Data modeling is often viewed as a static exercise in defining relationships and entities. However, an Entity Relationship Diagram (ERD) is not merely a blueprint for storage; it is a direct determinant of how efficiently a database engine retrieves and manipulates information. Every line drawn, every relationship defined, and every data type selected ripples through the execution plan of your queries. Understanding the mechanics behind schema design allows for systems that scale gracefully under load.
This guide explores the technical relationship between ERD structures and query performance. We will move beyond basic definitions to examine how specific modeling decisions influence I/O operations, CPU usage, and locking mechanisms within a relational environment.
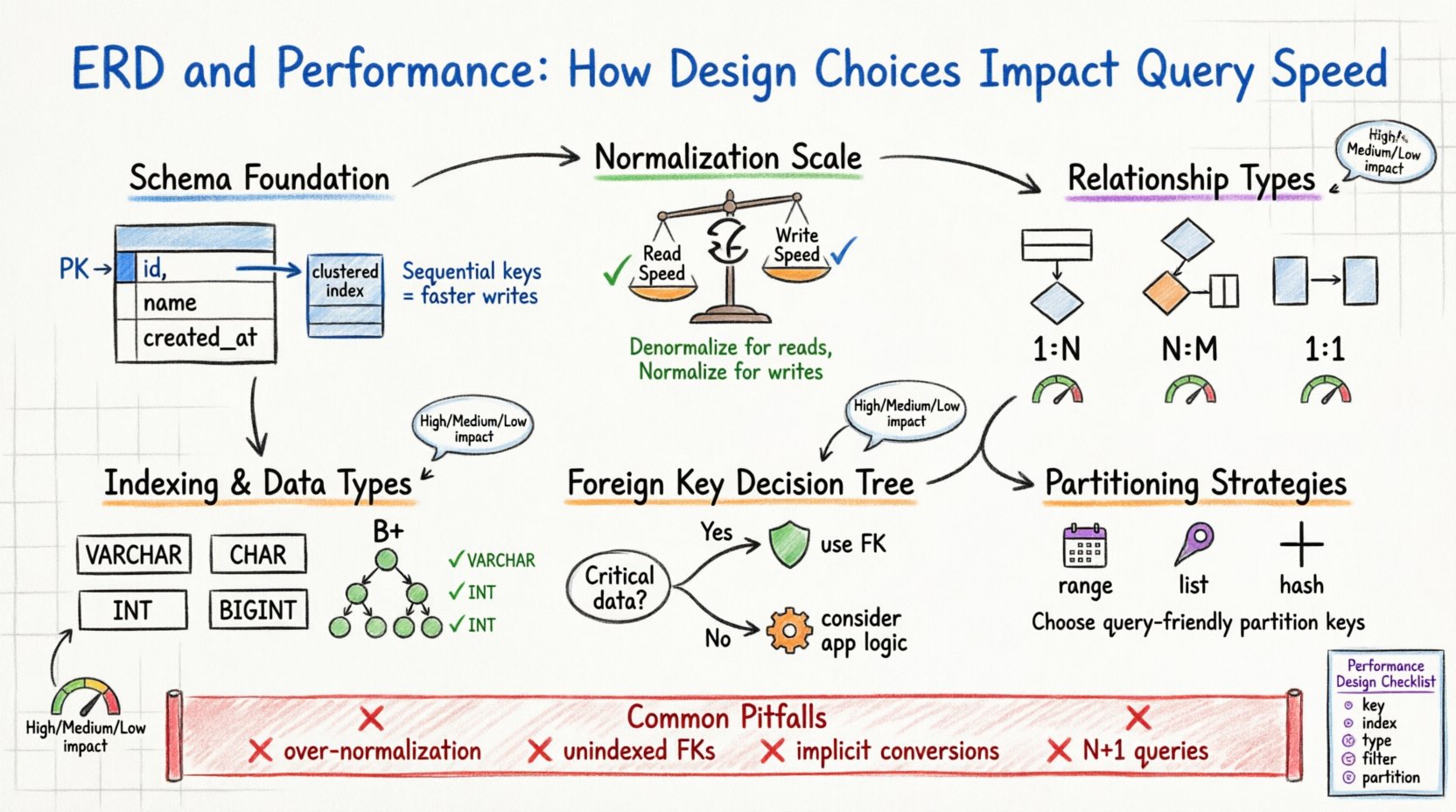
1. The Foundation: Schema Structure and Physical Storage 🏗️
The logical design you create in your ERD eventually translates to physical files on a disk. The database engine must map these logical entities to pages, blocks, and rows. When the schema is optimized, the engine minimizes the number of disk reads required to satisfy a request. When it is not, the engine may be forced to perform full table scans, which are expensive operations.
