Designing a robust data model is one of the most critical tasks in software engineering. An Entity Relationship Diagram (ERD) serves as the blueprint for how information is stored, retrieved, and maintained. At the heart of this blueprint lies normalization. Many practitioners approach normalization as a rigid checklist to be completed before moving to implementation. However, the reality is far more nuanced. There is a delicate balance between data integrity and query performance that requires deep understanding.
This guide explores the technical realities of ERD normalization. It moves beyond the textbook definitions to address practical scenarios where strict adherence to rules becomes a liability. Whether you are building a transactional system or an analytical platform, knowing when to stop normalizing and when to introduce redundancy is essential for long-term stability.
🔍 Understanding the Core Principles of Relational Design
Normalization is not merely about organizing data; it is about managing dependencies. In a relational model, every column must have a clear relationship to the primary key of its table. When this relationship is weak or indirect, anomalies occur. These anomalies manifest as data inconsistencies, wasted storage, and complex update logic.
The primary goals of normalization include:
- Data Integrity: Ensuring that data remains accurate and consistent across the system.
- Storage Efficiency: Eliminating redundant copies of the same data.
- Scalability: Designing schemas that can accommodate growth without structural rewrites.
- Maintainability: Reducing the complexity required to update information.
However, achieving these goals often comes at a cost. Every level of normalization typically increases the number of tables and the complexity of the queries required to retrieve joined data. Understanding this trade-off is the first step in effective schema design.
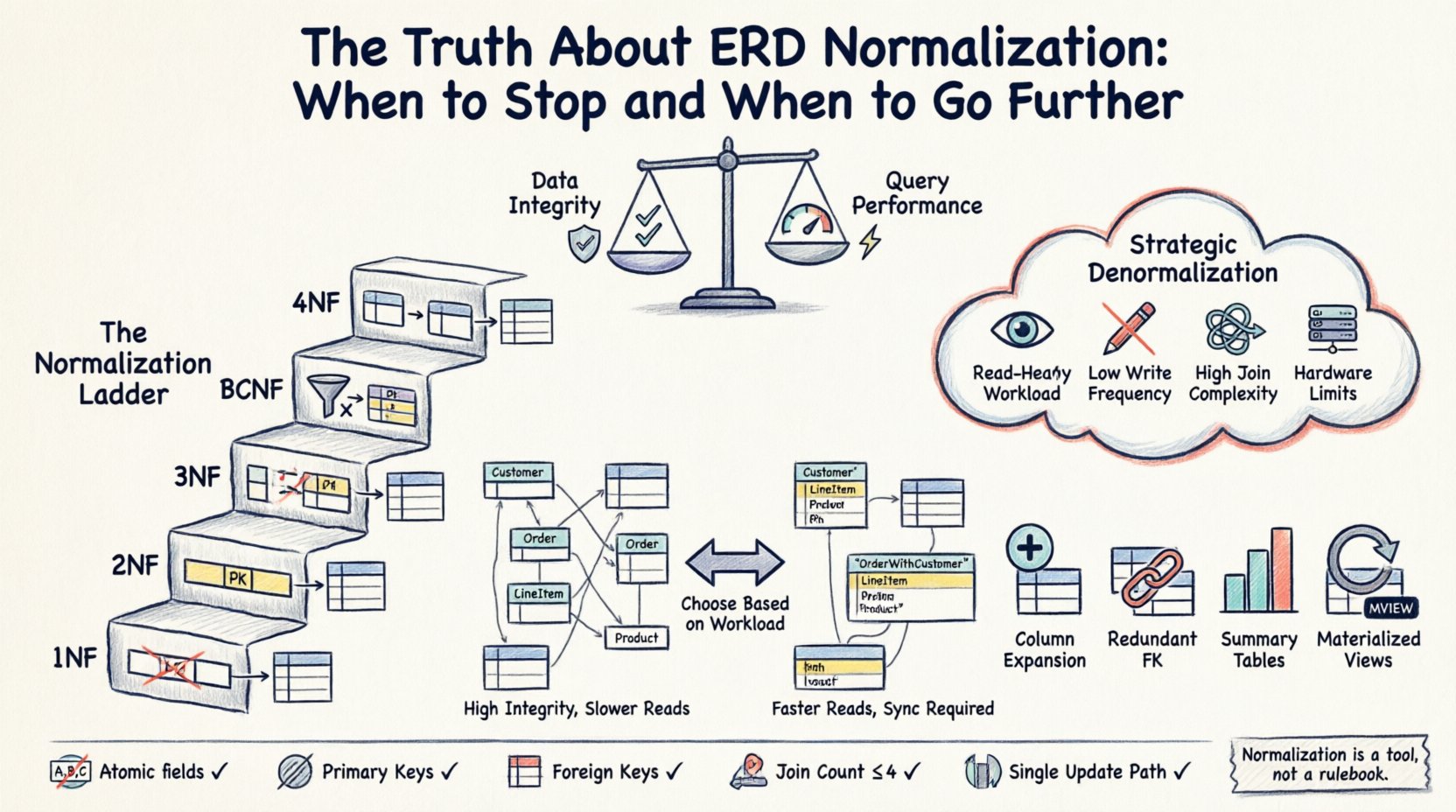
⚙️ The Three Pillars of Standard Normalization (1NF, 2NF, 3NF)
Before deciding to stop or go further, one must understand the baseline. The standard forms provide a ladder of structural refinement.
