变化。
模式的版本控制
与代码一样,数据库模式也应进行版本控制。这使团队能够追踪随时间的变化。如果某项更改导致系统崩溃,你可以回退到之前的 ERD 版本及相应的脚本。
变更管理
修改 ERD 时,应考虑对现有数据的影响。向现有表中添加必填字段可能会导致报表失效。新增关系可能需要数据迁移。在更新设计的同时,务必同步规划迁移策略。
工具 vs. 钢笔和纸张 🖊️
尽管有许多软件工具可用于创建 ERD,但最初的构思过程最好不受限制。使用白板或纸笔可以实现快速迭代。你可以随意擦除、重画和重构,而无需担心格式或软件限制。
一旦逻辑结构达成一致,就可以将其转换为正式的绘图工具。这可以确保概念模型不会因软件限制而失真。工具应服务于模型,而非主导模型。
设计的最终思考 🌟
构建数据库是一次严谨的逻辑训练。第一步——创建一个稳固的 ERD——为整个项目奠定了方向。它迫使你在编写代码之前就思考数据之间的关系。这种前瞻性能够减少技术债务,并构建出能够抵御变化的系统。
注重清晰性。使用标准命名。严格定义主键。与利益相关者共同验证。将图表视为业务需求与技术实现之间的合同。遵循这些步骤,可以确保基础足够坚固,能够支撑你的数据重量。 🏗️