Consider the primary key. It serves as the unique identifier for a row. In many storage engines, the primary key defines the physical order of data on the disk (Clustered Index). Choosing a primary key that is sequential and short ensures that data is stored contiguously. This reduces fragmentation and allows for faster range scans. Conversely, a random, long primary key can cause page splits during inserts, degrading write performance and increasing storage overhead.
Key Considerations for Primary Keys
- Sequentiality: Auto-incrementing integers are typically preferred for write-heavy workloads.
- Size: Smaller keys reduce the size of secondary indexes, as they are stored as pointers in those indexes.
- Stability: Primary keys should not change. Updating a primary key often requires updating all associated foreign keys.
2. Normalization vs. Performance Trade-offs ⚖️
Normalization is the process of organizing data to reduce redundancy and improve integrity. While traditionally associated with data quality, it has profound effects on performance. A highly normalized schema (e.g., Third Normal Form) often requires more joins to reconstruct data, whereas a denormalized schema reduces joins but increases storage and update complexity.
The decision to normalize or denormalize is a balance between read speed and write speed. In a read-heavy environment, denormalization can significantly reduce query time by avoiding complex joins. In a write-heavy environment, normalization reduces the number of rows that need to be updated across multiple tables.
Normalization Impact Analysis
| Aspect | Highly Normalized | Denormalized |
|---|---|---|
| Read Performance | Lower (Requires Joins) | Higher (Single Table Access) |
| Write Performance | Higher (Less Redundancy) | Lower (Update Multiple Copies) |
| Data Integrity | High (Single Source of Truth) | Lower (Risk of Inconsistency) |
| Storage Usage | Lower | Higher |
3. Foreign Keys and Integrity Overhead 🔗
Foreign keys enforce referential integrity. They ensure that a value in one table matches a value in another. While this prevents orphaned records, it introduces runtime overhead. When you insert, update, or delete a row, the database must check the foreign key constraint.
This check is not free. The engine must locate the referenced row and verify its existence. If the referenced table is large and lacks an index on the foreign key column, the check becomes a full table scan. Furthermore, deleting a parent record requires the engine to check all child records to ensure no references remain, potentially locking many rows.
When to Use Foreign Keys
- Critical Data Integrity: If data correctness is paramount (e.g., financial transactions), use foreign keys.
- Application Logic: If the application logic is complex, offloading integrity to the database simplifies code.
- Small Datasets: The overhead is negligible on small tables.
When to Avoid Foreign Keys
- High Write Throughput: Removing constraints can reduce locking contention.
- Large Scale Analytics: In data warehousing, performance often outweighs strict integrity.
- Architectural Layers: In microservices, maintaining foreign keys across service boundaries is often impractical.
4. Indexing Strategies and Column Types 📑
An ERD defines the data types for every column. The choice between a VARCHAR and a CHAR, or an INT and a BIGINT, impacts how data is stored and indexed. Smaller data types consume less memory and disk space, allowing more data to fit in the buffer pool (RAM).
When a query filters on a column, the database engine relies on indexes to find rows quickly. If the schema design does not align with the query patterns, indexes become useless. For example, creating an index on a column that is rarely used in WHERE clauses is a waste of resources.
Column Type Optimization
- Fixed vs. Variable Length: Use CHAR for fixed-length data (e.g., country codes) to reduce fragmentation. Use VARCHAR for variable-length data.
- Integer Ranges: Do not use BIGINT if INT suffices. Smaller integers fit more rows per page.
- Boolean Representation: Use TINYINT(1) or BOOLEAN types rather than storing ‘Yes’/’No’ strings.
5. Relationship Cardinality Implications 📊
The cardinality of relationships (One-to-One, One-to-Many, Many-to-Many) dictates how data is linked. Each relationship type has different performance characteristics.
One-to-Many (1:N)
This is the most common relationship. A parent table holds one record, and the child table holds many. Performance depends heavily on the index on the foreign key column in the child table. Without this index, finding all children for a parent requires scanning the entire child table.