First Normal Form (1NF)
The foundation of any relational database is 1NF. A table is in 1NF if it meets the following criteria:
- All column values are atomic (indivisible).
- Each column contains values of a single type.
- There are no repeating groups or arrays within a row.
For example, storing a list of product names in a single column violates 1NF. Instead, each product should occupy its own row. While modern systems often handle complex data types, strict adherence to atomicity ensures that queries remain predictable and indexing strategies work as intended.
Second Normal Form (2NF)
Once a table is in 1NF, it must meet 2NF requirements. This form applies specifically to tables with composite primary keys (keys made of multiple columns). A table is in 2NF if:
- It is already in 1NF.
- All non-key attributes are fully dependent on the entire primary key, not just part of it.
Consider an order details table where the key is a combination of Order ID and Product ID. If you store the Product Name in this table, you have a partial dependency. The Product Name depends only on the Product ID, not the Order ID. To fix this, you move the Product Name to a separate Products table. This reduces update anomalies; if a product name changes, you update it in one place, not across thousands of order records.
Third Normal Form (3NF)
3NF is often considered the sweet spot for most operational systems. A table is in 3NF if:
- It is in 2NF.
- There are no transitive dependencies. Non-key attributes must depend only on the primary key.
A transitive dependency occurs when Column A determines Column B, and Column B determines Column C. In a database, if Customer ID determines City, and City determines Region, storing Region in the Customer table creates a transitive dependency. If the Region changes for that City, you must update every customer record in that city. Normalizing this out moves the Region data to a separate location, ensuring updates happen once.
📉 The Performance Cost of Strict Normalization
While 3NF minimizes redundancy, it maximizes the number of tables. In a normalized schema, retrieving a single logical record often requires joining multiple tables. This process has a computational cost.
- Join Overhead: Every join operation requires the database engine to match rows from different tables. As tables grow larger, this matching process consumes CPU and memory.
- I/O Operations: Data spread across many tables requires more disk reads. If the data is not cached efficiently, read latency increases.
- Complexity: Complex queries with many joins are harder to optimize and maintain. They are also more prone to breaking if the schema changes.
For systems with heavy write loads, normalization is usually the correct choice. It prevents data duplication and ensures that an update to a single fact propagates correctly. However, for systems with heavy read loads, the cost of joins can become a bottleneck.
🚀 Strategic Denormalization: When to Break the Rules
Denormalization is the intentional introduction of redundancy to optimize performance. It is not a mistake; it is a deliberate architectural decision made when the cost of normalization exceeds its benefits.
Triggers for Denormalization
You should consider relaxing normalization rules when:
- Read Operations Dominate: If your application is read-heavy (e.g., a reporting dashboard), reducing joins can significantly lower latency.
- Query Complexity is High: If users require data from 10+ tables to view a single page, the query becomes slow and difficult to debug.
- Write Frequency is Low: If data is rarely updated, the risk of inconsistency from redundancy is minimized.
- Hardware Constraints Exist: In environments where disk I/O is expensive or limited, caching redundant data can reduce physical reads.
Common Denormalization Strategies
- Column Expansion: Storing a derived value directly in a table. For example, adding a “Total Price” column to an Order table, calculated from line items, so you do not need to sum them on every read.
- Redundant Foreign Keys: Adding a Parent ID to a Child table to avoid a join when retrieving the hierarchy.
- Summary Tables: Pre-calculating aggregates (counts, sums) in a separate table that is updated periodically or via triggers.
- Materialized Views: Storing the result of a complex query as a physical table that refreshes on a schedule.
📊 Comparison: Normalization vs. Denormalization
To visualize the trade-offs, consider the following comparison table.
| Aspect | High Normalization (3NF+) | Denormalized Design |
|---|---|---|
| Data Integrity | High – Single source of truth | Lower – Requires sync logic |
| Storage Usage | Efficient – No duplicates | Inefficient – Redundant data |
| Write Performance | Fast – Single row update | Slower – Multiple rows update |
| Read Performance | Slower – Requires joins | Fast – Direct access |
| Query Complexity | High – Many joins needed | Low – Simple queries |
| Maintenance Effort | Low – Update once | High – Sync multiple places |
This table highlights that there is no universal best practice. The choice depends entirely on the specific workload of the application.
🛠️ Decision Framework for Schema Design
To determine the right level of normalization for your specific project, use this decision framework. Evaluate each point against your project requirements.
1. Analyze the Workload Pattern
Identify the ratio of reads to writes. If your system is OLTP (Online Transaction Processing), prioritize integrity and 3NF. If it is OLAP (Online Analytical Processing), prioritize read speed and consider denormalization.
2. Assess Data Freshness Requirements
Does the data need to be real-time? If you denormalize, you introduce a delay between a source update and the reflected change in the redundant data. If your users need immediate consistency, strict normalization is safer.
3. Evaluate Update Frequency
Look at the primary keys. If a lookup table (like a list of countries) changes rarely, denormalizing its data into transactional tables is safe. If a lookup table changes frequently, keep it separate to minimize synchronization errors.
4. Consider Hardware and Caching
Modern databases often cache data in memory. If your working set fits in RAM, the cost of joins decreases. In this case, you can afford a slightly more normalized schema without sacrificing performance.
🧠 Advanced Normalization: BCNF and 4NF
Beyond 3NF, there are higher forms like Boyce-Codd Normal Form (BCNF) and Fourth Normal Form (4NF). These address specific edge cases.
Boyce-Codd Normal Form (BCNF)
BCNF is a stricter version of 3NF. It handles cases where a non-prime attribute determines another non-prime attribute, even if the primary key is composite. While theoretically perfect, BCNF can sometimes result in a loss of dependency preservation. In practice, 3NF is often sufficient, and forcing BCNF can sometimes complicate the schema without adding significant value.
Fourth Normal Form (4NF)
4NF deals with multi-valued dependencies. This occurs when a single row contains multiple independent lists of values. For example, a student table storing multiple hobbies and multiple classes in the same row. This is rare in standard business applications but common in specialized data modeling scenarios.
🚫 Common Pitfalls to Avoid
Even with a solid understanding of normalization, it is easy to make mistakes. Avoid these common errors:
- Over-Normalization: Creating hundreds of tiny tables for simple relationships. This makes the application logic difficult to follow and slows down development.
- Ignoring Indexes: A normalized schema requires joins. If the join columns are not indexed, performance will degrade regardless of the schema design.
- Denormalizing Without Monitoring: Introducing redundancy without a plan to keep it synchronized leads to data corruption over time.
- Hardcoding Logic: Do not calculate derived values in the application layer if they should be in the database. Keep business rules close to the data.
✅ Checklist for Schema Validation
Before deploying a new schema, run it through this validation checklist.
- Atomicity: Are all fields atomic?
- Primary Keys: Does every table have a unique primary key?
- Foreign Keys: Are relationships enforced via foreign keys?
- Redundancy: Are there any obvious repeated groups of data?
- Join Count: Do critical queries require more than 3-4 joins?
- Update Path: Can a single data change be made in one place?
🔗 Conclusion on Data Architecture
Normalization is a tool, not a rulebook. It exists to protect your data from inconsistency, but it should not prevent your application from performing efficiently. The “truth” about ERD normalization is that it is a spectrum. You start with a highly normalized structure to ensure integrity, and you selectively denormalize based on performance needs.
There is no one-size-fits-all solution. A high-frequency trading system will look very different from a content management system. The key is to understand the underlying mechanics of dependencies and joins. By balancing the cost of storage against the cost of computation, you can build systems that are both reliable and fast.
As you continue to design, remember that schema evolution is inevitable. Plan for changes. Use versioning for your database migrations. And always test your queries under load before committing to a structural decision. The best schema is the one that supports your business goals without becoming a bottleneck.