Many-to-Many (N:M)
This requires a junction table (associative entity). This adds an extra layer of indirection. Queries involving N:M relationships typically require three joins: Table A, Junction Table, Table B. This complexity increases CPU usage and memory requirements.
One-to-One (1:1)
Often used to split a large table into logical groups. This can improve performance if only one subset of columns is frequently queried. However, it adds the cost of a join to retrieve the full record.
6. Partitioning and Sharding Considerations 🗃️
As data grows, a single table can become too large to manage efficiently. Partitioning allows you to divide a large table into smaller, more manageable pieces based on a key (e.g., date). The ERD design must anticipate this.
If you design a schema for a system that will eventually be sharded (split across multiple servers), the partition key must be chosen carefully. The key should be used frequently in queries to allow the engine to route requests to the correct shard. Choosing a key that is not used in queries forces the system to aggregate data from all shards, which is slow.
Partitioning Strategies
- Range Partitioning: Split by date or ID ranges. Good for time-series data.
- List Partitioning: Split by specific values (e.g., region codes).
- Hash Partitioning: Distributes data evenly to avoid hotspots.
7. Common Pitfalls in Design 🚫
Even experienced architects can introduce performance bottlenecks through design choices. Recognizing these patterns early prevents costly refactoring later.
- Over-Normalization: Splitting data into too many small tables increases join complexity and reduces cache efficiency.
- Ignoring Selectivity: Indexing columns with low selectivity (e.g., gender or status flags) often yields poor performance because the optimizer may ignore the index and scan the table anyway.
- Implicit Conversions: Designing a column as a string when numeric values are expected forces the engine to convert types during queries, preventing index usage.
- N+1 Query Patterns: Designing relationships that encourage fetching data in loops rather than batched joins can overwhelm the server.
8. Future Proofing and Evolution 🛡️
Databases evolve. Requirements change, and new features are added. A schema that is performant today may become a bottleneck tomorrow if it lacks flexibility. The ERD should accommodate growth without requiring a complete rewrite.
Consider adding columns that are likely to be used for filtering in the future. While this increases row size slightly, it saves the cost of altering the table structure later, which can be an expensive operation on large datasets. Also, consider the impact of adding new indexes. Every index consumes write resources. Design the schema to minimize the number of necessary indexes.
Design Checklist for Performance
- Are primary keys short and sequential?
- Are foreign keys indexed?
- Are data types the smallest possible valid type?
- Are frequent filters covered by indexes?
- Is the normalization level appropriate for the workload?
- Have you considered partitioning for large tables?
- Are there any columns storing complex JSON or text that could be structured?
9. The Role of the Execution Plan 📋
Ultimately, the database engine decides how to execute a query based on the schema and statistics. The ERD influences the statistics the engine gathers. For example, a column with a distinct value distribution will be handled differently than one with skewed data. Understanding how the execution plan works helps you interpret why a query is slow.
If a query performs a full table scan, it often indicates a missing index or a design that does not support efficient filtering. If it performs many nested loops, it suggests complex joins that could be simplified. By aligning the ERD with the expected access patterns, you guide the engine toward optimal execution plans.
10. Balancing Integrity and Speed ⚖️
There is no perfect schema. Every design choice involves a trade-off. The goal is not to eliminate performance issues but to manage them strategically. In some cases, accepting a small risk of data inconsistency (via application-level checks instead of database constraints) is a valid trade-off for extreme write throughput.
Regularly review your ERD against actual query logs. Identify the slowest queries and trace them back to the schema. This feedback loop ensures that your design evolves in sync with your application’s needs.
Summary of Impact Areas 📝
| Design Element | Performance Impact | Recommendation |
|---|---|---|
| Primary Key Type | High (Storage & Indexing) | Use integers or UUIDs consistently. |
| Foreign Keys | Medium (Write Overhead) | Index FK columns; remove if integrity is handled elsewhere. |
| Normalization | High (Join Complexity) | Denormalize read-heavy tables. |
| Data Types | Medium (Memory Usage) | Use the most specific type available. |
| Cardinality | High (Join Cost) | Optimize junction tables for N:M relationships. |
By treating the Entity Relationship Diagram as a performance artifact rather than just a logical map, you can build systems that are robust, scalable, and efficient. The decisions you make now will dictate the behavior of your application for years to come.